13-损失函数与反向传播
 本章主要介绍损失函数和反向传播的使用
本章主要介绍损失函数和反向传播的使用
1. 损失函数
① Loss损失函数一方面计算实际输出和目标之间的差距。
② Loss损失函数另一方面为我们更新输出提供一定的依据。
2. L1loss损失函数
① L1loss数学公式如下图所示,例子如下下图所示。

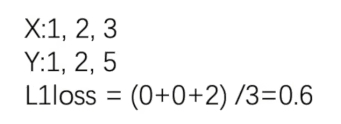
import torch
from torch.nn import L1Loss
inputs = torch.tensor([1,2,3],dtype=torch.float32)
targets = torch.tensor([1,2,5],dtype=torch.float32)
inputs = torch.reshape(inputs,(1,1,1,3))
targets = torch.reshape(targets,(1,1,1,3))
loss = L1Loss() # 默认为 maen
result = loss(inputs,targets)
print(result)
tensor(0.6667)
import torch
from torch.nn import L1Loss
inputs = torch.tensor([1,2,3],dtype=torch.float32)
targets = torch.tensor([1,2,5],dtype=torch.float32)
inputs = torch.reshape(inputs,(1,1,1,3))
targets = torch.reshape(targets,(1,1,1,3))
loss = L1Loss(reduction='sum') # 修改为sum,三个值的差值,然后取和
result = loss(inputs,targets)
print(result)
tensor(2.)
3. MSE损失函数
① MSE损失函数数学公式如下图所示。

import torch
from torch.nn import L1Loss
from torch import nn
inputs = torch.tensor([1,2,3],dtype=torch.float32)
targets = torch.tensor([1,2,5],dtype=torch.float32)
inputs = torch.reshape(inputs,(1,1,1,3))
targets = torch.reshape(targets,(1,1,1,3))
loss_mse = nn.MSELoss()
result_mse = loss_mse(inputs,targets)
print(result_mse)
tensor(1.3333)
4. 交叉熵损失函数
① 交叉熵损失函数数学公式如下图所示。
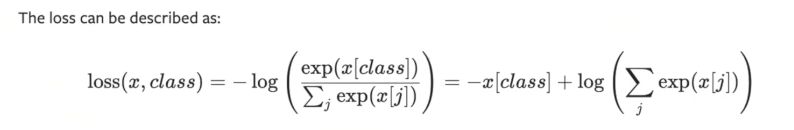
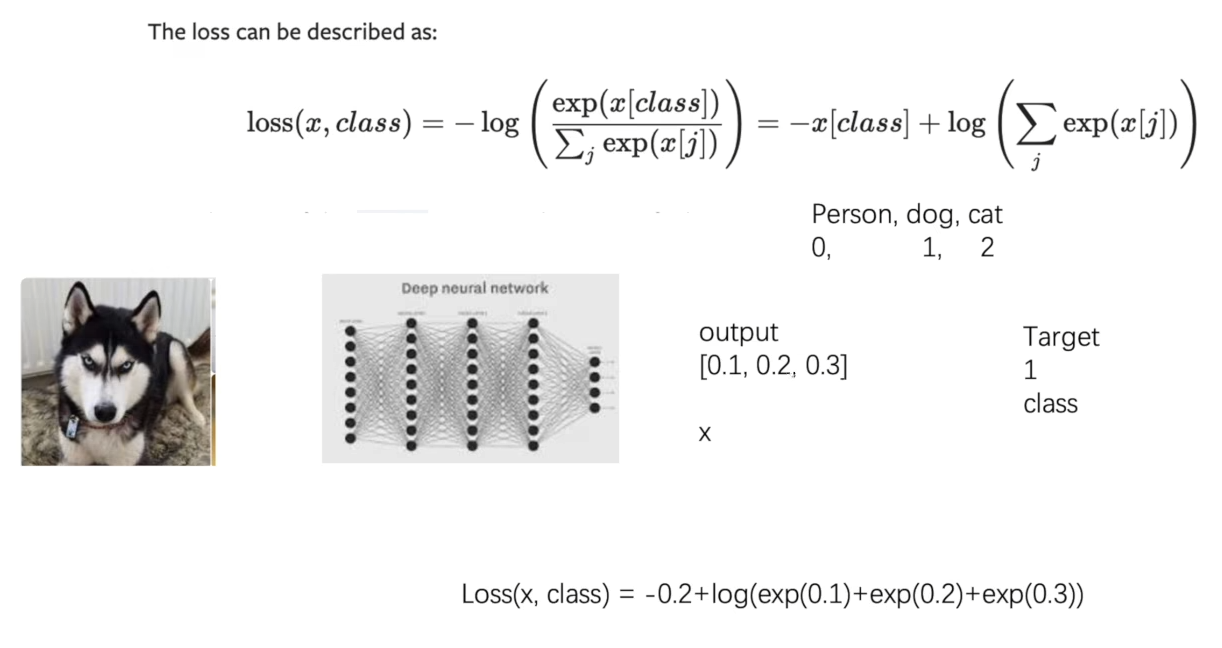
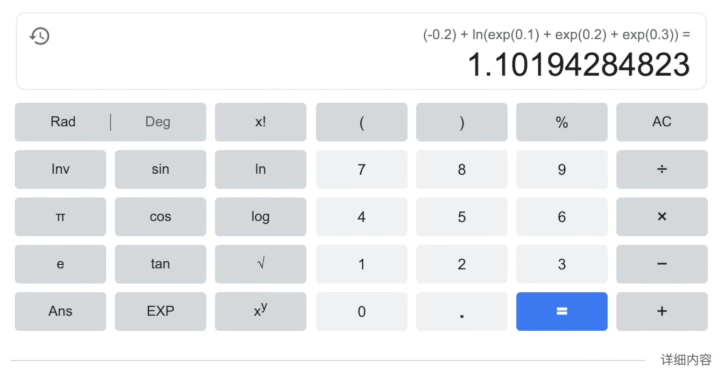
import torch
from torch.nn import L1Loss
from torch import nn
x = torch.tensor([0.1,0.2,0.3])
y = torch.tensor([1])
x = torch.reshape(x,(1,3)) # 1的 batch_size,有三类
loss_cross = nn.CrossEntropyLoss()
result_cross = loss_cross(x,y)
print(result_cross)
tensor(1.1019)
5. 搭建神经网络
import torch
import torchvision
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10("./dataset",train=False,transform=torchvision.transforms.ToTensor(),download=True)
dataloader = DataLoader(dataset, batch_size=1,drop_last=True)
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.model1 = Sequential(
Conv2d(3,32,5,padding=2),
MaxPool2d(2),
Conv2d(32,32,5,padding=2),
MaxPool2d(2),
Conv2d(32,64,5,padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024,64),
Linear(64,10)
)
def forward(self, x):
x = self.model1(x)
return x
tudui = Tudui()
for data in dataloader:
imgs, targets = data
outputs = tudui(imgs)
print(outputs)
print(targets)
Files already downloaded and verified
tensor([[-0.1256, -0.1614, -0.0474, -0.0409, 0.0259, -0.1314, -0.1198, -0.0682,
-0.1246, -0.1217]], grad_fn=<AddmmBackward0>)
tensor([3])
tensor([[-0.1278, -0.1590, -0.0487, -0.0508, 0.0202, -0.1075, -0.0921, -0.0896,
-0.1443, -0.1351]], grad_fn=<AddmmBackward0>)
tensor([8])
tensor([[-0.1186, -0.1567, -0.0528, -0.0613, 0.0136, -0.1183, -0.0932, -0.0849,
-0.1402, -0.1259]], grad_fn=<AddmmBackward0>)
tensor([8])
tensor([[-0.1269, -0.1612, -0.0489, -0.0636, 0.0117, -0.1156, -0.0884, -0.0865,
-0.1429, -0.1252]], grad_fn=<AddmmBackward0>)
tensor([0])
tensor([[-0.1267, -0.1545, -0.0428, -0.0409, 0.0202, -0.1402, -0.1139, -0.0693,
-0.1246, -0.1261]], grad_fn=<AddmmBackward0>)
tensor([6])
tensor([[-0.1218, -0.1509, -0.0433, -0.0226, 0.0247, -0.1093, -0.1307, -0.0773,
-0.1250, -0.1148]], grad_fn=<AddmmBackward0>)
tensor([6])
tensor([[-0.1175, -0.1661, -0.0200, -0.0216, 0.0403, -0.1204, -0.0925, -0.0690,
-0.1076, -0.1219]], grad_fn=<AddmmBackward0>)
