
电子游戏销量数据集分析
一、选题的背景
游戏已经成为当代年轻人最为主流的消遣时间、放松娱乐的一种方式。但有时常常因为找不到好的游戏,会去花费大量的时间去查阅相关资料去了解各种各样的游戏以便找到适合自己的那一款。为了节省时间,缩减对好游戏的搜索范围,通过对电子游戏销量数据的分析,来快速匹配了解热门游戏,在寻找精品游戏的同时,大大节约了我们的时间。
二、设计方案
1.搜集数据
通过爱数科下载电子游戏销量数据集
来源网址:http://idatascience.cn/dataset-detail?table_id=431
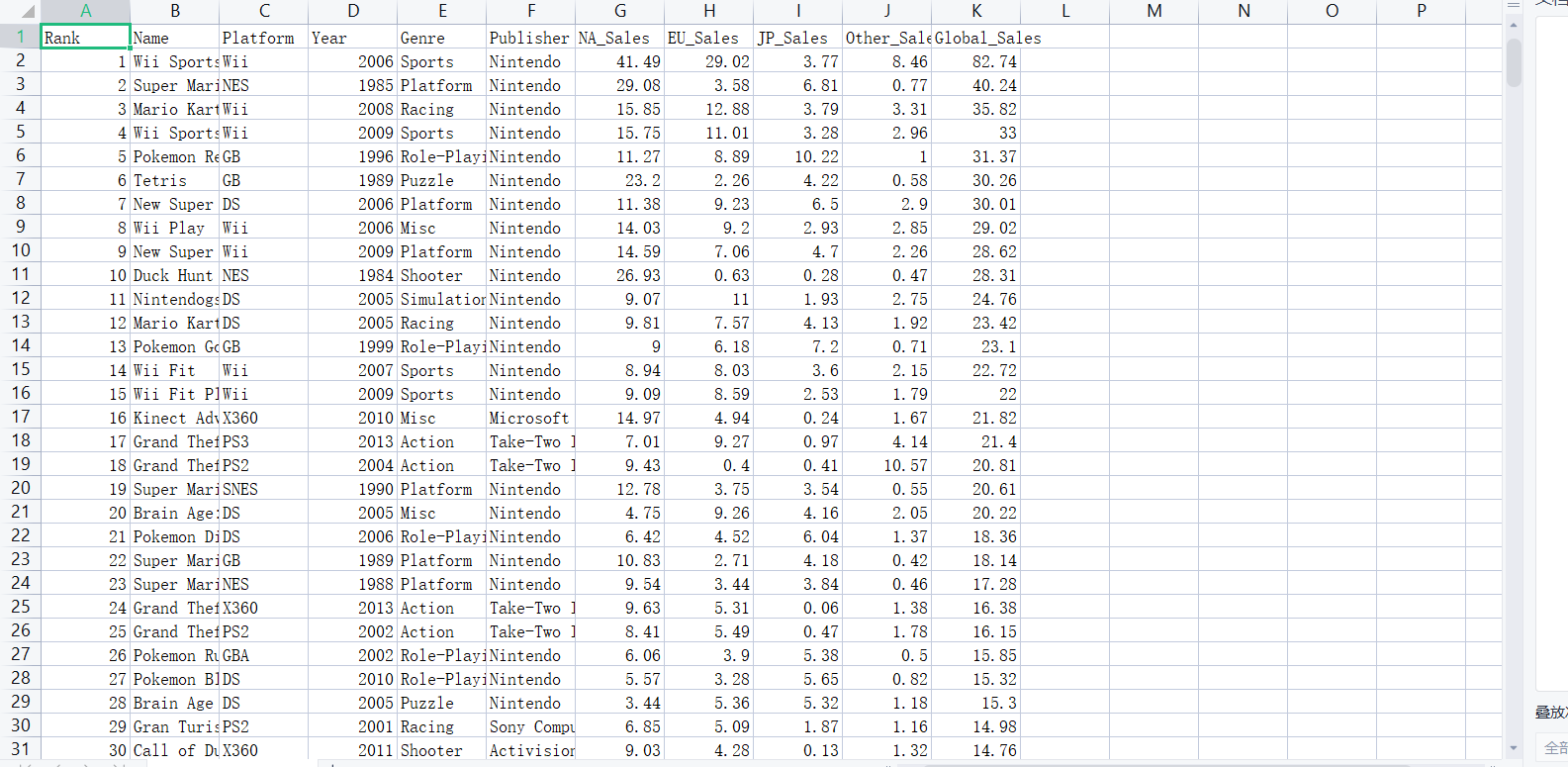
该数据集包含销量大于十万份的电子游戏数据,包括销量排行、发行平台、发行年份和游戏种类,还包括北美、欧洲、日本各地区销量和全球销量等信息。
2.数据准备
找到数据集保存位置,通过df=pd.read_csv('C:/Users/home/电子游戏销量数据集.csv')代码打开数据集。
3.数据可视化分析
分析目标:各游戏类型占比,游戏平台占比, 绘制年份和销量的散点关系图,查看年份和销量的二元变量分布,查看平台与销量之间的关系,查看各平台下游戏数量,对各地区近年销量可视化处理,各地区销量之间关系,绘制词云,将游戏类型汇总 探索电子游戏销量数据集中的多个成对双变量的分布。
三、实施过程以及代码的实现
1数据读取
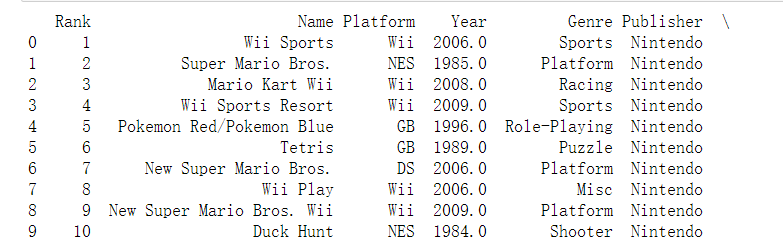
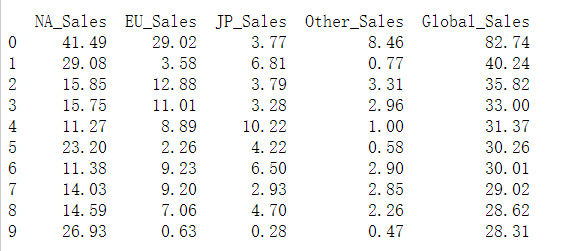
1 #通过爱数科下载电子游戏销量数据集 2 #来源网址 http://idatascience.cn/dataset-detail?table_id=431 3 #该数据集包含销量大于十万份的电子游戏数据,包括销量排行、发行平台、发行年份和游戏种类,还包括北美、欧洲、日本各地区销量和全球销量等信息。 4 #---------------------------------------------------------------- 5 import matplotlib.pyplot as plt 6 import numpy as np 7 import pandas as pd 8 df=pd.read_csv('C:/Users/home/电子游戏销量数据集.csv') 9 df.head() 10 #排名 名称 平台 发行年份 类型 发行商 北美地区销量 欧洲地区销量 日本地区销量 其它地区销量 全球销量

2数据分析
1 #全球销量同时间变化 2 import pandas as pd 3 import matplotlib.pyplot as plt 4 import seaborn as sns 5 # 数据准备 6 df=pd.read_csv('C:/Users/home/电子游戏销量数据集.csv') 7 x = df['Year'] 8 y = df['Global_Sales'] 9 # 使用Seaborn画折线图 10 df = pd.DataFrame({'x': x, 'y': y}) 11 sns.lineplot(x="x", y="y", data=df) 12 plt.show()
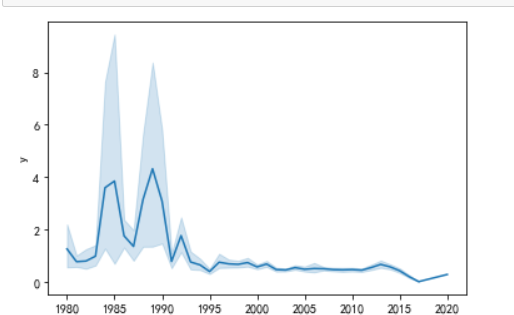 结论:由全球销量折线图看出,数据是起伏不定的,在1995年后,逐渐趋于平缓,稳定在2以下
结论:由全球销量折线图看出,数据是起伏不定的,在1995年后,逐渐趋于平缓,稳定在2以下
1 #各游戏发行商占比 2 from pylab import * 3 mpl.rcParams['font.sans-serif'] = ['SimHei'] 4 mpl.rcParams['axes.unicode_minus'] = False 5 df=pd.read_csv('C:/Users/home/电子游戏销量数据集.csv') 6 df = (df['Publisher'].value_counts())[:16].to_frame() 7 plt.figure(figsize=(15,15)) 8 plt.pie(df['Publisher'], labels=df.index.values, autopct='%.1f%%') 9 plt.title('发行商占比',fontsize=20)
