MySQL外键
一.自增特性缺陷
自增是跟随着主键儿存在的,插入值时可以不绑定主键 添加值会按照序号排列但在删除数据里的某条数据的时候会出现
但再次添加也是按照之前主键排序的方式进行下去,主键不会重置,其实往往碰到这种情况有解决办法,但非刻意不要使用
1.删除数据并重置主键值方法
truncate 表名 # truncate 关键字
'直接输入即可,后需从新添加数据 库还在重启了表内信息'
insert into 表名(字段名) valuse(数据1);
二.外键简介
外键:在MySQL中,外键是用于建议和加强两个数据表之间链家的一列或多列,他表示中的一个字段被另一个表中的字段引用,外键对相关表中的数据造成了一些限制,使MySQL能有保持参照完整性
举例说明:
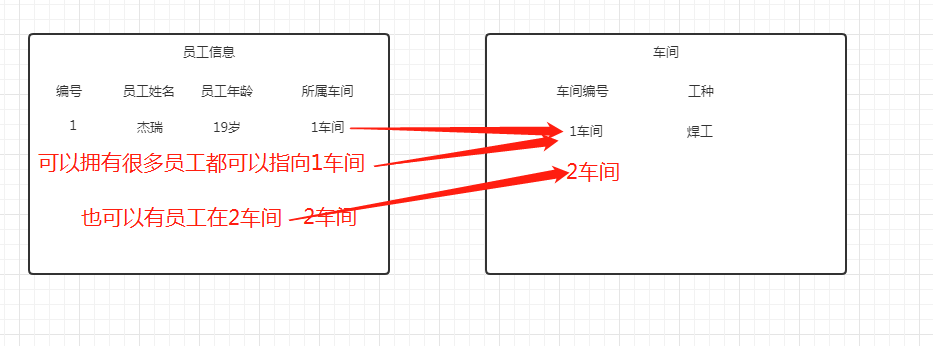
创建一张员工信息表要有姓名,年龄,哪个车间,什么工种
缺陷:猛地一看 对于这个表的扩展性很差 车间和工种添加一个工人就会被重复使用 不利于维护
决绝方法:将一张表一分为二,员工信息,车间工种(车间统一工种)
通过外键方法进行绑定关系
1.1员工表
员工表名暂且t1
"""
create table t1(id int primary auto_increment,
name varchar(32),
ataff int,
age int )
"""
创建员工表id绑定主键与自增 约束条件 方便查找与添加员工
1.2车间工种
车间工种暂且t2
"""
create table t2(id int primary auto_increment,
plant varchar(32),
eet varchar(32))
"""
外键关对应上述为例
,员工不可以同时在多个车间工作暂且算单一工种,员工不能拥有多个技能
但 车间也用拥有很多员工,工种也可以很多人拥有
三.外键的四种关系
使用上边的例子为例,关系表达式只能一对多不能一对一
外键字段建立在多的一方
1.一对多
关键字:foreingn key(我们这派出去对应的信息)
关键字:references 对应的表名(他的id)
# 员工表
create table t1(id int primary auto_increment,
name varchar(32),
age int,
plant int,
foreign key(plant) references t2(id) )
# 车间工种表
create table t2(id int primary auto_increment,
plant varchar(32),
eet varchar(32))

优先创建多(被关联的表,没有外键字段表) 在创建一(有外键字段的表)
插入时优先插入多(被关联的表,没有关联字段的表)
不然无法找到被关联表会报错
修改 删除 被关联数据表会产生阻碍
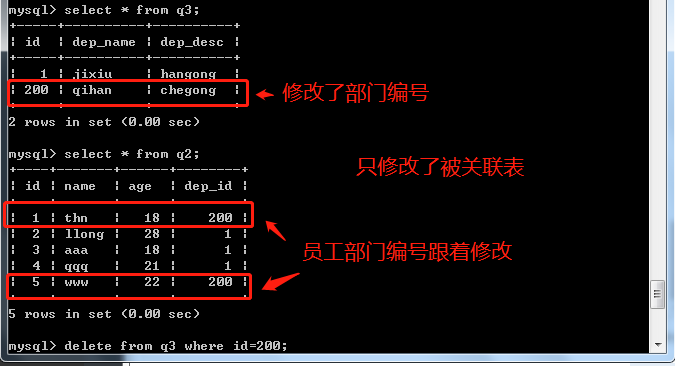
1.1级联更新级联删除
级联更新级联删除主要用于 关联数据与被关联数据之间的修改和删除
关键字 : on update cascade # 级联更新
关键字 : on delete cascade # 级联删除
需要加在有外键字段的表中
create table t1(id int primary auto_increment,
name varchar(32),
age int,
plant int,
foreign key(plant) references t2(id) # 不需要逗号
on update cascade
on delete cascade)
# 修改 update 表名 set id=200 where id=2;
# 删除 delete from 表名 where id=2;
通过级联更新与级联删除方法修改被关联
2.多对多
以图书与作者表为例
一本书可拥有多个作者,协作
一个作者可以拥有多本书
# 创建一个书表格
create table book(
id int primary key auto_increment,
title varchar(32),
price float(10,2),
author_id int,
foreign key(author_id) references author(id)
on updete cascade
on delete cascade);
# 创建一个作者的表
create table author(
id int primary key auto_increment,
name varchar(32),
gender enum('male','female')),
book_id int;
foreign key(book_id) references book(id)
on update cascade
on delete cascdae);
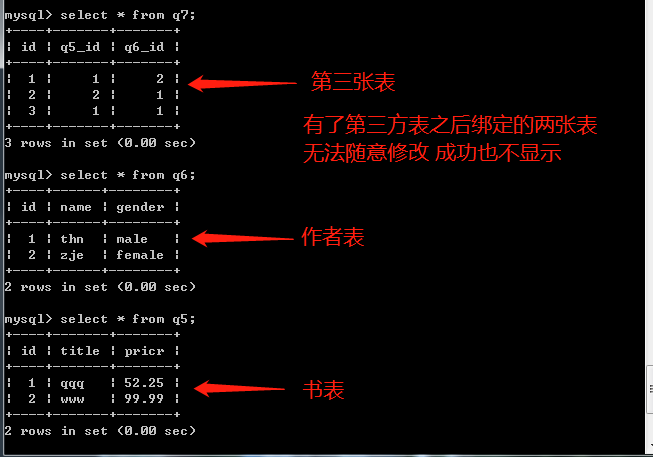
# 双向调用时肯定会报错 两个都是被关联表无法创建
# 需要创建第三张表 进行存储他们的关系
# 书
create table book(