tensor([1])
tensor([[-0.1274, -0.1585, -0.0466, -0.0366, 0.0189, -0.1274, -0.1266, -0.0731,
-0.1236, -0.1056]], grad_fn=<AddmmBackward0>)
tensor([6])
tensor([[-0.1226, -0.1648, -0.0610, -0.0536, 0.0237, -0.1352, -0.1083, -0.0587,
-0.1397, -0.1293]], grad_fn=<AddmmBackward0>)
tensor([3])
tensor([[-0.1212, -0.1440, -0.0480, -0.0478, 0.0247, -0.1004, -0.0845, -0.0927,
-0.1450, -0.1103]], grad_fn=<AddmmBackward0>)
tensor([1])
tensor([[-0.1309, -0.1570, -0.0568, -0.0564, 0.0183, -0.1257, -0.1078, -0.0642,
-0.1439, -0.1277]], grad_fn=<AddmmBackward0>)
tensor([0])
tensor([[-0.1077, -0.1609, -0.0311, -0.0440, 0.0310, -0.1114, -0.1070, -0.0995,
-0.1300, -0.1111]], grad_fn=<AddmmBackward0>)
tensor([9])
tensor([[-0.1226, -0.1537, -0.0421, -0.0342, 0.0253, -0.1308, -0.1092, -0.0697,
-0.1278, -0.1258]], grad_fn=<AddmmBackward0>)
tensor([5])
tensor([[-0.1232, -0.1516, -0.0323, -0.0389, 0.0146, -0.1201, -0.1123, -0.0699,
-0.1315, -0.1234]], grad_fn=<AddmmBackward0>)
tensor([7])
tensor([[-0.1152, -0.1759, -0.0368, -0.0246, 0.0398, -0.1116, -0.1142, -0.0924,
-0.1383, -0.1161]], grad_fn=<AddmmBackward0>)
tensor([9])
tensor([[-0.1221, -0.1710, -0.0589, -0.0644, 0.0144, -0.1282, -0.1062, -0.0704,
-0.1431, -0.1295]], grad_fn=<AddmmBackward0>)
tensor([8])
tensor([[-0.1187, -0.1746, -0.0539, -0.0542, 0.0305, -0.1147, -0.1383, -0.0772,
-0.1379, -0.0984]], grad_fn=<AddmmBackward0>)
tensor([5])
tensor([[-0.1258, -0.1635, -0.0496, -0.0357, 0.0359, -0.1233, -0.1045, -0.0749,
-0.1390, -0.1145]], grad_fn=<AddmmBackward0>)
tensor([7])
tensor([[-0.1225, -0.1366, -0.0441, -0.0508, 0.0201, -0.0954, -0.0909, -0.1079,
-0.1505, -0.1168]], grad_fn=<AddmmBackward0>)
tensor([8])
tensor([[-0.1254, -0.1434, -0.0434, -0.0332, 0.0344, -0.1151, -0.1287, -0.0606,
-0.1336, -0.1187]], grad_fn=<AddmmBackward0>)
tensor([6])
tensor([[-0.1094, -0.1510, -0.0290, -0.0317, 0.0440, -0.1047, -0.0928, -0.0822,
-0.1347, -0.1067]], grad_fn=<AddmmBackward0>)
tensor([7])
tensor([[-0.1221, -0.1825, -0.0374, -0.0700, 0.0211, -0.1297, -0.0816, -0.0851,
-0.1662, -0.1258]], grad_fn=<AddmmBackward0>)
tensor([0])
tensor([[-0.1263, -0.1471, -0.0424, -0.0346, 0.0274, -0.1253, -0.0980, -0.0809,
-0.1234, -0.1176]], grad_fn=<AddmmBackward0>)
tensor([4])
tensor([[-0.1041, -0.1541, -0.0365, -0.0256, 0.0472, -0.1037, -0.1165, -0.0900,
-0.1332, -0.1072]], grad_fn=<AddmmBackward0>)
tensor([9])
tensor([[-0.1260, -0.1505, -0.0422, -0.0420, 0.0271, -0.1167, -0.0958, -0.0696,
-0.1511, -0.1189]], grad_fn=<AddmmBackward0>)
tensor([5])
tensor([[-0.1315, -0.1589, -0.0469, -0.0392, 0.0237, -0.1134, -0.1137, -0.0835,
-0.1391, -0.1114]], grad_fn=<AddmmBackward0>)
tensor([2])
tensor([[-0.1237, -0.1630, -0.0434, -0.0283, 0.0310, -0.1174, -0.1258, -0.0745,
-0.1328, -0.1010]], grad_fn=<AddmmBackward0>)
tensor([4])
tensor([[-0.1225, -0.1509, -0.0488, -0.0479, 0.0244, -0.1125, -0.0882, -0.0956,
-0.1454, -0.1062]], grad_fn=<AddmmBackward0>)
tensor([0])
tensor([[-0.1245, -0.1512, -0.0332, -0.0294, 0.0428, -0.1038, -0.1036, -0.0971,
-0.1413, -0.1075]], grad_fn=<AddmmBackward0>)
tensor([9])
tensor([[-0.1252, -0.1393, -0.0469, -0.0215, 0.0278, -0.1156, -0.1093, -0.0802,
-0.1158, -0.1047]], grad_fn=<AddmmBackward0>)
tensor([6])
tensor([[-0.1235, -0.1323, -0.0388, -0.0139, 0.0388, -0.1146, -0.1099, -0.0776,
-0.1113, -0.1039]], grad_fn=<AddmmBackward0>)