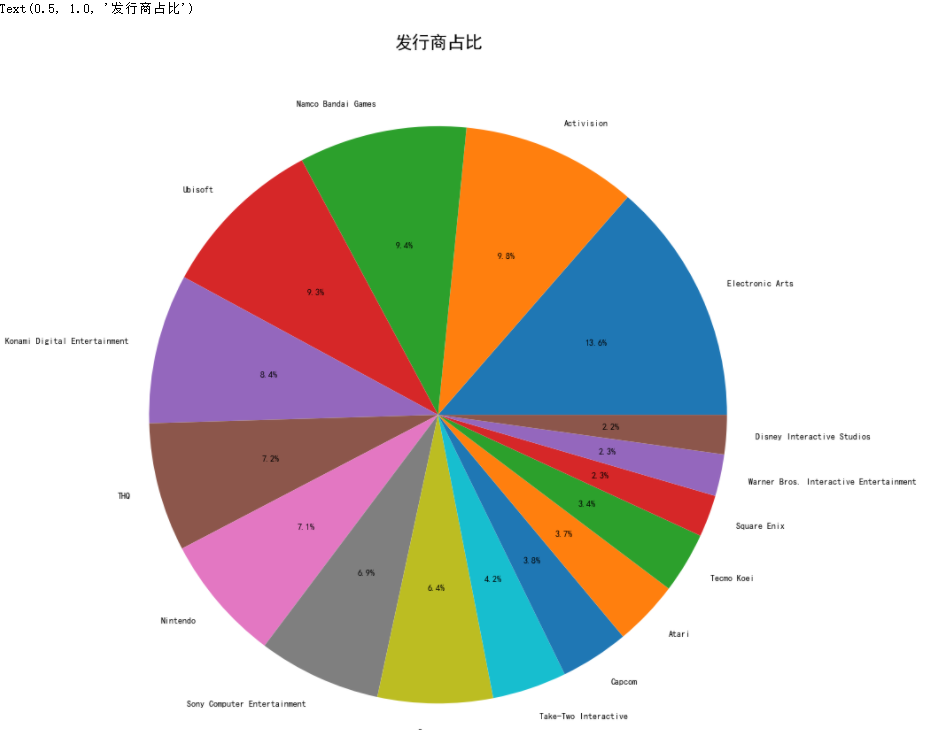
饼状图能更快在看出各发行商的占比,通过上图可得,在所有发行商中,占比最大的是Electronic Arts,达到了13.6%,占比最小的是Di sney Interactive Stud ios,仅仅只有2.2%。而lbisoft,Namco Bandai Games,Activision三者所占比相近。
1 #各游戏类型占比 2 from pylab import * 3 mpl.rcParams['font.sans-serif'] = ['SimHei'] 4 mpl.rcParams['axes.unicode_minus'] = False 5 df=pd.read_csv('C:/Users/home/电子游戏销量数据集.csv') 6 df = (df['Genre'].value_counts())[:16].to_frame() 7 plt.figure(figsize=(15,15)) 8 plt.pie(df['Genre'], labels=df.index.values, autopct='%.1f%%') 9 plt.title('游戏类型占比',fontsize=20)
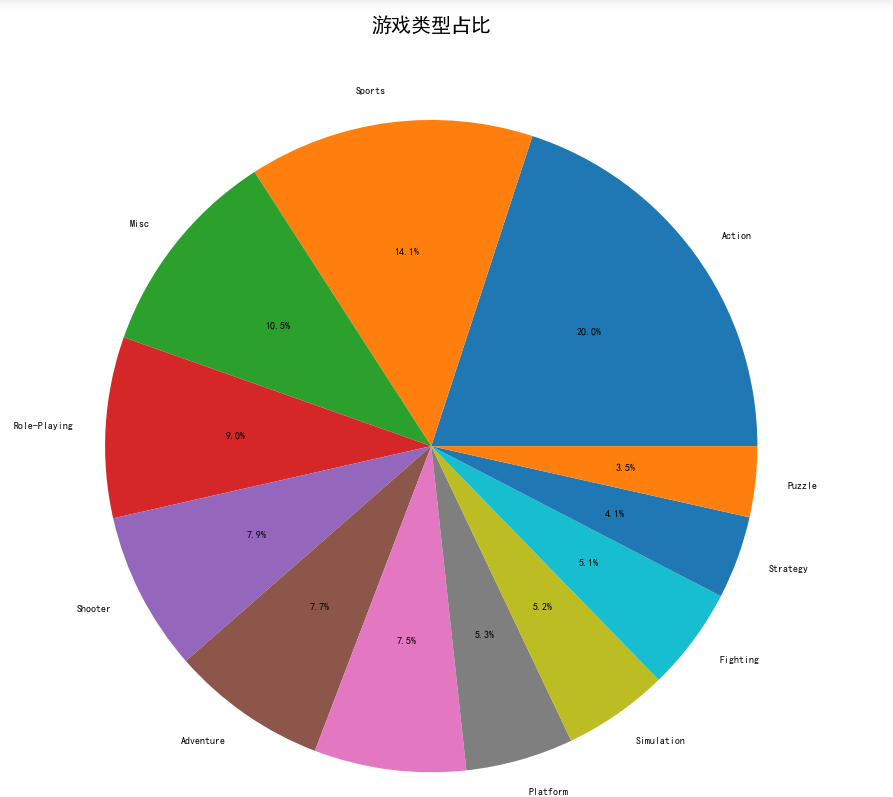
由游戏类型占比饼状图可以看出,最受人欢迎的游戏类型是Action,达到了20%。比较受欢迎的是Sports类和Mi sc类游戏,最不受欢迎的是puzzle类游戏,只占了3.5%。
1 #游戏平台占比 2 from pylab import * 3 mpl.rcParams['font.sans-serif'] = ['SimHei'] 4 mpl.rcParams['axes.unicode_minus'] = False 5 df=pd.read_csv('C:/Users/home/电子游戏销量数据集.csv') 6 df = (df['Platform'].value_counts())[:16].to_frame() 7 plt.figure(figsize=(15,15)) 8 plt.pie(df['Platform'], labels=df.index.values, autopct='%.1f%%') 9 plt.title('游戏平台占比',fontsize=20)
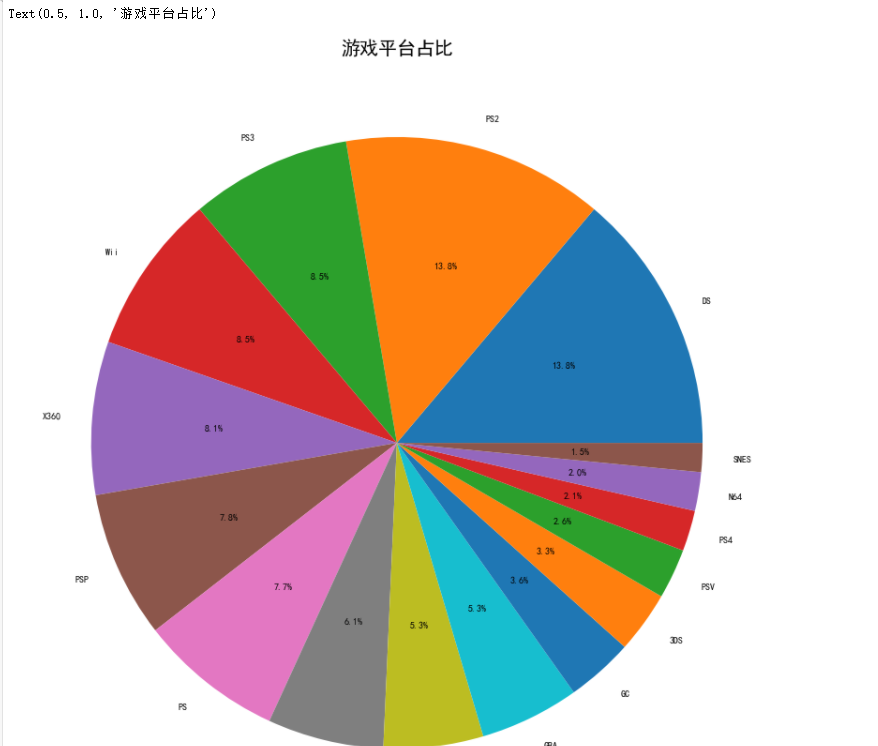
通过游戏平台占比饼状图,我们可以看出占比最大的游戏平台是ps2和DS,占比都是13.8%,而最不受人欢迎的平台是snes,占比仅有1.5%
1 # 绘制年份和销量的散点关系图 2 lx = df['Year'].apply(lambda x:float(x)) 3 # print(home_area.head()) 4 xl = df['Global_Sales'] 5 # print(total_price.head()) 6 plt.scatter(lx,xl,s=3) 7 plt.title('年份和销量关系',fontsize=15) 8 plt.xlabel('年份',fontsize=15) 9 plt.ylabel('全球销量',fontsize=15) 10 plt.grid(linestyle=":", color="r") 11 plt.show()
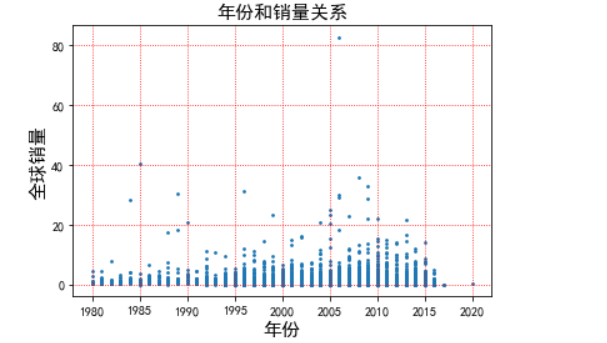
由年份与销量的散点关系图可以看出,从1980到2015年的销量呈现上下波动的现象 其中2010年的销量最多,2017年的销量最少
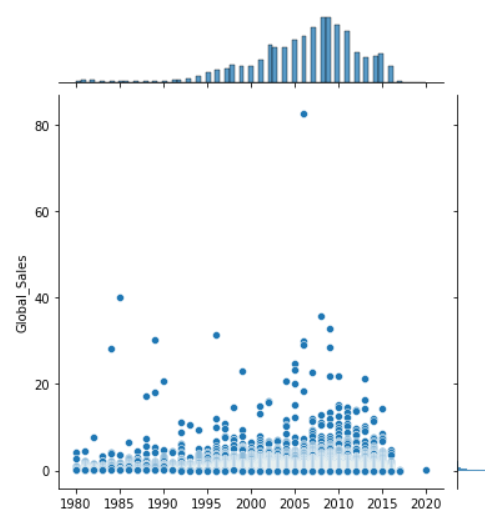
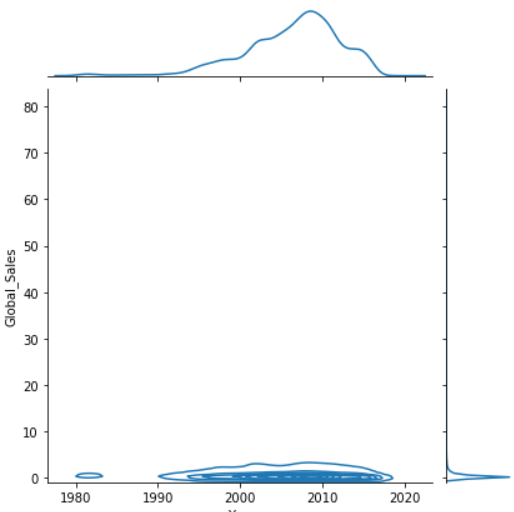
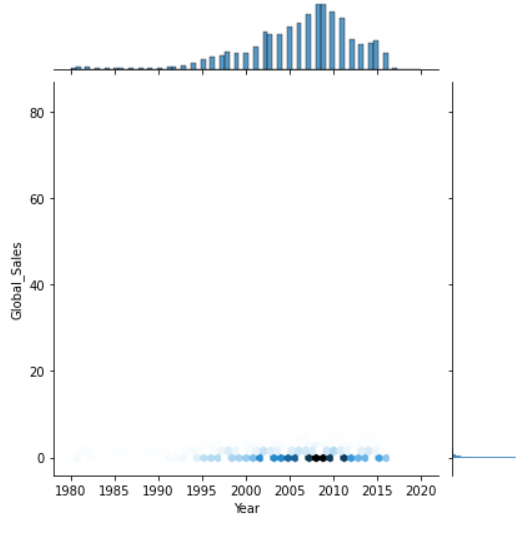
