


数据库分库分表中间件实现原理和选型
参考:
https://www.cnblogs.com/wangzhongqiu/p/7100332.html
https://zhuanlan.zhihu.com/p/200984092
https://zhuanlan.zhihu.com/p/25166375
https://zhuanlan.zhihu.com/p/107100975
https://blog.csdn.net/qq_25889465/article/details/89645006
https://cloud.tencent.com/developer/article/1430676
https://blog.csdn.net/chongliu1196/article/details/100803323
https://blog.csdn.net/qq_33576463/article/details/108877246
【MySQL】数据库(分库分表)中间件对比
分区:对业务透明,分区只不过把存放数据的文件分成了许多小块,例如mysql中的一张表对应三个文件.MYD,MYI,frm。
根据一定的规则把数据文件(MYD)和索引文件(MYI)进行了分割,分区后的表呢,还是一张表。分区可以把表分到不同的硬盘上,但不能分配到不同服务器上。
- 优点:数据不存在多个副本,不必进行数据复制,性能更高。
- 缺点:分区策略必须经过充分考虑,避免多个分区之间的数据存在关联关系,每个分区都是单点,如果某个分区宕机,就会影响到系统的使用。
分片:对业务透明,在物理实现上分成多个服务器,不同的分片在不同服务器上
个人感觉跟分库没啥区别,只是叫法不一样而已,值得一提的是关系型数据库和nosql数据库分片的概念以及处理方式是一样的吗?
请各位看官自行查找相关资料予以解答
分表:当数据量大到一定程度的时候,都会导致处理性能的不足,这个时候就没有办法了,只能进行分表处理。也就是把数据库当中数据根据按照分库原则分到多个数据表当中,
这样,就可以把大表变成多个小表,不同的分表中数据不重复,从而提高处理效率。
分表也有两种方案:
1. 同库分表:所有的分表都在一个数据库中,由于数据库中表名不能重复,因此需要把数据表名起成不同的名字。
- 优点:由于都在一个数据库中,公共表,不必进行复制,处理更简单
- 缺点:由于还在一个数据库中,CPU、内存、文件IO、网络IO等瓶颈还是无法解决,只能降低单表中的数据记录数。
表名不一致,会导后续的处理复杂(参照mysql meage存储引擎来处理)
2. 不同库分表:由于分表在不同的数据库中,这个时候就可以使用同样的表名。
- 优点:CPU、内存、文件IO、网络IO等瓶颈可以得到有效解决,表名相同,处理起来相对简单
- 缺点:公共表由于在所有的分表都要使用,因此要进行复制、同步。
一些聚合的操作,join,group by,order等难以顺利进行
参考博客:http://www.cnblogs.com/langtianya/p/4997768.html,http://blog.51yip.com/mysql/949.html
分库:分表和分区都是基于同一个数据库里的数据分离技巧,对数据库性能有一定提升,但是随着业务数据量的增加,
原来所有的数据都是在一个数据库上的,网络IO及文件IO都集中在一个数据库上的,因此CPU、内存、文件IO、网络IO都可能会成为系统瓶颈。
当业务系统的数据容量接近或超过单台服务器的容量、QPS/TPS接近或超过单个数据库实例的处理极限等
此时,往往是采用垂直和水平结合的数据拆分方法,把数据服务和数据存储分布到多台数据库服务器上。
分库只是一个通俗说法,更标准名称是数据分片,采用类似分布式数据库理论指导的方法实现,对应用程序达到数据服务的全透明和数据存储的全透明
读写分离方案
海量数据的存储及访问,通过对数据库进行读写分离,来提升数据的处理能力。读写分离它的方案特点是数据库产生多个副本,
数据库的写操作都集中到一个数据库上,而一些读的操作呢,可以分解到其它数据库上。这样,只要付出数据复制的成本,
就可以使得数据库的处理压力分解到多个数据库上,从而大大提升数据处理能力。


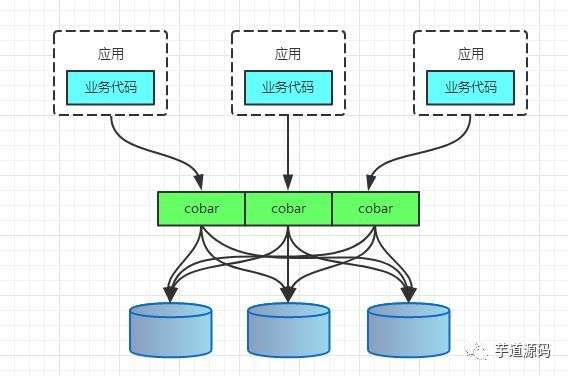
1>Cobar 是提供关系型数据库(MySQL)分布式服务的中间件,它可以让传统的数据库得到良好的线性扩展,并看上去还是一个数据库,对应用保持透明。
Cobar以Proxy的形式位于前台应用和实际数据库之间,对前台的开放的接口是MySQL通信协议,将前台SQL语句变更并按照数据分布规则发到合适的后台数据分库,再合并返回结果,模拟单库下的数据库行为。
Cobar属于中间层方案,在应用程序和MySQL之间搭建一层Proxy。中间层介于应用程序与数据库间,需要做一次转发,而基于JDBC协议并无额外转发,直接由应用程序连接数据库,
性能上有些许优势。这里并非说明中间层一定不如客户端直连,除了性能,需要考虑的因素还有很多,中间层更便于实现监控、数据迁移、连接管理等功能。
Cobar属于阿里B2B事业群,始于2008年,在阿里服役3年多,接管3000+个MySQL数据库的schema,集群日处理在线SQL请求50亿次以上。
由于Cobar发起人的离职,Cobar停止维护。后续的类似中间件,比如MyCAT建立于Cobar之上,包括现在阿里服役的RDRS其中也复用了Cobar-Proxy的相关代码。
2>MyCAT是社区爱好者在阿里cobar基础上进行二次开发,解决了cobar当时存 在的一些问题,并且加入了许多新的功能在其中。目前MyCAT社区活 跃度很高,
目前已经有一些公司在使用MyCAT。总体来说支持度比 较高,也会一直维护下去,发展到目前的版本,已经不是一个单纯的MySQL代理了,
它的后端可以支持MySQL, SQL Server, Oracle, DB2, PostgreSQL等主流数据库,也支持MongoDB这种新型NoSQL方式的存储,未来还会支持更多类型的存储。
MyCAT是一个强大的数据库中间件,不仅仅可以用作读写分离,以及分表分库、容灾管理,而且可以用于多租户应用开发、云平台基础设施,让你的架构具备很强的适应性和灵活性,
借助于即将发布的MyCAT只能优化模块,系统的数据访问瓶颈和热点一目了然,根据这些统计分析数据,你可以自动或手工调整后端存储,将不同的表隐射到不同存储引擎上,而整个应用的代码一行也不用改变。
MyCAT是在Cobar基础上发展的版本,两个显著提高:后端由BIO改为NIO,并发量有大幅提高; 增加了对Order By, Group By, Limit等聚合功能
(虽然Cobar也可以支持Order By, Group By, Limit语法,但是结果没有进行聚合,只是简单返回给前端,聚合功能还是需要业务系统自己完成)
3>TDDL是Tabao根据自己的业务特点开发了(Tabao Distributed Data Layer, 外号:头都大了)。主要解决了分库分表对应用的透明化以及异构数据库之间的数据复制,
它是一个基于集中式配置的jdbc datasourcce实现,具有主备,读写分离,动态数据库配置等功能。
TDDL并非独立的中间件,只能算作中间层,处于业务层和JDBC层中间,是以Jar包方式提供给应用调用,属于JDBC Shard的思想。
TDDL源码:https://github.com/alibaba/tb_tddl
TDDL复杂度相对较高。当前公布的文档较少,只开源动态数据源,分表分库部分还未开源,还需要依赖diamond,不推荐使用。
4>DRDS是阿里巴巴自主研发的分布式数据库服务(此项目不开源),DRDS脱胎于阿里巴巴开源的Cobar分布式数据库引擎,吸收了Cobar核心的Cobar-Proxy源码,
实现了一套独立的类似MySQL-Proxy协议的解析端,能够对传入的SQL进行解析和处理,对应用程序屏蔽各种复杂的底层DB拓扑结构,获得单机数据库一样的使用体验,
同时借鉴了淘宝TDDL丰富的分布式数据库实践经验,实现了对分布式Join支持,SUM/MAX/COUNT/AVG等聚合函数支持以及排序等函数支持,
通过异构索引、小表广播等解决分布式数据库使用场景下衍生出的一系列问题,最终形成了完整的分布式数据库方案。
5>Atlas是一个位于应用程序与MySQL之间的基于MySQL协议的数据中间层项目,它是在mysql-proxy 0.8.2版本上对其进行优化,360团队基于mysql proxy 把lua用C改写,
它实现了MySQL的客户端和服务端协议,作为服务端与应用程序通讯,同时作为客户端与MySQL通讯。它对应用程序屏蔽了DB的细节。
Altas不能实现分布式分表,所有的字表必须在同一台DB的同一个DataBase里且所有的字表必须实现建好,Altas没有自动建表的功能。
原有版本是不支持分库分表, 目前已经放出了分库分表版本。在网上看到一些朋友经常说在高并 发下会经常挂掉,如果大家要使用需要提前做好测试。
6>DBProxy是美团点评DBA团队针对公司内部需求,在奇虎360公司开源的Atlas做了很多改进工作,形成了新的高可靠、高可用企业级数据库中间件
其特性主要有:读写分离、负载均衡、支持分表、IP过滤、sql语句黑名单、DBA平滑下线DB、从库流量配置、动态加载配置项
项目的Github地址是https://github.com/Meituan-Dianping/DBProxy
7>sharding-JDBC是当当应用框架ddframe中,从关系型数据库模块dd-rdb中分离出来的数据库水平分片框架,实现透明化数据库分库分表访问。
Sharding-JDBC是继dubbox和elastic-job之后,ddframe系列开源的第3个项目。
Sharding-JDBC直接封装JDBC API,可以理解为增强版的JDBC驱动,旧代码迁移成本几乎为零:
- 可适用于任何基于Java的ORM框架,如JPA、Hibernate、Mybatis、Spring JDBC Template或直接使用JDBC。
- 可基于任何第三方的数据库连接池,如DBCP、C3P0、 BoneCP、Druid等。
- 理论上可支持任意实现JDBC规范的数据库。虽然目前仅支持MySQL,但已有支持Oracle、SQLServer等数据库的计划。
Sharding-JDBC定位为轻量Java框架,使用客户端直连数据库,以jar包形式提供服务,无proxy代理层,无需额外部署,无其他依赖,DBA也无需改变原有的运维方式。
Sharding-JDBC分片策略灵活,可支持等号、between、in等多维度分片,也可支持多分片键。
SQL解析功能完善,支持聚合、分组、排序、limit、or等查询,并支持Binding Table以及笛卡尔积表查询。
知名度较低的:
Heisenberg
Baidu.
