随笔记录知识
 随时记录知识
随时记录知识
1.SVM
1.1 概念
SVM(Support Vector Machine,支持向量机)是一种监督学习算法,主要用于分类任务(也可用于回归,称为 SVR)。
其核心思想是:在特征空间中找到一个最优超平面,将不同类别的样本分隔开,并且使这个超平面与最近的样本点(称为 “支持向量”)之间的间隔最大化。
1.2 工作原理(How)
- 线性可分情况:直接寻找能最大化分类间隔的超平面。
- 线性不可分情况:通过核函数将数据映射到更高维度的特征空间,使其在高维空间中线性可分,再寻找最优超平面。常见核函数包括:
- 线性核(Linear):
K(x, y) = x·y - 多项式核(Polynomial):
K(x, y) = (γx·y + r)^d - 高斯核(RBF,径向基函数):
K(x, y) = exp(-γ||x-y||²)(最常用)
- 线性核(Linear):
1.3 使用场景与示例(When & Where)
SVM 适合小样本、高维度的数据分类,例如文本分类、图像识别、基因数据分析等。
2.图片中无法加载中文
在代码中加入下面的代码即可解决
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei', 'DejaVu Sans', 'Arial'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
或者写一个函数,在使用的时候调用这个函数也可以
import matplotlib.pyplot as plt
#设置matplotlib支持中文显示(如果系统有中文字体)
def setup_plot_fonts():
"""设置图表字体"""
try:
plt.rcParams['font.sans-serif'] = ['SimHei', 'DejaVu Sans', 'Arial'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
except:
plt.rcParams['font.sans-serif'] = ['DejaVu Sans', 'Arial']
plt.rcParams['axes.unicode_minus'] = False
3.蒙特卡洛树搜索(MCTS)全面介绍
蒙特卡洛树搜索(Monte Carlo Tree Search,简称MCTS)是一种基于“随机采样+树结构迭代优化”的启发式决策算法,核心价值在于通过“试错式探索”逐步构建搜索树,动态平衡“利用已知高价值区域”与“探索潜在最优区域”,尤其适用于状态空间庞大、先验知识不足的复杂决策问题。其本质是通过有限的随机模拟,高效逼近问题的最优解,已在棋类AI、函数优化、路径规划等多个领域广泛应用。
一、核心组成:蒙特卡洛树的节点结构
MCTS的搜索过程围绕“树结构”展开,树中每个节点对应问题的一个“状态/区间”,节点的核心属性决定了搜索方向,典型属性如下(以函数最大值搜索场景为例):
- 状态标识:节点对应的具体问题状态,如函数搜索中的“x值区间”(如[-5.00,5.00]),棋类游戏中的“棋盘布局”。
- 价值(Value,分子):节点状态的“优质程度”量化指标,函数搜索中为该区间内采样到的最大函数值(如4.00),棋类游戏中为该布局的胜率期望。
- 访问次数(Visits,分母):节点被搜索过程选中的次数(如5次),反映该状态的“探索充分程度”。
- 父子/子节点关系:父节点状态可分解为多个子节点状态(如区间分裂),形成树的层级结构,根节点为初始状态,叶子节点为未扩展的终端状态。
节点的“价值/访问次数”(如4/5)是MCTS决策的核心依据,直接体现状态的“潜力”与“探索度”。
二、核心流程:四步迭代循环
MCTS通过“选择→扩展→模拟→回溯”四步循环迭代,逐步细化搜索树,实现从“全局粗搜”到“局部精搜”的收敛,每一步的逻辑紧密衔接:
1. 选择(Selection):找最值得探索的节点