1 #查看年份和销量的二元变量分布 2 import matplotlib.pyplot as plt 3 import seaborn as sns 4 # 数据准备 5 # tips = sns.load_dataset("tips") 6 tips = pd.read_csv('C:/Users/home/电子游戏销量数据集.csv') 7 print(tips.head(10)) 8 # 用Seaborn画二元变量分布图(散点图,核密度图,Hexbin图) 9 sns.jointplot(x="Year", y="Global_Sales", data=tips, kind='scatter') 10 sns.jointplot(x="Year", y="Global_Sales", data=tips, kind='kde') 11 sns.jointplot(x="Year", y="Global_Sales", data=tips, kind='hex') 12 plt.show()
1 #查看平台与销量之间的关系 2 import pandas as pd 3 import numpy as np 4 import matplotlib.pyplot as plt 5 import seaborn as sns 6 7 df=pd.read_csv('C:/Users/home/电子游戏销量数据集.csv') 8 fig,ax = plt.subplots() 9 fig.set_size_inches(19,7) 10 sns.boxplot(x=df['Platform'],y=df['Global_Sales'],data=df) 11 plt.show()
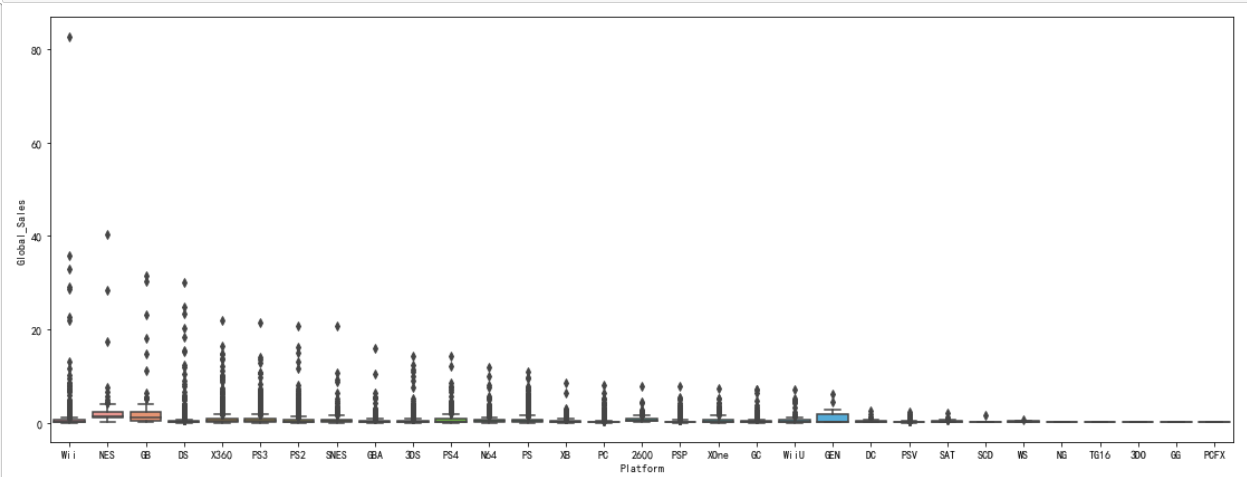
由图可以看出,在wii平台和nes平台和ds平台上,游戏的销量是最好的,在ng,tg16和gg和pcfx平台上,游戏的销量最少
1 #查看各平台下游戏数量 2 fig,ax = plt.subplots() 3 fig.set_size_inches(10,10) 4 xq = df['Platform'].value_counts().sort_values() 5 index = list(xq.index) 6 value = list(xq.values) 7 qx = pd.DataFrame({'Platform':index,'数量':value}) 8 qx.plot.barh(x='Platform',y='数量',ax=ax,color='blue',fontsize=12) 9 plt.legend(loc='right') 10 for a,b in zip(value,np.arange(0,14,1)): 11 plt.text(a+0.5,b,a,fontsize=12) 12 plt.show()
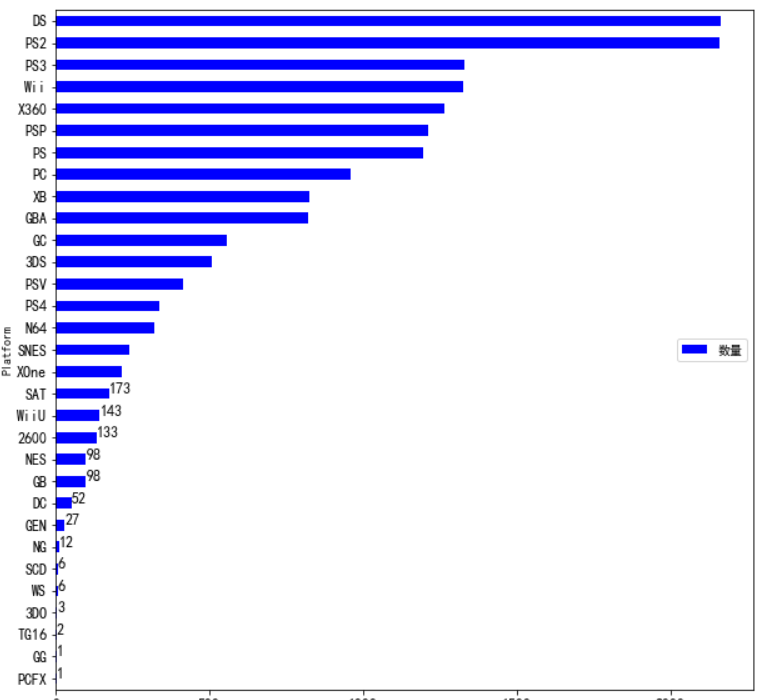
由图可以看出,ds,ps平台上游戏的下载量是最多,二者持平。pcfx,gg,tg16平台上游戏的下载数是最少的。
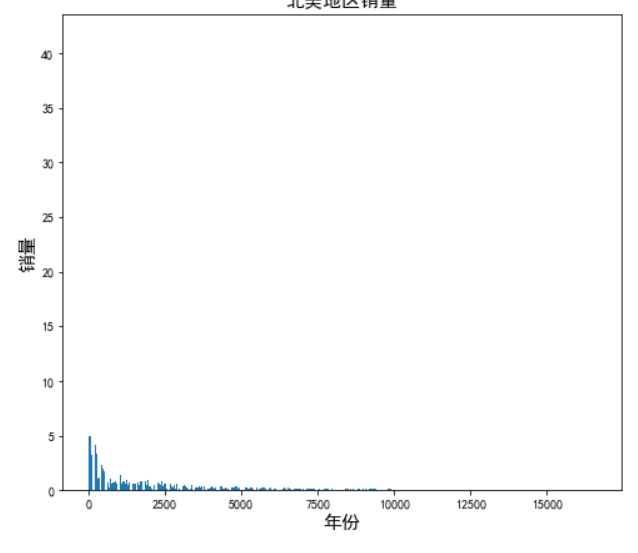
1 #对各地区近年销量可视化处理 2 #导入库 3 import matplotlib.pyplot as plt 4 plt.figure(figsize=(8,7)) 5 6 date = df.set_index('Year') #把日期列设为索引 7 date.index = pd.to_datetime(date.index) #把索引转为时间格式 8 plt.title('北美地区销量',fontsize=15) 9 plt.xlabel('年份',fontsize=15) 10 plt.ylabel('销量',fontsize=15) 11 plt.bar(df.index, df['NA_Sales']) #以日期为横轴,销量为纵轴绘制条形图
由图可以看出,随着时间的增长,北美地区的销量逐渐减少,最后逐渐趋于平缓
1 date = df.set_index('Year') 2 date.index = pd.to_datetime(date.index) 3 plt.title('欧洲地区销量',fontsize=15) 4 plt.xlabel('年份',fontsize=15) 5 plt.ylabel('销量',fontsize=15) 6 plt.bar(df.index, df['EU_Sales'])
