第4次系统综合实践
(1)使用Docker-compose实现Tomcat+Nginx负载均衡
1.docker-compose.yml
version: "3"
services:
nginx:
image: nginx
container_name: mynginx
ports:
- 82:2020
volumes:
- ./default.conf:/etc/nginx/conf.d/default.conf
depends_on:
- tomcat1
- tomcat2
- tomcat3
tomcat1:
image: tomcat
container_name: mynginx1
volumes:
- ./tomcat1:/usr/local/tomcat/webapps/ROOT
tomcat2:
image: tomcat
container_name: mynginx2
volumes:
- ./tomcat2:/usr/local/tomcat/webapps/ROOT
tomcat3:
image: tomcat
container_name: mynginx3
volumes:
- ./tomcat3:/usr/local/tomcat/webapps/ROOT
2.default.conf
upstream tomcats {
server mynginx1:8080; # 主机名:端口号
server mynginx2:8080; # tomcat默认端口号8080
server mynginx3:8080; # 默认使用轮询策略
}
server {
listen 2020;
server_name localhost;
location / {
proxy_pass http://tomcats; # 请求转向tomcats
}
}
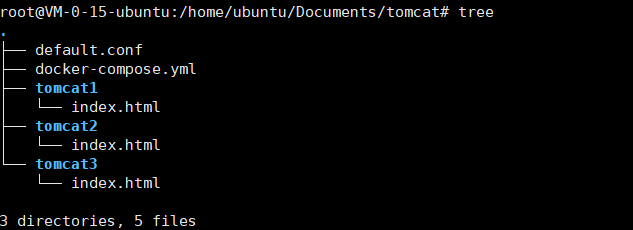
3.查看文件结构:
4.构建:

5.在浏览器中打开:
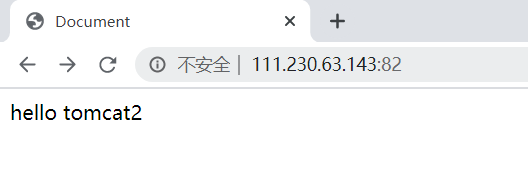
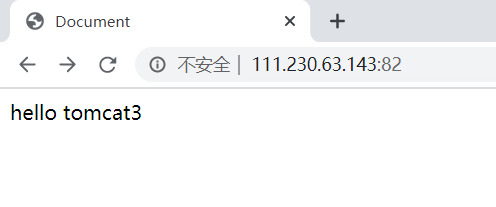
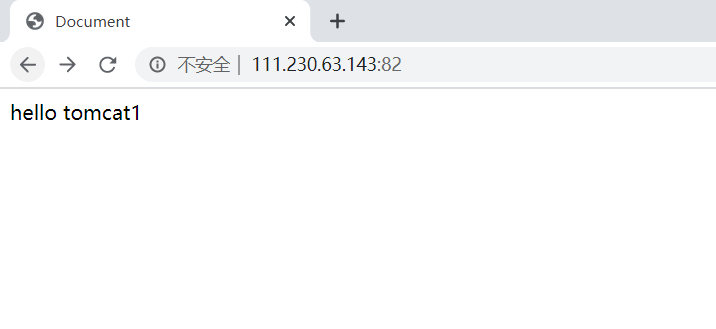
6.测试均衡负载:
多次刷新页面,可以看出会随机加载:
(2) 使用Docker-compose部署javaweb运行环境
参考资料:https://blog.csdn.net/weixin_41043145/article/details/92834784
1.修改ip地址:此处不发图了
2.构建:

3.在本地浏览器中查看效果:
4.在本地对数据库进行操作:
5.更改为均衡负载:
docker-compose.yml
version: "3"
services:
tomcat: #tomcat 服务
image: tomcat #镜像
hostname: hostname
container_name: tomcat00
ports:
- "5050:8080"
volumes: #
- "./webapps:/usr/local/tomcat/webapps"
- ./wait-for-it.sh:/wait-for-it.sh
networks: #网络设置静态IP
webnet:
ipv4_address: 15.22.0.15
mymysql:
build: . #通过MySQL的Dockerfile文件构建MySQL
image: mymysql:test
container_name: mymysql
ports:
- "3309:3306"
command: [
'--character-set-server=utf8mb4',
'--collation-server=utf8mb4_unicode_ci'
]
environment:
MYSQL_ROOT_PASSWORD: "123456"
networks:
webnet:
ipv4_address: 15.22.0.6
nginx:
image: nginx
container_name: "nginx-tomcat"
ports:
- 8080:8080
volumes:
- ./default.conf:/etc/nginx/conf.d/default.conf # 挂载配置文件
tty: true
stdin_open: true
networks:
webnet:
ipv4_address: 15.22.0.7
networks: #网络设置
webnet:
driver: bridge #网桥模式
ipam:
config:
-
subnet: 15.22.0.0/24 #子网
default.conf:
upstream tomcat123 { server tomcat00:8080; } server { listen 8080; server_name localhost; location / { proxy_pass http://tomcat123; } }
(3)使用Docker搭建大数据集群环境
1.
2.换源:

3.apt更新与安装一些软件:
apt-get update apt-get install vim # 用于修改配置文件 apt-get install ssh # 分布式hadoop通过ssh连接 /etc/init.d/ssh start # 开启sshd服务器 vim ~/.bashrc # 在文件末尾添加/etc/init.d/ssh start,实现ssd开机自启
4.安装jdk
apt install openjdk-8-jdk vim ~/.bashrc # 在文件末尾添加以下两行,配置Java环境变量: export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64/ export PATH=$PATH:$JAVA_HOME/bin source ~/.bashrc # 使.bashrc生效 java -version #查看是否安装成功
5.配置hadoop
core-site.xml:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop-3.1.3/tmp</value>
<description>A base for other temporary derectories.</description>
</property>
</configuration>
hdfs-site.xml:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop-3.1.3/tmp/dfs/name</value>
</property>
<property>
<name>dfs.namenode.data.dir</name>
<value>file:/usr/local/hadoop-3.1.3/tmp/dfs/data</value>
</property>
</configuration>
mapred-site.xml:
<configuration>
<property>
<!--使用yarn运行MapReduce程序-->
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<!--jobhistory地址host:port-->
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<!--jobhistory的web地址host:port-->
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
<property>
<!--指定MR应用程序的类路径-->
<name>mapreduce.application.classpath</name>
<value>/usr/local/hadoop-3.1.3/share/hadoop/mapreduce/lib/*,/usr/local/hadoop-3.1.3/share/hadoop/mapreduce/*</value>
</property>
</configuration>
yarn-site.xml:
<configuration> <property> <name>yarn.resourcemanager.hostname</name> <value>master</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.vmem-pmem-ratio</name> <value>2.5</value> </property> </configuration>
对于start-dfs.sh和stop-dfs.sh文件,添加下列参数:
HDFS_DATANODE_USER=root HADOOP_SECURE_DN_USER=hdfs HDFS_NAMENODE_USER=root HDFS_SECONDARYNAMENODE_USER=root
对于start-yarn.sh和stop-yarn.sh,添加下列参数
YARN_RESOURCEMANAGER_USER=root HADOOP_SECURE_DN_USER=yarn YARN_NODEMANAGER_USER=root
6.运行:
docker commit 52927f8bcb13 ubuntu_hadoop
# 第一个终端 sudo docker run -it -h master --name master ubuntu_hadoop # 第二个终端 sudo docker run -it -h slave01 --name slave01 ubuntu_hadoop # 第三个终端 sudo docker run -it -h slave02 --name slave02 ubuntu_hadoop

 浙公网安备 33010602011771号
浙公网安备 33010602011771号