
复制
## 什么是复制
复制是指分布系统中,多台机器上保持相同副本的机制.
## 多副本能够解决的问题?
1. 地理位置上的副本,能够降低延迟.高性能
2.部分组件失效后,系统依然能够工作,高可用
3.副本能沟通工数据访问服务,从而提高吞吐量.
## 复制中的挑战
1.复制的内容不是一层不变的.数据会一直增加,导致复制一直不能停
2.采用的复制方式是同步的还是异步的.当复制失效的时候如何处理?
## 复制的方式
1.主从复制
2.多主复制
3.无主复制
## 主从方式
多个副本中,分为主副本和从副本.主副本负责接受用户的写入请求.然后将修改内容变为日志或者流发送到从库.从库进行按照顺序来修改.
大多数的关系数据库,非关系数据库,MongoDB,Redis,也支持数据库,MQ消息kafka,RabbitMQ也支持数据库.同时zookeeper也支持数据库等.
主从同步是常用的一种方式.
## 同步复制和异步复制
同步:主节点等待复制到从节点的请求后返回.且不会被打断
异步:主节点不等待主节点复制到从节点的请求,且不会打断.
半异步:多个从节点的时候,保证一个同步,其他从节点异步.
同步: 优势是一致性高,缺点是:吞吐率差
异步: 优势是一致性低,缺点是:吞吐率高
半同步:兼顾两者.
同时系统中提供了一种链式复制的技术.
异步复制带来的问题是:"复制滞后性问题"
## 如何添加一个新节点进来.
添加新节点意味着从头开始进行同步.
一种方式是:
1.生成一个快照版本文件.这个快照版本基于一个事务标号.不同的系统有不同的称呼.(binglog coordinates)或者 log sequence number
2.将这个快照版本文件拷贝到新的从节点中.
3.从节点连接到主节点,获取到 快照版本之后的日志.
4.将获取到的日志在从节点上进行回放.这个过程是追赶.
数据库系统分为两个部分:第一步是备份迁移,第二步是追赶.有的是全自动的,还有一种是手动的.
## 处理失效节点
1.从节点实现:追赶恢复
从节点由于一些原因失效的,发生了重启,然后继续连接上主节点,进行重新追赶.
2.主节点失效: 节点切换
主节点的切换是failover,比较复杂,步骤如下:
1.发现主节点失效:目前有效的只有一种是 心跳+超时?不同的系统 心跳间隔和超时阈值不同
2.确定新的主节点: 可以由多数节点投票选出,或者由其他的一些固定策略来选出
3.其他从节点接受新的主节点:当原的主节点需要接受新的主节点,同时自动降级为从节点.
4.通知客户端新的主节点:客户端需要能够将请求发送到新的主节点中.
其中可能会遇到的情况如下:
1.主节点失效了,重新回来,没有意识到角色的变换.试图发送请求给其他节点.
2.可能会出现数据没有完全同步的问题,导致数据不一致的问题.例如mysql的id自增.
3.发生脑裂,导致集群中同时又两个主节点.这个时候可能会关闭其中一个,或者导致两个都关闭了.
4.这个当中超时时间设置多久,如果设置得过长,发现和恢复问题的时间就太长,如果太短,可能会导致不必要的切换.
## 复制的东西是什么(复制日志的实现)
1. 基于语言的复制,执行的语句是什么,就复制什么.有点是实现起来简单.缺点是其中可能会出现不确定的内容,例如函数中带有now(),触发器啥的.
2.wal日志的复制方式.wal日志记录的对于磁盘文件中的某些位置的修改.这种堆lsm或者是btree类型的数据库都可以.但是缺点是无法不停机升级系统版本.因为不同版本,对于数据的引用和描述可能会有差异.
3.逻辑日志的复制:没有每一行的修改的逻辑数据.但是如果是对于多行的修改,就在日志中添加一个事务的标识来标记事务情况.
4.基于触发器的复制.这个没有遇到过.
## 复制滞后性的问题
很多时候我们无法选择同步复制,因为这样可能会影响到写操作的可用性.往往大多数时候会选择异步复制.这个时候会有复制滞后性的问题.
### 解决思路
1.读自己写一致性
如果写后读的场景不太多的话,可以从主库读
如果写后读很多的话,这里就统计一下一个合适的时间,然后等待合适的时长去从库读
客户端记录住写入返回的时间戳,然后用这个时间戳去从库查询,保证这个时间戳之前的 所有操作都到了.