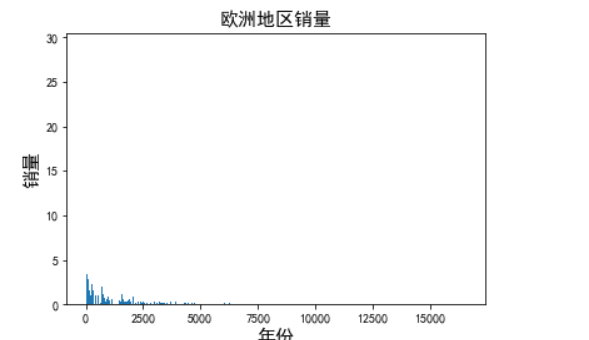
由图可以看出,随着时间的增长,欧洲地区的销量逐渐减少,最后逐渐趋于平缓
1 date = df.set_index('Year') 2 date.index = pd.to_datetime(date.index) 3 plt.title('日本地区销量',fontsize=15) 4 plt.xlabel('年份',fontsize=15) 5 plt.ylabel('销量',fontsize=15) 6 plt.bar(df.index, df['JP_Sales'])
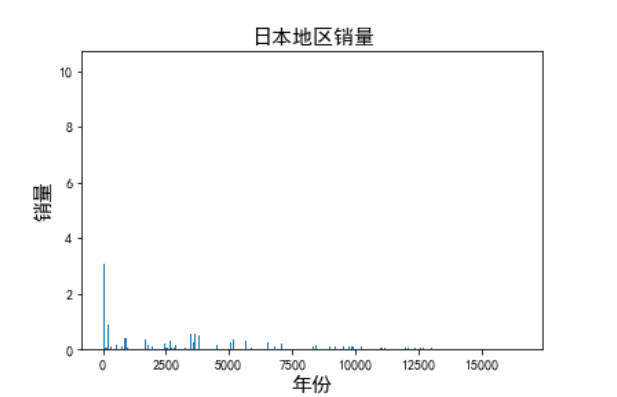
从图可以看出,日本地区最初的销量是最高的,但是随着时间的增长,销量逐渐减少。
1 date = df.set_index('Year') 2 date.index = pd.to_datetime(date.index) 3 plt.title('其他地区销量',fontsize=15) 4 plt.xlabel('年份',fontsize=15) 5 plt.ylabel('销量',fontsize=15) 6 plt.bar(df.index, df['Other_Sales'])
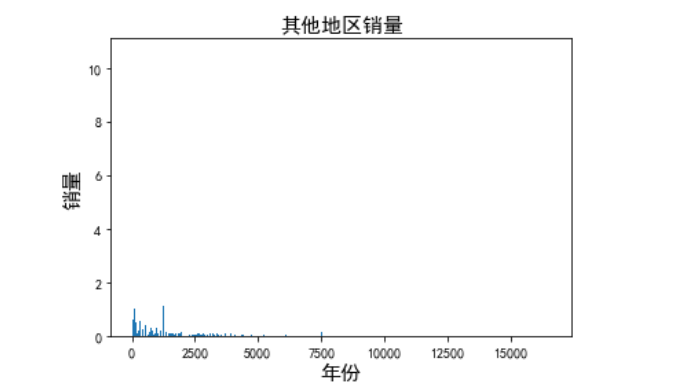
由图可以看出,随着时间增加,销量逐渐减少,但是在1990年时候,达到最高值。
1 date = df.set_index('Year') 2 date.index = pd.to_datetime(date.index) 3 plt.title('全球销量',fontsize=15) 4 plt.xlabel('年份',fontsize=15) 5 plt.ylabel('销量',fontsize=15) 6 plt.bar(df.index, df['Global_Sales'])
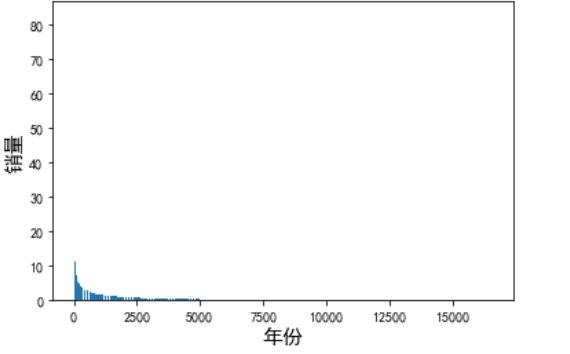
由图可以看出,全球地区的销量随着时间的增加而逐渐减少。
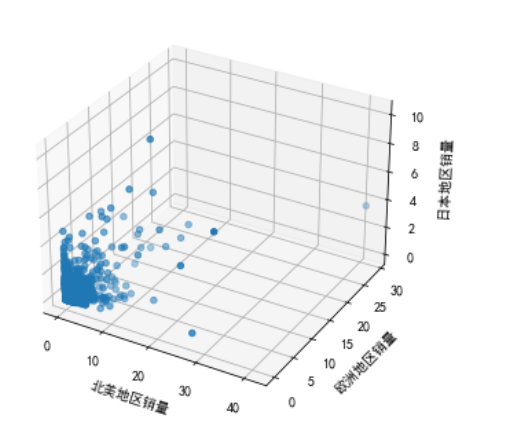
1 #各地区销量之间关系 2 import numpy as np 3 import matplotlib.pyplot as plt 4 from mpl_toolkits. mplot3d import Axes3D 5 fig = plt.figure() 6 ax = Axes3D(fig,auto_add_to_figure=False) 7 fig.add_axes(ax) 8 9 x = df['NA_Sales'] 10 y = df['EU_Sales'] 11 z = df['JP_Sales'] 12 ax. scatter(x, y, z) 13 ax.set_xlabel('北美地区销量') 14 ax.set_ylabel( '欧洲地区销量') 15 ax.set_zlabel('日本地区销量') 16 plt.show()
1 # 绘制词云,将游戏类型汇总 2 import jieba 3 from wordcloud import WordCloud 4 df=pd.read_csv('C:/Users/home/电子游戏销量数据集.csv') 5 text = '' 6 for line in df['Genre']: 7 text += line 8 # 使用jieba模块将字符串分割为单词列表 9 cut_text = ' '.join(jieba.cut(text)) 10 color_mask = imread('C:/Users/home/56.jpg') #设置背景图 11 cloud = WordCloud( 12 13 background_color = 'white', 14 # 对中文操作必须指明字体 15 font_path='C:\windows\Fonts\STZHONGS.TTF', 16 mask = color_mask, 17 max_words = 50, 18 max_font_size = 200 19 ).generate(cut_text) 20 21 # 保存词云图片 22 cloud.to_file('word1cloud.jpg') 23 plt.imshow(cloud) 24 plt.axis('off') 25 plt.show()

