
数据采集作业4
目录
1.第一题
1.1主要代码
点击查看代码
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.edge.service import Service
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.common.exceptions import NoSuchElementException, TimeoutException
import time
import pymysql
from beautifultable import BeautifulTable
driver = webdriver.Edge(service=Service())
class DatabaseManager:
def __init__(self):
self.db = None
self.cursor = None
self.connect()
def connect(self):
"""连接数据库"""
try:
self.db = pymysql.connect(
host='localhost',
user='root',
password='826922',
database='stocks_db',
charset='utf8mb4',
port=3306
)
self.cursor = self.db.cursor()
print("MySQL数据库连接成功")
self.create_table()
except Exception as e:
print(f"MySQL连接失败: {e}")
self.db = None
self.cursor = None
def create_table(self):
"""创建数据表"""
self.cursor.execute('DROP TABLE IF EXISTS stocks1')
try:
self.cursor.execute('''
CREATE TABLE IF NOT EXISTS stocks1 (
stock_code VARCHAR(20) PRIMARY KEY,
stock_name VARCHAR(50),
last_price DECIMAL(10,2),
change_percent VARCHAR(30),
change_amount DECIMAL(10,2),
volume VARCHAR(30),
turnover VARCHAR(30),
turnover_rate VARCHAR(30),
high_price DECIMAL(10,2),
low_price DECIMAL(10,2),
open_price DECIMAL(10,2),
close_price DECIMAL(10,2)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4
''')
self.db.commit()
print("数据表 stocks1 创建成功或已存在")
except Exception as e:
print(f"创建表失败: {e}")
def insert_stock_data(self, stock_data):
"""插入股票数据"""
if not self.db or not self.cursor:
print("数据库未连接,跳过数据插入")
return False
try:
sql = '''
INSERT INTO stocks1
(stock_code, stock_name, last_price, change_percent, change_amount,
volume, turnover,turnover_rate,high_price, low_price, open_price, close_price)
VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s,%s)
ON DUPLICATE KEY UPDATE
stock_name = VALUES(stock_name),
last_price = VALUES(last_price),
change_percent = VALUES(change_percent),
change_amount = VALUES(change_amount),
volume = VALUES(volume),
turnover = VALUES(turnover),turnover_rate = VALUES(turnover_rate),
high_price = VALUES(high_price),
low_price = VALUES(low_price),
open_price = VALUES(open_price),
close_price = VALUES(close_price)
'''
self.cursor.executemany(sql, stock_data)
self.db.commit()
print(f"成功插入/更新 {self.cursor.rowcount} 条股票数据")
return True
except Exception as e:
self.db.rollback()
print(f"数据插入失败: {e}")
return False
def get_html(url, max_page):
"""获取HTML数据"""
driver.get(url)
current_page = 1
data = []
while current_page <= max_page:
try:
print(f"\n正在获取第 {current_page} 页数据...")
# 等待表格数据加载完成
wait = WebDriverWait(driver, 10)
marks = wait.until(
EC.presence_of_all_elements_located(
(By.XPATH, '//table//tbody/tr[td[2]/a[contains(@href, "quote.eastmoney.com")]]'))
)
print(f"找到 {len(marks)} 条数据")
# 提取当前页的所有数据
for mark in marks:
try:
code = mark.find_element(By.XPATH, './/td[2]').text
name = mark.find_element(By.XPATH, './/td[3]').text
# 价格信息
last_price = mark.find_element(By.XPATH, './/td[5]').text
change_percent = mark.find_element(By.XPATH, './/td[6]').text
change_amount = mark.find_element(By.XPATH, './/td[7]').text
# 成交量信息
volume = mark.find_element(By.XPATH, './/td[8]').text
turnover = mark.find_element(By.XPATH, './/td[9]').text
turnover_rate = mark.find_element(By.XPATH, './/td[10]').text
# 价格区间
high_price = mark.find_element(By.XPATH, './/td[11]').text
low_price = mark.find_element(By.XPATH, './/td[12]').text
open_price = mark.find_element(By.XPATH, './/td[13]').text
close_price = mark.find_element(By.XPATH, './/td[14]').text
data.append([ code, name, last_price, change_percent, change_amount,
volume, turnover, turnover_rate, high_price, low_price,
open_price, close_price])
except NoSuchElementException as e:
print(f"提取数据时元素未找到: {e}")
continue
# 翻页逻辑(处理完当前页所有数据后再翻页)
if current_page < max_page:
if not click_next_page():
print("没有下一页,停止翻页")
break
else:
break # 已经达到最大页数,退出循环
# 当前页处理完成,页码递增
current_page += 1
time.sleep(2) # 翻页间隔
except TimeoutException:
print("页面加载超时,未找到数据")
break
except Exception as e:
print(f"获取第 {current_page} 页数据时出错: {e}")
break
return data # 添加返回值
def click_next_page():
try:
time.sleep(2)
# 查找并点击下一页按钮
next_buttons = driver.find_elements(By.XPATH, '//a[@title="下一页"]')
for button in next_buttons:
if button.is_displayed() and button.is_enabled():
driver.execute_script("arguments[0].click();", button)
time.sleep(3)
return True
return False
except Exception as e:
print(f"翻页失败: {e}")
return False
def main():
try:
markets = [
"https://quote.eastmoney.com/center/gridlist.html#hs_a_board",
"https://quote.eastmoney.com/center/gridlist.html#sh_a_board",
"https://quote.eastmoney.com/center/gridlist.html#sz_a_board"
]
market_names = ["沪深京A股", "上证A股", "深证A股"]
all_data = []
db_manager = DatabaseManager()
for i, url in enumerate(markets):
print(f"\n{'=' * 50}")
print(f"开始处理板块: {market_names[i]}")
print(f"{'=' * 50}")
data = get_html(url, 2)
if data:
all_data.extend(data)
print(f"{market_names[i]} 获取到 {len(data)} 条数据")
# 显示当前板块的数据预览
print(f"\n{market_names[i]} 数据:")
table = BeautifulTable()
table.set_style(BeautifulTable.STYLE_COMPACT)
table.columns.alignment = BeautifulTable.ALIGN_CENTER
table.columns.header = [
'代码', '名称', '最新价', '涨跌幅', '涨跌额',
'成交量', '成交额', '换手率', '最高价', '最低价', '开盘价', '昨收价'
]
table.columns.width = [14,12,12,12,12,12,12,12,12,12,12,12]
for product in data:
# 简化商品名称显示
table.rows.append(product)
print(table)
else:
print(f"{market_names[i]} 没有获取到数据")
# 板块间短暂停顿
if i < len(markets) - 1:
time.sleep(3)
if all_data:
success = db_manager.insert_stock_data(all_data)
if success:
print(f"成功保存股票数据到数据库")
else:
print("保存数据到数据库失败")
else:
print("没有获取到任何股票数据")
except Exception as e:
print(f"主程序执行出错: {e}")
finally:
input("按回车键关闭浏览器...")
driver.quit()
if __name__ == "__main__":
main()
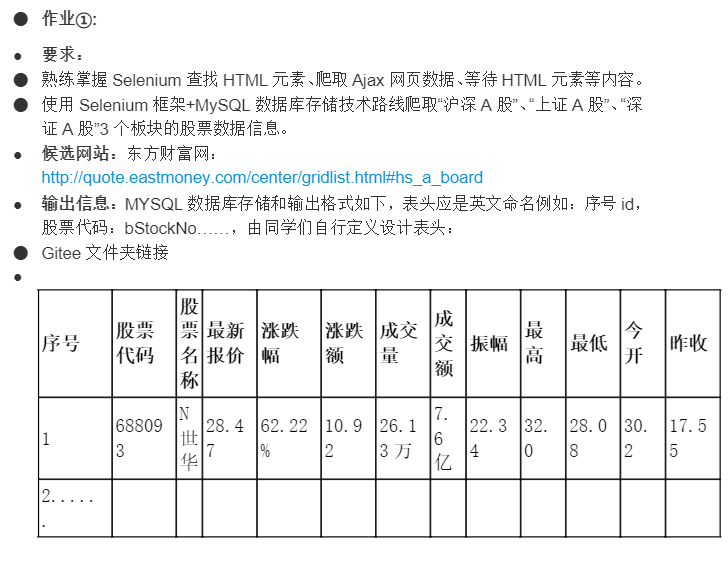
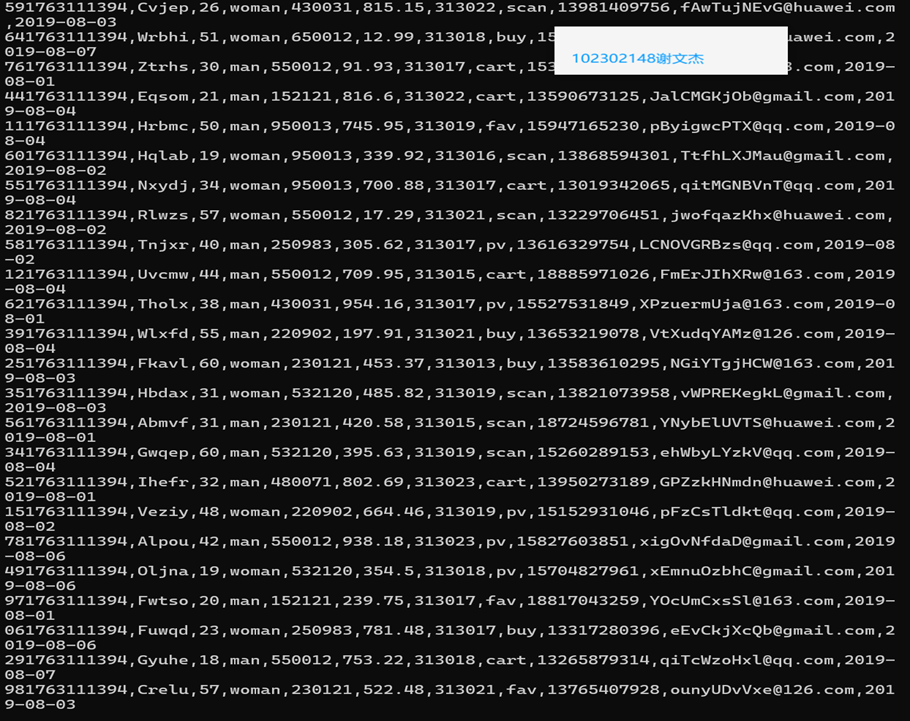
通过图片可以看到通过标签//table//tbody/tr定位到每个股票的数据,再通过td[i]来提取到对应的数据,但是仅靠这个提取,会出现一个空的标头,所以加上[td[2]/a[contains(@href, "quote.eastmoney.com")]],来更好的定位.
