


首先先上一张图:
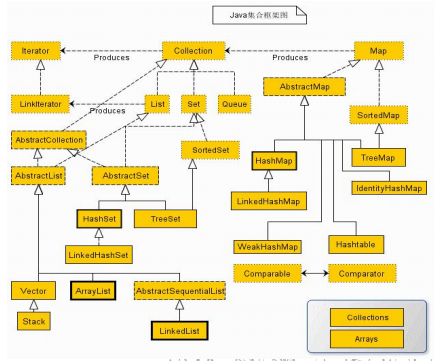
类集
概念
类集(Collection)就是一个动态的对象数组。Java的类集框架使程序处理对象组的方法标准化。类集中最大的几个操作接口:Collection、Map、Iterator,这三个接口为以后要使用的最重点的接口。
Collection 接口
Collection 接口是在整个 Java 类集中保存单值的最大操作父接口,里面每次操作的时候都只能保存一个对象的数据。
public interface Collection<E> extends Iterable<E>
常用方法如下所:
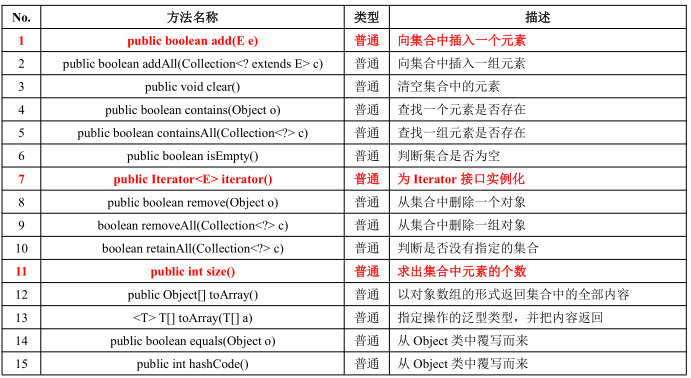
注意:我们在开发中不会直接使用 Collection 接口。而使用其操作的子接口:List、Set
List 接口*
在整个集合中 List 是 Collection 的子接口,里面的所有内容都是允许重复的。
List 子接口的定义:
public interface List<E> extends Collection<E>
常用方法如下所:
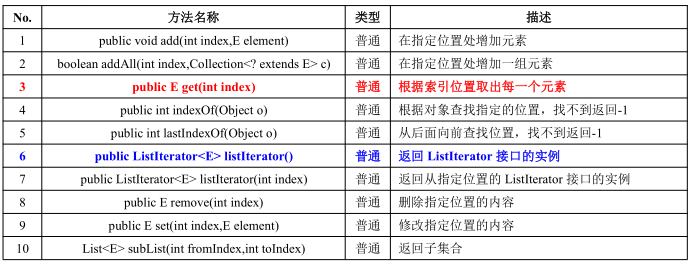
在 List 接口中有以上 10 个方法是对已有的 Collection 接口进行的扩充。
在List中有三个我们经常用到的实现类: ArrayList(95%)、Vector(4%)、LinkedList(1%)。
1、ArrayList
ArrayList 类是一个可以动态修改的数组,与普通数组的区别就是它是没有固定大小的限制,我们可以添加或删除元素。ArrayList 继承了 AbstractList ,并实现了 List 接口。
定义格式如下(此类继承了 AbstractList 类。AbstractList 是 List 接口的子类。AbstractList 是个抽象类,适配器设计模式。):
public classArrayList<E> extendsAbstractList<E> implements List<E>, RandomAccess, Cloneable, Serializable
详细操作:
package org.listdemo.arraylistdemo;
import java.util.ArrayList;
import java.util.List;
public class ArrayListDemo02 {
public static void main(String[] args) {
List<String> all = new ArrayList<String>(); // 实例化List对象,并指定泛型类型
all.add("hello "); // 增加内容,此方法从Collection接口继承而来
all.add(0, "LAMP ");// 增加内容,此方法是List接口单独定义的
all.add("world"); // 增加内容,此方法从Collection接口继承而来
all.remove(1); // 根据索引删除内容,此方法是List接口单独定义的
all.remove("world");// 删除指定的对象
System.out.print("集合中的内容是:");
for (int x = 0; x < all.size(); x++) { // size()方法从Collection接口继承而来
System.out.print(all.get(x) + "、"); // 此方法是List接口单独定义的
}
}
}
2、Vector
Vector 类实现了一个动态数组。和 ArrayList 很相似,但是两者是不同是:Vector是访问同步的(线程安全),包含了许多传统的方法,这些方法不属于集合框架。
定义格式如下:
public class Vector<E> extendsAbstractList<E> implements List<E>, RandomAccess, Cloneable, Serializable
详细操作:
package org.listdemo.vectordemo;
import java.util.List;
import java.util.Vector;
public class VectorDemo01 {
public static void main(String[] args) {
List<String> all = new Vector<String>(); // 实例化List对象,并指定泛型类型
all.add("hello "); // 增加内容,此方法从Collection接口继承而来
all.add(0, "LAMP ");// 增加内容,此方法是List接口单独定义的
all.add("world"); // 增加内容,此方法从Collection接口继承而来
all.remove(1); // 根据索引删除内容,此方法是List接口单独定义的
all.remove("world");// 删除指定的对象
System.out.print("集合中的内容是:");