tensor([6])
tensor([[-0.1166, -0.1517, -0.0444, -0.0333, 0.0222, -0.1178, -0.0961, -0.0788,
-0.1379, -0.1137]], grad_fn=<AddmmBackward0>)
tensor([5])
tensor([[-0.1272, -0.1624, -0.0555, -0.0450, 0.0264, -0.1286, -0.1142, -0.0632,
-0.1337, -0.1216]], grad_fn=<AddmmBackward0>)
tensor([4])
tensor([[-0.1225, -0.1664, -0.0399, -0.0295, 0.0262, -0.1197, -0.1303, -0.0751,
-0.1359, -0.1044]], grad_fn=<AddmmBackward0>)
tensor([5])
tensor([[-0.1302, -0.1304, -0.0432, -0.0302, 0.0359, -0.0957, -0.0713, -0.0990,
-0.1333, -0.1181]], grad_fn=<AddmmBackward0>)
tensor([9])
tensor([[-0.1275, -0.1868, -0.0453, -0.0352, 0.0182, -0.1452, -0.1307, -0.0617,
-0.1160, -0.1275]], grad_fn=<AddmmBackward0>)
tensor([2])
tensor([[-0.1179, -0.1421, -0.0482, -0.0414, 0.0210, -0.1183, -0.1012, -0.0772,
-0.1309, -0.1180]], grad_fn=<AddmmBackward0>)
tensor([4])
tensor([[-0.1286, -0.1622, -0.0549, -0.0662, 0.0222, -0.0999, -0.1112, -0.0764,
-0.1522, -0.1182]], grad_fn=<AddmmBackward0>)
tensor([1])
tensor([[-0.1175, -0.1486, -0.0418, -0.0337, 0.0255, -0.0982, -0.1069, -0.0869,
-0.1494, -0.1059]], grad_fn=<AddmmBackward0>)
tensor([9])
tensor([[-0.1313, -0.1584, -0.0458, -0.0510, 0.0158, -0.1352, -0.1135, -0.0694,
-0.1428, -0.1304]], grad_fn=<AddmmBackward0>)
tensor([5])
tensor([[-0.1281, -0.1710, -0.0381, -0.0487, 0.0164, -0.1144, -0.0941, -0.0999,
-0.1553, -0.1237]], grad_fn=<AddmmBackward0>)
tensor([4])
tensor([[-0.1241, -0.1383, -0.0407, -0.0075, 0.0367, -0.1165, -0.1280, -0.0769,
-0.1169, -0.1014]], grad_fn=<AddmmBackward0>)
tensor([6])
tensor([[-0.1202, -0.1504, -0.0396, -0.0264, 0.0305, -0.1174, -0.0945, -0.0944,
-0.1141, -0.1188]], grad_fn=<AddmmBackward0>)
tensor([5])
tensor([[-0.1234, -0.1696, -0.0374, -0.0331, 0.0295, -0.1284, -0.1252, -0.0708,
-0.1169, -0.0991]], grad_fn=<AddmmBackward0>)
tensor([6])
tensor([[-0.1399, -0.1446, -0.0465, -0.0542, 0.0311, -0.1092, -0.1004, -0.0914,
-0.1619, -0.1139]], grad_fn=<AddmmBackward0>)
tensor([0])
tensor([[-0.1363, -0.1602, -0.0574, -0.0523, 0.0230, -0.1163, -0.1003, -0.0711,
-0.1439, -0.1269]], grad_fn=<AddmmBackward0>)
tensor([9])
tensor([[-0.1198, -0.1429, -0.0465, -0.0309, 0.0375, -0.1282, -0.0960, -0.0725,
-0.1247, -0.1334]], grad_fn=<AddmmBackward0>)
tensor([3])
tensor([[-0.1256, -0.1470, -0.0431, -0.0336, 0.0304, -0.1213, -0.0977, -0.0707,
-0.1236, -0.1199]], grad_fn=<AddmmBackward0>)
tensor([9])
tensor([[-0.1269, -0.1463, -0.0541, -0.0331, 0.0299, -0.1212, -0.1126, -0.0708,
-0.1399, -0.1121]], grad_fn=<AddmmBackward0>)
tensor([7])
tensor([[-0.1236, -0.1405, -0.0449, -0.0229, 0.0258, -0.1186, -0.1084, -0.0756,
-0.1244, -0.1083]], grad_fn=<AddmmBackward0>)
tensor([6])
tensor([[-0.1349, -0.1592, -0.0465, -0.0401, 0.0161, -0.1175, -0.0877, -0.0946,
-0.1346, -0.1274]], grad_fn=<AddmmBackward0>)
tensor([9])
tensor([[-0.1293, -0.1516, -0.0467, -0.0350, 0.0297, -0.1058, -0.1112, -0.0819,
-0.1361, -0.1159]], grad_fn=<AddmmBackward0>)
tensor([8])
tensor([[-0.1171, -0.1566, -0.0423, -0.0199, 0.0289, -0.1192, -0.1231, -0.0705,
-0.1278, -0.1172]], grad_fn=<AddmmBackward0>)
tensor([0])
tensor([[-0.1180, -0.1438, -0.0374, -0.0287, 0.0381, -0.1024, -0.1027, -0.0864,
-0.1163, -0.1106]], grad_fn=<AddmmBackward0>)
tensor([3])
tensor([[-0.1283, -0.1576, -0.0557, -0.0619, 0.0131, -0.1090, -0.0922, -0.0852,