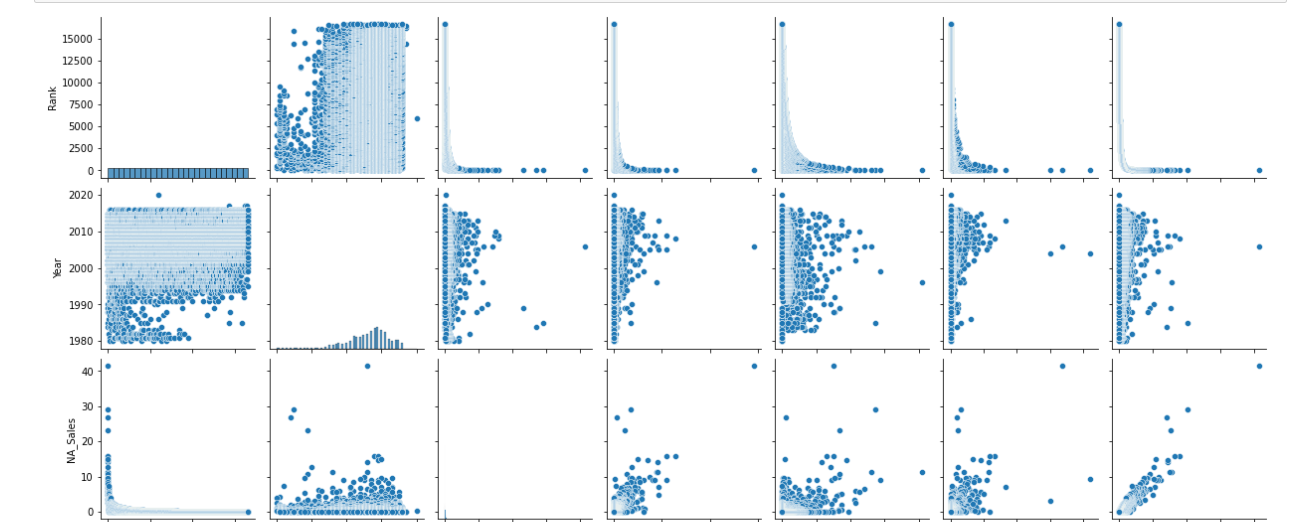
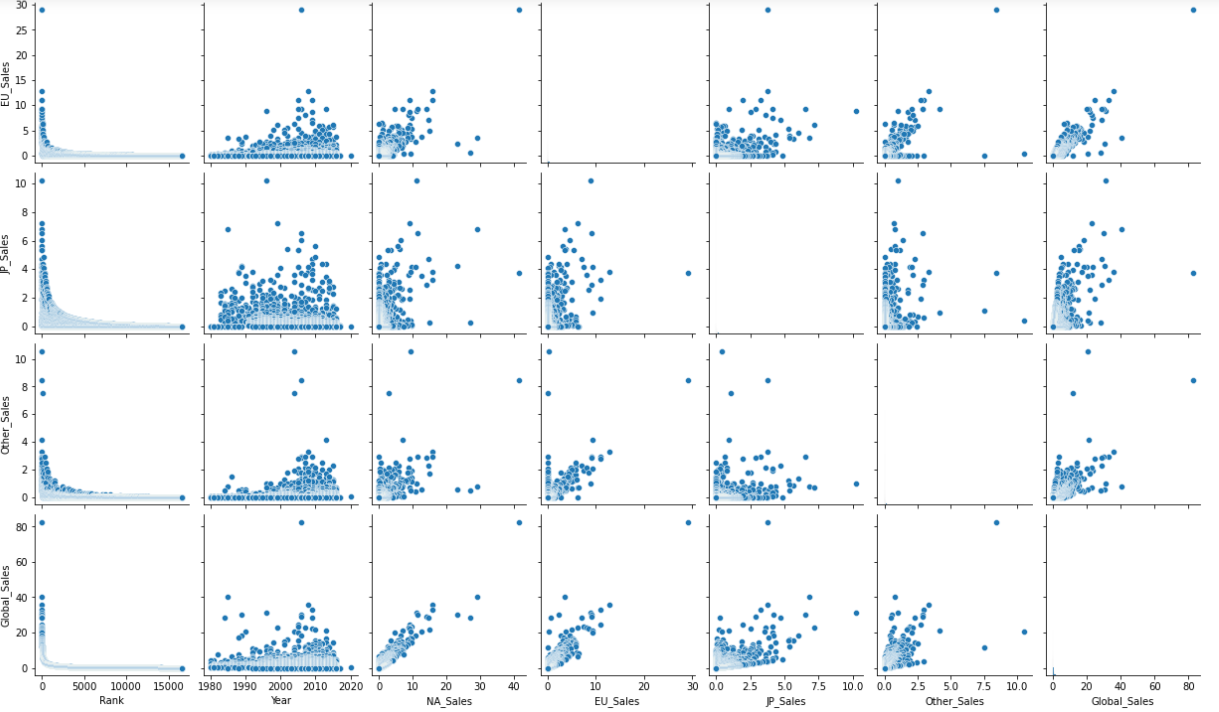
1 #探索电子游戏销量数据集中的多个成对双变量的分布 2 import matplotlib.pyplot as plt 3 import seaborn as sns 4 # 数据准备 5 # iris = sns.load_dataset('iris') 6 iris =pd.read_csv('C:/Users/home/电子游戏销量数据集.csv') 7 # 用Seaborn画成对关系 8 sns.pairplot(iris) 9 plt.show()
四完整代码
1 #通过爱数科下载电子游戏销量数据集 2 #来源网址 http://idatascience.cn/dataset-detail?table_id=431 3 #该数据集包含销量大于十万份的电子游戏数据,包括销量排行、发行平台、发行年份和游戏种类,还包括北美、欧洲、日本各地区销量和全球销量等信息。 4 #---------------------------------------------------------------- 5 import matplotlib.pyplot as plt 6 import numpy as np 7 import pandas as pd 8 df=pd.read_csv('C:/Users/home/电子游戏销量数据集.csv') 9 df.head() 10 #排名 名称 平台 发行年份 类型 类型 北美地区销量 欧洲地区销量 日本地区销量 其它地区销量 全球销量 11 12 #---------------------------------------------------------------- 13 14 #全球销量同时间变化 15 import pandas as pd 16 import matplotlib.pyplot as plt 17 import seaborn as sns 18 # 数据准备 19 df=pd.read_csv('C:/Users/home/电子游戏销量数据集.csv') 20 x = df['Year'] 21 y = df['Global_Sales'] 22 # 使用Seaborn画折线图 23 df = pd.DataFrame({'x': x, 'y': y}) 24 sns.lineplot(x="x", y="y", data=df) 25 plt.show() 26 27 #---------------------------------------------------------------- 28 29 #各游戏发行商占比 30 from pylab import * 31 mpl.rcParams['font.sans-serif'] = ['SimHei'] 32 mpl.rcParams['axes.unicode_minus'] = False 33 df=pd.read_csv('C:/Users/home/电子游戏销量数据集.csv') 34 df = (df['Publisher'].value_counts())[:16].to_frame() 35 plt.figure(figsize=(15,15)) 36 plt.pie(df['Publisher'], labels=df.index.values, autopct='%.1f%%') 37 plt.title('发行商占比',fontsize=20) 38 39 #---------------------------------------------------------------- 40 41 #各游戏类型占比 42 from pylab import * 43 mpl.rcParams['font.sans-serif'] = ['SimHei'] 44 mpl.rcParams['axes.unicode_minus'] = False 45 df=pd.read_csv('C:/Users/home/电子游戏销量数据集.csv') 46 df = (df['Genre'].value_counts())[:16].to_frame() 47 plt.figure(figsize=(15,15)) 48 plt.pie(df['Genre'], labels=df.index.values, autopct='%.1f%%') 49 plt.title('游戏类型占比',fontsize=20) 50 51 #---------------------------------------------------------------- 52 53 #游戏平台占比 54 from pylab import * 55 mpl.rcParams['font.sans-serif'] = ['SimHei'] 56 mpl.rcParams['axes.unicode_minus'] = False 57 df=pd.read_csv('C:/Users/home/电子游戏销量数据集.csv') 58 df = (df['Platform'].value_counts())[:16].to_frame() 59 plt.figure(figsize=(15,15)) 60 plt.pie(df['Platform'], labels=df.index.values, autopct='%.1f%%') 61 plt.title('游戏平台占比',fontsize=20) 62 63 #---------------------------------------------------------------- 64 65 # 绘制年份和销量的散点关系图 66 lx = df['Year'].apply(lambda x:float(x)) 67 # print(home_area.head()) 68 xl = df['Global_Sales'] 69 # print(total_price.head()) 70 plt.scatter(lx,xl,s=3) 71 plt.title('年份和销量关系',fontsize=15) 72 plt.xlabel('年份',fontsize=15) 73 plt.ylabel('全球销量',fontsize=15) 74 plt.grid(linestyle=":", color="r") 75 plt.show() 76 77 #---------------------------------------------------------------- 78 79 #查看年份和销量的二元变量分布 80 import matplotlib.pyplot as plt 81 import seaborn as sns 82 # 数据准备 83 # tips = sns.load_dataset("tips") 84 tips = pd.read_csv('C:/Users/home/电子游戏销量数据集.csv') 85 print(tips.head(10)) 86 # 用Seaborn画二元变量分布图(散点图,核密度图,Hexbin图) 87 sns.jointplot(x="Year", y="Global_Sales", data=tips, kind='scatter') 88 sns.jointplot(x="Year", y="Global_Sales", data=tips, kind='kde') 89 sns.jointplot(x="Year", y="Global_Sales", data=tips, kind='hex') 90 plt.show() 91 92 #---------------------------------------------------------------- 93 #查看平台与销量之间的关系 94 import pandas as pd 95 import