2.单调读
这种情况是每次读取的数据不会回滚.出现的场景是:读取的数据在多个版本中不同展示.这种情况在看nba的时候可能会出现,比分忽高忽低.
3.前缀一致读
读取的数据可能顺序会不同.例如有两个因果关系的两句话,读取返回的可能会有不同.
对于这种问题:一种解决方案是 将有因果关系的数据交给一个分区来完成.这种方案可能会让性能比较差.(当区域分布在全球各地的时候,可能会比较困难)
有一些happen-before的算法来表示因果关系.
## 多主节点复制
主从复制在很多时候能够解决问题.但是当用户分布在全球的时候,这个时候只有一个主节点的时候,这个时候性能就比较差劲了.
这个时候可以让多个节点作为主节点,可以接收复制.
### 适用场景
单个数据中心使用一个主节点就好.多数据中心的时候需要适用多主节点.
由于多数据中心的高可用和离用户更近的原则,需要在每个数据中心设置一个主节点+冲突解决.内部依然是主从复制.数据中心之间由主节点进行数据合并.
### 多主的缺点
会数据冲突
### 优点
1.性能,离用户更近
2.当一个数据中心失败了,不需要重新确定主节点.有其他的主节点.
3.容忍失败.
多主复制的适用场景:
离线客户端的操作,这种就是每个本地就是主库.然后连上系统后进行同步,解决冲突.
协作编辑:运行多个用户同时编辑文档.先运用在本地,然后同步到其他编辑者哪里.
### 如何解决冲突
1.避免冲突
2.解决冲突(1.分配一个全局的写入Id,后面的覆盖前面的;2.将冲突值进行合并,收敛到一致,3.按照固定的格式,将冲突记录下来,后期交个用户来解决)
### 解决冲突的时机
1.写入解决.在发生冲突的时候,就提示用户,需要解决冲突了.或者调用用户的写入进行解冲突
2.在读取的时候解决,将冲突提示用户.
### 拓扑结构
第一种是环形拓扑结构
第二种是星型拓扑结构
第三种:广播拓扑结构(最常用)
环形解重复通知的方式:在每一条记录中写入每个节点已经处理过的标记信息.避免重复转发.
环形和星型的缺点是:如果一个节点失效了,可能会影响到其他节点.
广播的方式的缺点是:顺序不一样,可能会导致覆盖的问题.
## 无主节点复制
一开始都是无中心复制的系统,后来关系数据库带动了中心复制的潮流.亚马逊的Dynamo数据库重启了无中心复制.
###如何解决冲突:
由于在分布式系统中,互相并不知道对方的情况,但是全局知道互相的顺序.这个时候就需要处理并发合并的问题了.
每一次每个用户添加消息的时候都会分配一个全局的递增的版本号.每个人都是从0开始.
任何一个用户添加一个数值的时候,都会带上自己的版本号,同时自己有的全量的信息.然后讲对应的版本号的值设置为这次提交的值.并将版本号改为当前最大的最.为了理解添加和删除.这里会记录删除,而不是减少一个元素.这样后期可以merge.
这种可以用来类似于多人点菜的这种操作,来解决冲突的实现.
//todo 添加 zk ,mysql ,redis,hbase,hdfs,kafka,rabbitMq,mongodb的复制的具体是如何实现的.
## 常见分布式系统的复制如何实现的?
系统架构,复制语义,复制方式,复制滞后性如何解决.
节点失效(从节点,主节点)
新加入节点是如何处理的.
### hbase中复制是如何发生的
#### Hbase的架构
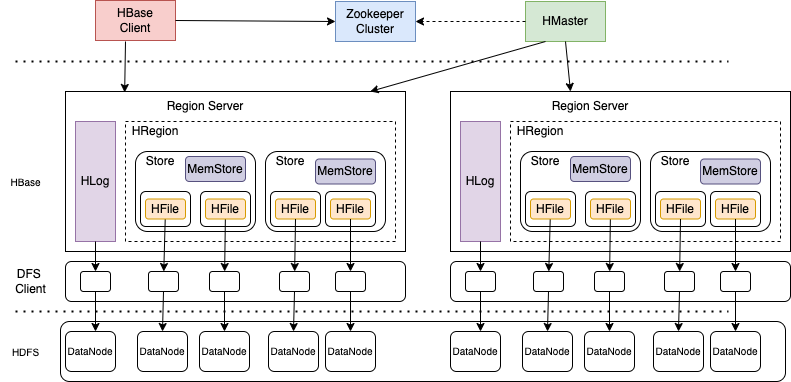
#### hbase的复制对象
写入到HLog中的Entry,进行复制.