-0.1373, -0.1214]], grad_fn=<AddmmBackward0>)
tensor([8])
tensor([[-0.1303, -0.1445, -0.0563, -0.0490, 0.0148, -0.1129, -0.0991, -0.0761,
-0.1414, -0.1262]], grad_fn=<AddmmBackward0>)
tensor([8])
tensor([[-0.1243, -0.1721, -0.0463, -0.0375, 0.0361, -0.1230, -0.1268, -0.0771,
-0.1340, -0.1348]], grad_fn=<AddmmBackward0>)
tensor([7])
tensor([[-0.1082, -0.1452, -0.0374, -0.0319, 0.0206, -0.1279, -0.1202, -0.0817,
-0.1216, -0.1166]], grad_fn=<AddmmBackward0>)
tensor([7])
tensor([[-0.1292, -0.1648, -0.0546, -0.0479, 0.0225, -0.1200, -0.1174, -0.0719,
-0.1357, -0.1231]], grad_fn=<AddmmBackward0>)
tensor([4])
tensor([[-0.1350, -0.1697, -0.0309, -0.0450, 0.0308, -0.1253, -0.1128, -0.0918,
-0.1271, -0.1097]], grad_fn=<AddmmBackward0>)
tensor([6])
tensor([[-0.1307, -0.1591, -0.0501, -0.0407, 0.0214, -0.1232, -0.1125, -0.0713,
-0.1402, -0.1171]], grad_fn=<AddmmBackward0>)
tensor([7])
tensor([[-0.1214, -0.1507, -0.0391, -0.0169, 0.0354, -0.1199, -0.1092, -0.0684,
-0.1303, -0.1203]], grad_fn=<AddmmBackward0>)
tensor([3])
tensor([[-0.1223, -0.1657, -0.0366, -0.0205, 0.0285, -0.1331, -0.1248, -0.0615,
-0.1201, -0.1261]], grad_fn=<AddmmBackward0>)
tensor([6])
tensor([[-0.1172, -0.1406, -0.0356, -0.0449, 0.0357, -0.1077, -0.0814, -0.1030,
-0.1340, -0.1167]], grad_fn=<AddmmBackward0>)
tensor([3])
tensor([[-0.1263, -0.1558, -0.0473, -0.0252, 0.0244, -0.1149, -0.1142, -0.0721,
-0.1325, -0.1109]], grad_fn=<AddmmBackward0>)
tensor([6])
tensor([[-0.1236, -0.1599, -0.0454, -0.0284, 0.0297, -0.1272, -0.1178, -0.0750,
-0.1245, -0.1135]], grad_fn=<AddmmBackward0>)
tensor([2])
tensor([[-0.1165, -0.1574, -0.0414, -0.0328, 0.0123, -0.1058, -0.1146, -0.0846,
-0.1480, -0.1126]], grad_fn=<AddmmBackward0>)
tensor([1])
tensor([[-0.1236, -0.1834, -0.0557, -0.0632, 0.0312, -0.1359, -0.0924, -0.0802,
-0.1561, -0.1215]], grad_fn=<AddmmBackward0>)
tensor([2])
tensor([[-0.1193, -0.1480, -0.0396, -0.0175, 0.0506, -0.1092, -0.1074, -0.0875,
-0.1199, -0.1148]], grad_fn=<AddmmBackward0>)
tensor([3])
tensor([[-0.1235, -0.1555, -0.0455, -0.0351, 0.0304, -0.1053, -0.1010, -0.0957,
-0.1335, -0.1197]], grad_fn=<AddmmBackward0>)
tensor([7])
tensor([[-0.1378, -0.1529, -0.0590, -0.0461, 0.0340, -0.1096, -0.1127, -0.0718,
-0.1476, -0.1224]], grad_fn=<AddmmBackward0>)
tensor([2])
tensor([[-0.1240, -0.1494, -0.0453, -0.0277, 0.0239, -0.1221, -0.1242, -0.0800,
-0.1212, -0.1054]], grad_fn=<AddmmBackward0>)
tensor([6])
tensor([[-0.1289, -0.1581, -0.0518, -0.0483, 0.0183, -0.1098, -0.1036, -0.0755,
-0.1489, -0.1298]], grad_fn=<AddmmBackward0>)
tensor([8])
tensor([[-0.1231, -0.1440, -0.0546, -0.0551, 0.0175, -0.1225, -0.0971, -0.0781,
-0.1359, -0.1232]], grad_fn=<AddmmBackward0>)
tensor([8])
tensor([[-0.1219, -0.1313, -0.0446, -0.0305, 0.0334, -0.0887, -0.0883, -0.1025,
-0.1545, -0.1033]], grad_fn=<AddmmBackward0>)
tensor([0])
tensor([[-0.1251, -0.1542, -0.0416, -0.0334, 0.0427, -0.1159, -0.0978, -0.0632,
-0.1340, -0.1166]], grad_fn=<AddmmBackward0>)
tensor([2])
tensor([[-0.1183, -0.1669, -0.0487, -0.0520, 0.0200, -0.1113, -0.1097, -0.0950,
-0.1372, -0.1183]], grad_fn=<AddmmBackward0>)
tensor([9])
tensor([[-0.1157, -0.1488, -0.0449, -0.0585, 0.0108, -0.1375, -0.0951, -0.0765,
-0.1313, -0.1343]], grad_fn=<AddmmBackward0>)
tensor([3])
tensor([[-0.1154, -0.1439, -0.0324, -0.0401, 0.0303, -0.1268, -0.1075, -0.0731,