def get_html(url, max_page):
"""获取HTML数据"""
driver.get(url)
current_page = 1
data = []
while current_page <= max_page:
try:
print(f"\n正在获取第 {current_page} 页数据...")
# 等待表格数据加载完成
wait = WebDriverWait(driver, 10)
marks = wait.until(
EC.presence_of_all_elements_located(
(By.XPATH, '//table//tbody/tr[td[2]/a[contains(@href, "quote.eastmoney.com")]]'))
)
print(f"找到 {len(marks)} 条数据")
# 提取当前页的所有数据
for mark in marks:
try:
code = mark.find_element(By.XPATH, './/td[2]').text
name = mark.find_element(By.XPATH, './/td[3]').text
# 价格信息
last_price = mark.find_element(By.XPATH, './/td[5]').text
change_percent = mark.find_element(By.XPATH, './/td[6]').text
change_amount = mark.find_element(By.XPATH, './/td[7]').text
# 成交量信息
volume = mark.find_element(By.XPATH, './/td[8]').text
turnover = mark.find_element(By.XPATH, './/td[9]').text
turnover_rate = mark.find_element(By.XPATH, './/td[10]').text
# 价格区间
high_price = mark.find_element(By.XPATH, './/td[11]').text
low_price = mark.find_element(By.XPATH, './/td[12]').text
open_price = mark.find_element(By.XPATH, './/td[13]').text
close_price = mark.find_element(By.XPATH, './/td[14]').text
data.append([ code, name, last_price, change_percent, change_amount,
volume, turnover, turnover_rate, high_price, low_price,
open_price, close_price])
except NoSuchElementException as e:
print(f"提取数据时元素未找到: {e}")
continue
# 翻页逻辑(处理完当前页所有数据后再翻页)
if current_page < max_page:
if not click_next_page():
print("没有下一页,停止翻页")
break
else:
break
# 当前页处理完成,页码递增
current_page += 1
time.sleep(2) # 翻页间隔
except TimeoutException:
print("页面加载超时,未找到数据")
break
except Exception as e:
print(f"获取第 {current_page} 页数据时出错: {e}")
break
return data
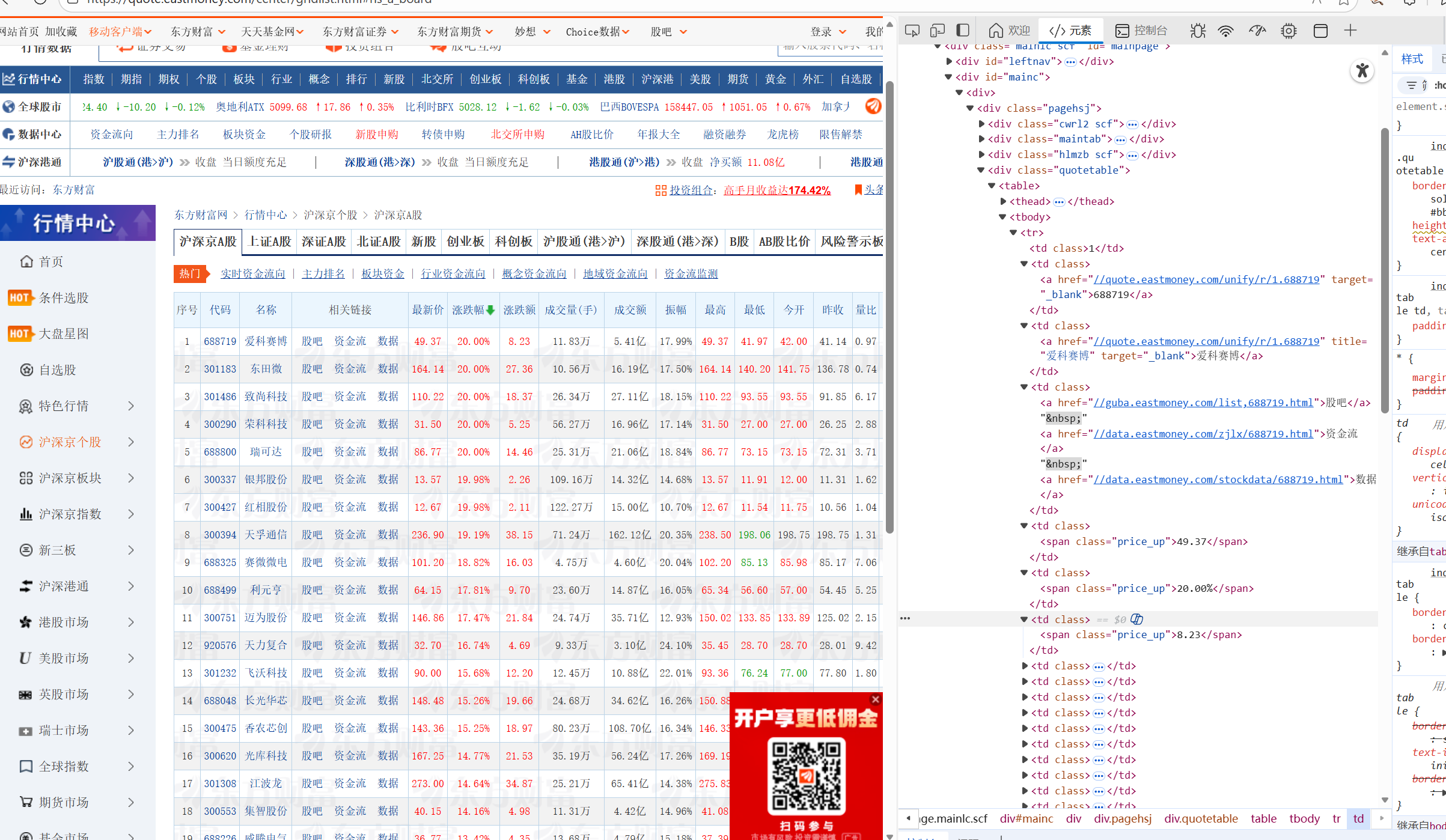
对于翻页,通过定位到下一页的按钮,然后自动点击。
def click_next_page():
try:
time.sleep(2)
# 查找并点击下一页按钮
next_buttons = driver.find_elements(By.XPATH, '//a[@title="下一页"]')
for button in next_buttons:
if button.is_displayed() and button.is_enabled():
driver.execute_script("arguments[0].click();", button)
time.sleep(3)
return True
return False
except Exception as e:
print(f"翻页失败: {e}")
return False
再往数据库里面存储数据
点击查看代码
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.edge.service import Service
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.common.exceptions import NoSuchElementException, TimeoutException
import time
import pymysql
from beautifultable import BeautifulTable
driver = webdriver.Edge(service=Service())
class DatabaseManager:
def __init__(self):
self.db = None
self.cursor = None
self.connect()
def connect(self):
"""连接数据库"""
try:
self.db = pymysql.connect(
host='localhost',
user='root',
password='826922',
database='stocks_db',
charset='utf8mb4',
port=3306
)
self.cursor = self.db.cursor()
print("MySQL数据库连接成功")
self.create_table()
except Exception as e:
print(f"MySQL连接失败: {e}")
self.db = None
self.cursor = None
def create_table(self):
"""创建数据表"""
self.cursor.execute('DROP TABLE IF EXISTS stocks1')
try:
self.cursor.execute('''
CREATE TABLE IF NOT EXISTS stocks1 (
stock_code VARCHAR(20) PRIMARY KEY,
stock_name VARCHAR(50),
