
获取全部校园新闻
1.取出一个新闻列表页的全部新闻 包装成函数。
2.获取总的新闻篇数,算出新闻总页数。
3.获取全部新闻列表页的全部新闻详情。
4.找一个自己感兴趣的主题,进行数据爬取,并进行分词分析。不能与其它同学雷同。
# -*- coding: UTF-8 -*- import requests from bs4 import BeautifulSoup from datetime import datetime import re #获取点击次数 def getClickCount(newsUrl): newsId = re.findall('\_(.*).html', newsUrl)[0].split('/')[1] clickUrl = 'http://oa.gzcc.cn/api.php?op=count&id={}&modelid=80'.format(newsId) clickStr = requests.get(clickUrl).text count = re.search("hits'\).html\('(.*)'\);",clickStr).group(1) return count # 获取新闻详情 def getNewDetail(url): resd = requests.get(url) resd.encoding = 'utf-8' soupd = BeautifulSoup(resd.text, 'html.parser') title = soupd.select('.show-title')[0].text info = soupd.select('.show-info')[0].text time = info.lstrip('发布时间:')[0:19] dt = datetime.strptime(time, '%Y-%m-%d %H:%M:%S') if info.find('来源:') > 0: source = info[info.find('来源:'):].split()[0].lstrip('来源:') else: source = 'none' if info.find('作者:') > 0: author = info[info.find('作者:'):].split()[0].lstrip('作者:') else: author = 'none' print('链接:'+url) print('标题:' + title) print('发布时间:{}'.format(dt)) print('来源:' + source) print('作者:' + author) print('***********') def getListPage(listPageUrl): res = requests.get(listPageUrl) res.encoding = 'utf-8' soup = BeautifulSoup(res.text, 'html.parser') for news in soup.select('li'): if len(news.select('.news-list-title')) > 0: # 获取新闻模块链接 a = news.a.attrs['href'] # 调用函数获取新闻正文 getNewDetail(a) #首页列表新闻 # getListPage('http://news.gzcc.cn/html/xiaoyuanxinwen/') #计算总页数 resn = requests.get('http://news.gzcc.cn/html/xiaoyuanxinwen/') resn.encoding = 'utf-8' soupn = BeautifulSoup(resn.text,'html.parser') n = int(soupn.select('.a1')[0].text.rstrip('条'))//10+1 for i in range(n,n+1): pageUrl = 'http://news.gzcc.cn/html/xiaoyuanxinwen/{}.html'.format(i) getListPage(pageUrl)
运行结果截图:
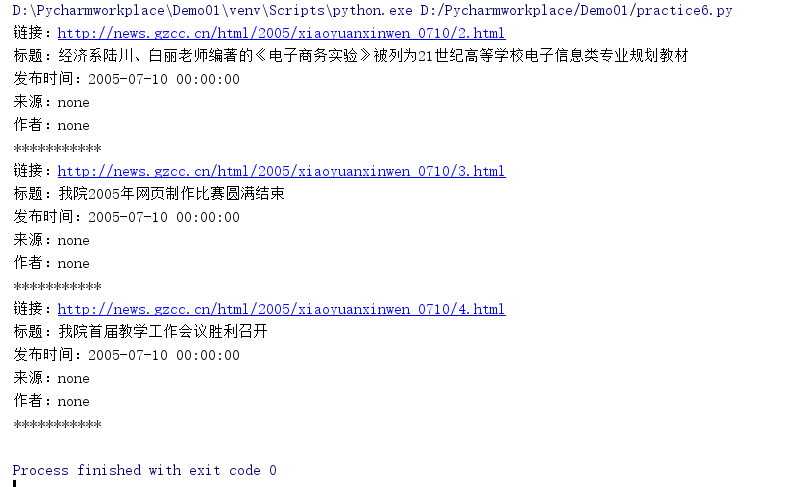
爬取简书简单数据:
# -*- coding: UTF-8 -*- import requests from bs4 import BeautifulSoup from datetime import datetime import re import jieba res = requests.get('https://www.jianshu.com/p/7cb27667442a') res.encoding = 'utf-8' soup = BeautifulSoup(res.text,'html.parser') title = soup.select('.title')[0].text time = soup.select('.publish-time')[0].text.rstrip('*') dt = datetime.strptime(time, '%Y.%m.%d %H:%M') words = soup.select('.wordage')[0].text.lstrip('字数 ') article = list(jieba.lcut(soup.select('p')[0].text)) print('标题:'+title) print('发布时间:{}'.format(dt)) print('字数'+words) print('分词后的正文:') print(article)


 浙公网安备 33010602011771号
浙公网安备 33010602011771号