-0.1161, -0.1206]], grad_fn=<AddmmBackward0>)
tensor([3])
tensor([[-0.1380, -0.1498, -0.0655, -0.0652, 0.0165, -0.0988, -0.0843, -0.0903,
-0.1702, -0.1296]], grad_fn=<AddmmBackward0>)
tensor([8])
tensor([[-0.1245, -0.1498, -0.0603, -0.0668, 0.0179, -0.1186, -0.0847, -0.0779,
-0.1474, -0.1207]], grad_fn=<AddmmBackward0>)
tensor([8])
tensor([[-0.1168, -0.1449, -0.0354, -0.0221, 0.0122, -0.1211, -0.1084, -0.0785,
-0.1220, -0.1134]], grad_fn=<AddmmBackward0>)
tensor([1])
tensor([[-0.1252, -0.1567, -0.0469, -0.0140, 0.0255, -0.1284, -0.0953, -0.0736,
-0.1280, -0.1234]], grad_fn=<AddmmBackward0>)
tensor([1])
tensor([[-0.1380, -0.1632, -0.0518, -0.0740, 0.0322, -0.1211, -0.0968, -0.0824,
-0.1473, -0.1214]], grad_fn=<AddmmBackward0>)
tensor([7])
tensor([[-0.1208, -0.1639, -0.0639, -0.0613, 0.0261, -0.1200, -0.0906, -0.0598,
-0.1507, -0.1215]], grad_fn=<AddmmBackward0>)
tensor([2])
tensor([[-0.1149, -0.1616, -0.0326, -0.0460, 0.0285, -0.1192, -0.0921, -0.1111,
-0.1333, -0.1067]], grad_fn=<AddmmBackward0>)
tensor([5])
tensor([[-0.1187, -0.1662, -0.0403, -0.0551, 0.0197, -0.1302, -0.0941, -0.0849,
-0.1305, -0.1328]], grad_fn=<AddmmBackward0>)
tensor([2])
tensor([[-0.1234, -0.1595, -0.0549, -0.0688, 0.0035, -0.1117, -0.0789, -0.0765,
-0.1583, -0.1455]], grad_fn=<AddmmBackward0>)
tensor([7])
tensor([[-0.1191, -0.1484, -0.0571, -0.0605, 0.0168, -0.1018, -0.0837, -0.0803,
-0.1588, -0.1186]], grad_fn=<AddmmBackward0>)
tensor([8])
tensor([[-0.1210, -0.1471, -0.0451, -0.0429, 0.0235, -0.1068, -0.1050, -0.0891,
-0.1479, -0.1165]], grad_fn=<AddmmBackward0>)
tensor([9])
tensor([[-0.1250, -0.1628, -0.0494, -0.0501, 0.0212, -0.1210, -0.0939, -0.0800,
-0.1459, -0.1309]], grad_fn=<AddmmBackward0>)
tensor([0])
tensor([[-0.1214, -0.1578, -0.0458, -0.0194, 0.0324, -0.1198, -0.1152, -0.0754,
-0.1236, -0.1220]], grad_fn=<AddmmBackward0>)
tensor([3])
tensor([[-0.1319, -0.1555, -0.0585, -0.0642, 0.0160, -0.1158, -0.0933, -0.0778,
-0.1442, -0.1278]], grad_fn=<AddmmBackward0>)
tensor([8])
tensor([[-0.1261, -0.1353, -0.0419, -0.0358, 0.0291, -0.1165, -0.0877, -0.0808,
-0.1368, -0.1087]], grad_fn=<AddmmBackward0>)
tensor([6])
tensor([[-0.1239, -0.1398, -0.0391, -0.0284, 0.0274, -0.1188, -0.1065, -0.0759,
-0.1247, -0.1137]], grad_fn=<AddmmBackward0>)
tensor([4])
tensor([[-0.1242, -0.1557, -0.0396, -0.0284, 0.0301, -0.1176, -0.1119, -0.0834,
-0.1324, -0.1232]], grad_fn=<AddmmBackward0>)
tensor([6])
tensor([[-0.1138, -0.1545, -0.0521, -0.0281, 0.0193, -0.1238, -0.1218, -0.0732,
-0.1323, -0.1079]], grad_fn=<AddmmBackward0>)
tensor([6])
tensor([[-0.1285, -0.1568, -0.0494, -0.0531, 0.0215, -0.1265, -0.1017, -0.0740,
-0.1361, -0.1241]], grad_fn=<AddmmBackward0>)
tensor([0])
tensor([[-0.1448, -0.1704, -0.0385, -0.0573, 0.0444, -0.1197, -0.0804, -0.0999,
-0.1477, -0.1223]], grad_fn=<AddmmBackward0>)
tensor([0])
tensor([[-0.1292, -0.1364, -0.0416, -0.0428, 0.0479, -0.1044, -0.0831, -0.0820,
-0.1464, -0.1262]], grad_fn=<AddmmBackward0>)
tensor([7])
tensor([[-0.1336, -0.1568, -0.0538, -0.0484, 0.0263, -0.1264, -0.1177, -0.0735,
-0.1309, -0.1194]], grad_fn=<AddmmBackward0>)
tensor([4])
tensor([[-0.1278, -0.1589, -0.0561, -0.0429, 0.0262, -0.1182, -0.1174, -0.0758,
-0.1408, -0.1137]], grad_fn=<AddmmBackward0>)
tensor([5])
tensor([[-0.1208, -0.1564, -0.0324, -0.0271, 0.0311, -0.1286, -0.1268, -0.0869,