last_price DECIMAL(10,2),
change_percent VARCHAR(30),
change_amount DECIMAL(10,2),
volume VARCHAR(30),
turnover VARCHAR(30),
turnover_rate VARCHAR(30),
high_price DECIMAL(10,2),
low_price DECIMAL(10,2),
open_price DECIMAL(10,2),
close_price DECIMAL(10,2)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4
''')
self.db.commit()
print("数据表 stocks1 创建成功或已存在")
except Exception as e:
print(f"创建表失败: {e}")
def insert_stock_data(self, stock_data):
"""插入股票数据"""
if not self.db or not self.cursor:
print("数据库未连接,跳过数据插入")
return False
try:
sql = '''
INSERT INTO stocks1
(stock_code, stock_name, last_price, change_percent, change_amount,
volume, turnover,turnover_rate,high_price, low_price, open_price, close_price)
VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s,%s)
ON DUPLICATE KEY UPDATE
stock_name = VALUES(stock_name),
last_price = VALUES(last_price),
change_percent = VALUES(change_percent),
change_amount = VALUES(change_amount),
volume = VALUES(volume),
turnover = VALUES(turnover),turnover_rate = VALUES(turnover_rate),
high_price = VALUES(high_price),
low_price = VALUES(low_price),
open_price = VALUES(open_price),
close_price = VALUES(close_price)
'''
self.cursor.executemany(sql, stock_data)
self.db.commit()
print(f"成功插入/更新 {self.cursor.rowcount} 条股票数据")
return True
except Exception as e:
self.db.rollback()
print(f"数据插入失败: {e}")
return False
1.2实验结果
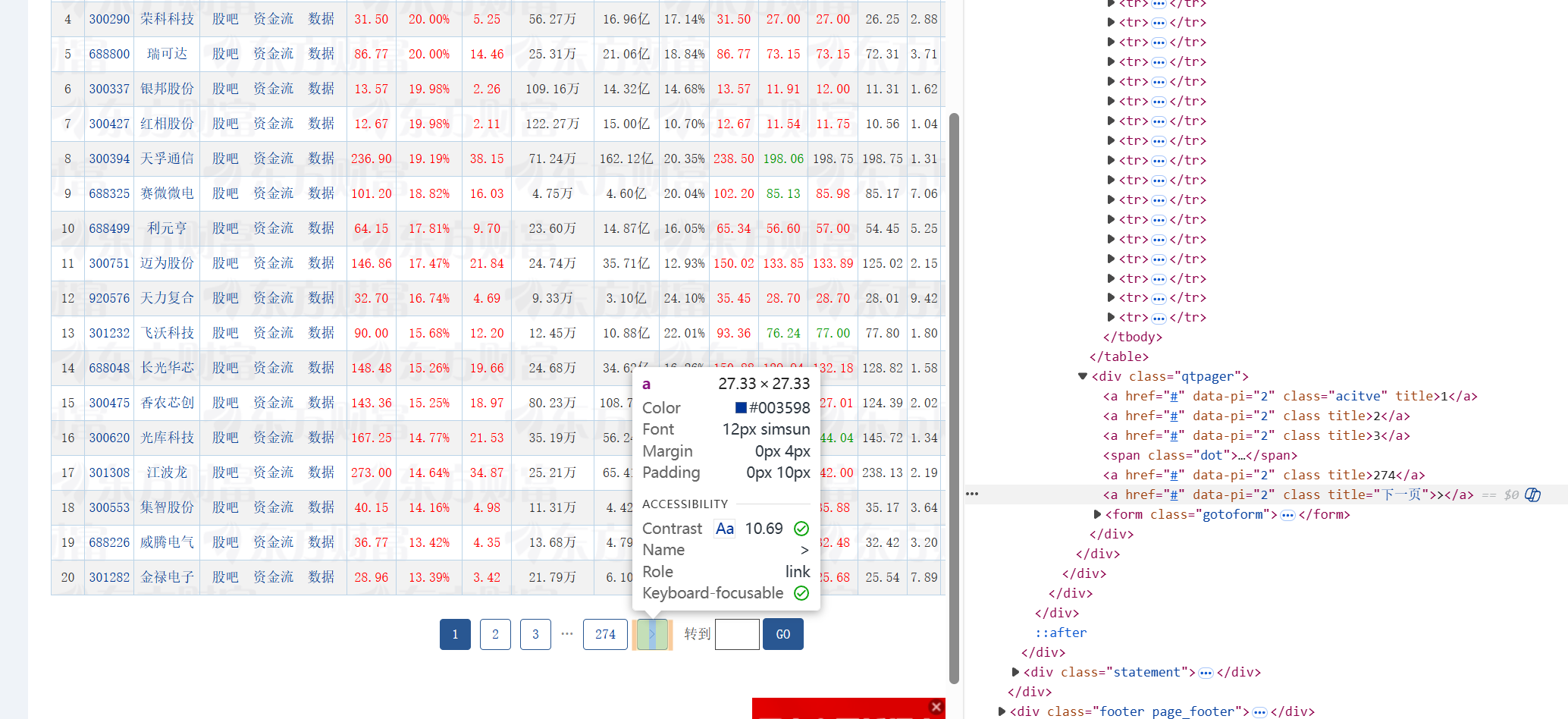
从运行结果里面查看:
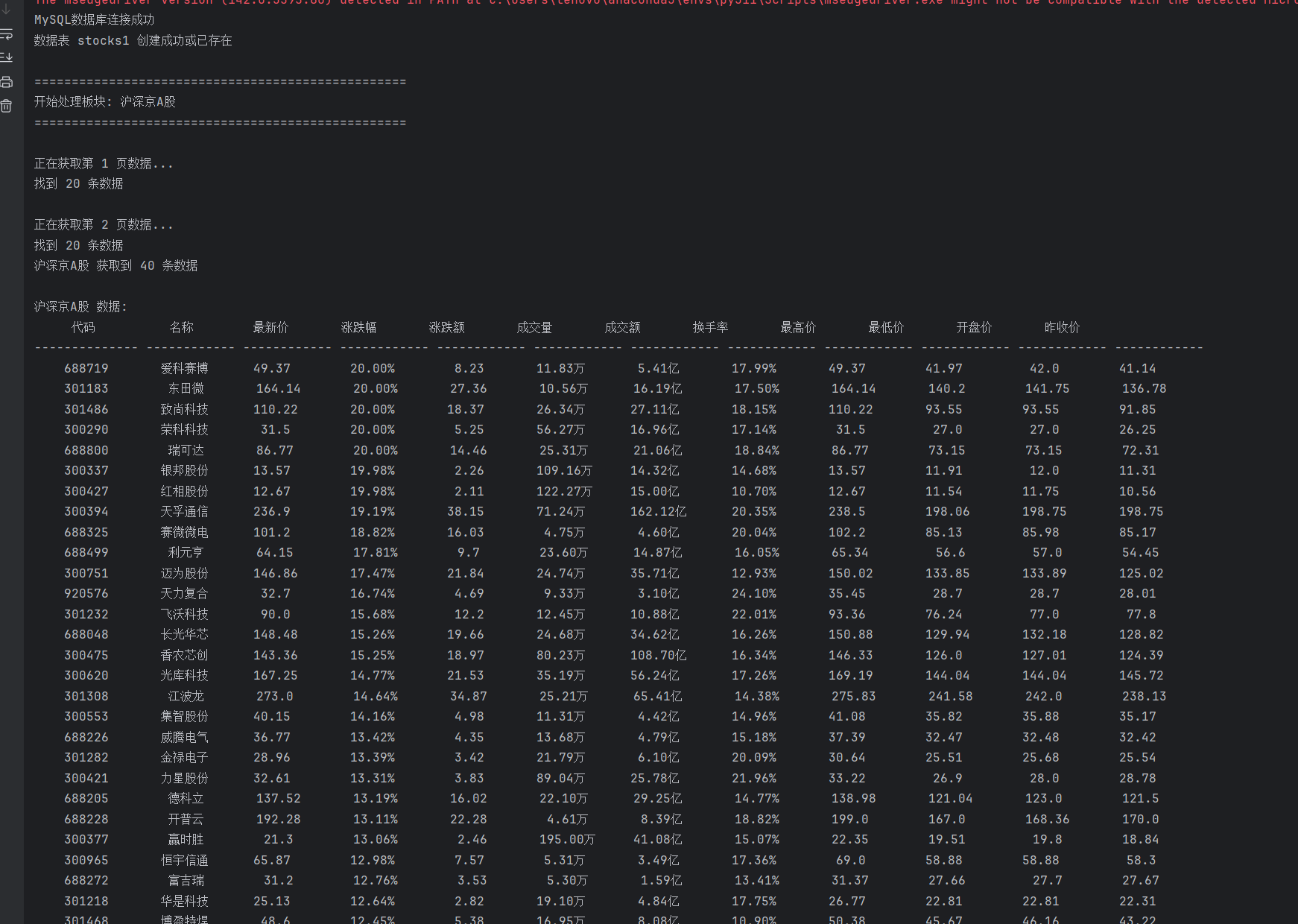
从Mysql里面查看:
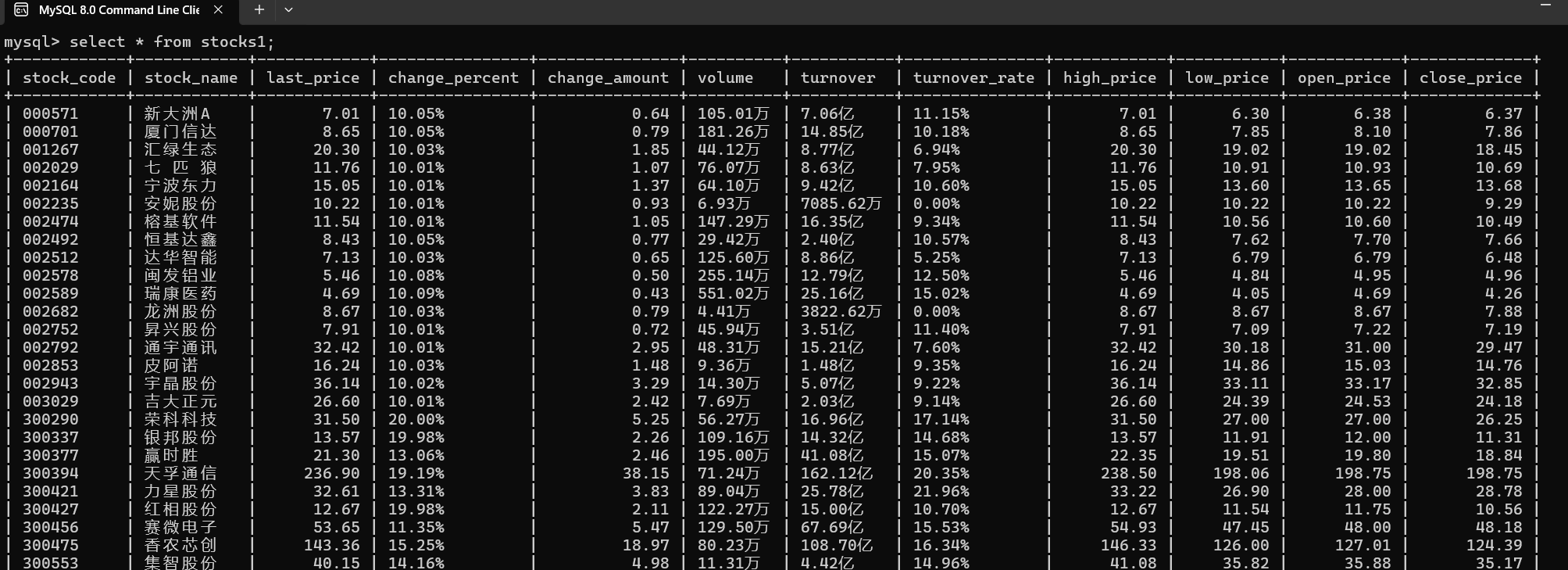
1.3心得提会
在本次实验中,通过使用 Selenium 爬取了东方财富网的股票数据。在提取数据的时候,不需要做可以处理,可以直接读出单位与正确的数据格式,其次,在翻页的时候,可以通过定位到下一页的按钮的位置,直接进行点击,而非之前的,需要采用url里面的页数的参数,来作为翻页。最后往数据库里面使用ON DUPLICATE KEY UPDATE语句的设计很实用,能够实现数据的更新而非简单插入。
通过这个股票数据爬取项目的实践,我深刻体会到编程不仅是代码的堆砌,更是一场与数据和细节的博弈。在数据抓取中,最复杂的往往不是技术本身,而是对网站结构变化的应对和处理各种意外情况的能力。翻页逻辑的调试、数据格式的统一、异常处理的完善,每一步都需要严谨的思考。
2.第二题
2.1主要代码
点击查看代码
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.edge.service import Service
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import time
from beautifultable import BeautifulTable
from selenium.webdriver.common.keys import Keys
import pymysql
driver = webdriver.Edge(service=Service())
#数据库:
class DatabaseManager:
def __init__(self):
self.db = None
self.cursor = None
self.connect()
def connect(self):
"""连接数据库"""
try:
self.db = pymysql.connect(
host='localhost',
user='root',
password='826922',
database='mooc_db',
charset='utf8mb4',
port=3306
)
self.cursor = self.db.cursor()
print("MySQL数据库连接成功")
self.create_table()
except Exception as e:
print(f"MySQL连接失败: {e}")
self.db = None
self.cursor = None
def create_table(self):
"""创建数据表"""
self.cursor.execute('DROP TABLE IF EXISTS mooc1')
try:
self.cursor.execute('''
CREATE TABLE IF NOT EXISTS mooc1 (
mooc_name VARCHAR(255),
school VARCHAR(100),
teacher VARCHAR(100),
teamates TEXT,
num VARCHAR(50),
schedule VARCHAR(100),
text TEXT
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4
''')
self.db.commit()
print("数据表 mooc1 创建成功或已存在")
except Exception as e:
print(f"创建表失败: {e}")