id int primary key auto_increment,
title varchar(32),
price float(10,2));
# 作者
create table author(
id int primary key auto_increment,
name varchar(32),
gender enum('male','female'));
# 第三张表绑定关系
create table book_author(
id int primary key auto_increment,
author_id int,
book_id int,
foreign key(author_id) references author(id)
on update cascade
on delete cascade
foreign key(book_id) references book(id)
on update caseade
on delete caseade);
3.一对一
一对一数据分为两种部分
热数据:经常使用的数据 明面
冷数据:不经常使用的数据 隐藏面
为了节省资源并降低数据库压力 会将表一分为二
用户表:使用频率较高的数据字段
详情表:使用频频率较低的数据字段
一对一关系 一个用户表只能对应他自己的详情表
# 热数据
create table user(
id int primary key auto_increment,
name varchar(32),
user_detail_id int unique, # 添加了唯一性
gender enum('male','female')),
foreign key(user_detail_id) references userdetail(id)
on update cascade
on delete cascade);
# 冷数据
create table userdetail(
id int primar key auto_increment,
phone bigint,
age int);
和一对多本质基本一样但一对一是多了一个唯一性
四.查询关键字
点击查看代码
# 数据准备
create table emp(
id int primary key auto_increment,
name varchar(20) not null,
sex enum('male','female') not null default 'male', #大部分是男的
age int(3) unsigned not null default 28,
hire_date date not null,
post varchar(50),
post_comment varchar(100),
salary double(15,2),
office int, #一个部门一个屋子
depart_id int
);
#插入记录
#三个部门:教学,销售,运营
insert into emp(name,sex,age,hire_date,post,salary,office,depart_id) values
('jason','male',18,'20170301','张江第一帅形象代言',7300.33,401,1), #以下是教学部
('tom','male',78,'20150302','teacher',1000000.31,401,1),
('kevin','male',81,'20130305','teacher',8300,401,1),
('tony','male',73,'20140701','teacher',3500,401,1),
('owen','male',28,'20121101','teacher',2100,401,1),
('jack','female',18,'20110211','teacher',9000,401,1),
('jenny','male',18,'19000301','teacher',30000,401,1),
('sank','male',48,'20101111','teacher',10000,401,1),
('哈哈','female',48,'20150311','sale',3000.13,402,2),#以下是销售部门
('呵呵','female',38,'20101101','sale',2000.35,402,2),
('西西','female',18,'20110312','sale',1000.37,402,2),
('乐乐','female',18,'20160513','sale',3000.29,402,2),
('拉拉','female',28,'20170127','sale',4000.33,402,2),
('僧龙','male',28,'20160311','operation',10000.13,403,3), #以下是运营部门