-0.1206, -0.1271]], grad_fn=<AddmmBackward0>)
tensor([6])
tensor([[-0.1269, -0.1622, -0.0573, -0.0427, 0.0214, -0.1085, -0.1206, -0.0879,
-0.1411, -0.1108]], grad_fn=<AddmmBackward0>)
tensor([3])
tensor([[-0.1257, -0.1703, -0.0305, -0.0382, 0.0137, -0.1247, -0.1078, -0.0862,
-0.1311, -0.1204]], grad_fn=<AddmmBackward0>)
tensor([1])
tensor([[-0.1298, -0.1612, -0.0590, -0.0594, 0.0171, -0.0986, -0.0918, -0.0863,
-0.1696, -0.1425]], grad_fn=<AddmmBackward0>)
tensor([1])
tensor([[-0.1166, -0.1768, -0.0469, -0.0312, 0.0290, -0.1289, -0.1120, -0.0677,
-0.1205, -0.1165]], grad_fn=<AddmmBackward0>)
tensor([3])
tensor([[-0.1209, -0.1468, -0.0501, -0.0226, 0.0244, -0.1187, -0.1159, -0.0794,
-0.1188, -0.1118]], grad_fn=<AddmmBackward0>)
tensor([6])
tensor([[-0.1133, -0.1678, -0.0541, -0.0554, 0.0281, -0.1230, -0.1224, -0.0745,
-0.1357, -0.1116]], grad_fn=<AddmmBackward0>)
tensor([8])
tensor([[-0.1412, -0.1821, -0.0267, -0.0587, 0.0293, -0.1372, -0.1417, -0.0916,
-0.1174, -0.1340]], grad_fn=<AddmmBackward0>)
tensor([7])
tensor([[-0.1186, -0.1463, -0.0488, -0.0166, 0.0367, -0.1075, -0.1304, -0.0647,
-0.1315, -0.1124]], grad_fn=<AddmmBackward0>)
tensor([4])
tensor([[-0.1267, -0.1719, -0.0574, -0.0550, 0.0225, -0.1333, -0.1071, -0.0659,
-0.1500, -0.1165]], grad_fn=<AddmmBackward0>)
tensor([0])
6. 数据集计算损失函数
import torch
import torchvision
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10("./dataset",train=False,transform=torchvision.transforms.ToTensor(),download=True)
dataloader = DataLoader(dataset, batch_size=64,drop_last=True)
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.model1 = Sequential(
Conv2d(3,32,5,padding=2),
MaxPool2d(2),
Conv2d(32,32,5,padding=2),
MaxPool2d(2),
Conv2d(32,64,5,padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024,64),
Linear(64,10)
)
def forward(self, x):
x = self.model1(x)
return x
loss = nn.CrossEntropyLoss() # 交叉熵
tudui = Tudui()
for data in dataloader:
imgs, targets = data
outputs = tudui(imgs)
result_loss = loss(outputs, targets) # 计算实际输出与目标输出的差距
print(result_loss)
Files already downloaded and verified
tensor(2.2994, grad_fn=<NllLossBackward0>)
tensor(2.2952, grad_fn=<NllLossBackward0>)
tensor(2.3162, grad_fn=<NllLossBackward0>)
tensor(2.3234, grad_fn=<NllLossBackward0>)
tensor(2.2983, grad_fn=<NllLossBackward0>)
tensor(2.3051, grad_fn=<NllLossBackward0>)
tensor(2.2991, grad_fn=<NllLossBackward0>)
tensor(2.3084, grad_fn=<NllLossBackward0>)
tensor(2.3059, grad_fn=<NllLossBackward0>)
tensor(2.3066, grad_fn=<NllLossBackward0>)
tensor(2.2939, grad_fn=<NllLossBackward0>)
tensor(2.3037, grad_fn=<NllLossBackward0>)
tensor(2.2835, grad_fn=<NllLossBackward0>)
tensor(2.2898, grad_fn=<NllLossBackward0>)
tensor(2.3043, grad_fn=<NllLossBackward0>)
tensor(2.3290, grad_fn=<NllLossBackward0>)
tensor(2.2848, grad_fn=<NllLossBackward0>)
tensor(2.3043, grad_fn=<NllLossBackward0>)
tensor(2.3056, grad_fn=<NllLossBackward0>)
tensor(2.3195, grad_fn=<NllLossBackward0>)
tensor(2.3193, grad_fn=<NllLossBackward0>)
tensor(2.3130, grad_fn=<NllLossBackward0>)
tensor(2.3068, grad_fn=<NllLossBackward0>)
tensor(2.2979, grad_fn=<NllLossBackward0>)
tensor(2.3035, grad_fn=<NllLossBackward0>)
tensor(2.3011, grad_fn=<NllLossBackward0>)
tensor(2.3147, grad_fn=<NllLossBackward0>)
tensor(2.3126, grad_fn=<NllLossBackward0>)