def insert_mooc_data(self, mooc_data):
"""插入mooc数据"""
if not self.db or not self.cursor:
print("数据库未连接,跳过数据插入")
return False
try:
sql = '''
INSERT INTO mooc1
(mooc_name, school, teacher, teamates, num,schedule,text)
VALUES (%s, %s, %s, %s, %s, %s, %s)
'''
self.cursor.executemany(sql, mooc_data)
self.db.commit()
print(f"成功插入/更新 {self.cursor.rowcount} 条股票数据")
return True
except Exception as e:
self.db.rollback()
print(f"数据插入失败: {e}")
return False
def click_login_button():
try:
wait = WebDriverWait(driver, 10)
login_button = wait.until(EC.element_to_be_clickable((By.CLASS_NAME,'_3uWA6')))
login_button.click()
print("点击登录按钮成功")
return True
except Exception as e:
print(f"点击登录按钮失败: {e}")
return False
def fill_login_form():
try:
try:
# 查找所有iframe
iframes = driver.find_elements(By.TAG_NAME, "iframe")
print(f"找到 {len(iframes)} 个iframe")
# 切换到第一个iframe(通常是登录框)
driver.switch_to.frame(iframes[0])
print("已切换到第一个iframe")
except Exception as e:
print(f"切换iframe失败: {e}")
time.sleep(2) #等待切换至iframe结构
#1.找到手机号输入框
phone_input = driver.find_element(By.ID, "phoneipt")
phone_input.send_keys("15880128200")
print("已输入手机号")
time.sleep(1)
password_input = driver.find_element(By.CLASS_NAME, "j-inputtext")
password_input.send_keys("Xwj.826922")
print("已输入密码")
# 点击登录
submit_btn = driver.find_element(By.ID, 'submitBtn')
submit_btn.click()
print("已提交登录")
#再切换回原本的iframe结构
driver.switch_to.default_content()
return True
except Exception as e:
print(f"自动填写失败: {e}")
return False
def find_selection(keyword):
print("等待页面加载...")
time.sleep(3)
try:
select_btn = driver.find_element(By.CLASS_NAME, "ant-input")
select_btn.clear()
select_btn.send_keys(keyword)
print("已成功输入数据")
select_btn.send_keys(Keys.ENTER)
print("已按回车键搜索")
time.sleep(10)
return True
except Exception as e:
print(f"搜索失败:{e}")
return False
def get_html():
wait = WebDriverWait(driver, 10)
wait.until(EC.presence_of_element_located((By.CLASS_NAME, "_3NYsM")))
data=[]
# 给页面更多时间加载
time.sleep(2)
# 查找所有搜索结果项
result_items = driver.find_elements(By.CLASS_NAME, "_3NYsM")
print(f"找到 {len(result_items)} 个搜索结果")
for mark in result_items:
title = mark.find_element(By.CLASS_NAME, '_1vfZ-').text.strip()
author_elements = mark.find_elements(By.CLASS_NAME, '_3t_C8')
teacher=author_elements[0].text
teammates = ' '.join([auth.text.strip() for auth in author_elements])
school = mark.find_elements(By.CLASS_NAME, '_3vJDG')[0].text.strip() if mark.find_elements(By.CLASS_NAME, '_3vJDG') else 'Null'
num=mark.find_element(By.CLASS_NAME, '_CWjg').text.strip()
text = mark.find_element(By.CLASS_NAME, '_3JEMz').text.strip()
schedule = mark.find_elements(By.CLASS_NAME, 'NOdDs')[0].text.strip() if mark.find_elements(By.CLASS_NAME, 'NOdDs') else 'Null'
data.append([title,school,teacher, teammates, num,schedule,text])
return data
def main(url):
db_manager =DatabaseManager()
all_data=[]
driver.get(url)
wait = WebDriverWait(driver, 10)
click_login_button()
time.sleep(10) # 等待10秒
fill_login_form()
time.sleep(10)
print("等待登录完成...")
time.sleep(5) # 等待页面跳转和加载
# 检查是否登录成功
print("在新页面查找搜索框...")
