


Mysql事务
一、Mysql事务
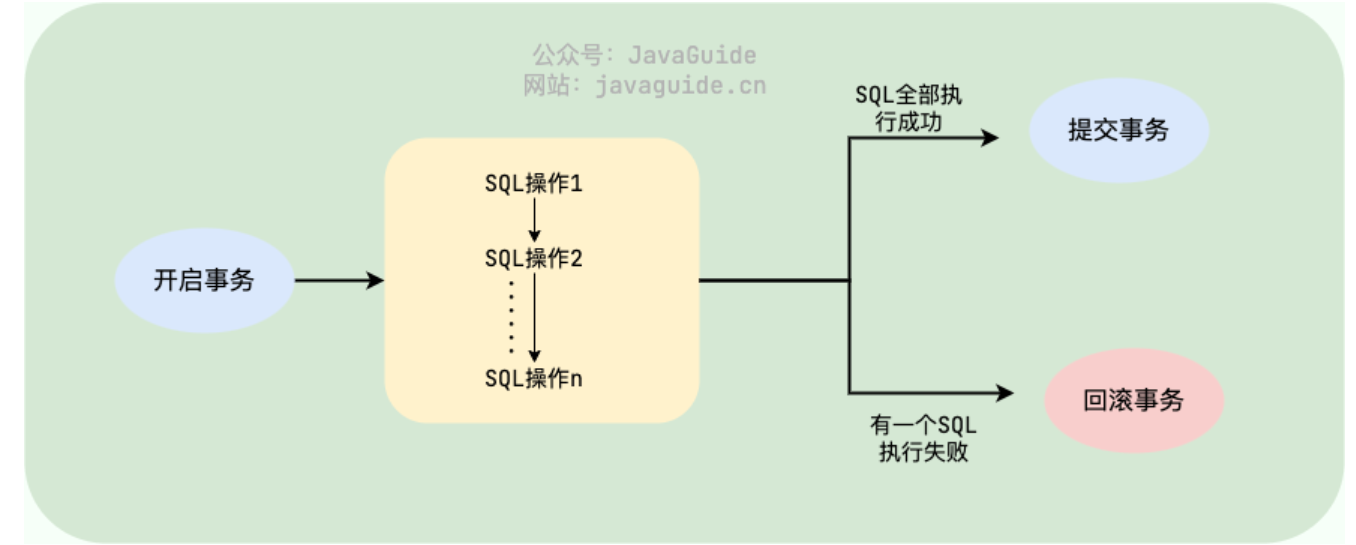
何为事务? 一言蔽之,事务是逻辑上的一组操作,要么都执行,要么都不执行。
- 数据库中途突然因为某些原因挂掉了。
- 客户端突然因为网络原因连接不上数据库了。
- 并发访问数据库时,多个线程同时写入数据库,覆盖了彼此的更改。
- ......
上面的任何一个问题都可能会导致数据的不一致性。为了保证数据的一致性,系统必须能够处理这些问题。事务就是我们抽象出来简化这些问题的首选机制。事务的概念起源于数据库,目前,已经成为一个比较广泛的概念。
1、ACID
- 原子性(
Atomicity) : 事务是最小的执行单位,不允许分割。事务的原子性确保动作要么全部完成,要么完全不起作用; - 一致性(
Consistency): 执行事务前后,数据保持一致,例如转账业务中,无论事务是否成功,转账者和收款人的总额应该是不变的; - 隔离性(
Isolation): 并发访问数据库时,一个用户的事务不被其他事务所干扰,各并发事务之间数据库是独立的; - 持久性(
Durabilily): 一个事务被提交之后。它对数据库中数据的改变是持久的,即使数据库发生故障也不应该对其有任何影响。
🌈 这里要额外补充一点:只有保证了事务的持久性、原子性、隔离性之后,一致性才能得到保障。也就是说 A、I、D 是手段,C 是目的!(DDIA 也就是 《Designing Data-Intensive Application(数据密集型应用系统设计)》)
2、并发事务带来了哪些问题?(不考虑事务的隔离)
在典型的应用程序中,多个事务并发运行,经常会操作相同的数据来完成各自的任务(多个用户对同一数据进行操作)。并发虽然是必须的,但可能会导致以下的问题。
- 脏读(Dirty read): 当一个事务正在访问数据并且对数据进行了修改,而这种修改还没有提交到数据库中,这时另外一个事务也访问了这个数据,然后使用了这个数据。因为这个数据是还没有提交的数据并进行了回滚在提交,那么另外一个事务读到的这个数据是“脏数据”,依据“脏数据”所做的操作可能是不正确的。
- 丢失修改(Lost to modify): 指在一个事务读取一个数据时,另外一个事务也访问了该数据,那么在第一个事务中修改了这个数据后,第二个事务也修改了这个数据。这样第一个事务内的修改结果就被丢失,因此称为丢失修改。 例如:事务 1 读取某表中的数据 A=20,事务 2 也读取 A=20,事务 1 修改 A=A-1,事务 2 也修改 A=A-1,最终结果 A=19,事务 1 的修改被丢失。
- 不可重复读(Unrepeatable read): 指在一个事务内多次读同一数据。在这个事务还没有结束时,另一个事务也访问该数据。那么,在第一个事务中的两次读数据之间,由于第二个事务的修改导致第一个事务两次读取的数据可能不太一样。这就发生了在一个事务内两次读到的数据是不一样的情况,因此称为不可重复读。(通过行级锁可以实现可重复读的隔离级别)
- 幻读(Phantom read): 幻读与不可重复读类似。它发生在一个事务(T1)读取了几行数据,接着另一个并发事务(T2)插入了一些数据时。在随后的查询中,第一个事务(T1)就会发现多了一些原本不存在的记录,就好像发生了幻觉一样,所以称为幻读。(只能通过Serializable隔离级别来实现)
不可重复读和幻读有什么区别呢?
