猫狗识别——PyTorch
猫狗识别
数据集下载:
网盘链接:https://pan.baidu.com/s/1SlNAPf3NbgPyf93XluM7Fg
提取密码:hpn4
1. 要导入的包


import os import time import numpy as np import torch import torch.nn as nn import torch.nn.functional as F from torch.utils.data import DataLoader from torch.utils import data from torchvision import transforms as T from PIL import Image
2. 模型配置
################################### # SETTINGS ################################### class Config(object): batch_size = 32 max_epoch = 30 num_workers = 2 lr = 0.001 lr_decay = 0.95 weight_decay = 0.0001 train_data_root = '/home/dong/Documents/DATASET/train' test_data_root = '/home/dong/Documents/DATASET/test' load_dict_path = None opt = Config()
3. 选择DEVICE
device = 'cuda:0' if torch.cuda.is_available() else 'cpu'
4. 数据集
################################### # DATASETS ################################### class DogCatDataset(data.Dataset): def __init__(self, root, transforms=None, train=True, test=False): super(DogCatDataset, self).__init__() imgs = [os.path.join(root, img) for img in os.listdir(root)] np.random.seed(10000) np.random.permutation(imgs) len_imgs = len(imgs) self.test = test # ----------------------------------------------------------------------------------------- # 因为在猫狗数据集中,只有训练集和测试集,但是我们还需要验证集,因此从原始训练集中分离出30%的数据 # 用作验证集。 # ------------------------------------------------------------------------------------------ if self.test: self.imgs = imgs elif train: self.imgs = imgs[: int(0.7*len_imgs)] else: self.imgs = imgs[int(0.7*len_imgs): ] if transforms is None: normalize = T.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) if self.test or not train: self.transforms = T.Compose([ T.Scale(224), T.CenterCrop(224), T.ToTensor(), normalize ]) else: self.transforms = T.Compose([ T.Scale(246), T.RandomCrop(224), T.RandomHorizontalFlip(), T.ToTensor(), normalize ]) def __getitem__(self, index): # 当前要获取图像的路径 img_path = self.imgs[index] if self.test: img_label = int(img_path.split('.')[-2].split('/')[-1]) else: img_label = 1 if 'dog' in img_path.split('/')[-1] else 0 img_data = Image.open(img_path) img_data = self.transforms(img_data) return img_data, img_label def __len__(self): return len(self.imgs) train_dataset = DogCatDataset(root=opt.train_data_root, train=True) # train=True, test=False -> 训练集 val_dataset = DogCatDataset(root=opt.train_data_root, train=False) # train=False, test=False -> 验证集 test_dataset = DogCatDataset(root=opt.test_data_root, test=True) # test=True -> 测试集 train_dataloader = DataLoader(dataset=train_dataset, shuffle=True, batch_size=opt.batch_size, num_workers = opt.num_workers) val_dataloader = DataLoader(dataset=val_dataset, shuffle=False, batch_size=opt.batch_size, num_workers = opt.num_workers) test_dataloader = DataLoader(dataset=test_dataset, shuffle=False, batch_size=opt.batch_size, num_workers = opt.num_workers)
5. 检查数据集的 shape
# ------------------------------------------------ # CHECKING THE DATASETS # ------------------------------------------------ print("Training set:") for images, labels in train_dataloader: print('Image Batch Dimensions:', images.size()) print('Label Batch Dimensions:', labels.size()) break print("Validation set:") for images, labels in val_dataloader: print('Image Batch Dimensions:', images.size()) print('Label Batch Dimensions:', labels.size()) break print("Testing set:") for images, labels in test_dataloader: print('Image Batch Dimensions:', images.size()) print('Label Batch Dimensions:', labels.size()) break
eg:
Training set:
Image Batch Dimensions: torch.Size([32, 3, 224, 224])
Label Batch Dimensions: torch.Size([32])
Validation set:
Image Batch Dimensions: torch.Size([32, 3, 224, 224])
Label Batch Dimensions: torch.Size([32])
Testing set:
Image Batch Dimensions: torch.Size([32, 3, 224, 224])
Label Batch Dimensions: torch.Size([32])
6. 模型定义
################################################### # MODEL ################################################### class AlexNet(nn.Module): def __init__(self, num_classes=2): # num_classes代表数据集的类别数 super(AlexNet, self).__init__() self.features = nn.Sequential( nn.Conv2d(3, 64, kernel_size=(11, 11), stride=(4, 4), padding=2), nn.ReLU(inplace=True), nn.MaxPool2d(kernel_size=(3, 3), stride=2), nn.Conv2d(64, 192, kernel_size=5, padding=2), nn.ReLU(inplace=True), nn.MaxPool2d(kernel_size=3, stride=2), nn.Conv2d(192, 384, kernel_size=3, padding=1), nn.ReLU(inplace=True), nn.Conv2d(384, 256, kernel_size=3, padding=1), nn.ReLU(inplace=True), nn.Conv2d(256, 256, kernel_size=3, padding=1), nn.ReLU(inplace=True), nn.MaxPool2d(kernel_size=3, stride=2) ) self.avgpool = nn.AdaptiveAvgPool2d((6, 6)) self.classifers = nn.Sequential( nn.Dropout(), nn.Linear(256 * 6 * 6, 4096), nn.ReLU(inplace=True), nn.Dropout(), nn.Linear(4096, 4096), nn.ReLU(inplace=True), nn.Linear(4096, num_classes), ) def forward(self, x): x = self.features(x) x = self.avgpool(x) x = x.view(x.size(0), 256*6*6) logits = self.classifers(x) probas = F.softmax(logits, dim=1) return logits, probas # 记载模型 def load(self, model_path): self.load_state_dict(torch.load(model_path)) # 保存模型 def save(self, model_name): # 状态字典的保存格式:文件名 + 日期时间 .pth prefix = 'checkpoints/' + model_name + '_' name = time.strftime(prefix + '%m%d_%H:%M:%S.pth') torch.save(self.state_dict, name) model = AlexNet() model = model.to(device)
7. 定义优化器
############################################## # Optimizer ############################################## # optimizer = torch.optim.Adam(model.parameters(), lr=opt.lr, weight_decay=opt.weight_decay) optimizer = torch.optim.SGD(model.parameters(), lr=opt.lr, momentum=0.8)
8. 计算准确率
# ------------------------------------------- # 计算准确率 # ------------------------------------------- def compute_acc(model, dataloader, device): correct_pred, num_examples = 0, 0 # correct_pred 统计正确预测的样本数,num_examples 统计样本总数 for i, (features, targets) in enumerate(dataloader): features = features.to(device) targets = targets.to(device) logits, probas = model(features) _, predicted_labels = torch.max(probas, 1) num_examples += targets.size(0) assert predicted_labels.size() == targets.size() correct_pred += (predicted_labels == targets).sum() return correct_pred.float() / num_examples * 100
9. 训练 and 验证