其优点:分库分表与应用脱离,分库表如同使用单库表一样,减少db连接数压力,热重启配置,可水平扩容,遵守MySQL原生协议,读写分离,无语言限制,
mysqlclient, c, java都可以使用Heisenberg服务器通过管理命令可以查看,如连接数,线程池,结点等,并可以调整采用velocity的分库分表脚本进行自定义分库表,相当的灵活。
https://github.com/brucexx/heisenberg(开源版已停止维护)
CDS
JD. Completed Database Sharding.
CDS是一款基于客户端开发的分库分表中间件产品,实现了JDBC标准API,支持分库分表,读写分离和数据运维等诸多共,提供高性能,高并发和高可靠的海量数据路由存取服务,
业务系统可近乎零成本进行介入,目前支持MySQL, Oracle和SQL Server.
(架构上和Cobar,MyCAT相似,直接采用jdbc对接,没有实现类似MySQL协议,没有NIO,AIO,SQL Parser模块采用JSqlParser, Sql解析器有:druid>JSqlParser>fdbparser.)
DDB
网易. Distributed DataBase.
DDB经历了三次服务模式的重大更迭:Driver模式->Proxy模式->云模式。
Driver模式:基于JDBC驱动访问,提供一个db.jar, 和TDDL类似, 位于应用层和JDBC之间. Proxy模式:在DDB中搭建了一组代理服务器来提供标准的MySQL服务,
在代理服务器内部实现分库分表的逻辑。应用通过标准数据库驱动访问DDB Proxy, Proxy内部通过MySQL解码器将请求还原为SQL, 并由DDB Driver执行得到结果。
私有云模式:基于网易私有云开发的一套平台化管理工具Cloudadmin, 将DDB原先Master的功能打散,一部分分库相关功能集成到proxy中,
如分库管理、表管理、用户管理等,一部分中心化功能集成到Cloudadmin中,如报警监控,此外,Cloudadmin中提供了一键部署、自动和手动备份,版本管理等平台化功能。
OneProxy:
数据库界大牛,前支付宝数据库团队领导楼方鑫开发,基于mysql官方 的proxy思想利用c进行开发的,OneProxy是一款商业收费的中间件, 楼总舍去了一些功能点,
专注在性能和稳定性上。有朋友测试过说在 高并发下很稳定。
Oceanus(58同城数据库中间件)
Oceanus致力于打造一个功能简单、可依赖、易于上手、易于扩展、易于集成的解决方案,甚至是平台化系统。拥抱开源,提供各类插件机制集成其他开源项目,
新手可以在几分钟内上手编程,分库分表逻辑不再与业务紧密耦合,扩容有标准模式,减少意外错误的发生。
Vitess:
这个中间件是Youtube生产在使用的,但是架构很复杂。 与以往中间件不同,使用Vitess应用改动比较大要 使用他提供语言的API接口,我们可以借鉴他其中的一些设计思想。
Kingshard:
Kingshard是前360Atlas中间件开发团队的陈菲利用业务时间 用go语言开发的,目前参与开发的人员有3个左右, 目前来看还不是成熟可以使用的产品,需要在不断完善。
MaxScale与MySQL Route:
这两个中间件都算是官方的吧,MaxScale是mariadb (MySQL原作者维护的一个版本)研发的,目前版本不支持分库分表。
MySQL Route是现在MySQL 官方Oracle公司发布出来的一个中间件。
分库分表Sharding-JDBC入门与项目实战
最近项目中不少表的数据量越来越大,并且导致了一些数据库的性能问题。因此想借助一些分库分表的中间件,实现自动化分库分表实现。调研下来,发现Sharding-JDBC目前成熟度最高并且应用最广的Java分库分表的客户端组件。
本文主要介绍一些Sharding-JDBC核心概念以及生产环境下的实战指南,旨在帮助组内成员快速了解Sharding-JDBC并且能够快速将其使用起来。
核心概念
在使用Sharding-JDBC之前,一定是先理解清楚下面几个核心概念。
逻辑表
水平拆分的数据库(表)的相同逻辑和数据结构表的总称。例:订单数据根据主键尾数拆分为10张表,分别是t_order_0到t_order_9,他们的逻辑表名为t_order。
真实表
在分片的数据库中真实存在的物理表。即上个示例中的t_order_0到t_order_9。
数据节点
数据分片的最小单元。由数据源名称和数据表组成,例:ds_0.t_order_0。
绑定表
指分片规则一致的主表和子表。例如:t_order表和t_order_item表,均按照order_id分片,则此两张表互为绑定表关系。绑定表之间的多表关联查询不会出现笛卡尔积关联,关联查询效率将大大提升。
举例说明,如果SQL为:
SELECT i.* FROM t_order o JOIN t_order_item i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
假设t_order和t_order_item对应的真实表各有2个,那么真实表就有t_order_0、t_order_1、t_order_item_0、t_order_item_1。
在不配置绑定表关系时,假设分片键order_id将数值10路由至第0片,将数值11路由至第1片,那么路由后的SQL应该为4条,它们呈现为笛卡尔积:
SELECT i.* FROM t_order_0 o JOIN t_order_item_0 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
SELECT i.* FROM t_order_0 o JOIN t_order_item_1 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
SELECT i.* FROM t_order_1 o JOIN t_order_item_0 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
SELECT i.* FROM t_order_1 o JOIN t_order_item_1 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
在配置绑定表关系后,路由的SQL应该为2条:
SELECT i.* FROM t_order_0 o JOIN t_order_item_0 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
SELECT i.* FROM t_order_1 o JOIN t_order_item_1 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
广播表
指所有的分片数据源中都存在的表,表结构和表中的数据在每个数据库中均完全一致。适用于数据量不大且需要与海量数据的表进行关联查询的场景,例如:字典表。
数据分片
分片键
用于分片的数据库字段,是将数据库(表)水平拆分的关键字段。例:将订单表中的订单主键的尾数取模分片,则订单主键为分片字段。SQL 中如果无分片字段,将执行全路由,性能较差。除了对单分片字段的支持,Sharding-JDBC 也支持根据多个字段进行分片。
分片算法
通过分片算法将数据分片,支持通过=、>=、<=、>、<、BETWEEN和IN分片。分片算法需要应用方开发者自行实现,可实现的灵活度非常高。
目前提供4种分片算法。由于分片算法和业务实现紧密相关,因此并未提供内置分片算法,而是通过分片策略将各种场景提炼出来,提供更高层级的抽象,并提供接口让应用开发者自行实现分片算法。
精确分片算法
对应 PreciseShardingAlgorithm,用于处理使用单一键作为分片键的 = 与 IN 进行分片的场景。需要配合 StandardShardingStrategy 使用。
范围分片算法
对应 RangeShardingAlgorithm,用于处理使用单一键作为分片键的 BETWEEN AND、>、<、>=、<=进行分片的场景。需要配合 StandardShardingStrategy 使用。
复合分片算法
对应 ComplexKeysShardingAlgorithm,用于处理使用多键作为分片键进行分片的场景,包含多个分片键的逻辑较复杂,需要应用开发者自行处理其中的复杂度。需要配合 ComplexShardingStrategy 使用。