- 不可重复读的重点是内容修改或者记录减少比如多次读取一条记录发现其中某些记录的值被修改;
- 幻读的重点在于记录新增比如多次执行同一条查询语句(DQL)时,发现查到的记录增加了。
幻读其实可以看作是不可重复读的一种特殊情况,单独把区分幻读的原因主要是解决幻读和不可重复读的方案不一样。
举个例子:执行 delete 和 update 操作的时候,可以直接对记录加锁,保证事务安全。而执行 insert 操作的时候,由于记录锁(Record Lock)只能锁住已经存在的记录,为了避免插入新记录,需要依赖间隙锁(Gap Lock)。也就是说执行 insert 操作的时候需要依赖 Next-Key Lock(Record Lock+Gap Lock) 进行加锁来保证不出现幻读。
3、SQL 标准定义了哪些事务隔离级别?
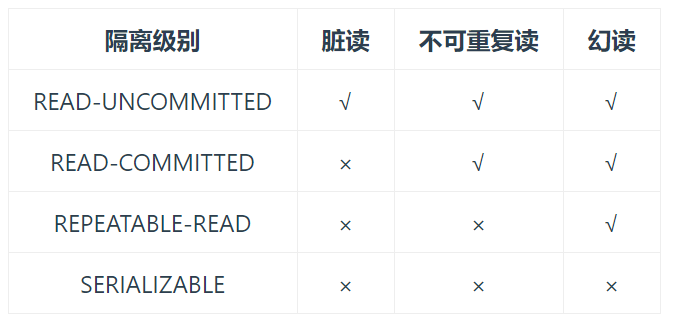
SQL 标准定义了四个隔离级别:
- READ-UNCOMMITTED(读取未提交) : 最低的隔离级别,允许读取尚未提交的数据变更,可能会导致脏读、幻读或不可重复读。
- READ-COMMITTED(读取已提交) : 允许读取并发事务已经提交的数据,可以阻止脏读,但是幻读或不可重复读仍有可能发生。
- REPEATABLE-READ(可重复读) : 对同一字段的多次读取结果都是一致的,除非数据是被本身事务自己所修改,可以阻止脏读和不可重复读,但幻读仍有可能发生。
-
SERIALIZABLE(可串行化) : 最高的隔离级别,完全服从 ACID 的隔离级别。所有的事务依次逐个执行,这样事务之间就完全不可能产生干扰,也就是说,该级别可以防止脏读、不可重复读以及幻读。
![]()
4、MySQL 的隔离级别是基于锁实现的吗?
MySQL 的隔离级别基于锁和 MVCC (多版本并发控制)机制共同实现的。
SERIALIZABLE 隔离级别,是通过锁来实现的。除了 SERIALIZABLE 隔离级别,其他的隔离级别都是基于 MVCC 实现。
不过, SERIALIZABLE 之外的其他隔离级别可能也需要用到锁机制,就比如 REPEATABLE-READ 在当前读情况下需要使用加锁读来保证不会出现幻读。
5、MySQL 的默认隔离级别是什么?
MySQL InnoDB 存储引擎的默认支持的隔离级别是 REPEATABLE-READ(可重读)。我们可以通过SELECT @@tx_isolation;命令来查看,MySQL 8.0 该命令改为SELECT @@transaction_isolation;
二、Mysql锁
1、表级锁和行级锁了解吗?有什么区别?
MyISAM 仅仅支持表级锁(table-level locking),一锁就锁整张表,这在并发写的情况下性非常差。
InnoDB 不光支持表级锁(table-level locking),还支持行级锁(row-level locking),默认为行级锁。行级锁的粒度更小,仅对相关的记录上锁即可(对一行或者多行记录加锁),所以对于并发写入操作来说, InnoDB 的性能更高。
表级锁和行级锁对比 :
- 表级锁: MySQL 中锁定粒度最大的一种锁,是针对非索引字段加的锁,对当前操作的整张表加锁,实现简单,资源消耗也比较少,加锁快,不会出现死锁。其锁定粒度最大,触发锁冲突的概率最高,并发度最低,MyISAM 和 InnoDB 引擎都支持表级锁。
- 行级锁: MySQL 中锁定粒度最小的一种锁,是针对索引字段加的锁,只针对当前操作的行记录进行加锁。 行级锁能大大减少数据库操作的冲突。其加锁粒度最小,并发度高,但加锁的开销也最大,加锁慢,会出现死锁。
行级锁的使用有什么注意事项?
InnoDB 的行锁是针对索引字段加的锁,表级锁是针对非索引字段加的锁。当我们执行 UPDATE、DELETE 语句时,如果 WHERE条件中字段没有命中唯一索引或者索引失效的话,就会导致扫描全表对表中的所有行记录进行加锁。这个在我们日常工作开发中经常会遇到,一定要多多注意!!!
不过,很多时候即使用了索引也有可能会走全表扫描,这是MySQL 优化器的原因。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号