hashmap详解
哈希表
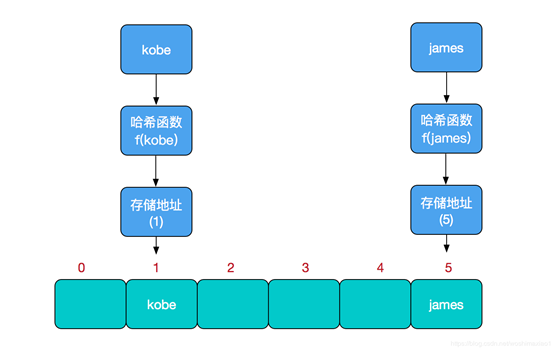
哈希表是根据关键码值(key,value)而直接进行访问的数据结构。根据key值计算出该元素的存储位置。若不存在哈希冲突,在哈希表中进行查找、删除以及增加等操作时间复杂度都是O(1)。
哈希冲突
当不同元素采用哈希函数计算得到的地址相同。即两个不同的key值计算得到了相同的地址,则为哈希冲突。
通常会用一个指针数组(table[])来分散所有的key,当一个Key被加入时,一个哈希函数会根据这个key值计算出下标地址i,然后根据i值把<key,value>置入table[]数组中。如果有两个不同的key值计算出了相同一个i,那么就叫哈希冲突或者哈希碰撞。在该table[i]上生成一个链表。因此如果table[]长度很小时,如果要放入多个key值,会频繁的产生哈希碰撞。时间复杂度O(1)也会变成链表查询O(n)。
JDK 1.7 hashmap问题
1.死锁问题
在jdk 1.7中,当更新hash表长度时,需要把原来表中的数据复制到新表,但扩容时并没有定义各个元素插入的顺序。当两个线程同时扩容hashmap时,可能会导致出现环形链表,导致死锁。比如线程一当前为key3,next为key7。线程二可能当前为key7,next为key3。会出现环形链表,导致死锁。
JDK7 情况下,hashmap 数组加链表的经典实现会出现多线程情况下环形链表,导致死锁。
2.哈希冲突
哈希冲突可能会导致hashmap变成链表。
hashmap源码
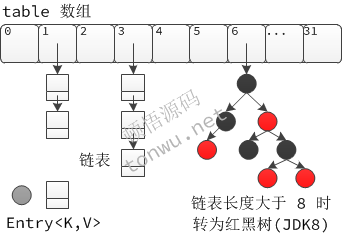
JDK1.8 之前 HashMap 由 数组+链表 组成的,数组是 HashMap 的主体,链表则是主要为了解决哈希冲突而存在的(“拉链法”解决冲突).JDK1.8 以后在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为 8)时,将链表转化为红黑树,以减少搜索时间。
https://www.cnblogs.com/wskwbog/p/10907457.html
在hashmap中,Node<K,V> table 为哈希桶。如果哈希桶数组很大,即使较差的Hash算法也会比较分散,如果哈希桶数组数组很小,即使好的Hash算法也会出现较多碰撞。在hashmap中,初始容量定义为16,负载因子为0.75,阈值为初始容量*负载因子=12。在默认情况下,当插入的<key,value>超过12时,hashmap会自动扩容。
hashmap扩容机制