############################################## # TRAINING and VALIDATION ############################################## cost_list = [] train_acc_list, val_acc_list = [], [] start_time = time.time() for epoch in range(opt.max_epoch): model.train() for batch_idx, (features, targets) in enumerate(train_dataloader): features = features.to(device) targets = targets.to(device) optimizer.zero_grad() logits, probas = model(features) # print(targets.size(), logits.size(), probas.size()) cost = F.cross_entropy(logits, targets) # cost = torch.nn.CrossEntropyLoss(logits, targets) cost.backward() optimizer.step() cost_list.append(cost.item()) if not batch_idx % 50: print('Epoch: %03d/%03d | Batch %03d/%03d | Cost: %.4f' %(epoch+1, opt.max_epoch, batch_idx, len(train_dataloader), cost)) model.eval() with torch.set_grad_enabled(False): # save memory during inference train_acc = compute_acc(model, train_dataloader, device=device) val_acc = compute_acc(model, val_dataloader, device=device) print('Epoch: %03d/%03d | Training ACC: %.4f%% | Validation ACC: %.4f%%' %(epoch+1, opt.max_epoch, train_acc, val_acc)) train_acc_list.append(train_acc) val_acc_list.append(val_acc) print('Time Elapsed: %.2f min' % ((time.time() - start_time)/60)) print('Total Time Elapsed: %.2f min' % ((time.time() - start_time)/60))
eg:
Epoch: 001/030 | Batch 000/547 | Cost: 0.6945
Epoch: 001/030 | Batch 050/547 | Cost: 0.6920
Epoch: 001/030 | Batch 100/547 | Cost: 0.6942
Epoch: 001/030 | Batch 150/547 | Cost: 0.6926
Epoch: 001/030 | Batch 200/547 | Cost: 0.6926
Epoch: 001/030 | Batch 250/547 | Cost: 0.6946
Epoch: 001/030 | Batch 300/547 | Cost: 0.6920
Epoch: 001/030 | Batch 350/547 | Cost: 0.6951
Epoch: 001/030 | Batch 400/547 | Cost: 0.6943
Epoch: 001/030 | Batch 450/547 | Cost: 0.6946
Epoch: 001/030 | Batch 500/547 | Cost: 0.6932
Epoch: 001/030 | Training ACC: 51.7657% | Validation ACC: 50.8933%
Time Elapsed: 2.98 min
Epoch: 002/030 | Batch 000/547 | Cost: 0.6926
Epoch: 002/030 | Batch 050/547 | Cost: 0.6931
Epoch: 002/030 | Batch 100/547 | Cost: 0.6915
Epoch: 002/030 | Batch 150/547 | Cost: 0.6913
Epoch: 002/030 | Batch 200/547 | Cost: 0.6908
Epoch: 002/030 | Batch 250/547 | Cost: 0.6964
Epoch: 002/030 | Batch 300/547 | Cost: 0.6939
Epoch: 002/030 | Batch 350/547 | Cost: 0.6914
Epoch: 002/030 | Batch 400/547 | Cost: 0.6941
Epoch: 002/030 | Batch 450/547 | Cost: 0.6937
Epoch: 002/030 | Batch 500/547 | Cost: 0.6948
Epoch: 002/030 | Training ACC: 53.0400% | Validation ACC: 52.2933%
Time Elapsed: 6.00 min
...
Epoch: 030/030 | Batch 000/547 | Cost: 0.1297
Epoch: 030/030 | Batch 050/547 | Cost: 0.2972
Epoch: 030/030 | Batch 100/547 | Cost: 0.2468
Epoch: 030/030 | Batch 150/547 | Cost: 0.1685
Epoch: 030/030 | Batch 200/547 | Cost: 0.3452
Epoch: 030/030 | Batch 250/547 | Cost: 0.3029
Epoch: 030/030 | Batch 300/547 | Cost: 0.2975
Epoch: 030/030 | Batch 350/547 | Cost: 0.2125
Epoch: 030/030 | Batch 400/547 | Cost: 0.2317
Epoch: 030/030 | Batch 450/547 | Cost: 0.2464
Epoch: 030/030 | Batch 500/547 | Cost: 0.2487
Epoch: 030/030 | Training ACC: 89.5314% | Validation ACC: 88.6400%
Time Elapsed: 92.85 min
Total Time Elapsed: 92.85 min
10. 可视化 Loss
plt.plot(cost_list, label='Minibatch cost')
plt.plot(np.convolve(cost_list,
np.ones(200,)/200, mode='valid'),
label='Running average')
plt.ylabel('Cross Entropy')
plt.xlabel('Iteration')
plt.legend()
plt.show()
eg:
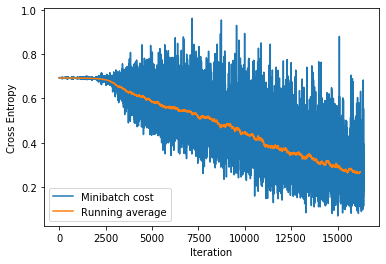
11. 可视化 准确率
plt.plot(np.arange(1, opt.max_epoch+1), train_acc_list, label='Training') plt.plot(np.arange(1, opt.max_epoch+1), val_acc_list, label='Validation') plt.xlabel('Epoch') plt.ylabel('Accuracy') plt.legend() plt.show()
eg:
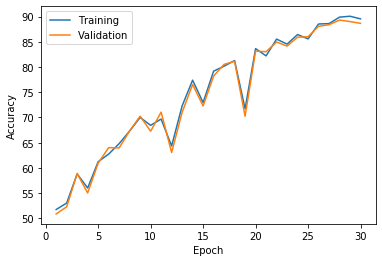

 浙公网安备 33010602011771号
浙公网安备 33010602011771号