for (int x = 0; x < all.size(); x++) { // size()方法从Collection接口继承而来
System.out.print(all.get(x) + "、"); // 此方法是List接口单独定义的
}
}
}
Vector 类和 ArrayList 类的区别

3、链表操作类:LinkedList
链表(Linked list)是一种常见的基础数据结构,是一种线性表,但是并不会按线性的顺序存储数据,而是在每一个节点里存到下一个节点的地址。了解链表
定义格式如下:
public class LinkedList<E> extendsAbstractSequentialList<E> implements List<E>, Deque<E>, Cloneable, Serializable
此类继承了 AbstractList,所以是 List 的子类。但是此类也是 Queue 接口的子类,Queue 接口定义了如下的方法:
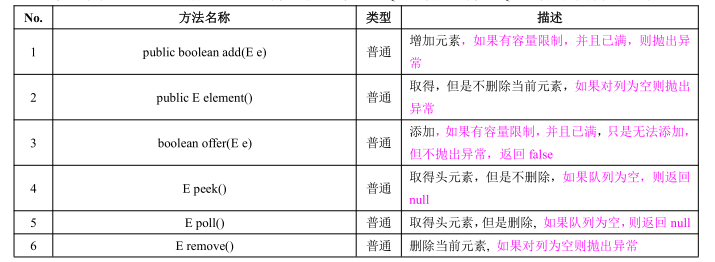
详细操作:
import java.util.LinkedList;
import java.util.Queue;
public class TestDemo {
public static void main(String[] args) {
Queue<String> queue = new LinkedList<String>();
queue.add("A");
queue.add("B");
queue.add("C");
int len=queue.size();// 把queue 的大小先取出来,否则每循环一次,移除一个元素,就少一个元素,那么queue.size() 在变小,就不能循环queue.size() 次了。
for (int x = 0; x <len; x++) {
System.out.println(queue.poll());
}
System.out.println(queue);
}
}
Set 接口
Set 接口也是 Collection 的子接口,与 List 接口最大的不同在于,Set 接口里面的内容是不允许重复的。
Set 接口并没有对 Collection 接口进行扩充,基本上还是与 Collection 接口保持一致。因为此接口没有 List 接口中定义的 get(int index)方法,所以无法使用循环进行输出。
此接口中有两个常用的子类:HashSet、TreeSet。
1、散列存放:HashSet
HashSet 基于 HashMap 来实现的,是一个不允许有重复元素的集合。HashSet 允许有 null 值、是无序的、不是线程安全的。
import java.util.HashSet;
public class RunoobTest {
public static void main(String[] args) {
HashSet<String> sites = new HashSet<String>();
sites.add("Google");
sites.add("Runoob");
sites.add("Taobao");
sites.add("Zhihu");
sites.add("Runoob"); // 重复的元素不会被添加
sites.remove("Taobao"); // 删除元素,删除成功返回 true,否则为 false
System.out.println(sites.contains("Taobao"));//使用 contains() 方法来判断元素是否存在于集合当中:
}
}
2、排序的子类:TreeSet
TreeSet 是一个有序的集合,它的作用是提供有序的Set集合。它继承于AbstractSet抽象类,实现了NavigableSet<E>, Cloneable, java.io.Serializable接口,与 HashSet 不同的是,TreeSet 本身属于排序的子类,此类的定义如下:
public class TreeSet<E> extendsAbstractSet<E> implements NavigableSet<E>, Cloneable, Serializable
例子:
package day01;
import java.util.TreeSet;
public class TreeSet1 {
/**
* TreeSet的排序是基于里面的数据排序的,排序的值不能为重复一样的数据
* @param args
*/
public static void main(String[] args) {
TreeSet<String> data = new TreeSet<>();
data.add("王麻子");
data.add("李麻子");
data.add("杨麻子");
data.add("高麻子");
data.add("胡麻子");
data.add("秦麻子");
for(String s : data) {
System.out.println(s);
}
}
}
返回如下:
李麻子
杨麻子
王麻子
秦麻子
胡麻子
高麻子
注意:如果现在要想对象进行排序的话,则必须在 Person 类中实现 Comparable 接口。