numpy as np 96 import matplotlib.pyplot as plt 97 import seaborn as sns 98 99 df=pd.read_csv('C:/Users/home/电子游戏销量数据集.csv') 100 fig,ax = plt.subplots() 101 fig.set_size_inches(19,7) 102 sns.boxplot(x=df['Platform'],y=df['Global_Sales'],data=df) 103 plt.show() 104 105 #---------------------------------------------------------------- 106 107 #查看各平台下游戏数量 108 fig,ax = plt.subplots() 109 fig.set_size_inches(10,10) 110 xq = df['Platform'].value_counts().sort_values() 111 index = list(xq.index) 112 value = list(xq.values) 113 qx = pd.DataFrame({'Platform':index,'数量':value}) 114 qx.plot.barh(x='Platform',y='数量',ax=ax,color='blue',fontsize=12) 115 plt.legend(loc='right') 116 for a,b in zip(value,np.arange(0,14,1)): 117 plt.text(a+0.5,b,a,fontsize=12) 118 plt.show() 119 120 #---------------------------------------------------------------- 121 122 #对各地区近年销量可视化处理 123 #导入库 124 import matplotlib.pyplot as plt 125 plt.figure(figsize=(8,7)) 126 #北美 127 date = df.set_index('Year') #把日期列设为索引 128 date.index = pd.to_datetime(date.index) #把索引转为时间格式 129 plt.title('北美地区销量',fontsize=15) 130 plt.xlabel('年份',fontsize=15) 131 plt.ylabel('销量',fontsize=15) 132 plt.bar(df.index, df['NA_Sales']) #以日期为横轴,销量为纵轴绘制条形图 133 #欧洲 134 date = df.set_index('Year') 135 date.index = pd.to_datetime(date.index) 136 plt.title('欧洲地区销量',fontsize=15) 137 plt.xlabel('年份',fontsize=15) 138 plt.ylabel('销量',fontsize=15) 139 plt.bar(df.index, df['EU_Sales']) 140 #日本 141 date = df.set_index('Year') 142 date.index = pd.to_datetime(date.index) 143 plt.title('日本地区销量',fontsize=15) 144 plt.xlabel('年份',fontsize=15) 145 plt.ylabel('销量',fontsize=15) 146 plt.bar(df.index, df['JP_Sales']) 147 #其他 148 date = df.set_index('Year') 149 date.index = pd.to_datetime(date.index) 150 plt.title('其他地区销量',fontsize=15) 151 plt.xlabel('年份',fontsize=15) 152 plt.ylabel('销量',fontsize=15) 153 