Hint分片算法
对应 HintShardingAlgorithm,用于处理通过Hint指定分片值而非从SQL中提取分片值的场景。需要配合 HintShardingStrategy 使用。
分片策略
包含分片键和分片算法,由于分片算法的独立性,将其独立抽离。真正可用于分片操作的是分片键 + 分片算法,也就是分片策略。目前提供 5 种分片策略。
标准分片策略
对应 StandardShardingStrategy。提供对 SQ L语句中的 =, >, <, >=, <=, IN 和 BETWEEN AND 的分片操作支持。StandardShardingStrategy 只支持单分片键,提供 PreciseShardingAlgorithm 和 RangeShardingAlgorithm 两个分片算法。
PreciseShardingAlgorithm 是必选的,用于处理 = 和 IN 的分片。RangeShardingAlgorithm 是可选的,用于处理 BETWEEN AND, >, <, >=, <=分片,如果不配置 RangeShardingAlgorithm,SQL 中的 BETWEEN AND 将按照全库路由处理。
复合分片策略
对应 ComplexShardingStrategy。复合分片策略。提供对 SQL 语句中的 =, >, <, >=, <=, IN 和 BETWEEN AND 的分片操作支持。ComplexShardingStrategy 支持多分片键,由于多分片键之间的关系复杂,因此并未进行过多的封装,而是直接将分片键值组合以及分片操作符透传至分片算法,完全由应用开发者实现,提供最大的灵活度。
行表达式分片策略
对应 InlineShardingStrategy。使用 Groovy 的表达式,提供对 SQL 语句中的 = 和 IN的分片操作支持,只支持单分片键。对于简单的分片算法,可以通过简单的配置使用,从而避免繁琐的Java代码开发,如: t_user_$->{u_id % 8} 表示 t_user 表根据 u_id 模 8,而分成 8 张表,表名称为 t_user_0 到 t_user_7。可以认为是精确分片算法的简易实现
Hint分片策略
对应 HintShardingStrategy。通过 Hint 指定分片值而非从 SQL 中提取分片值的方式进行分片的策略。
分布式主键
用于在分布式环境下,生成全局唯一的id。Sharding-JDBC 提供了内置的分布式主键生成器,例如 UUID、SNOWFLAKE。还抽离出分布式主键生成器的接口,方便用户自行实现自定义的自增主键生成器。为了保证数据库性能,主键id还必须趋势递增,避免造成频繁的数据页面分裂。
读写分离
提供一主多从的读写分离配置,可独立使用,也可配合分库分表使用。
- 同一线程且同一数据库连接内,如有写入操作,以后的读操作均从主库读取,用于保证数据一致性
- 基于Hint的强制主库路由。
- 主从模型中,事务中读写均用主库。
执行流程
Sharding-JDBC 的原理总结起来很简单: 核心由 SQL解析 => 执行器优化 => SQL路由 => SQL改写 => SQL执行 => 结果归并的流程组成。

分库分表中间件DDAL的设计及使用
1. DDAL分层架构设计
DDAL在设计上主要可以分为三层:
- 最上层为DDALDataSource,用于解析数据源的富客户端(smart client)和轻客户端(light client)的协议实现,目前DDAL实现的是富客户端(smart client);
<bean name="dataSource" class="org.hellojavaer.ddal.datasource.DefaultDDALDataSource">
<constructor-arg index="0" value="jdbc:ddal:thick:classpath:/datasource.xml"/>
<!-- <constructor-arg index="0" value="jdbc:ddal:thick:http://{host}:{port}/{appName}"/> -->
</bean>- 中间层为DBClusterManager,用于实现数据库多集群的路由管理,实际中的一个应用场景为应用访问就近数据库集群(需要注意这里定义的集群的含义是每个集群的功能是对等的,而非主从的关系的集群);
- 底层为DDRDataSource,它是真正用于实现分库分表路由的组件实现;
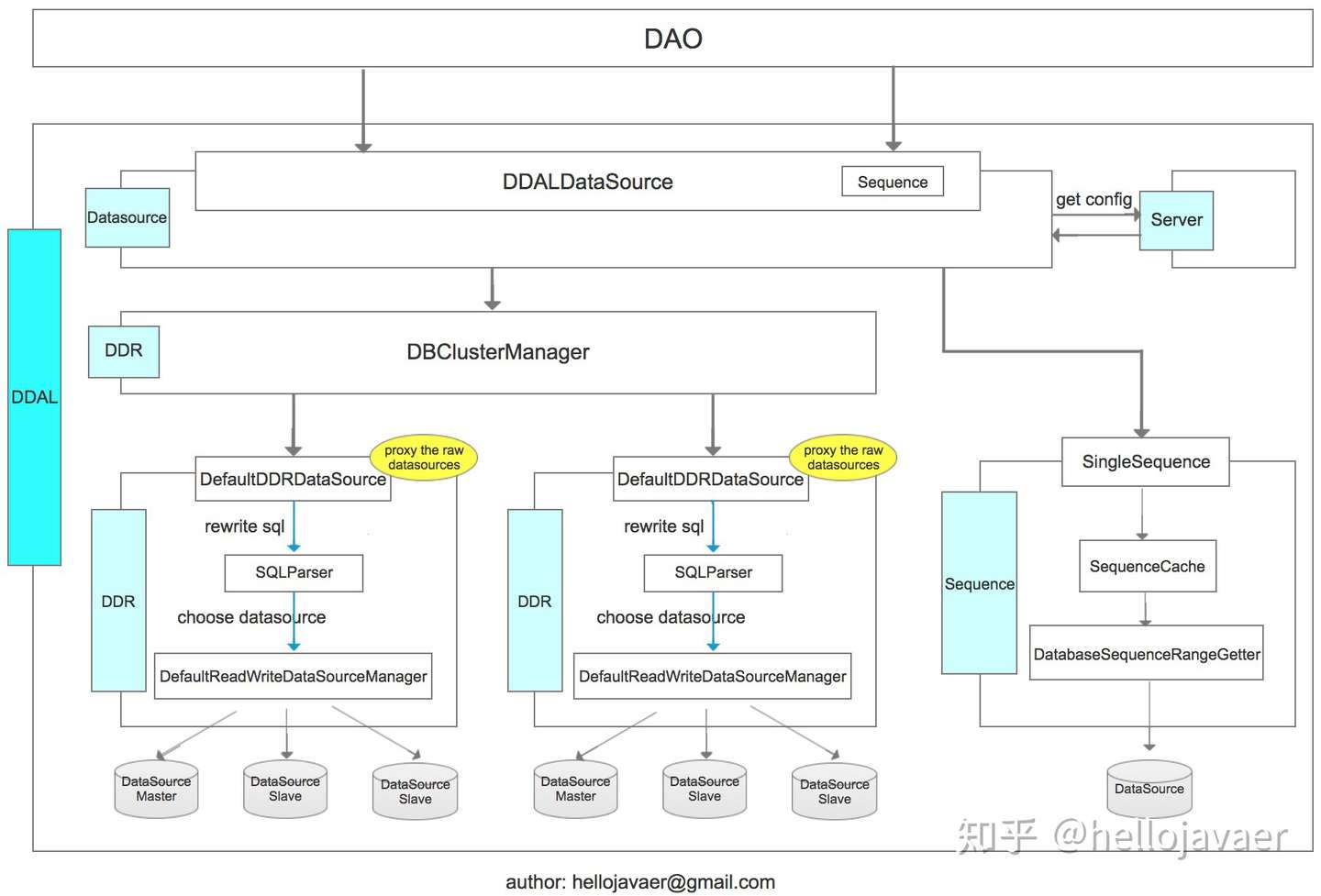
基于上图架构的一个完整的工程示例:
另一个简单的读写分离的工程示例
2. DDAL的执行原理
- 定义分库分表路由规则
<!-- DDAL处理路由规则的一个实现方式是使用EL表达式解析,EL特点是可以使用简单的表达式实现复杂功能 -->
<bean id="idRule" class="org.hellojavaer.ddal.ddr.shard.rule.SpelShardRouteRule">
<property name="scRouteRule" value="{scName}_{format('%02d', sdValue % 2)}"/>
<property name="tbRouteRule" value="{tbName}_{format('%04d', sdValue % 8)}"/>
</bean>2.绑定路由规则到逻辑表名或逻辑库(逻辑schema)上,并设置分片字段(也可以不设置分片字段)
<bean class="org.hellojavaer.ddal.ddr.shard.simple.SimpleShardRouteRuleBinding">
<!-- scName是必选的,scName的路由结果会被用于在数据源管理器中做数据源选择 -->
<property name="scName" value="base"></property>
<!-- tbName是可选的,当没有配置tbName时,表示当前路由规则绑定到了当前schema下的所有表 -->
<!--<property name="tbName" value="user"></property>-->
<!-- rule是可选的,当没有配置时,解析时直接返回原表名 -->
<property name="rule" ref="idRule"></property>
<!-- sdKey是可选的,当没有配置时,通过ShardRouteContext获取路由信息 -->
<property name="sdKey" value="id"></property>
<!-- sdValues是可选的,sdValues用于将以上的配置转换为物理表,可用于扫表查询接口 -->
<property name="sdValues" value="[0..7]"></property>
</bean>通过这个绑定,可以计算出一个逻辑表名对应的物理表名和一个逻辑库(schema)对应的为物理库(schema)
3. 解析并重写sql
DDAL支持的sql主语法有select,insert,delete,update,支持主语法下的几乎所有sql子语法,包括sub-select,union,exsit, join等
解析sql的过程就是识别sql中的所有表名,如果某一个表名能匹配到步骤2中的逻辑表名,则该表名会根据步骤1中规则进行表名重写,如果没匹配到则不做任何操作,同时所有被重写后的表名会被放在一个结果集用于步骤4数据源的获取。
在重写sql时一个关键的点是获取路由信息,DDAL对分表路由信息的获取分为两大类:
(1)通过sql中的分片值
(2)通过ShardRouteContext;
其中方式(1)优先于方式(2),只有当方式(1)获取失败后才会尝试从方式(2)中获取。而如果两种方式都不能获取到路由信息则会抛出异常,比如:
select * from tb where id = 9上面的tb匹配了步骤2的绑定,因此会执行表名重写;而id字段又匹配了分片字段,因此会执行方式(1)的分片值重写,重写后的结果为
SELECT * FROM base_01.tb_0001 WHERE id = 9而如果当sql中不含分片字段或分片字段不能计算路由信息时(比如: id != 9)