tensor(2.3177, grad_fn=<NllLossBackward0>)
tensor(2.3124, grad_fn=<NllLossBackward0>)
tensor(2.2949, grad_fn=<NllLossBackward0>)
tensor(2.3179, grad_fn=<NllLossBackward0>)
tensor(2.3062, grad_fn=<NllLossBackward0>)
tensor(2.3132, grad_fn=<NllLossBackward0>)
tensor(2.3004, grad_fn=<NllLossBackward0>)
tensor(2.3095, grad_fn=<NllLossBackward0>)
tensor(2.3018, grad_fn=<NllLossBackward0>)
tensor(2.3118, grad_fn=<NllLossBackward0>)
tensor(2.3170, grad_fn=<NllLossBackward0>)
tensor(2.2988, grad_fn=<NllLossBackward0>)
tensor(2.2960, grad_fn=<NllLossBackward0>)
tensor(2.2833, grad_fn=<NllLossBackward0>)
tensor(2.3189, grad_fn=<NllLossBackward0>)
tensor(2.2927, grad_fn=<NllLossBackward0>)
tensor(2.2946, grad_fn=<NllLossBackward0>)
tensor(2.3104, grad_fn=<NllLossBackward0>)
tensor(2.3118, grad_fn=<NllLossBackward0>)
tensor(2.3017, grad_fn=<NllLossBackward0>)
tensor(2.3059, grad_fn=<NllLossBackward0>)
tensor(2.3191, grad_fn=<NllLossBackward0>)
tensor(2.2971, grad_fn=<NllLossBackward0>)
tensor(2.3065, grad_fn=<NllLossBackward0>)
tensor(2.3048, grad_fn=<NllLossBackward0>)
tensor(2.3074, grad_fn=<NllLossBackward0>)
tensor(2.2991, grad_fn=<NllLossBackward0>)
tensor(2.3185, grad_fn=<NllLossBackward0>)
tensor(2.2937, grad_fn=<NllLossBackward0>)
tensor(2.3057, grad_fn=<NllLossBackward0>)
tensor(2.3080, grad_fn=<NllLossBackward0>)
tensor(2.3141, grad_fn=<NllLossBackward0>)
tensor(2.3018, grad_fn=<NllLossBackward0>)
tensor(2.3121, grad_fn=<NllLossBackward0>)
tensor(2.3113, grad_fn=<NllLossBackward0>)
tensor(2.2942, grad_fn=<NllLossBackward0>)
tensor(2.3001, grad_fn=<NllLossBackward0>)
tensor(2.3064, grad_fn=<NllLossBackward0>)
tensor(2.3268, grad_fn=<NllLossBackward0>)
tensor(2.3142, grad_fn=<NllLossBackward0>)
tensor(2.3031, grad_fn=<NllLossBackward0>)
tensor(2.3125, grad_fn=<NllLossBackward0>)
tensor(2.3007, grad_fn=<NllLossBackward0>)
tensor(2.2948, grad_fn=<NllLossBackward0>)
tensor(2.2963, grad_fn=<NllLossBackward0>)
tensor(2.2952, grad_fn=<NllLossBackward0>)
tensor(2.3121, grad_fn=<NllLossBackward0>)
tensor(2.3139, grad_fn=<NllLossBackward0>)
tensor(2.3107, grad_fn=<NllLossBackward0>)
tensor(2.3138, grad_fn=<NllLossBackward0>)
tensor(2.2930, grad_fn=<NllLossBackward0>)
tensor(2.3238, grad_fn=<NllLossBackward0>)
tensor(2.3019, grad_fn=<NllLossBackward0>)
tensor(2.2962, grad_fn=<NllLossBackward0>)
tensor(2.2952, grad_fn=<NllLossBackward0>)
tensor(2.2989, grad_fn=<NllLossBackward0>)
tensor(2.2985, grad_fn=<NllLossBackward0>)
tensor(2.3154, grad_fn=<NllLossBackward0>)
tensor(2.2773, grad_fn=<NllLossBackward0>)
tensor(2.3149, grad_fn=<NllLossBackward0>)
tensor(2.2925, grad_fn=<NllLossBackward0>)
tensor(2.2947, grad_fn=<NllLossBackward0>)
tensor(2.3068, grad_fn=<NllLossBackward0>)
tensor(2.2909, grad_fn=<NllLossBackward0>)
tensor(2.2964, grad_fn=<NllLossBackward0>)
tensor(2.3057, grad_fn=<NllLossBackward0>)
tensor(2.3012, grad_fn=<NllLossBackward0>)
tensor(2.3204, grad_fn=<NllLossBackward0>)
tensor(2.3095, grad_fn=<NllLossBackward0>)
tensor(2.3012, grad_fn=<NllLossBackward0>)
tensor(2.3043, grad_fn=<NllLossBackward0>)
tensor(2.2964, grad_fn=<NllLossBackward0>)
tensor(2.3131, grad_fn=<NllLossBackward0>)
tensor(2.2971, grad_fn=<NllLossBackward0>)
tensor(2.3228, grad_fn=<NllLossBackward0>)
tensor(2.3057, grad_fn=<NllLossBackward0>)