package day01;
import java.util.TreeSet;
public class TreeSet1 {
/**
* TreeSet对象进行排序,在 Person 类中实现 Comparable 接口
* @param args
*/
public static void main(String[] args) {
TreeSet<Person> data1 = new TreeSet<>();
Person p1 = new Person("高宇",15);
Person p2 = new Person("高宇1",26);
data1.add(p1);
data1.add(p2);
for(Person s:data1) {
System.out.println(s);
}
}
static class Person implements Comparable<Person>{
private String name;
private int age;
@Override
public int compareTo(Person o) {
//this与 o 比较
// 返回的数据:
if(this.age > o.age) {
return 1;
}else if(this.age < o.age) {
return -1;
}
return 0;
}
public Person(String name ,int age){
this.name = name;
this.age = age;
}
@Override
public String toString() {
return "Person [name=" + name + ", age=" + age + "]";
}
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + age;
result = prime * result + ((name == null) ? 0 : name.hashCode());
return result;
}
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
Person other = (Person) obj;
if (age != other.age)
return false;
if (name == null) {
if (other.name != null)
return false;
} else if (!name.equals(other.name))
return false;
return true;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
}
}
结果如下:
Person [name=高宇, age=15]
Person [name=高宇1, age=26]
3、关于重复元素的说明
之前使用 Comparable 完成的对于重复元素的判断,那么 Set 接口定义的时候本身就是不允许重复元素的,那么证明如果现在真的是有重复元素的话,使用 HashSet 也同样可以进行区分。
package org.listdemo.treesetdemo04;
import java.util.HashSet;
import java.util.Set;
public class HashSetPersonDemo01 {
public static void main(String[] args) {
Set<Person> all = new HashSet<Person>();
all.add(new Person("张三", 10));
all.add(new Person("李四", 10));
all.add(new Person("李四", 10));
all.add(new Person("王五", 11));
all.add(new Person("赵六", 12));
all.add(new Person("孙七", 13));
System.out.println(all);
}
}
此时发现,并没有去掉所谓的重复元素,也就是说之前的操作并不是真正的重复元素的判断,而是通过 Comparable接口间接完成的。
如果要想判断两个对象是否相等,则必须使用 Object 类中的 equals()方法。从最正规的来讲,如果要想判断两个对象是否相等,则有两种方法可以完成:
· 第一种判断两个对象的编码是否一致,这个方法需要通过 hashCode()完成,即:每个对象有唯一的编码
· 还需要进一步验证对象中的每个属性是否相等,需要通过 equals()完成。
所以此时需要覆写 Object 类中的 hashCode()方法,此方法表示一个唯一的编码,一般是通过公式计算出来的。
public boolean equals(Object obj) {
if (this == obj) {
return true;
}
if (!(obj instanceof Person)) {
return false;
}
Person per = (Person) obj;
if (per.name.equals(this.name) && per.age == this.age) {