从根节点出发,依据UCB公式(上置信界准则)遍历树,选择“最值得探索”的节点,平衡“利用”与“探索”:
UCB公式:UCB = 节点价值 + C × √[ln(父节点访问次数)/节点访问次数]
- 利用(Exploitation):优先选择“价值高”的节点(如函数值接近4的区间),聚焦已知优质区域;
- 探索(Exploration):优先选择“访问次数少”的节点(如访问次数为0的新节点),避免遗漏潜在最优解;
- 系数C:调节探索与利用的权重(通常取2),C越大越倾向探索。
例:在函数搜索中,会优先选择“价值3.99且访问3次”的节点,而非“价值1.2且访问5次”的节点。
2. 扩展(Expansion):细化未充分探索的节点
当选择到“叶子节点”且该节点状态有细化空间(如区间长度大于阈值)时,将其分裂为多个子节点,每个子节点对应原状态的一个细分状态:
例:将区间[0.00,2.50](叶子节点)分裂为[0.00,1.25]和[1.25,2.50]两个子节点,使搜索范围更精准。若节点为终端状态(如区间足够小),则直接进入模拟步骤。
3. 模拟(Simulation):随机试错得临时结果
对新扩展的子节点(或未扩展的叶子节点),通过“随机采样”模拟一次完整的决策过程,得到该节点的“临时价值”:
例:在区间[0.00,1.25]内随机采样x=1.0,计算函数值y=4.00,该值即为节点的临时价值。模拟过程无需复杂策略,核心是快速获取状态的“粗略评估”。
4. 回溯(Backpropagation):更新路径上所有节点
将模拟得到的“临时价值”反向传递至“当前节点→根节点”的所有路径节点,更新两个核心属性:
- 访问次数:所有路径节点的访问次数+1,标记该路径已被探索;
- 节点价值:若临时价值大于节点当前价值,则更新为临时价值(如将节点价值从3.99更新为4.00)。
回溯的作用是“记忆”优质状态,让后续搜索更倾向于高价值路径。
三、核心特点:为何MCTS如此高效?
- 无需先验知识:不依赖问题的数学模型(如函数解析表达式)或领域经验,仅通过随机采样即可迭代优化,适用于“黑箱问题”;
- 自适应聚焦:通过UCB公式自动向高价值区域倾斜搜索资源,低价值区域(如函数值为负的区间)仅被少量探索,搜索效率远高于“全局均匀采样”;
- 迭代收敛性:迭代次数越多,搜索树越完善,结果越接近理论最优解,可根据精度需求灵活控制迭代次数;
- 内存高效:仅存储已探索的节点,无需预存整个状态空间,适用于状态爆炸的复杂问题(如围棋的10^170状态)。
四、典型应用场景
- 棋类与游戏AI:AlphaGo的核心算法之一,通过MCTS探索棋步组合,结合深度学习优化价值评估,实现超越人类的决策水平;
- 函数与参数优化:如寻找复杂函数的最大值/最小值(如你之前接触的y=-x²+2x+3),尤其适用于非凸、高维函数;
- 路径规划:在动态环境中(如自动驾驶)搜索最优路径,平衡路径长度、安全性等多目标;
- 机器人决策:机器人在未知环境中选择动作(如抓取、移动),通过MCTS评估动作的成功率;
- 组合优化:如旅行商问题(TSP)、调度问题,在离散状态空间中寻找最优解。
五、局限与优化方向
1. 局限
- 低迭代次数时结果不稳定:随机采样的随机性可能导致短期结果波动,需足够迭代次数才能收敛;
- 终端模拟效率低:对长流程问题(如多步棋类),随机模拟的评估精度低,需结合领域模型优化;
- 高维状态空间适配性差:状态维度过高时,节点分裂会导致树结构爆炸,需降维或剪枝策略。
2. 常见优化
- 结合深度学习:用神经网络预测节点价值和子节点选择概率(如AlphaGo的策略网络),减少随机模拟的开销;
- 节点剪枝:删除低价值的冗余节点,减少内存占用;
- 并行计算:同时进行多组四步循环,加速搜索树构建。
六、总结
蒙特卡洛树搜索的核心逻辑是“通过随机试错积累经验,用数学准则引导搜索方向”,其“选择-扩展-模拟-回溯”四步循环是高效收敛的关键。节点的“价值/访问次数”直观反映状态潜力,UCB公式平衡探索与利用,使MCTS在复杂、高维、缺乏先验知识的问题中展现出独特优势。从函数优化到棋类AI,MCTS的应用场景持续拓展,是人工智能领域极具影响力的决策算法之一。