plt.bar(df.index, df['Other_Sales']) 154 #全球 155 date = df.set_index('Year') 156 date.index = pd.to_datetime(date.index) 157 plt.title('其他地区销量',fontsize=15) 158 plt.xlabel('年份',fontsize=15) 159 plt.ylabel('销量',fontsize=15) 160 plt.bar(df.index, df['Global_Sales']) 161 162 #---------------------------------------------------------------- 163 164 #各地区销量之间关系 165 import numpy as np 166 import matplotlib.pyplot as plt 167 from mpl_toolkits. mplot3d import Axes3D 168 fig = plt.figure() 169 ax = Axes3D(fig,auto_add_to_figure=False) 170 fig.add_axes(ax) 171 172 x = df['NA_Sales'] 173 y = df['EU_Sales'] 174 z = df['JP_Sales'] 175 ax. scatter(x, y, z) 176 ax.set_xlabel('北美地区销量') 177 ax.set_ylabel( '欧洲地区销量') 178 ax.set_zlabel('日本地区销量') 179 plt.show() 180 181 #---------------------------------------------------------------- 182 183 # 绘制词云,将游戏类型汇总 184 import jieba 185 from wordcloud import WordCloud 186 df=pd.read_csv('C:/Users/home/电子游戏销量数据集.csv') 187 text = '' 188 for line in df['Genre']: 189 text += line 190 # 使用jieba模块将字符串分割为单词列表 191 cut_text = ' '.join(jieba.cut(text)) 192 color_mask = imread('C:/Users/home/56.jpg') #设置背景图 193 cloud = WordCloud( 194 195 background_color = 'white', 196 # 对中文操作必须指明字体 197 font_path='C:\windows\Fonts\STZHONGS.TTF', 198 mask = color_mask, 199 max_words = 50, 200 max_font_size = 200 201 ).generate(cut_text) 202 203 # 保存词云图片 204 cloud.to_file('word1cloud.jpg') 205 plt.imshow(cloud) 206 plt.axis('off') 207 plt.show() 208 209 #---------------------------------------------------------------- 210 211 #探索电子游戏销量数据集中的多个成对双变量的分布 212 import matplotlib.pyplot as plt 213 import seaborn as sns 214 # 数据准备 215 # iris = sns.load_dataset('iris') 216 iris =pd.read_csv('C:/Users/home/电子游戏销量数据集.csv') 217 # 用Seaborn画成对关系 218 sns.pairplot(iris) 219 plt.show()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号