#### hbase中是如何进行复制的
hbase的提交是以HLog中的Entry为提交基础的.其中一个RegionServer中包括了多个HLog文件.一个NameSpace(一组表的分组,类似于DataSource)使用一个文件,相对应的日志的执行也是顺序的.
1.当添加一个集群新副本集群的时候,这个时候会启动一个对应的复制线程,这个复制线程负责将对应的HLog文件添加到对应队列中,同时添加一个Listener,当Hlog发生Roll的时候会产生新文件,这个时候,需要将对应的文件添加到Hlog文件队列中.同时持久化到Zk中去.(处理HLog).因为回有很多个HLog.所以复制线程只负责处理HLog的情况.
2.有另外一个线程WALReader线程,从队列中,将对应的HLog读取出来,一次处理,将Entry信息读取出来添加到EntryBatchQueue中来.
3.有一个Shipper线程负责从队列中读取出Entry添加到ReplicationEndpoint中去.这个时候ReplicationEndpoint批量的将信息发送到远端的集群中去.
4.对应的集群将信息收到信息后,更新对应集群的同步的Position信息.
复制的过程: Hlog文件会分割, --> Hlog队列 --> Entry列表 --> Entry队列 --> Endpoint信息.
这个当中为什么需要有两个队列:第一个原因是:HLog需要及时的将状态同步到ZK中,因为有HLog清除队列会清理掉Roll的Hlog文件.
第二个Entry的队列是EndPoint负责发送消息耗时会比较的高.
#### Hbase中如何添加一台新机器到集群中
1.创建一个复制链路,并将复制链路阻塞,此时所有的HLog都会被阻塞在队列中
2.对复制的Talbe创建一个 Snaphot.并用工具将对应SnapShot文件copy到新加入的集群中.
3.将阻塞的复制链路打开,将其中堆积的消息释放出来,并同步到新添加的机器中来.
#### hbase的串行推送的逻辑.
##### 并行推送遇到的问题
当一个Region在RegionServer1的时候,这个时候会有日志在HLog1中,
当时当Region迁移到RegionServer2的时候,这个时候会有日志在HLog2中.
此时HLog1和HLog2同时向新的Peer中同步数据的时候,会出现日志顺序冲突的情况.导致主从不一致的情况.
##### 串行推送的实现
如何解决串行推送的情况:
1.为每一个Region创建一个Barrier列表.当没发生一次迁移的时候,都创建一个Barrier,同时记录一个 全局的LastPushSeqenceId 和每一个RegionServer的 PendingSeqId位置来表示当前RegionServer可以推送的Id值.
定期的去校验 LastPushSequenceId的值和当前 RegionServer可以推送的SequenceId的值.
#### Hbase同步推送的实现
很多时候,对多个副本一致性要求较高的情况下,需要保证两个副本的数据完全一致.这个时候就需要同步复制的实现.
Hbase在写入的过程中添加了一个写入从库的 Remote_WAL的操作.相对的为了打到一致性,整体吞吐率会下降13%.
整个写入的步骤如下:
1.client将写入请你去提交到RegionServer中
2.RegionServer,将数据写入到HLog
3.RegionServer将数据写入到MemStrore
4.RegionServer启动的异步复制线程开始异步同步到远端
5.将数据同步到冲库的RemoteHLog中.
6.从库中收到了主库的异步同步以后,这个时候同步将RemoteHlog中的数据删除.
### Kafka的复制
#### kafka的架构
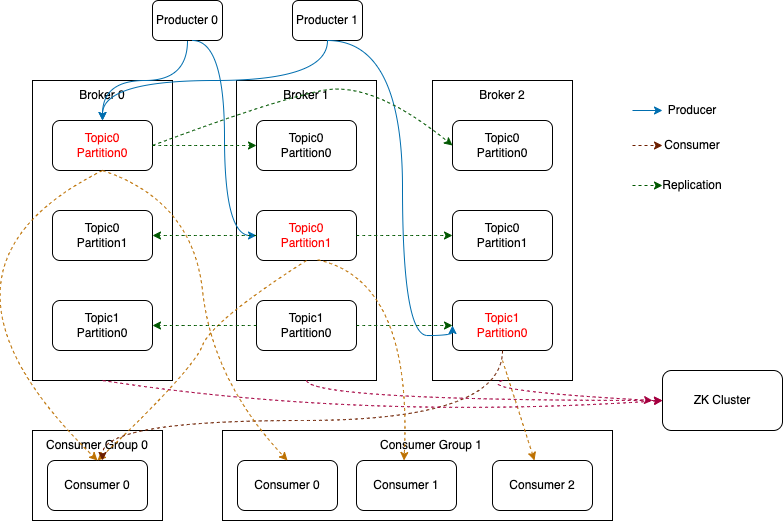
#### kafka的副本
kafka的架构是以topic + partition.其中是以分区作为副本单位的.分区分为 leader分区和folloer分区.这里统一用主分区,从分区来描述.