return true;
} else {
return false;
}
}
public int hashCode() {
return this.name.hashCode() * this.age;
}
此时已经不存在重复元素了,所以如果要想去掉重复元素需要依靠 hashCode()和 equals()方法共同完成。
注意:
关于 TreeSet 的排序实现,如果是集合中对象是自定义的或者说其他系统定义的类没有实现Comparable 接口,则不能实现 TreeSet 的排序,会报类型转换(转向 Comparable 接口)错误。换句话说要添加到 TreeSet 集合中的对象的类型必须实现了 Comparable 接口。
不过 TreeSet 的集合因为借用了 Comparable 接口,同时可以去除重复值,而 HashSet 虽然是Set 接口子类,但是对于没有复写 Object 的 equals 和 hashCode 方法的对象,加入了 HashSet集合中也是不能去掉重复值的。
Map 接口
Map 提供了一个通用的元素存储方法。Map 集合类用于存储元素对(称作“键”和“值”),其中每个键映射到一个值。也称为二元偶对象。
接口定义如下:
public interface Map<K,V>
此接口与 Collection 接口没有任何的关系,是第二大的集合操作接口。此接口常用方法如下:
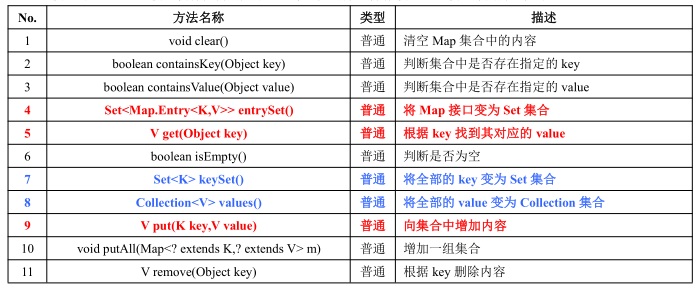
Map 本身是一个接口,所以一般会使用以下的几个子类:HashMap、TreeMap、Hashtable
1、新的子类:HashMap
HashMap 是一个散列表,它存储的内容是键值对(key-value)映射。根据键的 HashCode 值存储数据,具有很快的访问速度,最多允许一条记录的键为 null,不支持线程同步。HashMap 是无序的。
定义如下:
public class HashMap<K,V> extendsAbstractMap<K,V> implements Map<K,V>, Cloneable, Serializable
此类继承了 AbstractMap 类,同时可以被克隆,可以被序列化下来。
例子:
package org.listdemo.hashmapdemo;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import java.util.Set;
public class HashMapDemo03 {
public static void main(String[] args) {
Map<String, String> map = new HashMap<String, String>();
map.put("ZS", "张三");
map.put("LS", "李四");
map.put("WW", "王五");
map.put("ZL", "赵六");
map.put("SQ", "孙七");
Set<String> set = map.keySet(); // 得到全部的key
Iterator<String> iter = set.iterator();
while (iter.hasNext()) {
String i = iter.next(); // 得到key
System.out.println(i + " --:> " + map.get(i));
}
}
2、旧的子类:Hashtable
Hashtable 是一个最早的 keyvalue 的操作类,本身是在 JDK 1.0 的时候推出的。其基本操作与 HashMap 是类似的。
package org.listdemo.hashtabledemo;
import java.util.Hashtable;
import java.util.Map;
public class HashtableDemo01 {
public static void main(String[] args) {
Map<String, Integer> numbers = new Hashtable<String, Integer>();
numbers.put("one", 1);
numbers.put("two", 2);
numbers.put("three", 3);
Integer n = numbers.get("two");
if (n != null) {
System.out.println("two = " + n);
}
}
}
3、 HashMap 与 与 Hashtable 的区别

4、排序的子类:TreeMap
TreeMap 子类是允许 key 进行排序的操作子类,其本身在操作的时候将按照 key 进行排序,另外,key 中的内容可以为任意的对象,但是要求对象所在的类必须实现 Comparable 接口。
package org.listdemo.treemapdemo;
import java.util.Iterator;
import java.util.Map;
import java.util.Set;
import java.util.TreeMap;