select * from tb where WHERE name = 'test'这时可以通过ShardRouteContext设置路由信息
ShardRouteContext.setRouteInfo('base', 9);重新后的sql为
SELECT * FROM base_01.tb_0001 WHERE name = 'test'同时DDAL为了简化ShardRouteContext的调用,提供ShardRoute注解进行配置,注解的配置和ShardRouteContext是完全等效的,因为ShardRoute底层使用的就是ShardRouteContext,例如:
// 当id的值为9时,路由结果的信息完全等同于 ShardRouteContext.setRouteInfo('base', 9);
@ShardRoute(scName = "base", sdValue = "{$0}")
public void test(Long id){}
4.选取数据源并执行
这一步的核心是数据源管理器,它通过将步骤3中计算出的物理库的结果集用于筛选出实际的数据源去执行。而DDAL目前的数据源管理器包含两个:SingleDataSourceManager和DefaultReadWriteDataSourceManager。
SingleDataSourceManager不依赖步骤3计算的物理库结果集,因为它内部只管理了一个数据源,所以不论步骤3返回什么结果集,SingleDataSourceManager都只会把它管理的那一个数据源返回用于sql的执行;
DefaultReadWriteDataSourceManager实现了一个读写分离的数据源管理器,读和写都可以配置多个数据源,读数据源支持配置负载权重。由于内部包含多个数据源因此步骤3的物理库结果集必须至少包含一个结果,用于匹配实际的数据源(如果未匹配中则会抛出异常)
以上完整的配置信息参考以下链接
3.DDAL对分布式事务的处理
DDAL的设计方向完整的保留数据库ACID的所有特性,在一个数据源连接下的跨schema和跨table操作是允许的(因为底层数据库是支持的);当出现跨连接操作时,DDAL设计方案是将跨连接的数据进行分组使得分组后的每组数据都在一个连接内。在DDAL中提供的一个实现类是ShardRouteUtils,你可以先使用groupSdValuesByRouteInfo对shard-value进行分组,然后使用groupRouteInfosByDataSource对关联的数据源进行分组。分组后的shard-value再进行操作时每一组的操作就都能完整的保证ACID,不同分组间的操作异常由业务自行进行控制;
4.DDAL分布式主键设计
参考以下链接
5. DDAL特性概览
- 1. 使用上对业务代码没有任何入侵:只需要代理原有数据源即可实现分表路由功能,DDAL除了依赖jdbc本身的相关api外,不依赖spring,hibernate,mybatis等其他提框架提供的数据访问层的接口和实现;
- 2. 同时支持单数据源模式和读写组合数据源模式,灵活解决数据库从单一数据库发展到数据集群的不同阶段需要的不同解决方案;
- 3. 最小程度限制sql:DDAL对sql的限制主要分为两点。1)禁止跨数据源查询,2)分表需要提供分表路由信息;在满足这两点的前提下你的sql几乎是'自由的':允许多表jion,允许嵌套子查询,可以对分表字段使用in和between操作以及not操作;(相关设计细节参考DDAL wiki)
- 4. 分表路由规则配置灵活且简单:分表路由的字段可以是整型也可以是字符型,这里没有任何限制,你可以根据自己的业务规则灵活配置;
- 5. 支持分表不含分片字段;
- 6. 支持读写分离;
- 7. 支持数据源负载均衡配置且可以动态调整:DDAL默认提供了通过MBean动态调节数据库负载的方式,使用上只需要在启动应用后开启jconsole就可以控制各个数据源的负载;
- 8. 支持无分库分表的普通主从模式:在业务发展的初期,数据库可能并没有做分库分表,但为了提高读性能可能会发展为读写分离的主从模式数据库集群。在这种场景下只需要省略掉分表的配置即可方案实现该业务功能;
- 9. 支持注解方式的分库分表路由;
- 10. 支持数据库集群路由
- 11. 提供分布式主键模块:参考 wiki;
深入数据库分区分库分表
一、为什么要分库分表
软件时代,传统应用都有这样一个特点:访问量、数据量都比较小,单库单表都完全可以支撑整个业务。随着互联网的发展和用户规模的迅速扩大,对系统的要求也越来越高。因此传统的MySQL单库单表架构的性能问题就暴露出来了。而有下面几个因素会影响数据库性能:
- 数据量
MySQL单库数据量在5000万以内性能比较好,超过阈值后性能会随着数据量的增大而变弱。MySQL单表的数据量是500w-1000w之间性能比较好,超过1000w性能也会下降。
- 磁盘
因为单个服务的磁盘空间是有限制的,如果并发压力下,所有的请求都访问同一个节点,肯定会对磁盘IO造成非常大的影响。
- 数据库连接
数据库连接是非常稀少的资源,如果一个库里既有用户、商品、订单相关的数据,当海量用户同时操作时,数据库连接就很可能成为瓶颈。
为了提升性能,所以我们必须要解决上述几个问题,那就有必要引进分库分表,当然除了分库分表,还有别的解决方案,就是NoSQL和NewSQL,NoSQL主要是MongoDB等,NewSQL则以TiDB为代表。
二、分区分库分表的原理
1、什么是分区、分表、分库
(1)分区
就是把一张表的数据分成N个区块,在逻辑上看最终只是一张表,但底层是由N个物理区块组成的,分区实现比较简单,数据库mysql、oracle等很容易就可支持。
(2)分表
就是把一张表按一定的规则分解成N个具有独立存储空间的实体表。系统读写时需要根据定义好的规则得到对应的字表明,然后操作它。
(3)分库
一旦分表,一个库中的表会越来越多,将整个数据库比作图书馆,一张表就是一本书。当要在一本书中查找某项内容时,如果不分章节,查找的效率将会下降。而同理,在数据库中就是分区。
2、什么时候使用分区?
一张表的查询速度已经慢到影响使用的时候。
- sql经过优化
- 数据量大
- 表中的数据是分段的
- 对数据的操作往往只涉及一部分数据,而不是所有的数据
最常见的分区方法就是按照时间进行分区,分区一个最大的优点就是可以非常高效的进行历史数据的清理。
(1)分区的实现方式
mysql5自5.1开始对分区(Partition)有支持。
(2)分区类型
目前MySQL支持范围分区(RANGE),列表分区(LIST),哈希分区(HASH)以及KEY分区四种。
(3)RANGE分区实例
基于属于一个给定连续区间的列值,把多行分配给分区。最常见的是基于时间字段. 基于分区的列最好是整型,如果日期型的可以使用函数转换为整型。本例中使用to_days函数。
CREATE TABLE my_range_datetime(
id INT,
hiredate DATETIME
)
PARTITION BY RANGE (TO_DAYS(hiredate) ) (
PARTITION p1 VALUES LESS THAN ( TO_DAYS('20171202') ),
PARTITION p2 VALUES LESS THAN ( TO_DAYS('20171203') ),
PARTITION p3 VALUES LESS THAN ( TO_DAYS('20171204') ),
PARTITION p4 VALUES LESS THAN ( TO_DAYS('20171205') ),
PARTITION p5 VALUES LESS THAN ( TO_DAYS('20171206') ),
PARTITION p6 VALUES LESS THAN ( TO_DAYS('20171207') ),
PARTITION p7 VALUES LESS THAN ( TO_DAYS('20171208') ),
PARTITION p8 VALUES LESS THAN ( TO_DAYS('20171209') ),
PARTITION p9 VALUES LESS THAN ( TO_DAYS('20171210') ),
PARTITION p10 VALUES LESS THAN ( TO_DAYS('20171211') ),
PARTITION p11 VALUES LESS THAN (MAXVALUE)
);
3、什么时候分表?