为了提升系统的可用性,需要将各个分区的副本存放在不同物理节点上,这个物理节点是broker.
分区的同步是异步的.在kafka中将所有的分区统一称为 AR(Available Replica),同时将部分和主节点进度差异不远的节点称为 ISR(In-Sync-Replica).
在每一个分区中标识进度有两个,第一个是 LEO(Log End Offset)标识当前分区收到的最新一条消息的偏移量, HW(High Water).当前ISR中最小的LEO.其中HW表示了当前ISR副本中都已经收到了这些消息.只有HW中的消息,客户端才能后消费.
复制的过程是这样的:主分区负责接受消息,并不断更新LEO,从分区定期的从主分区复制消息.复制的内容中会带上当前分区的LEO.主分区将最新的消息以及HW同步给从分区.从分区更新消息和LEO以及HW.主分区负责维护所有ISR节点的LEO,并实时的更新HW.
##### ISR的伸缩
ISR的减少
ISR和AR的切换.:ISR是用当前分区最近一次追上主分区时间和当前时间的差的差小于一个阈值 replca.lag.max.mils(默认是10s).如果大于从副本就失效了.早期也用过落后的offset来统计,但是效果不好,阈值不太好拿捏.
这个事情是由Kafka启动的时候,启动一个定时任务来处理的,这个定时任务的触发时间是 replica.lag.max.mills的时间的一半.当检查到以副本从ISR中移到了AVR中的时候,这个时候就首先更新zk中的/replica的元数据,主要是从节点的情况.然后想 isr_changeSet中记录变更后的ISR数据.
有一个通知的定时任务,会定时(时间是2.5秒)的消费isr_changeSet中的事件.然后在zk的isr-chang-notification路径下创建一个事件.因为各个Broker的中有一个副本管理器添加了watcher.当发现对应ISR改变的时候,会修改对应的主节点的ISR信息,这样会影响到HW的设置,和客户端可消费进度.
可能会有抖动,所以只有在出现ISR变更的同事满足一下两个条件才修改目标节点中的ISR进度.第一点是:上一次ISR集合变化时间已经超过了5s;上一次写入zk的元数据的时间已经超过了60秒.
ISR的增加
当用指令添加新的副本到AR中来的时候,会不断的从主节点中同步状态,当新副本的LEO超过了主节点的HW的时候,就变更为ISR.这种情况依然会更新 /broker/topic/{topicId}/pration/{partionId}/state中副本信息.然后添加到ISRChangeSet中去.
##### 引入 leader Epoch
最开始的时候,当主从的发生切换的时候.将HW到LEO(HW,LEO)区间中的消息都丢掉的时候,可能会丢掉很多消息.其实只要发生消息切换都会丢失消息切换.或者会发生消息错乱.
这个时候添加一个 leader epoch --> startOffset的数据. 其中维护了所有的leader epoch 对应的 startOffset.当一个节点新启动的时候,会去主副本中获取到 offsetForLeaderEpoch的信息.拿到后,根据当前有的信息,会截断超过当前副本的epoch的信息.
##### kafka为什么不用副本
1.kafka的读写比差距不大
2.kafka的主从会有一定复制延迟.且hw的结算是慢一点的
3.kafka使用了预读,会把数据读取到内存中来处理.如果每个副本都来一套,这样会浪费broker的物理资源
4.实现起来会有些费劲,比只用主节点复杂一点.
kafka的复制比较的飘逸.非常的优秀.考虑的比较的多.
//todo mongoDB的实现
//zk的实现.
// mysql的复制
//hdfs的复制
//redis的复制

 浙公网安备 33010602011771号
浙公网安备 33010602011771号