find_selection("计算机网络")
all_data=get_html()
if all_data:
success=db_manager.insert_mooc_data(all_data)
if success:
print(f"成功保存{len(all_data)}条数据到数据库")
else:
print("保存数据到数据库失败")
else:
print("没有获取到课程数据")
print("等待结束,页面即将关闭")
return all_data
if __name__ == '__main__':
url="https://www.icourse163.org/"
all_data=main(url)
table = BeautifulTable()
table.set_style(BeautifulTable.STYLE_COMPACT)
table.columns.alignment = BeautifulTable.ALIGN_CENTER
table.columns.header = [
'课程名称', '学校', '老师', '团队成员', '参与人数',
'进度', '简介'
]
table.columns.width = [20, 18, 14,20,14,20,100]
for course in all_data:
# 简化商品名称显示
table.rows.append(course)
print(table)
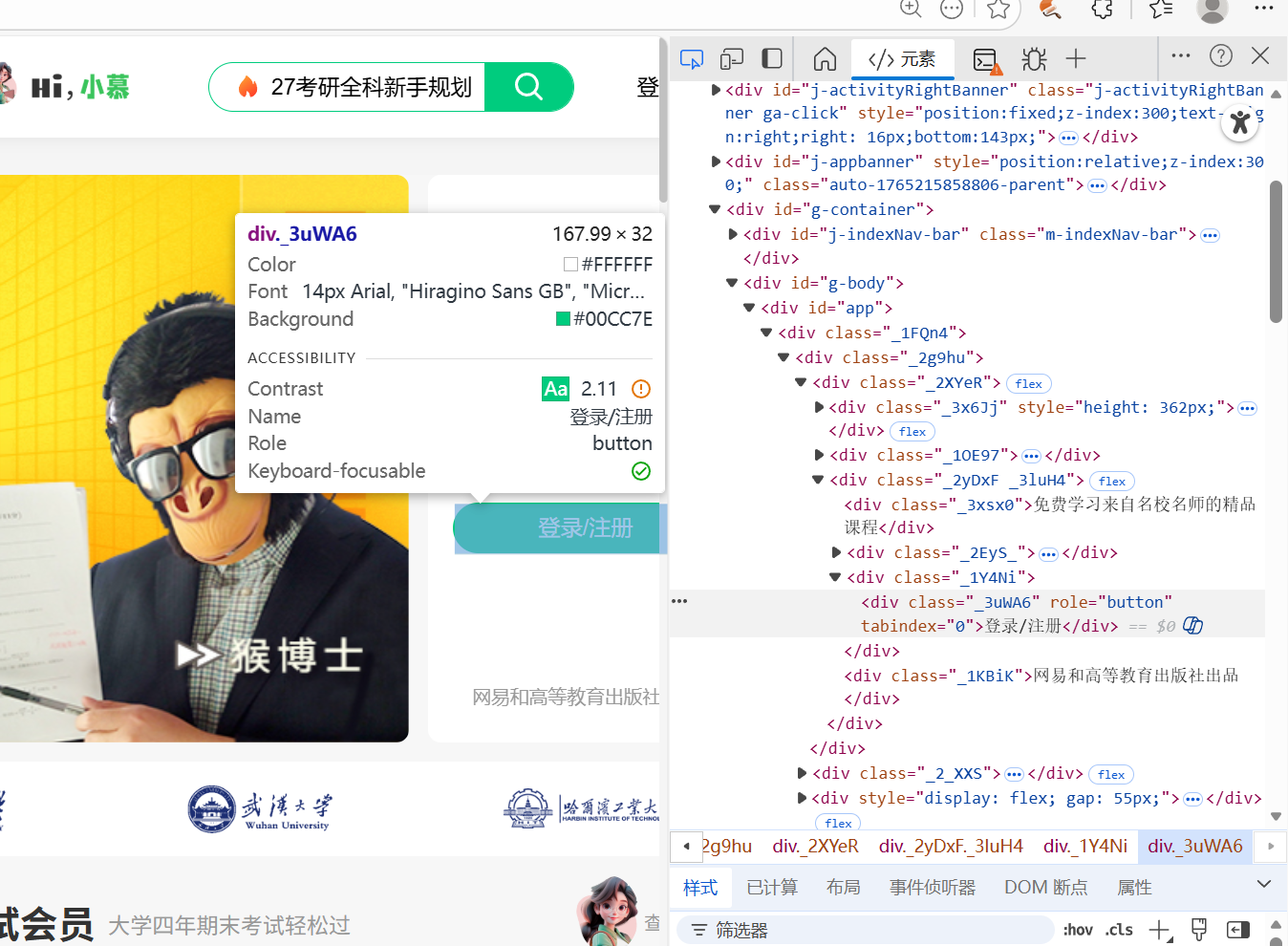
对于爬去中国mooc网时,首先要是实现自动登录的功能,所以使用click_login_button函数,找到定位到‘登录’的按钮
def click_login_button():
try:
wait = WebDriverWait(driver, 10)
login_button = wait.until(EC.element_to_be_clickable((By.CLASS_NAME,'_3uWA6')))
login_button.click()
print("点击登录按钮成功")
return True
except Exception as e:
print(f"点击登录按钮失败: {e}")
return False
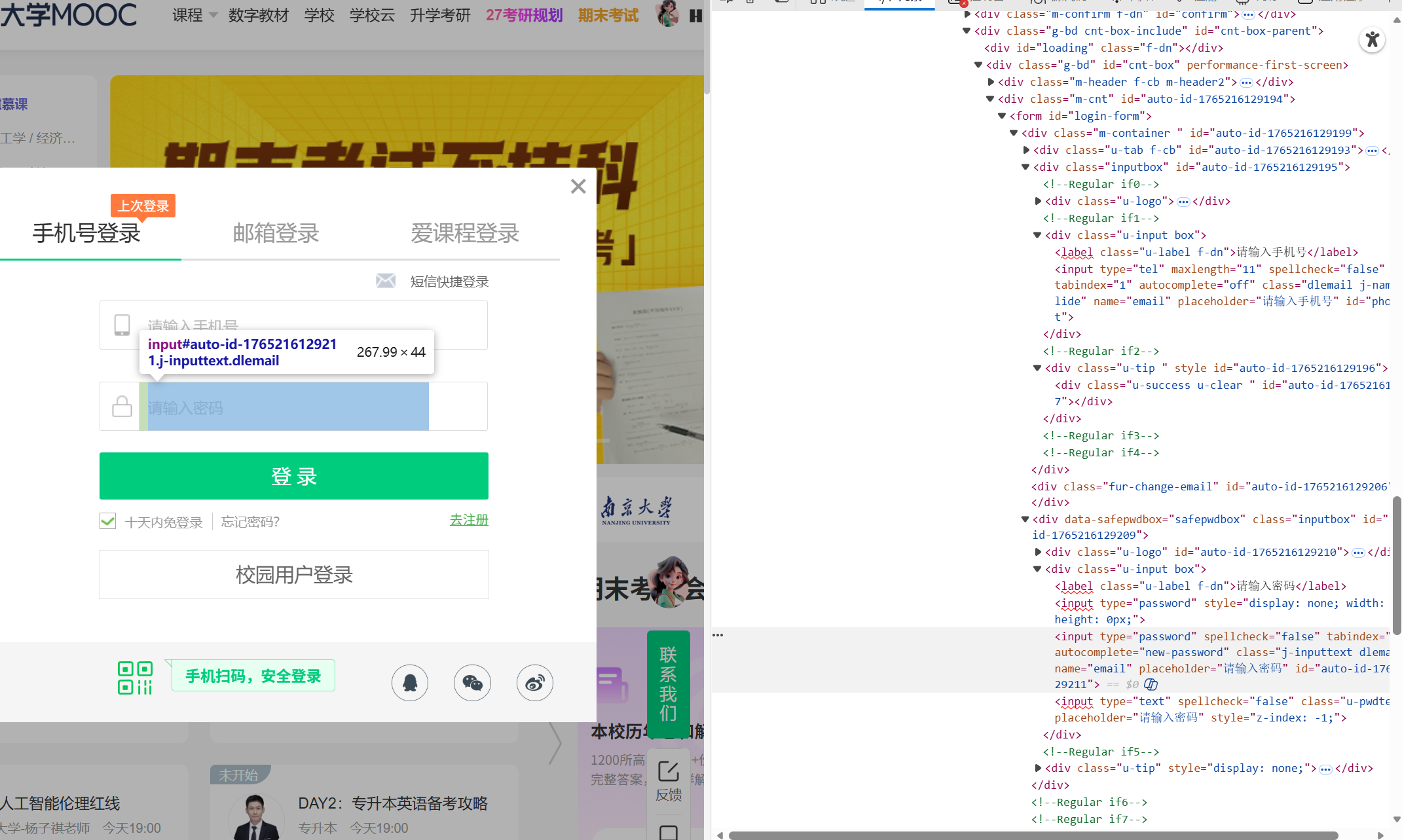
点击登录后,会弹出登录页面,但是输入框是一个嵌套的iframe结构,所以需要切换至iframe,在这里面定位到输入手机号和密码,输入手机号与密码,实现自动登录,并且登录完后需要再重新切换回原本的iframe结构。
def fill_login_form():
try:
try:
# 查找所有iframe
iframes = driver.find_elements(By.TAG_NAME, "iframe")
print(f"找到 {len(iframes)} 个iframe")
# 切换到第一个iframe(通常是登录框)
driver.switch_to.frame(iframes[0])
print("已切换到第一个iframe")
except Exception as e:
print(f"切换iframe失败: {e}")
time.sleep(2) #等待切换至iframe结构
#1.找到手机号输入框
phone_input = driver.find_element(By.ID, "phoneipt")