一张表的查询速度已经慢到影响使用的时候。
- sql经过优化
- 数据量大
- 当频繁插入或者联合查询时,速度变慢
分表后,单表的并发能力提高了,磁盘I/O性能也提高了,写操作效率提高了
(1)分表的实现方式
需要结合相关中间件,需要业务系统配合迁移升级,工作量较大。
三、分库分表后引入的问题
1、分布式事务问题
如果我们做了垂直分库或者水平分库以后,就必然会涉及到跨库执行SQL的问题,这样就引发了互联网界的老大难问题-"分布式事务"。那要如何解决这个问题呢?1.使用分布式事务中间件 2.使用MySQL自带的针对跨库的事务一致性方案(XA),不过性能要比单库的慢10倍左右。3.能否避免掉跨库操作(比如将用户和商品放在同一个库中)
2、跨库join的问题
分库分表后表之间的关联操作将受到限制,我们无法join位于不同分库的表,也无法join分表粒度不同的表, 结果原本一次查询能够完成的业务,可能需要多次查询才能完成。粗略的解决方法: 全局表:基础数据,所有库都拷贝一份。 字段冗余:这样有些字段就不用join去查询了。 系统层组装:分别查询出所有,然后组装起来,较复杂。
3、横向扩容的问题
当我们使用HASH取模做分表的时候,针对数据量的递增,可能需要动态的增加表,此时就需要考虑因为reHash导致数据迁移的问题。
4、结果集合并、排序的问题
因为我们是将数据分散存储到不同的库、表里的,当我们查询指定数据列表时,数据来源于不同的子库或者子表,就必然会引发结果集合并、排序的问题。如果每次查询都需要排序、合并等操作,性能肯定会受非常大的影响。走缓存可能一条路!
四、分库分表中间件设计
分表又分为单库分表(表名不同)和多库分表(表名相同),不管使用哪种策略都还需要自己去实现路由,制定路由规则等,可以考虑使用开源的分库分表中间件,无侵入应用设计,例如淘宝的tddl等。
分库分表中间件全部可以归结为两大类型:
- CLIENT模式;
- PROXY模式;
CLIENT模式代表有阿里的TDDL,开源社区的sharding-jdbc(sharding-jdbc的3.x版本即sharding-sphere已经支持了proxy模式)。
架构如下:

PROXY模式代表有阿里的cobar,民间组织的MyCAT。架构如下:
无论是CLIENT模式,还是PROXY模式。几个核心的步骤是一样的:SQL解析,重写,路由,执行,结果归并。
备注:
使用MyCat分表分库原理分析
1.Mycat中的路由结果是通过分片字段和分片方法来确定的,如果查询条件中有 id 字段的情况还好,查询将会落到某个具体的分片
2.如果查询没有分片的字段,会向所有的db都会查询一遍,让后封装结果级给客户端。
分布式数据库中间件选型
时下比较流行的两款数据库中间件产品做下介绍:
| 主要指标 | Sharding-JDBC | MyCat |
|---|---|---|
| 所属 | Apache | 基于阿里 Cobar 二次开发,社区维护 |
| 活跃度 | 高 | 高 |
| ORM支持 | 任意 | 任意 |
| 基于客户端还是服务端 | 客户端 | 服务端 |
| 分库 | 支持 | 支持 |
| 分表 | 支持 | 不支持单库分表 |
| 事务 | 自带弱XA、最大努力送达型柔性事务 | 自带弱XA |
| 监控 | 无,可通过其它方式支持 | 自带 |
| 读写分离 | 支持 | 支持 |
| 限制 | 部分 JDBC 方法不支持、SQL语句限制 | 部分 JDBC 方法不支持、SQL语句限制 |
| 数据库连接池 | 任意 | 任意 |
| MySQL交互协议 | JDBC Driver | 前后端均用 NIO |
| 开发 | 开发成本高,代码入侵大 | 开发成本小,代码入侵小 |
| 运维 | 维护成本低 | 维护成本高 |
| 配置难度 | 一般 | 复杂 |
Sharding-JDBC
架构图:

简单介绍:
Sharding-JDBC是一款轻量级的框架,以工程依赖JAR的形式提供功能,无需额外部署和依赖,可以理解为增强版的JDBC驱动- 对于运维同事来说,只需要协助一些简单的配置及后续的扩容工作,无需关注底层代码与分片策略规则,相对
MyCat,这是Sharding-JDBC的优势,减少了部署成本以及运维同事的学习成本
MyCat
架构图

简单介绍:
MyCat并不是业务系统代码里面的配置,而是独立运行的中间件,所有配置都会交给运维同事执行- 对于运维同事来说,它是在数据库
Server前增加的一层代理,MyCat本身不存数据,数据是在后端数据库上存储的,因此,数据可靠性以及事务等都是通过数据库保证的 MyCatdown 掉的时候,系统不能对数据库进行操作,会对所有用户产生影响MyCat比较适合大数据工作
通过以上分析,可见
Sharding-JDBC相对MyCat来说,更轻量,首选肯定是Sharding-JDBC,只要代码层面做好防腐层(依赖倒置)的设计,就算以后数据量级达到了百亿、千亿,也可以更加灵活方便的替换其它中间件产品,甚至NewSQL。
五、分库分表常用中间件
目前应用比较多的基本有以下几种,
- TDDL
- Sharding-jdbc
- Mycat
- Cobar
1、TDDL
淘宝团队开发的,属于 client 层方案。支持基本的 crud 语法和读写分离,但不支持 join、多表查询等语法。
2、Sharding-jdbc
当当开源的,属于 client 层方案,目前已经更名为 ShardingSphere。SQL 语法支持也比较多,没有太多限制,支持分库分表、读写分离、分布式 id 生成、柔性事务(最大努力送达型事务、TCC 事务)。
3、Cobar
阿里 b2b 团队开发和开源的,属于 proxy 层方案,就是介于应用服务器和数据库服务器之间。应用程序通过 JDBC 驱动访问 Cobar 集群,Cobar 根据 SQL 和分库规则对 SQL 做分解,然后分发到 MySQL 集群不同的数据库实例上执行。
4、Mycat
基于 Cobar 改造的,属于 proxy 层方案,支持的功能完善,社区活跃。
六、常见分表、分库常用策略
平均进行分配hash(object)%N(适用于简单架构)。
按照权重进行分配且均匀轮询。
按照业务进行分配。
按照一致性hash算法进行分配(适用于集群架构,在集群中节点的添加和删除不会造成数据丢失,方便数据迁移)。
七、全局ID生成策略
1、自动增长列
优点:数据库自带功能,有序,性能佳。缺点:单库单表无妨,分库分表时如果没有规划,ID可能重复。
解决方案,一个是设置自增偏移和步长。
- 假设总共有 10 个分表
- 级别可选: SESSION(会话级), GLOBAL(全局)
- SET @@SESSION.autoincrementoffset = 1; ## 起始值, 分别取值为 1~10
- SET @@SESSION.autoincrementincrement = 10; ## 步长增量
如果采用该方案,在扩容时需要迁移已有数据至新的所属分片。
另一个是全局ID映射表。
- 在全局 Redis 中为每张数据表创建一个 ID 的键,记录该表当前最大 ID;
- 每次申请 ID 时,都自增 1 并返回给应用;
- Redis 要定期持久至全局数据库。
2、UUID(128位)
在一台机器上生成的数字,它保证对在同一时空中的所有机器都是唯一的。通常平台会提供生成UUID的API。
UUID 由4个连字号(-)将32个字节长的字符串分隔后生成的字符串,总共36个字节长。形如:550e8400-e29b-41d4-a716-446655440000。
UUID 的计算因子包括:以太网卡地址、纳秒级时间、芯片ID码和许多可能的数字。UUID 是个标准,其实现有几种,最常用的是微软的 GUID(Globals Unique Identifiers)。
- 优点:简单,全球唯一;
- 缺点:存储和传输空间大,无序,性能欠佳。
3、COMB(组合)
组合 GUID(10字节) 和时间(6字节),达到有序的效果,提高索引性能。
4、Snowflake(雪花) 算法
Snowflake 是 Twitter 开源的分布式 ID 生成算法,其结果为 long(64bit) 的数值。其特性是各节点无需协调、按时间大致有序、且整个集群各节点单不重复。该数值的默认组成如下(符号位之外的三部分允许个性化调整):