tensor(2.3015, grad_fn=<NllLossBackward0>)
tensor(2.3196, grad_fn=<NllLossBackward0>)
tensor(2.3175, grad_fn=<NllLossBackward0>)
tensor(2.2937, grad_fn=<NllLossBackward0>)
tensor(2.3081, grad_fn=<NllLossBackward0>)
tensor(2.3053, grad_fn=<NllLossBackward0>)
tensor(2.2995, grad_fn=<NllLossBackward0>)
tensor(2.3188, grad_fn=<NllLossBackward0>)
tensor(2.2883, grad_fn=<NllLossBackward0>)
tensor(2.3213, grad_fn=<NllLossBackward0>)
tensor(2.2918, grad_fn=<NllLossBackward0>)
tensor(2.2998, grad_fn=<NllLossBackward0>)
tensor(2.3263, grad_fn=<NllLossBackward0>)
tensor(2.3028, grad_fn=<NllLossBackward0>)
tensor(2.3192, grad_fn=<NllLossBackward0>)
tensor(2.3196, grad_fn=<NllLossBackward0>)
tensor(2.3073, grad_fn=<NllLossBackward0>)
tensor(2.3012, grad_fn=<NllLossBackward0>)
tensor(2.2949, grad_fn=<NllLossBackward0>)
tensor(2.3062, grad_fn=<NllLossBackward0>)
tensor(2.3161, grad_fn=<NllLossBackward0>)
tensor(2.3182, grad_fn=<NllLossBackward0>)
tensor(2.3036, grad_fn=<NllLossBackward0>)
tensor(2.3117, grad_fn=<NllLossBackward0>)
tensor(2.2998, grad_fn=<NllLossBackward0>)
tensor(2.3089, grad_fn=<NllLossBackward0>)
tensor(2.2902, grad_fn=<NllLossBackward0>)
tensor(2.3173, grad_fn=<NllLossBackward0>)
tensor(2.3201, grad_fn=<NllLossBackward0>)
tensor(2.2994, grad_fn=<NllLossBackward0>)
tensor(2.2973, grad_fn=<NllLossBackward0>)
tensor(2.2989, grad_fn=<NllLossBackward0>)
tensor(2.3062, grad_fn=<NllLossBackward0>)
tensor(2.2890, grad_fn=<NllLossBackward0>)
tensor(2.3169, grad_fn=<NllLossBackward0>)
tensor(2.3027, grad_fn=<NllLossBackward0>)
tensor(2.3080, grad_fn=<NllLossBackward0>)
tensor(2.3102, grad_fn=<NllLossBackward0>)
tensor(2.2997, grad_fn=<NllLossBackward0>)
tensor(2.3128, grad_fn=<NllLossBackward0>)
tensor(2.3074, grad_fn=<NllLossBackward0>)
tensor(2.2941, grad_fn=<NllLossBackward0>)
tensor(2.3240, grad_fn=<NllLossBackward0>)
tensor(2.2948, grad_fn=<NllLossBackward0>)
tensor(2.3057, grad_fn=<NllLossBackward0>)
tensor(2.3135, grad_fn=<NllLossBackward0>)
tensor(2.3261, grad_fn=<NllLossBackward0>)
tensor(2.2970, grad_fn=<NllLossBackward0>)
tensor(2.3017, grad_fn=<NllLossBackward0>)
tensor(2.3292, grad_fn=<NllLossBackward0>)
tensor(2.3188, grad_fn=<NllLossBackward0>)
tensor(2.2930, grad_fn=<NllLossBackward0>)
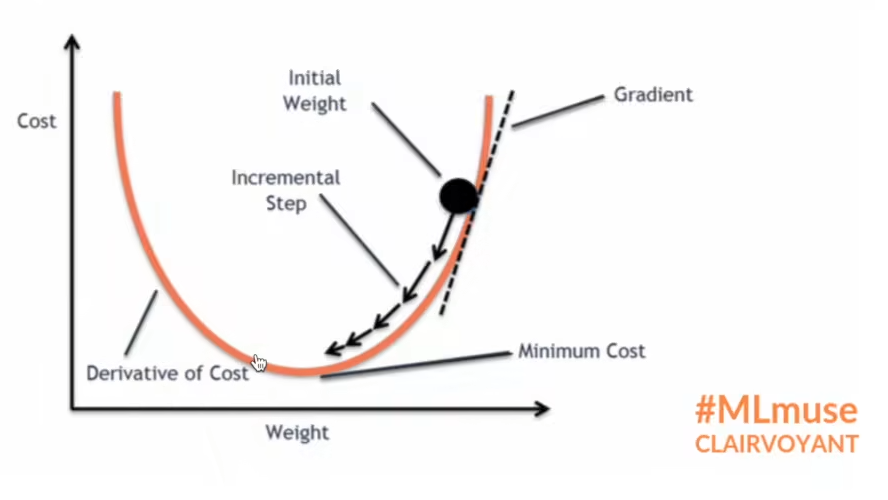
7. 损失函数反向传播
① 反向传播通过梯度来更新参数,使得loss损失最小,如下图所示。
import torch
import torchvision
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10("./dataset",train=False,transform=torchvision.transforms.ToTensor(),download=True)
dataloader = DataLoader(dataset, batch_size=64,drop_last=True)
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.model1 = Sequential(
Conv2d(3,32,5,padding=2),
MaxPool2d(2),
Conv2d(32,32,5,padding=2),
MaxPool2d(2),
Conv2d(32,64,5,padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024,64),
Linear(64,10)
)
def forward(self, x):
x = self.model1(x)
return x
loss = nn.CrossEntropyLoss() # 交叉熵
tudui = Tudui()
for data in dataloader:
imgs, targets = data
outputs = tudui(imgs)
result_loss = loss(outputs, targets) # 计算实际输出与目标输出的差距
result_loss.backward() # 计算出来的 loss 值有 backward 方法属性,反向传播来计算每个节点的更新的参数。这里查看网络的属性 grad 梯度属性刚开始没有,反向传播计算出来后才有,后面优化器会利用梯度优化网络参数。
print("ok")
Files already downloaded and verified
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok

 浙公网安备 33010602011771号
浙公网安备 33010602011771号