phone_input.send_keys("15880128200")
print("已输入手机号")
time.sleep(1)
password_input = driver.find_element(By.CLASS_NAME, "j-inputtext")
password_input.send_keys("Xwj.826922")
print("已输入密码")
# 点击登录
submit_btn = driver.find_element(By.ID, 'submitBtn')
submit_btn.click()
print("已提交登录")
#再切换回原本的iframe结构
driver.switch_to.default_content()
return True
except Exception as e:
print(f"自动填写失败: {e}")
return False
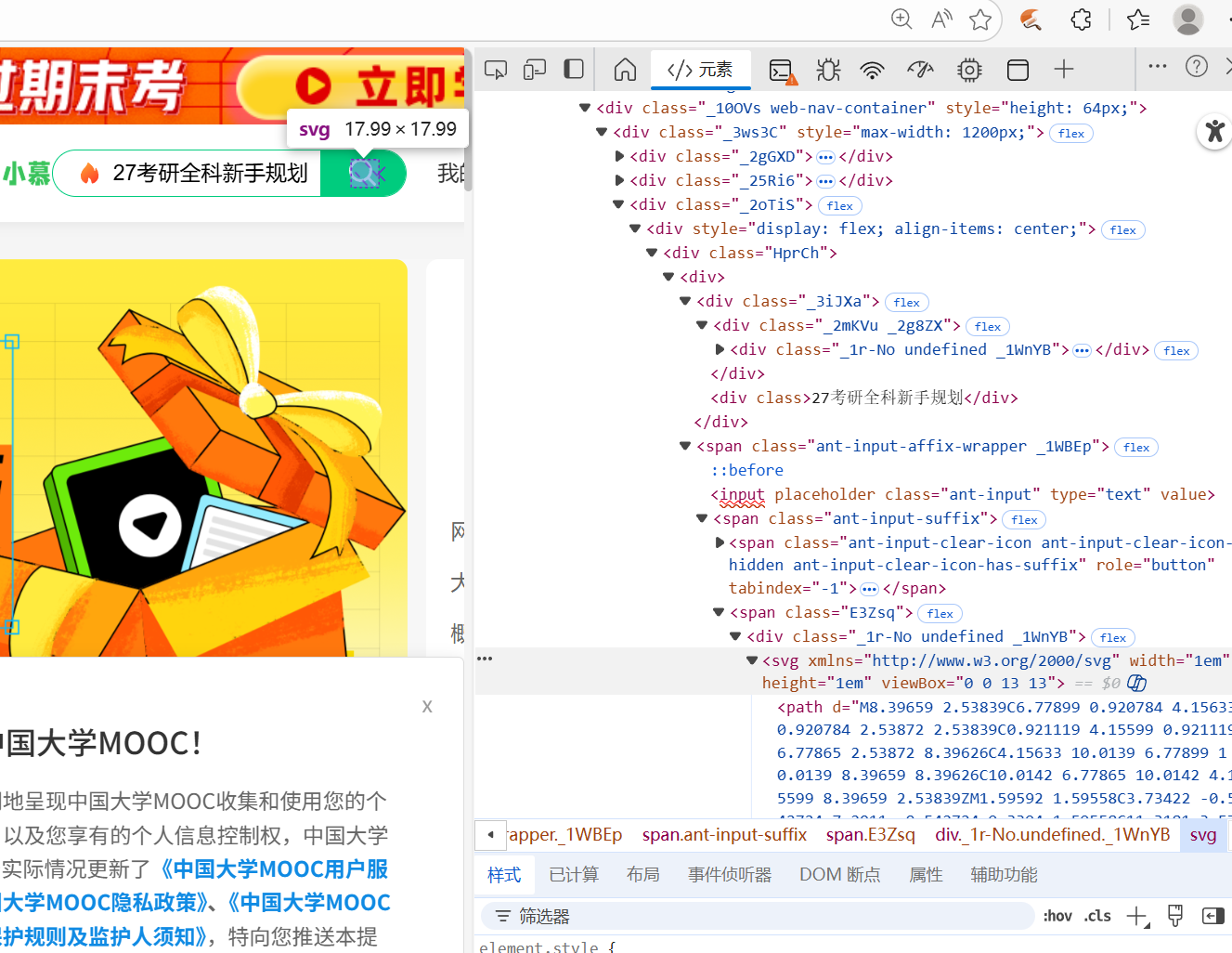
在成功登录后,定位搜索框,input数据,再点击搜索,找到需要的课程。
def find_selection(keyword):
print("等待页面加载...")
time.sleep(3)
try:
select_btn = driver.find_element(By.CLASS_NAME, "ant-input")
select_btn.clear()
select_btn.send_keys(keyword)
print("已成功输入数据")
select_btn.send_keys(Keys.ENTER)
print("已按回车键搜索")
time.sleep(10)
return True
except Exception as e:
print(f"搜索失败:{e}")
return False
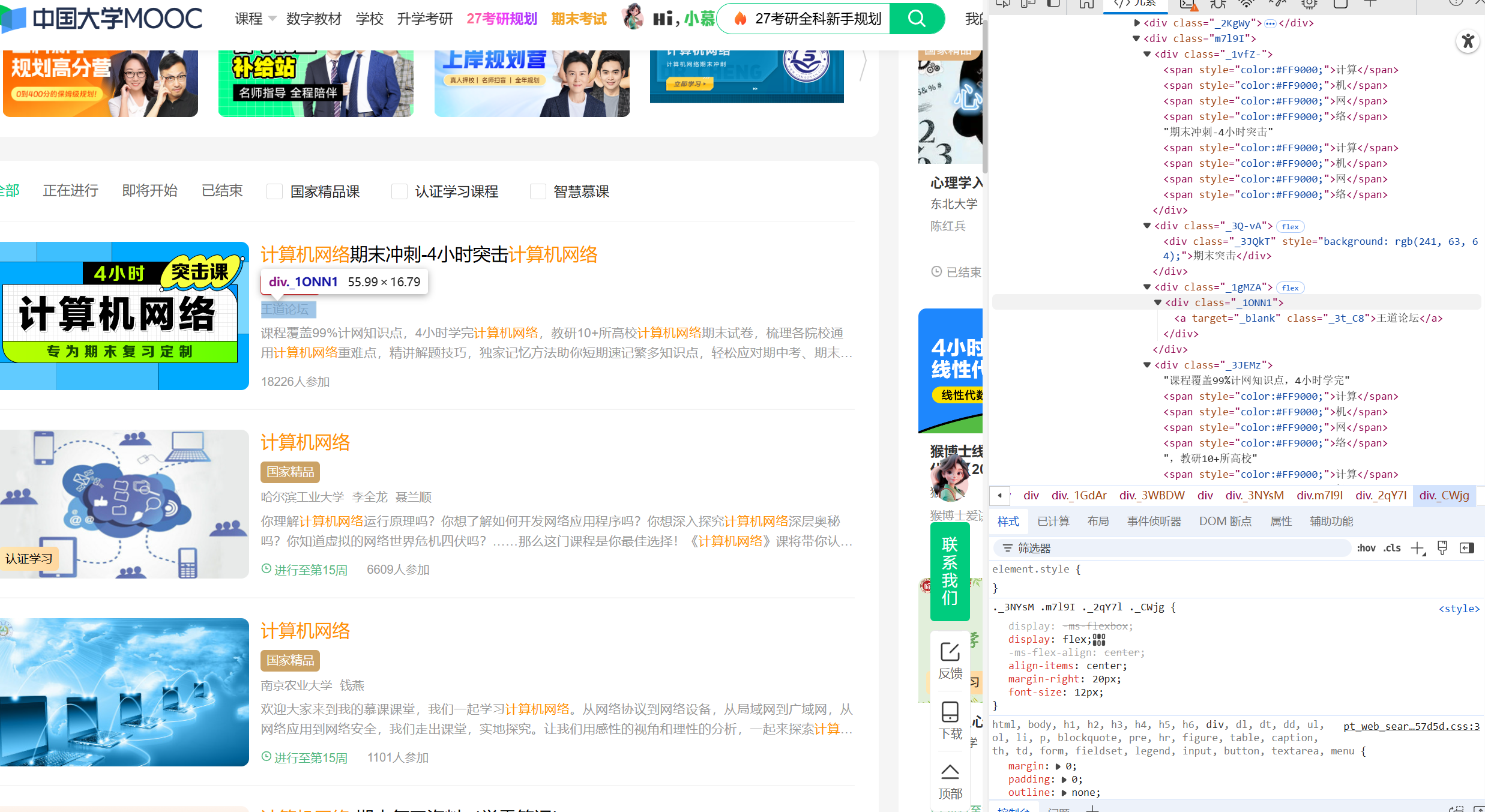
在搜索后,到达课程页面,最后开始爬取课程,将没有的数据设置为Null。
def get_html():
wait = WebDriverWait(driver, 10)
wait.until(EC.presence_of_element_located((By.CLASS_NAME, "_3NYsM")))
data=[]
# 给页面更多时间加载
time.sleep(2)
# 查找所有搜索结果项
result_items = driver.find_elements(By.CLASS_NAME, "_3NYsM")
print(f"找到 {len(result_items)} 个搜索结果")
for mark in result_items:
title = mark.find_element(By.CLASS_NAME, '_1vfZ-').text.strip()
author_elements = mark.find_elements(By.CLASS_NAME, '_3t_C8')
teacher=author_elements[0].text
teammates = ' '.join([auth.text.strip() for auth in author_elements])
school = mark.find_elements(By.CLASS_NAME, '_3vJDG')[0].text.strip() if mark.find_elements(By.CLASS_NAME, '_3vJDG') else 'Null'