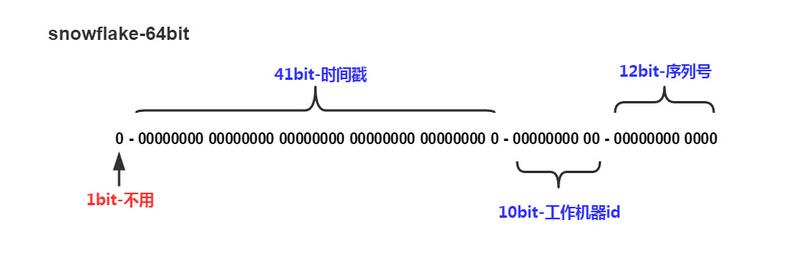
- 1bit: 符号位,总是 0(为了保证数值是正数)。
- 41bit: 毫秒数(可用 69 年);
- 10bit: 节点ID(5bit数据中心 + 5bit节点ID,支持 32 * 32 = 1024 个节点)
- 12bit: 流水号(每个节点每毫秒内支持 4096 个 ID,相当于 409万的 QPS,相同时间内如 ID 遇翻转,则等待至下一毫秒)
八、优雅实现分库分表的动态扩容
优雅的设计扩容缩容的意思就是 进行扩容缩容的代价要小,迁移数据要快。
可以采用逻辑分库分表的方式来代替物理分库分表的方式,要扩容缩容时,只需要将逻辑上的数据库、表改为物理上的数据库、表。
第一次进行分库分表时就多分几个库,一个实践是利用32 * 32来分库分表,即分为32个库,每个库32张表,一共就是1024张表,根据某个id先根据先根据数据库数量32取模路由到库,再根据一个库的表数量32取模路由到表里面。
刚开始的时候,这个库可能就是逻辑库,建在一个mysql服务上面,比如一个mysql服务器建了16个数据库。
如果后面要进行拆分,就是不断的在库和mysql实例之间迁移就行了。将mysql服务器的库搬到另外的一个服务器上面去,比如每个服务器创建8个库,这样就由两台mysql服务器变成了4台mysql服务器。我们系统只需要配置一下新增的两台服务器即可。
比如说最多可以扩展到32个数据库服务器,每个数据库服务器是一个库。如果还是不够?最多可以扩展到1024个数据库服务器,每个数据库服务器上面一个库一个表。因为最多是1024个表么。
这么搞,是不用自己写代码做数据迁移的,都交给dba来搞好了,但是dba确实是需要做一些库表迁移的工作,但是总比你自己写代码,抽数据导数据来的效率高得多了。
哪怕是要减少库的数量,也很简单,其实说白了就是按倍数缩容就可以了,然后修改一下路由规则。
mycat解决mysql的分库分表原理
MyCat
产生背景
随着公司不断发展,公司业务的不断运行,产生的数据也会与日俱增,更何况公司规模和业务的不断扩大,数据库的瓶颈所带来的困扰也越发明:
数据库的连接(mysql默认连接100个);
表数据量();
硬件资源限制(QPS(每秒事务数)/TPS(每秒查询量));
什么是MYCAT
- 一个彻底开源的,面向企业应用开发的大数据库集群;
- 支持事务、ACID、可以替代MySQL的加强版数据库;
- 一个可以视为MySQL集群的企业级数据库,用来替代昂贵的Oracle集群;
- 一个融合内存缓存技术、NoSQL技术、HDFS大数据的新型SQL Server;
- 结合传统数据库和新型分布式数据仓库的新一代企业级数据库产品;
- 一个新颖的数据库中间件产品;
Mycat是一个强大的数据库中间件,不仅仅可以用作读写分离、以及分表分库、容灾备份,而且可以用于多租户应用开发、云平台基础设施、让你的架构具备很强的适应性和灵活性,借助于即将发布的 Mycat智能优化模块,系统的数据访问瓶颈和热点一目了然,根据这些统计分析数据,你可以自动或手工调整后端存储,将不同的表映射到不同存储引擎上,而整个应用的代码一行也不用改变。
官方图解来一张: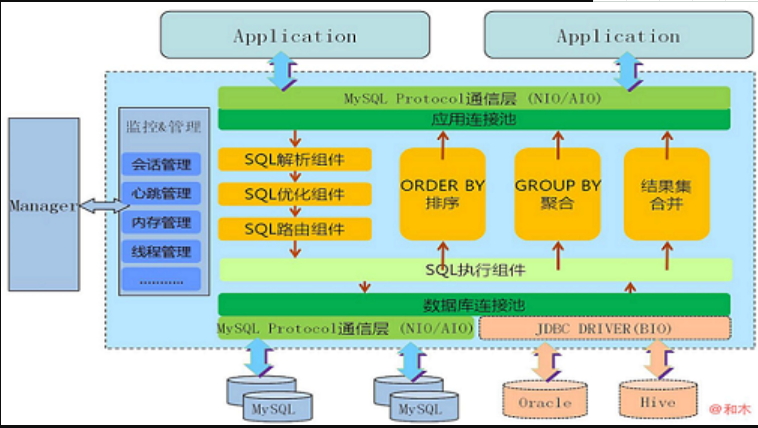
Mycat原理
拦截sql→解析sql→数据资源管理→数据源分配→请求/响应→结果整合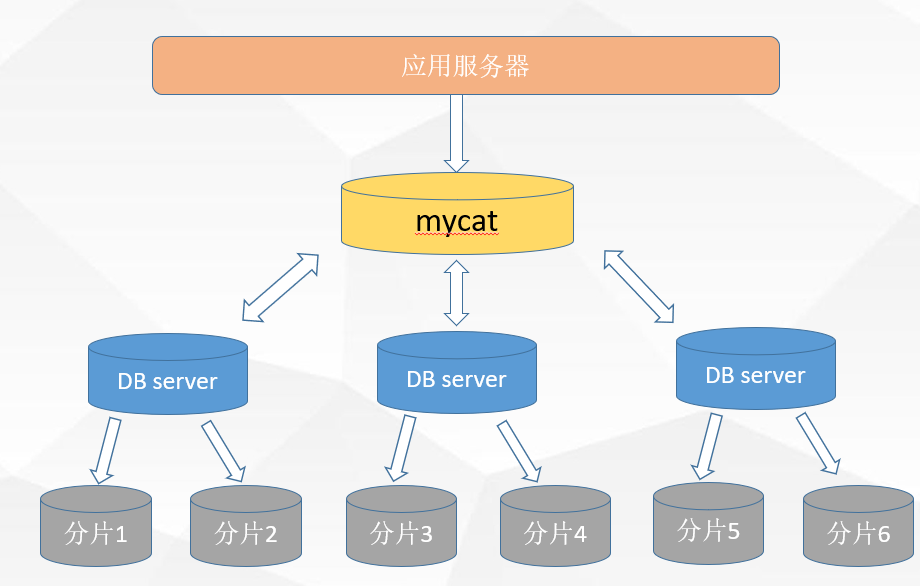
MyCat中概念的理解
逻辑库:通常对实际应用来说,并不需要知道中间件的存在,业务开发人员只需要知道数据库的概念,所以数据库中间件可以被看做是一个或多个数据库集群构成的逻辑库。
逻辑表:对应用来说,读写数据的表就是逻辑表。逻辑表,可以是数据切分后,分布在一个或多个分片库中,也可以不做数据切分,不分片,只有一个表构成。
分片表:分片表,是指那些原有的很大数据的表,需要水平切分到多个数据库的表,这样,每个分片都有一部分数据,所有分片构成了完整的数据。
非分片表:一个数据库中并不是所有的表都很大,某些表是可以不用进行切分的,非分片是相对分片表来说的,就是那些不需要进行数据切分的表。
ER表:子表的记录与所关联的父表记录存放在同一个数据分片上,即子表依赖于父表,通过表分组(Table Group)保证数据Join不会跨库操作。
全局表:所有的分片都有一份数据的拷贝,所有将字典表或者符合字典表特性的一些表定义为全局表。系统表(变动不频繁,规模不大)。
分片节点(dataNode):数据切分后,每个分片节点(dataNode)不一定都会独占一台机器,同一机器上面可以有多个分片数据库,这样一个或多个分片节点(dataNode)所在的机器就是节点主机,为了规避单节点主机并发数限制,尽量将读写压力高的分片节点(dataNode)均衡的放在不同的节点主机(dataHost)。
分片规则(rule):一个大表被分成若干个分片表,就需要一定的规则。
全局序列号(sequence):数据切分后,原有关系数据库中的主键约束在分布式条件下将无法使用,因此需要引入外部机制保证数据唯一性标识,这种保证全局性的数据唯一标识的机制就是全局序列号。
2分钟看懂MySQL分库分表原理
【导语】随着业务的增长,mysql中保存的数据会越来越多。此时,数据库很容易成为系统性能的一个瓶颈,单机存储容量、IO、CPU处理能力都有限,当单表的数据量达到1000W或100G以后,库表的增删改查操作面临着性能大幅下降的问题。分库分表是一种解决办法。
分库分表实际上就是对数据进行切分。我们一般可以将数据切分分为两种方式:垂直(纵向)切分和水平(横向)切分。
垂直切分
垂直切分常见有垂直分库和垂直分表两种。
1. 垂直分库
垂直分库就是根据业务耦合性,将关联度低的不同表存储在不同的数据库。
思想与”微服务治理“类似,将系统拆分为多个业务,每个业务使用自己单独的数据库。比如下图:

将应用拆分为客户,存款和贷款三个业务,每个业务使用自己单独的数据库。
2. 垂直分表
垂直分表是基于数据库中的表字段来进行的。业务中可能存在一些字段比较多的表,表中某些字段长度较大。这些长字段我们又只是偶尔需要用到。这时候我们就可以考虑将表进行垂直拆分了。将某些不常用的,但是长度又很大的字段拎出来放到另外一张表。
MySQL底层是通过数据页存储的,一条记录占用空间过大会导致跨页,造成额外的性能开销。另外数据库以行为单位将数据加载到内存中,这样表中字段长度较短且访问频率较高,内存能加载更多的数据,命中率更高,减少了磁盘IO,从而提升了数据库性能。
垂直切分例子如下图:

我们将一张包含4个字段的表拆分为2张表,在业务代码里面,通过字段C1来进行关联。
3. 垂直切分优缺点
优点:
1. 不同系统可以使用不同的库表,解决业务系统层面的耦合,业务清晰
2. 高并发场景下,垂直切分一定程度地提升IO、数据库连接数,缓解单机硬件资源的瓶颈
缺点:
1. 部分查询需要在业务代码逻辑里面做聚合,增加开发复杂度
2. 事务处理复杂,可能需要在业务代码层面做处理
3.不能根本解决单表数据量过大的问题
水平切分
当业务难以更细粒度地进行垂直切分,或者切分后单表数据依然过大,存在单库读写、存储性能瓶颈时候,这时候就可以考虑水平切分了。
水平切分又可以分为库内分表和分库分表。是根据表内数据的内在逻辑关系,将同一个表按不同的条件分散到多个数据库或多个表中,每个表中只包含一部分数据,从而使得单个表的数据量变小,达到分布式的效果。
1. 库内分表
库内分表就是在同一个db上,将表按照某种条件拆分为多张表。
比如一张订单表,我们可以依据订单的日期,按月建表。一月份的订单放month_201901这张表,二月份的订单放month_201902这张表。库内分表只解决单表数据量过大问题,但没有将表分布到不同机器上,所有请求还是在一台物理机上竞争cpu,内存,IO,对于减轻mysql负载压力来说帮助不大。
2. 分库分表
分库分表就是将表不仅拆分,而且拆分到不同机器上。
比如我们腾讯云上的DCDB就是这种处理方法。可以指定一张表的shardKey,然后对shardKey取hash,根据hash值将数据放到不同的数据库中。这个可以解决单机物理资源的瓶颈问题。
分库分表的示例如下:

上面示例先根据业务耦合性垂直分库,然后再针对单个库进行分库分表。
2.1 分库分表优缺点
优点:
1. 不存在单库数据量过大、高并发的性能瓶颈,提升系统稳定性和负载能力
2. 应用端改造较小,不需要拆分业务模块
缺点:
1. 跨分片的事务一致性较难保障,一般需要一层中间件,介于业务和db之间。对应腾讯云上的DCDB数据库所包含的Proxy层。
2. 跨库的join关联查询性能较差
2.2 分库分表带来的问题
分库分表能有效地缓解单机和单库带来的性能瓶颈和压力,突破网络IO、磁盘存储、CPU处理能力的瓶颈,同时也带来了一些问题。
(1) 事务一致性问题
当更新内容同时分布在不同库中,不可避免会带来跨库事务问题。跨分片事务也是分布式事务,没有简单的方案,一般可使用”XA协议”和”两阶段提交”处理。
分布式事务能最大限度保证数据库操作的原子性。但在提交事务时需要协调多个节点,推后了提交事务的时间点,延长了事务的执行时间。导致事务在访问共享资源时发生冲突或死锁的概率增高。随着数据库节点的增多,这种趋势会越来越严重,从而成为系统在数据库层面上水平扩展的枷锁。
(2) 跨节点关联查询 join 问题
切分之前,系统中很多列表和详情页所需的数据可以通过sql join来完成。而切分之后,数据可能分布在不同的节点上,此时join带来的问题就比较麻烦了,考虑到性能,尽量避免使用join查询。
解决这个问题的一些方法:
a. 全局表:
全局表,也可看做是”数据字典表”,就是系统中所有模块都可能依赖的一些表,为了避免跨库join查询,可以将这类表在每个数据库中都保存一份。这些数据通常很少会进行修改,所以也不担心一致性的问题。比如腾讯云上的DCDB,可以创建广播表,其实就是全局表。每个节点都有该表的全量数据,该表的所有操作都将广播到所有物理分片(set)中。
b. 字段冗余:
一种典型的反范式设计,利用空间换时间,为了性能而避免join查询。例如:订单表保存userId时候,也将userName冗余保存一份,这样查询订单详情时就不需要再去查询”买家user表”了。
但这种方法适用场景也有限,比较适用于依赖字段比较少的情况。而冗余字段的数据一致性也较难保证,就像上面订单表的例子,买家修改了userName后,是否需要在历史订单中同步更新呢?这也要结合实际业务场景进行考虑。
c. 数据组装:
在系统层面,分两次查询,第一次查询的结果集中找出关联数据id,然后根据id发起第二次请求得到关联数据。最后将获得到的数据进行字段拼装
(3) 跨节点分页、排序、函数问题
跨节点多库进行查询时,会出现limit分页、order by排序等问题。分页需要按照指定字段进行排序,当排序字段就是分片字段时,通过分片规则就比较容易定位到指定的分片。
当排序字段非分片字段时,就变得比较复杂了。需要先在不同的分片节点中将数据进行排序并返回,然后将不同分片返回的结果集进行汇总和再次排序,最终返回给用户。显然这个过程是会降低查询的效率。对IO,CPU也会增加额外的负担。
如下图所示:
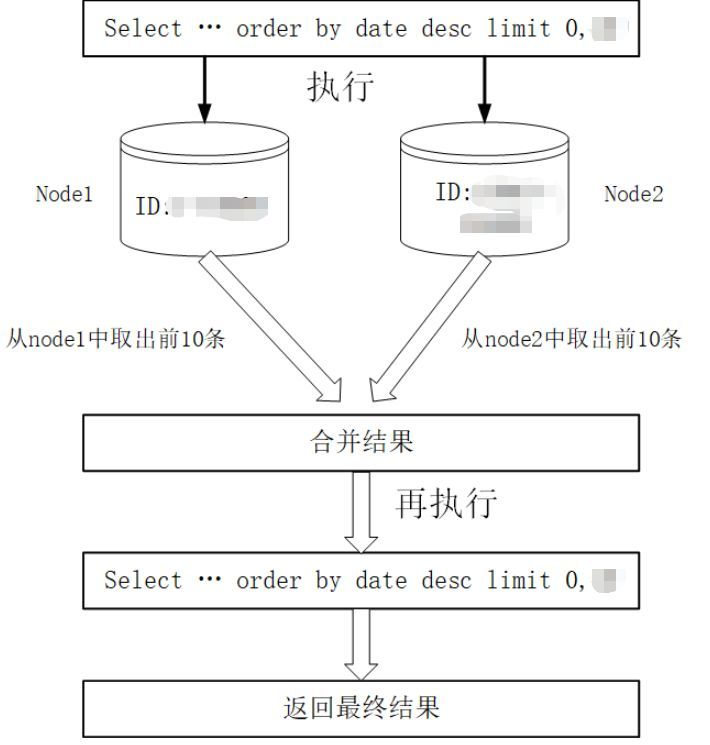
上图中只是取第一页的数据,对性能影响还不是很大。但是如果取得页数很大,情况则变得复杂很多,因为各分片节点中的数据可能是随机的,为了排序的准确性,需要将所有节点的前N页数据都排序好做合并,最后再进行整体的排序,这样的操作是很耗费CPU和内存资源的,所以页数越大,系统的性能也会越差。
在使用Max、Min、Sum、Count之类的函数进行计算的时候,也需要先在每个分片上执行相应的函数,然后将各个分片的结果集进行汇总、再次计算,最终将结果返回。
(4) 全局主键避重问题
在分库分表环境中,由于表中数据同时存在不同数据库中,主键平时使用的自增长将无用武之地,某个分区数据库自生成的ID无法保证全局唯一。因此需要单独设计全局主键,以避免跨库主键重复问题。
总结
分库分表可以解决一些问题(比如单机的IO,CPU、磁盘瓶颈问题),但也增添了一些新问题(比如事务一致性问题,跨分片join问题)。当然随着一些新的NewSql技术的成熟,分库分表这一方案也不再是业务扩张后的最优选择了。最近很火的TIDB,CynosDB都给出了更优的解决方案。
MySQL数据库如何定制分库分表中间件详解
一般来说,影响数据库最大的性能问题有两个,一个是对数据库的操作,一个是数据库中的数据太大。对于前者我们可以借助缓存来减少一部分读操作,针对一些复杂的报表分析和搜索可以交给 Hadoop 和ElasticSearch 。对于后者,我们就只能分库分表,读写分离。
互联网行业随着业务的复杂化,大多数应用都会经历数据的垂直分区。一个复杂的流程会按照领域拆分成不同的服务,每个服务中心都拥有自己独立的数据库。拆分后服务共享,业务更清晰,系统也更容易扩展,同时减少了单库数据库连接数的压力,也在一定程度上提高了单表大数据量下索引查询的效率。当然业务隔离,也可以避免一个业务把数据库拖死导致所有业务都死掉,我们将这种按照业务维度,把一个库拆分为多个不同的库的方式叫做垂直拆分。
垂直拆分也包含针对长表(属性很多)做冷热分离的拆分。例如,在商品系统设计中,一个商品的生产商、供销商以及特有属性,这些字段变化频率低,查询次数多,叫做冷数据;而商品的份额,关注量等类似的统计信息变化频率较高,叫做活跃数据或者热数据。在 MySQL 中,冷数据查询多更新少,适合用 MyISAM 存储引擎,而热数据更新比较频繁适合用 InnoDB,这也是垂直拆分的一种。
当单表数据量随着业务发展继续膨胀,在 MySQL 中当数据量达到千万级时,就需要考虑进行水平拆分了,这样数据就分散到不同的表上,单表的索引大小得到控制,可以提升查询性能。当数据库的实例吞吐量达到性能瓶颈后,我们需要水平扩展数据库的实例,让多个数据库实例分担请求,这种根据分片算法,将一个库拆分成多个一样结构的库,将多个表拆分成多个结构相同的表就叫做水平拆分。
数据拆分也有很多缺点,数据分散,数据库的 Join 操作变得更加复杂,分片后数据的事务一致性很难保证,同时数据的扩容和维护难度增加,拆分规则也可能导致某个业务需要同时查询所有的表然后进行聚合。如果需要排序和函数计算则更加复杂,所以不到万不得已可以先不必拆分。
根据分库分表方案中实施切片逻辑的层次不同,我们将分库分表的实现方案分成以下4种:
1. 在应用层直接分片
这种方式将分片规则直接放在应用层,虽然侵入了业务,开发人员不仅既需要实现业务逻辑也需要实现分库分表的配置的开发,但是实现起来简单,适合快速上线,通过编码方式也更容易实现跨表遍历的情况。后期故障也更容易定位,大多数公司都会在业务早期采用此种方式过渡,后期分表需求增多,则会寻求中间件来解决,以下代码为铜板街早期订单表在 DAO 层将分片信息以参数形式传到 mybatis 的 mapper 文件中的实现方案。
-
-
public OrderDO findByPrimaryKey(String orderNo) {
-
-
Assert.hasLength(orderNo, "订单号不能为空");
-
-
Map<String, Object> map = new HashMap<String, Object>(3);
-
map.put("tableSuffix", orderRouter.routeTableByOrderNo(orderNo));
-
map.put("dbSuffix", orderRouter.routeDbByOrderNo(orderNo));
-
map.put("orderNo", orderNo);
-
-
Object obj = getSqlSession().selectOne("NEW_ORDER.FIND_BY_PRIMARYKEY", map);
-
if (obj != null && obj instanceof OrderDO) {
-
return (OrderDO) obj;
-
}
-
return null;
-
}
2. 在ORM层直接分片
这种方式通过扩展第三方 ORM 框架,将分片规则和路由机制嵌入到 ORM 框架中,如hibernate 和 mybatis,也可以基于 spring jdbctemplate 来实现,目前实现方案较少。
3. 客户端定制 JDBC 协议