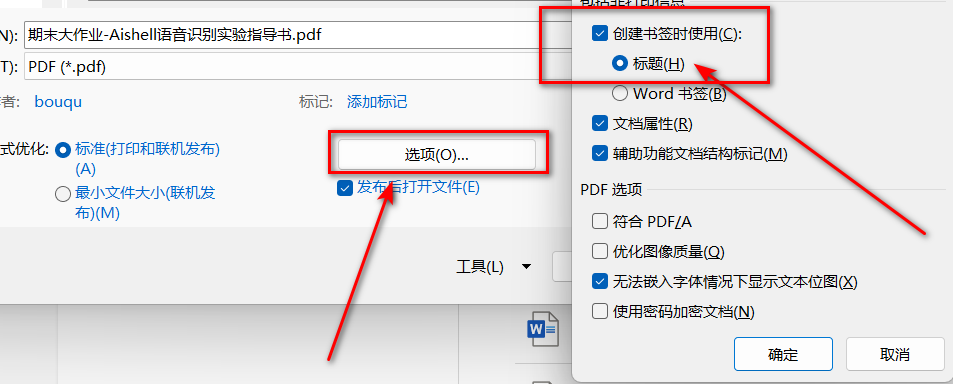
4.word导出pdf有导航
导出时,点击【选项】-【创建书签时使用】--【标题】,导出后的pdf文件就有了导航栏
5.BLEU指标
一、BLEU 是什么?
- 全称:Bilingual Evaluation Understudy(双语评估替补)
- 核心目的:自动评估机器翻译结果与专业人工翻译之间的相似度。
- 提出背景:在 BLEU 提出之前,评估机器翻译的质量主要依赖人工,这非常耗时、昂贵且主观。BLEU 的提出旨在提供一个快速、廉价、客观且与人工评价高度相关的自动评估方法。
- 核心思想:“越像人翻译的,质量就越好”。BLEU 通过计算机器翻译的输出与一个或多个参考翻译(由专业人士提供)之间的相似度来给出一个分数。
二、为什么需要 BLEU?
- 加速研发周期:在模型训练和调优过程中,研究人员需要快速知道每次改动是让翻译结果变好还是变坏。如果每次都靠人工评估,效率极低。BLEU 可以在几分钟甚至几秒钟内给出反馈。
- 客观统一:人工评估会受到评估者情绪、偏好等因素影响。BLEU 提供了一个统一的、可重复的数值标准,便于在不同系统之间进行比较。
- 学术界的标准:它已经成为机器翻译领域论文中事实上的标准评估指标,几乎所有相关研究都会报告 BLEU 值,以便与其他工作进行比较。
三、BLEU 是如何计算的?
BLEU 的计算主要基于两个概念:精确度 和 brevity penalty(过短惩罚)。它不是简单的字词匹配,而是考虑了 n-gram 的匹配。
计算步骤:
- n-gram 精确度
-
- 首先,我们不仅看单个单词(1-gram)是否出现,还要看连续的词组(2-gram, 3-gram, 4-gram)是否匹配。
- 例如,计算 1-gram 精确度:统计机器翻译输出中所有出现在任何一句参考翻译中的单词,然后除以机器翻译输出的总单词数。
- 但这样有个问题:如果机器翻译重复输出同一个正确的单词,它的精确度会被人为抬高。例如,输出 “the the the the”,而参考翻译是 “The cat is on the mat.”。其中 “the” 出现了很多次。
- 因此,BLEU 使用了 修正的 n-gram 精确度:对于机器输出中的每个单词,它的计数不得超过它在任何一条参考翻译中出现的最大次数。在上面的例子里,“the” 在参考翻译中最多出现了 2 次,那么机器输出中 “the” 的计数也只能算 2 次。
- 综合 n-gram 分数
-
- 我们会分别计算出 1-gram, 2-gram, 3-gram, 4-gram 的修正精确度(记为 P1, P2, P3, P4)。
- 然后把这些精确度几何平均并取对数,再取指数,得到一个综合分数:
BP · exp(⅟4 · (log P1 + log P2 + log P3 + log P4)) - 为什么用几何平均?因为它对各个 n-gram 的权重一视同仁,而算术平均会被较高的 1-gram 精确度主导。
- 过短惩罚
-
- 如果机器翻译的输出非常短,它很容易获得很高的 n-gram 精确度。比如,只输出参考翻译中的一个词 “The”,那么 1-gram 精确度就是 100%,但这显然不是好的翻译。
- 因此,当机器输出的长度(c)小于最接近的参考翻译的长度(r)时,会施加一个惩罚因子 BP:
-
-
- 如果
c > r,BP = 1(不惩罚) - 如果
c <= r,BP = exp(1 - r/c)
- 如果
-
-
- 输出越短,惩罚越重。
最终,BLEU 的输出是一个 0 到 1 之间的数值(有时也表示为百分比)。越接近 1,表示机器翻译的结果与参考翻译越相似。
四、一个简单的例子
假设:
- 参考翻译1:The cat is sitting on the mat.