num=mark.find_element(By.CLASS_NAME, '_CWjg').text.strip()
text = mark.find_element(By.CLASS_NAME, '_3JEMz').text.strip()
schedule = mark.find_elements(By.CLASS_NAME, 'NOdDs')[0].text.strip() if mark.find_elements(By.CLASS_NAME, 'NOdDs') else 'Null'
data.append([title,school,teacher, teammates, num,schedule,text])
return data
最后往数据库里面插入数据:
点击查看代码
class DatabaseManager:
def __init__(self):
self.db = None
self.cursor = None
self.connect()
def connect(self):
"""连接数据库"""
try:
self.db = pymysql.connect(
host='localhost',
user='root',
password='826922',
database='mooc_db',
charset='utf8mb4',
port=3306
)
self.cursor = self.db.cursor()
print("MySQL数据库连接成功")
self.create_table()
except Exception as e:
print(f"MySQL连接失败: {e}")
self.db = None
self.cursor = None
def create_table(self):
"""创建数据表"""
self.cursor.execute('DROP TABLE IF EXISTS mooc1')
try:
self.cursor.execute('''
CREATE TABLE IF NOT EXISTS mooc1 (
mooc_name VARCHAR(255),
school VARCHAR(100),
teacher VARCHAR(100),
teamates TEXT,
num VARCHAR(50),
schedule VARCHAR(100),
text TEXT
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4
''')
self.db.commit()
print("数据表 mooc1 创建成功或已存在")
except Exception as e:
print(f"创建表失败: {e}")
def insert_mooc_data(self, mooc_data):
"""插入mooc数据"""
if not self.db or not self.cursor:
print("数据库未连接,跳过数据插入")
return False
try:
sql = '''
INSERT INTO mooc1
(mooc_name, school, teacher, teamates, num,schedule,text)
VALUES (%s, %s, %s, %s, %s, %s, %s)
'''
self.cursor.executemany(sql, mooc_data)
self.db.commit()