当元素超过阈值时,会扩容到原来的两倍。在jdk1.7中会重新计算hash值,但在jdk1.8中,不需要重新计算hash值。return h & (length-1) ,元素要么在原位置,要么在原位置移动2次幂的位置。图(a)表示扩容前的key1和key2两种key确定索引位置的示例,图(b)表示扩容后key1和key2两种key确定索引位置的示例,
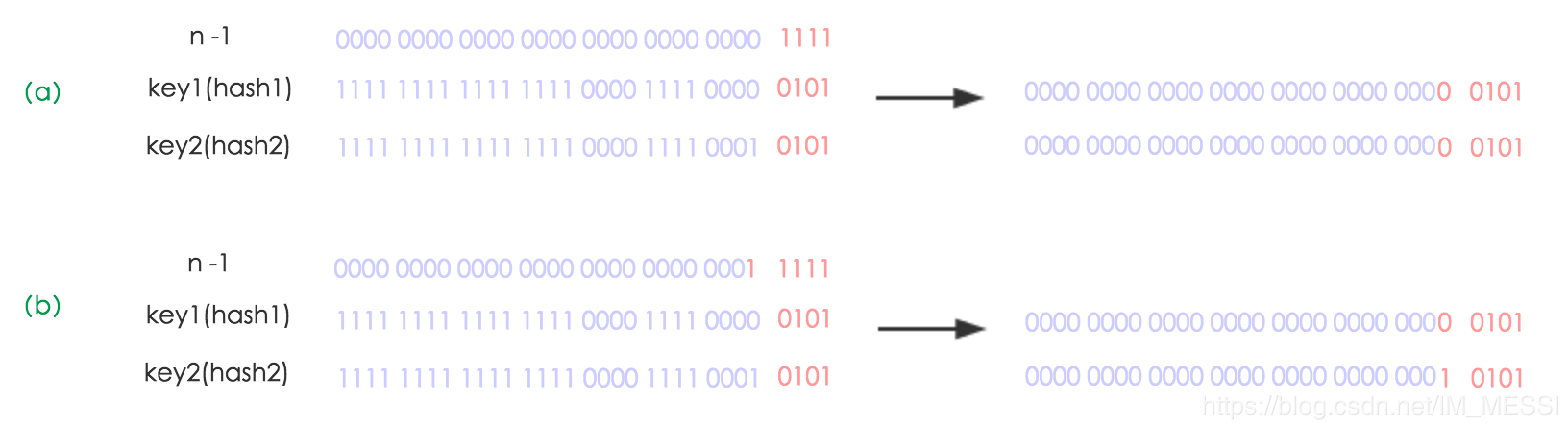
先length是16 length-1 = 01111 当扩容后length-1变成 11111,所以观察原hash值新增的那个bit位是1还是0就好了,是0的话索引没有变,是1的话索引变成“原索引+oldCap(旧数组大小)”。
hashmap jdk1.8优化
- 由数组+链表——数组+链表+红黑树
当链表元素数量超过8个时,改变为红黑树。查找时间复杂度为O(logn)。当链表元素个数小于6个时,为链表。
- jdk1.7对hashcode进行二次加工为
h ^= (h >>> 20) ^ (h >>> 12); return h ^ (h >>> 7) ^ (h >>> 4);
- jdk1.8为 return h ^ (h >>> 16); 优化了高位运算的hash算法,将高16位于低16位进行异或。速度加快。
- jdk1.8进行扩容时,不需要重新计算hash值,只是根据原hash值新增的bit值,bit值为0时放进原索引位置,为1时放进原索引加原来的数组长度。
- 尾插法所以新数组链表不会倒置,在多线程的情况下并不会出现死循环。
Hashmap的容量为什么是2的n次幂以及为什么扩容时2倍?
因为在放置元素以及扩容时,是按照hash&length-1进行的。&是按位与运算,比较高效。另外length-1的二进制形式为11111....11111,按照此形式能够充分的散列,避免哈希冲突。
当HashMap的容量是16时,它的二进制是10000,(n-1)的二进制是01111,与hash值得计算结果如下:
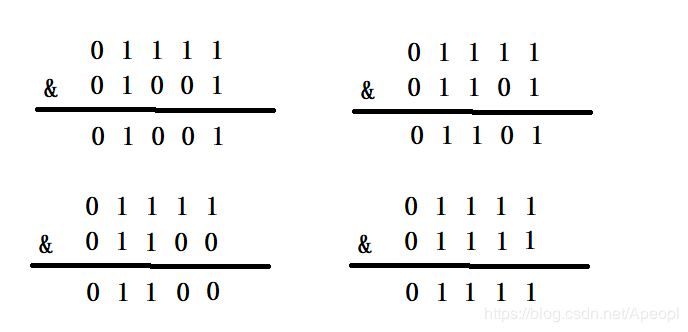
可见不同的hash值与其进行与运算后会得到不同的值,来进行散列。当容量不为2n,当容量为10时,二进制为01010,(n-1)的二进制是01001,结果为:
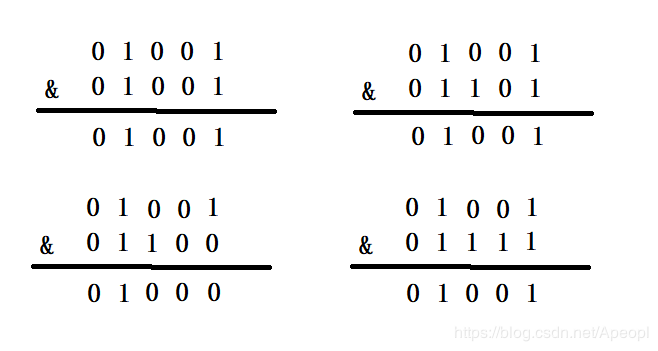
明显会产生严重的hash冲突。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号