- 参考翻译2:There is a cat sitting on the mat.
- 机器翻译输出:The cat the cat on the mat.
我们来计算它的 BLEU 分数(简化过程):
- 1-gram 精确度 (P1):
-
- 输出单词:
the, cat, the, cat, on, the, mat-> 共 7 个词。 - 匹配的单词:
the(在参考1中最多出现2次,所以计数为2),cat(最多出现1次,计数为1),on(出现1次),mat(出现1次)。注意:the在输出中出现了3次,但只能按2次计算。 - 所以匹配总数 = 2(
the) + 1(cat) + 1(on) + 1(mat) = 5。 - P1 = 5 / 7 ≈ 0.714
- 输出单词:
- 2-gram 精确度 (P2):
-
- 输出 2-grams:
the cat,cat the,the cat,cat on,on the,the mat。 - 只有
the cat和on the在参考翻译中出现过。the cat出现了2次,但只能算1次(参考中最多出现1次)。 - 匹配总数 = 1(
the cat) + 1(on the) = 2。 - 总 2-grams 数 = 6。
- P2 = 2 / 6 ≈ 0.333
- 输出 2-grams:
- 过短惩罚 (BP):
-
- 输出长度 c = 7。
- 参考翻译1长度 = 7, 参考翻译2长度 = 8。最接近的长度 r = 7。
- 因为 c = r, 所以 BP = 1。
- 综合 BLEU 分数:
-
- 我们只算到 2-gram 来简化:
BLEU = BP · exp((log(P1) + log(P2))/2) BLEU ≈ 1 · exp((log(0.714) + log(0.333))/2) ≈ exp((-0.337 -1.100)/2) ≈ exp(-0.718) ≈ 0.488
- 我们只算到 2-gram 来简化:
所以,这个输出的 BLEU 分大约在 0.49 左右。
五、BLEU 的优缺点
优点:
- 高效快捷:计算速度远快于人工评估。
- 成本低廉:几乎零成本。
- 客观一致:给定相同的输入,结果永远相同。
- 与人工评价相关:在语料库级别(即大量句子的平均分)上,BLEU 与人类对翻译质量的判断有很高的相关性。
缺点和批评:
- 不考虑语义:BLEU 只衡量表面字词的重叠,不理解句子的含义。一个意思正确但用词完全不同的句子可能得零分。
- 不考虑语法:一个 BLEU 分很高的句子可能在语法上完全不通顺。
- 对语言特性不敏感:它不考虑同义词、词形变化等。例如,输出 “goes” 而参考是 “went” 会被算作错误。
- 不擅长处理单个句子:BLEU 是为评估整个测试集(成百上千个句子)的平均质量而设计的。在单个句子上,它的得分可能很不稳定,且与人工判断相关性较低。
- 依赖参考翻译的质量和数量:如果参考翻译本身不佳或只有一条,BLEU 的可靠性会下降。
六、总结
BLEU 是 NLP 发展史上的一个里程碑式的指标。它虽然不是完美的,存在诸多局限性,但其开创性的思路和巨大的实用性使其至今仍是机器翻译领域不可或缺的工具。理解 BLEU 对于从事机器翻译、文本生成等领域的任何人来说都是至关重要的。
在使用时,要牢记:BLEU 是一个有用的仆人,但不是一个可靠的主人。它非常适合在模型开发中进行快速迭代和横向比较,但最终的系统评估仍然需要结合人工判断和其他更先进的评估方法。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号