print(f"成功插入/更新 {self.cursor.rowcount} 条股票数据")
return True
except Exception as e:
self.db.rollback()
print(f"数据插入失败: {e}")
return False
2.2运行结果
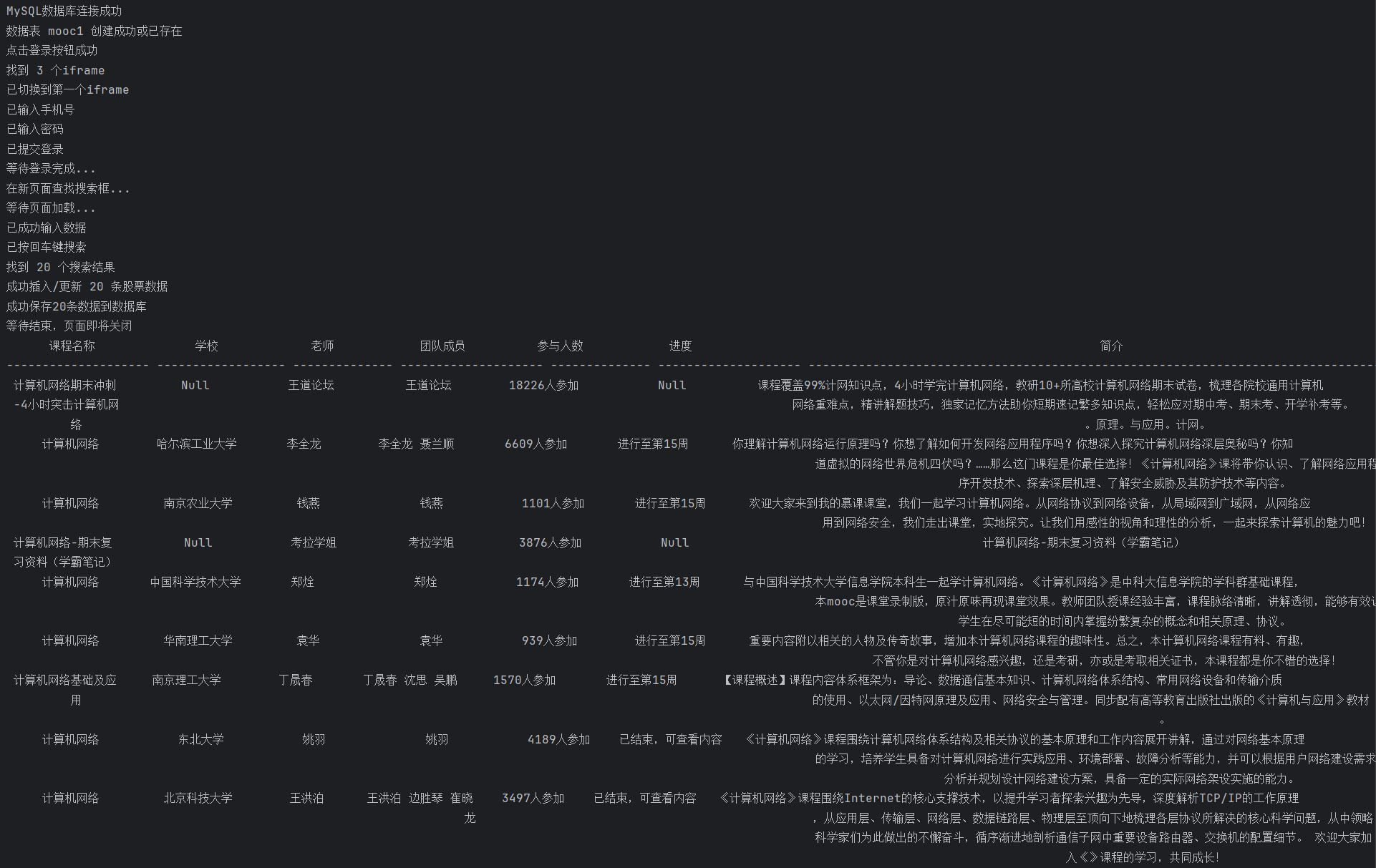
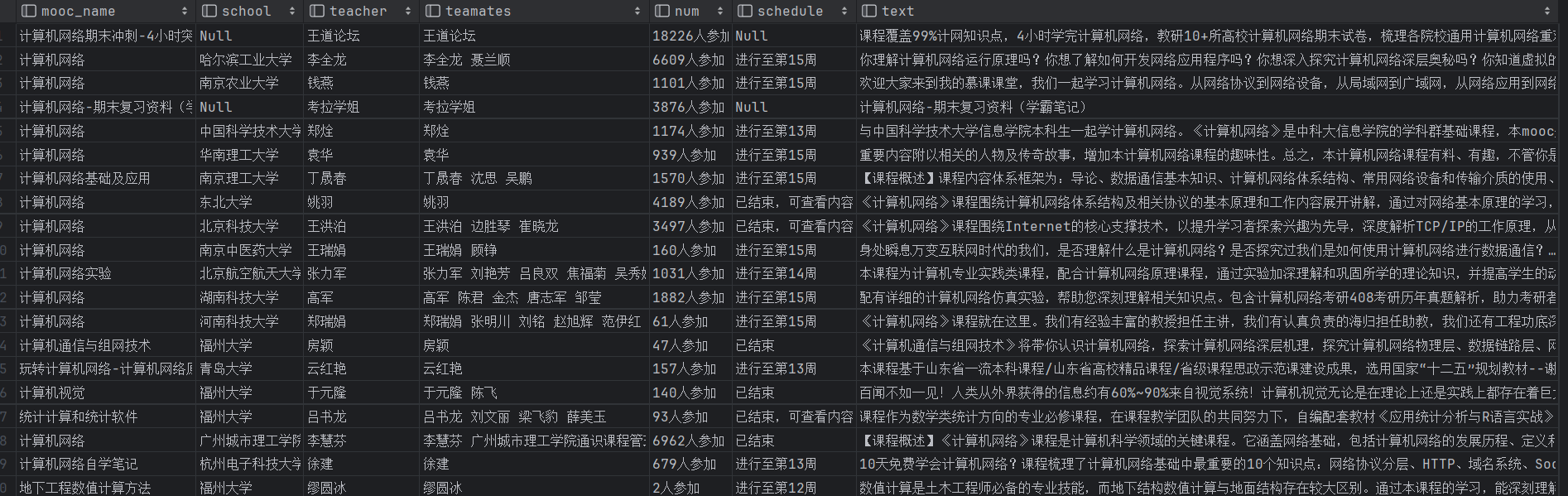
从数据库里面查看
2.3心得体会
这次实践更像一次“逆向工程”——我需要模拟一个真实用户的完整操作链条,从点击登录、填写信息,到搜索、提取数据。这个过程让我意识到,爬虫不仅是在获取数据,更是在理解一个复杂系统的运作方式。
在自动登录环节,仍有很多挑战,比如iframe的嵌套结构让元素定位变得困难,页面加载的不确定性需要精准的等待策略。每一个time.sleep()都不只是简单的暂停,而是对页面响应节奏的尊重。特别是切换回主框架的那一步,稍有不慎就会导致后续所有操作失败,这让我深刻体会到程序执行“上下文”的重要性。
数据提取时,面对看似规整的页面结构,实际处理中却充满变数。课程信息可能缺失教师,团队成员字段需要合并处理,参与人数和进度的格式需要清洗。每一个字段都可能隐藏着意外,代码必须具备足够的“弹性”来消化这些不完美。
3.第三题
掌握大数据相关服务,熟悉Xshell的使用
完成文档 华为云_大数据实时分析处理实验手册-Flume日志采集实验(部分)v2.docx 中的任务,即为下面5个任务,具体操作见文档。
环境搭建:
任务一:开通MapReduce服务
实时分析开发实战:
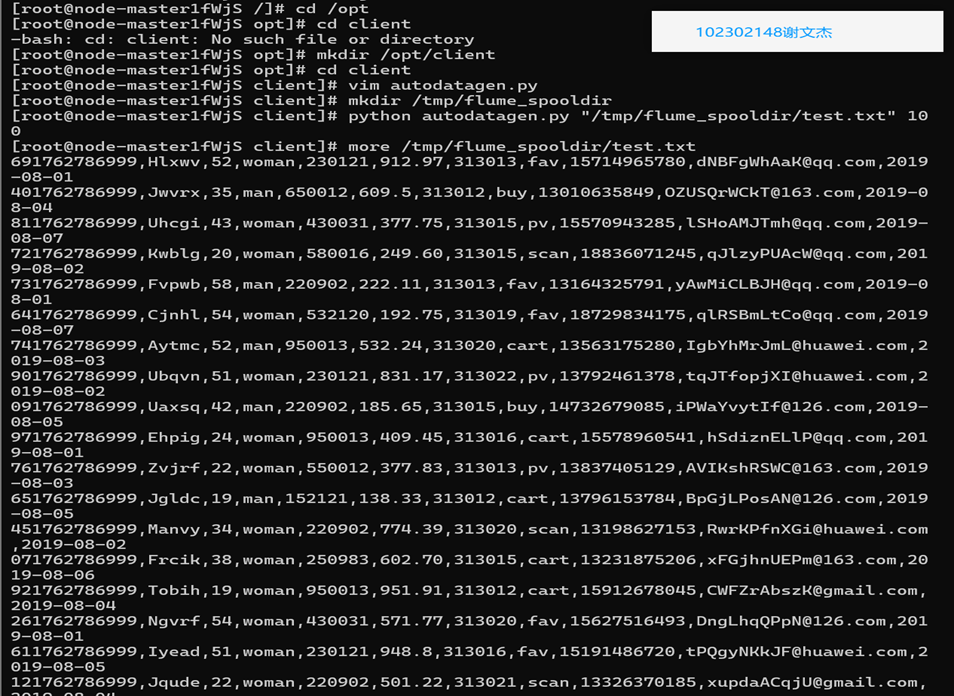
任务一:Python脚本生成测试数据
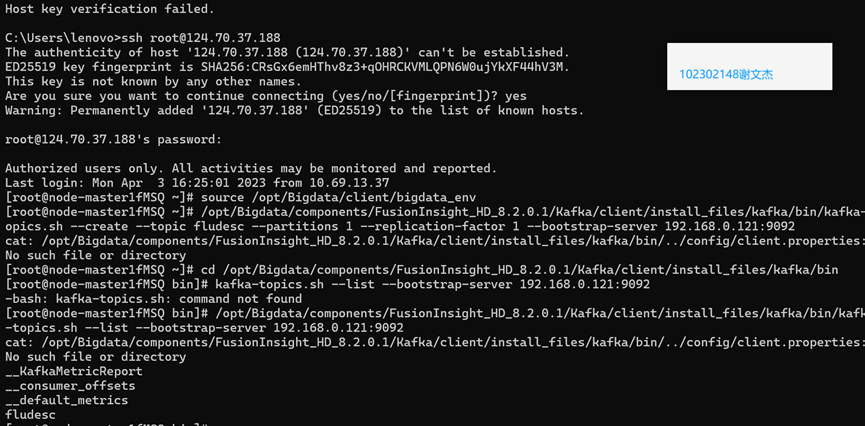
任务二:配置Kafka
任务三: 安装Flume客户端
任务四:配置Flume采集数据
实验步骤
任务一:环境搭建
3.1申请弹性公网IP
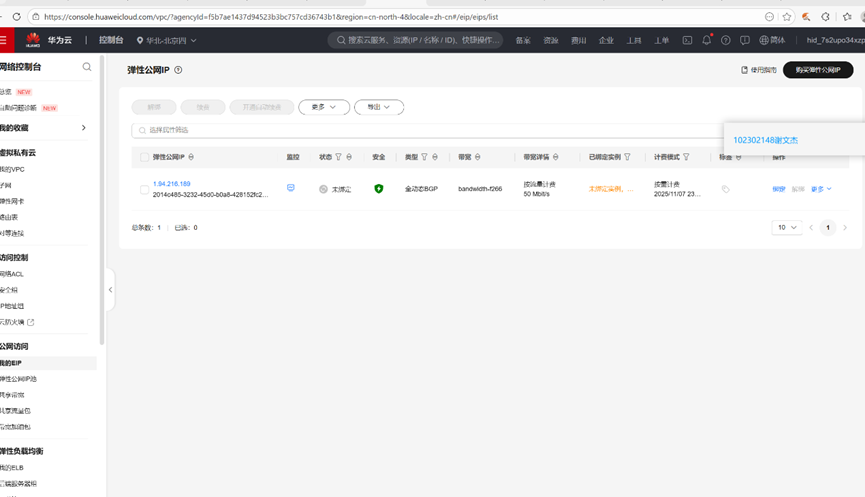
3.2开通MRS服务
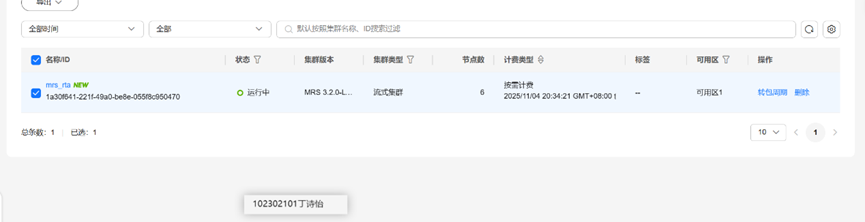
任务二:实时分析开发实战
3.3 编写python脚本测试数据
3.4配置Kfaka
3.5配置Flume
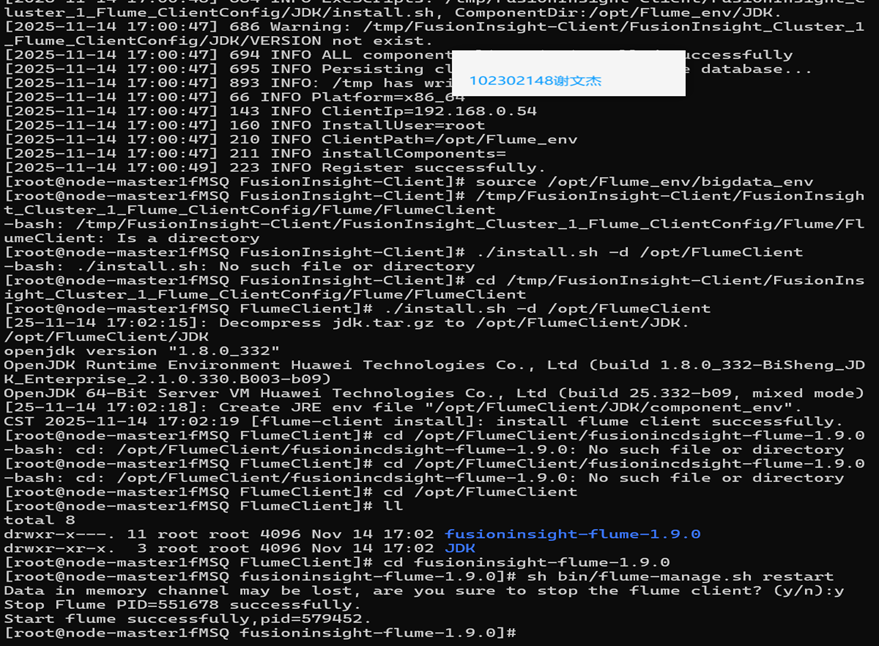
3.6配置Flume采集数据(说明Kafka和flume互通)
心得体会
从本地Python脚本生成数据,到云端Kafka传输,再到Flume采集,我清晰地看到了数据如何在不同系统间流动。这种端到端的实践让我明白,真正的挑战往往不在单一技术的使用,而在于如何让多个复杂组件无缝协作。
实践中,“配置 - 测试 - 校验” 的闭环操作(如用 Kafka 消费者验证 Flume 采集、通过日志排查 Flink 报错)能有效提前规避问题,Linux 基础与脚本能力(如vim编辑、crontab定时)也大幅提升了操作效率。同时意识到,资源规划(合理选择 MRS、RDS 规格)与安全配置(仅开放必要端口、及时备份数据)是实验顺利推进的基础。后续可从架构优化(MRS 多节点部署、DLI 弹性扩缩容)与技术延伸(Flink CDC、CSS 日志分析)入手,进一步挖掘 “云 + 实时大数据” 的应用价值。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号