('程咬金','male',18,'19970312','operation',20000,403,3),
('程咬银','female',18,'20130311','operation',19000,403,3),
('程咬铜','male',18,'20150411','operation',18000,403,3),
('程咬铁','female',18,'20140512','operation',17000,403,3);
五.查询关键字之select与from
select:用于指定查找的字段
from:用于指定查询的表
select id,name from mysql.user;
从musql.user 表内找出 id name 对应的所有数据
六.查询关键字之where筛选
# 1.查询id大于等于3 小于等于6的数据
select * from emp where id>=3 and id<=6;
select * from emp where id between 3 and 6;
# 2.查询薪资是20000或者18000或者17000的数据
select * from emp where salary=20000 or salary=18000 or salary=17000;
select * from emp where salary in (20000,18000,17000);
# 3.查询id小于3或者大于6的数据
select * from emp where id not between 3 and 6;
# 4.查询薪资不在20000,18000,17000的数据
select * from emp where salary not in (20000,18000,17000);
# 5.查询岗位描述为空的数据
select * from emp where post_comment is null;
# 6.查询员工姓名中包含字母o的员工姓名和薪资
'查询条件如果不是很明确的情况下统一称之为模糊查询关键字'
# 关键字:
like:开启模糊查询的关键字
# 关键符号:
%:匹配任意个数的任意字符
_:匹配单个个数的任意字符
select name,salary from emp where name like '%o%';
# 7.查询员工姓名是由四个字符组成的数据
select * from emp where name like '____';
select * from emp where char_length(name)=4;
七.查询关键字之group by分组
# 什么是分组?
按照指定的条件将单个单个的个体组织成一个个整体
'按照性别分组 按照部门分组 按照年龄分组 按照国家分组 等'
# 为什么需要分组?
分组的好处在于可以快速统计出某些数据
'最大薪资 平均年龄 最小年龄 总人数'
# 如何分组
select * from emp group by post;
"""
mysql5.7及以上版本默认自带sql_mode=only_full_group_by
该模式要求分组之后默认只可以直接获取分组的依据不能直接获取其他字段
原因是分组的目的就是按照分组的条件来管理诸多数据 最小单位应该是分组的依据而不是单个单个的数据
如果是MySQL5.6及以下版本 需要自己手动添加
"""
# 聚合函数
'专门用于分组之后的数据统计'
max # 统计最大值
min # 统计最小值
sum # 统计求和
count # 统计计数
avg # 统计平均值
# 1.统计每个部门的最高薪资
select post,max(salary) from emp group by post;
# 2.统计每个部门的平均薪资
select post,avg(salary) from emp group by post;
# 3.统计每个部门的员工人数
select post,count(id) from emp group by post;
# 4.统计每个部门的月工资开销
select post,sum(salary) from emp group by post;
# 5.统计每个部门最小的年龄数
select post,min(age) from emp group by post;
"""间接获取分组以外其他字段的数据"""
# 1.统计每个部门下所有员工的姓名
select post,group_concat(name) from emp group by post;
# 2.统计每个部门下所有员工的姓名和年龄
select post,group_concat(name,age) from emp group by post;
"""字段起别名"""
select post,group_concat(name) as '姓名' from emp group by post;
select id as '序号',name as '姓名' from emp;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号