public class TreeMapDemo01 {
public static void main(String[] args) {
Map<String, String> map = new TreeMap<String, String>();
map.put("ZS", "张三");
map.put("LS", "李四");
map.put("WW", "王五");
map.put("ZL", "赵六");
map.put("SQ", "孙七");
Set<String> set = map.keySet(); // 得到全部的key
Iterator<String> iter = set.iterator();
while (iter.hasNext()) {
String i = iter.next(); // 得到key
System.out.println(i + " --:> " + map.get(i));
}
}
}
5、关于 Map 集合的输出
在 Collection 接口中,可以使用 iterator()方法为 Iterator 接口实例化,并进行输出操作,但是在 Map 接口中并没有此方法的定义,所以 Map 接口本身是不能直接使用 Iterator 进行输出的。
因为 Map 接口中存放的每一个内容都是一对值,而使用 Iterator 接口输出的时候,每次取出的都实际上是一个完整的对象。如果此时非要使用 Iterator 进行输出的话,则可以按照如下的步骤进行:
1、 使用 Map 接口中的 entrySet()方法将 Map 接口的全部内容变为 Set 集合
2、 可以使用 Set 接口中定义的 iterator()方法为 Iterator 接口进行实例化
3、 之后使用 Iterator 接口进行迭代输出,每一次的迭代都可以取得一个 Map.Entry 的实例
4、 通过 Map.Entry 进行 key 和 value 的分离
Map.Entry 本身是一个接口。此接口是定义在 Map 接口内部的,是 Map 的内部接口。此内部接口使用 static 进行定义,所以此接口将成为外部接口。
实际上来讲,对于每一个存放到 Map 集合中的 key 和 value 都是将其变为了 Map.Entry 并且将 Map.Entry 保存在了Map 集合之中。
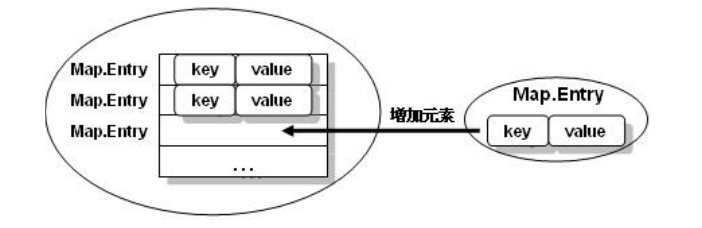
使用 Iterator 输出 Map 接口栗子:
package org.listdemo.mapoutdemo;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import java.util.Set;
public class MapOutDemo01 {
public static void main(String[] args) {
Map<String, String> map = new HashMap<String, String>();
map.put("ZS", "张三");
map.put("LS", "大声道");
map.put("WW", "王五");
map.put("ZL", "赵是多少");
map.put("SQ", "孙七");
Set<Map.Entry<String, String>> set = map.entrySet();// 变为Set实例
Iterator<Map.Entry<String, String>> iter = set.iterator();
while (iter.hasNext()) {
Map.Entry<String, String> me = iter.next();
System.out.println(me.getKey() + " --> " + me.getValue());
}
}
}
Map 集合中每一个元素都是 Map.Entry 的实例,只有通过 Map.Entry 才能进行 key 和 value;
除了以上的做法之外,在 JDK 1.5 之后也可以使用 foreach 完成同样的输出:
package org.listdemo.mapoutdemo;
import java.util.HashMap;
import java.util.Map;
public class MapOutDemo02 {
public static void main(String[] args) {
Map<String, String> map = new HashMap<String, String>();
map.put("ZS", "是是是");
map.put("LS", "李四");
map.put("WW", "王五");
map.put("ZL", "赵六");
map.put("SQ", "孙七");
for (Map.Entry<String, String> me : map.entrySet()) {
System.out.println(me.getKey() + " --> " + me.getValue());
}
}
}
end~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号