

Python 爬虫过程中的中文乱码问题
python+mongodb
在爬虫的过程中,抓到一个中文字段,encode和decode都无法正确显示
注:以下print均是在mongodb中截图显示的,在pythonshell中可能会有所不同
比如中文 “余年”,假设其为变量a
1. print a 结果如下:
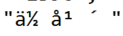
使用type查询之后,显示的确是unicode编码(正常情况下讲unicode编码内容直接存入mongodb中是可以正常显示的)
2. print type(a) 结果如下:

3. print a.encode('utf-8') 结果如下:
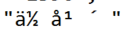
然后查看a的unicode编码,是这种格式 u''\xe4\xbd\x99\xe5\xb9\xb4"
解决办法:
a = a.encode('ISO 8859-1')
这样将a的由unicode的type变成了str类型的type
然后就可以正确的保存到mongodb中了
Reference:
http://blog.csdn.net/myheadfirst/article/details/46635197
keep moving...

 浙公网安备 33010602011771号
浙公网安备 33010602011771号