这种方式比较常见对业务侵入低。通过定制 JDBC 协议,针对业务逻辑层提供与 JDBC一致的接口,让开发人员不必要关心分库分表的具体实现,分库分表在 JDBC 内部搞定,对业务层透明。目前流行的 ShardingJDBC、TDDL 便采用了这种方案。这种方案需要开发人员熟悉 JDBC 协议,研发成本较低,适合大多数中型企业。
4. 代理分片
此种分片方式,是在应用层和数据库层增加一个代理,把分片的路由规则配置在代理层,代理层提供与 JDBC 兼容的接口给应用层,开发人员不用关心分片逻辑实现,只需要在代理层配置即可。增加代理服务器,需要解决代理的单点问题增加硬件成本,同时所有的数据库请求增加了一层网络传输影响性能,当然维护也需要更资深的专家,目前采用这种方式的框架有 cobar 和 mycat。
切片算法
选取分片字段
分片后,如果查询的标准是根据分片的字段,则根据切片算法,可以路由到对应的表进行查询。如果查询条件中不包含分片的字段,则需要将所有的表都扫描一遍然后在进行合并。所以在设计分片的时候我们一般会选择一个查询频率较高的字段作为分片的依据,后续的分片算法会基于该字段的值进行。例如根据创建时间字段取对应的年份,每年一张表,取电话号码里面的最后一位进行分表等,这个分片的字段我们一般会根据查询频率来选择。例如在互金行业,用户的持仓数据,我们一般选择用户 id 进行分表,而用户的交易订单也会选择用户 id 进行分表,但是如果我们要查询某个供应商下在某段时间内的所有订单就需要遍历所有的表,所以有时候我们可能会需要根据多个字段同时进行分片,数据进行冗余存储。
分片算法
分片规则必须保证路由到每张物理表的数据量大致相同,不然上线后某一张表的数据膨胀的特别快,而其他表数据相对很少,这样就失去了分表的意义,后期数据迁移也有很高的复杂度。通过分片字段定位到对应的数据库和物理表有哪些算法呢?(我们将分表后在数据库上物理存储的表名叫物理表,如 trade_order_01,trade_order_02,将未进行切分前的表名称作逻辑表如 trade_order)大致可以有以下分类:
- 按日期 如年份,季度,月进行分表,这种维度分表需要注意在边缘点的垮表查询。例如如果是根据创建时间按月进行分片,则查询最近3天的数据可能需要遍历两张表,这种业务比较常见,但是放中间件层处理起来就比较复杂,可能在应用层特殊处理会简单点。
- 哈希 ,这种是目前比较常用的算法,但是这里谨慎推荐,因为他的后期扩容是件很头痛的事情,例如根据用户 ID 对64取模,得到一个0到63的数字,这里最多可以切分64张表{0,1,2,3,4… 63},前期可能用不到这么多,我们可以借助一致性哈希的算法,每4个连续的数字分成放到一张表里。例如 0,1,2,3 分到00这张表,4,5,6,7分到04这张表,用算法表示 floor(userID % 64 / 4) * 4 假设 floor为取整的效果。
按照一致性哈希算法,当需要进行扩容一倍时需要迁移一半的数据量,虽然不至于迁移所有的数据,如果没有工具也是需要很大的开发量。下图中根据分表字段对16取余后分到4张表中,后面如果要扩容一倍则需要迁移一半的数据。
截取 这种算法将字段中某一段位置的数据截取出来,例如取电话号码里面的尾数,这种方式实现起来简单,但在上线前一定要预测最终的数据分布是否会平均。比如地域,姓氏可能并不平均等,以4结尾的电话号码也相对偏少。
特别注意点
分库和分表算法需要保证不相关,上线前一定要用线上数据做预测。例如分库算法用“用户id%64 分64个库” 分表算法也用 “用户id%64 分64张表”,总计 64 * 64 张表,最终数据都将落在 以下 64张表中 00库00表,01库01表… 63库63表, 其他 64 * 63张表则没有数据。这里可以推荐一个算法,分库用 用户ID/64 % 64 , 分表用 用户ID%64 测试1亿笔用户id发现分布均匀。
在分库分表前需要规划好业务增长量,以预备多大的空间,计算分表后可以支持按某种数据增长速度可以维持多久。
如何实现客户端分片
客户端需要定制 JDBC 协议,在拿到待执行的 sql 后,解析 sql,根据查询条件判断是否存在分片字段。如果存在,再根据分片算法获取到对应的数据库实例和物理表名,重写 sql,然后找到对应的数据库 datasource 并获取物理连接,执行 sql,将结果集进行合并筛选后返回。如果没有分片字段,则需要查询所有的表,注意,即使存在分片字段,但是分片字段在一个范围内,可能也需要查询多个表,针对 select 以外的 sql 如果没有传分片字段建议直接抛出异常。
JDBC 协议
我们先回顾下一个完整的通过 JDBC 执行一条查询 sql 的流程,其实 druid 也是在 JDBC 上做增强来做监控的,所以我们也可以适当参考 druid 的实现。
-
-
public void testQ() throws SQLException,NamingException{
-
Context context = new InitialContext();
-
DataSource dataSource = (DataSource)context.lookup("java:comp/env/jdbc/myDataSource");
-
Connection connection = dataSource.getConnection();
-
PreparedStatement preparedStatement = connection.prepareStatement("select * from busi_order where id = ?");
-
preparedStatement.setString(1,"1");
-
ResultSet resultSet = preparedStatement.executeQuery();
-
while(resultSet.next()){
-
String orderNo = resultSet.getString("order_no");
-
System.out.println(orderNo);
-
}
-
preparedStatement.close();
-
connection.close();
-
}
- datasource 需要提供根据分片结果获取对应的数据源的datasource,返回的connection应该是定制后的 connection,因为在执行 sql 前还无法知道是哪个库哪个表,所以只能返回一个逻辑意义上的 connection。
- 哈希 connection 定制的 connection,需要实现获取 statement,执行 sql 关闭。设置auto commit 等方法,在执行 sql 和获取 statement 的时候应该进行路由找到物理表后 在执行操作。由于该 connection 是逻辑意义上的,针对关闭,设置 auto commit 等需要将关联的多个物理 connection 一起设置。
- statement 定制化的 statement,由于和 connection 都提供了执行 sql 的方法,所以我们可以将执行 sql 都交给一个执行器执行,connection 和 statement 中都通过这个执行器执行sql。在执行器重解析 sql 获取物理连接,结果集处理等操作。
- resultset resultset 是一个迭代器,遍历的时候数据源由数据库提供,但我们在某些有排序和 limit 的查询中,可能迭代器直接在内存中遍历数据。
SQL解析
sql 解析一般借助 druid 框架里面的 SQLStatementParser 类。解析好的数据都在 SQLStatement 中,当然有条件的可以自己研究 SQL 解析,不过可能工作量有点大。
- 解析出 sql 类型,目前生成环境主要还是4中 sql 类型: SELECT DELETE UPDATE INSERT ,目前是直接解析 sql 是否以上面4个单词开头即可,不区分大小写。
- insert 类型需要区分,是否是批量插入,解析出 insert 插入的列的字段名称和对应的值,如果插入的列中不包含分片字段,将无法定位到具体插入到哪个物理表,此时应该抛出异常。
- delete 和 update 都需要解析 where 后的条件,根据查询条件里的字段,尝试路由到指定的物理表,注意此时可能会出现 where 条件里面 分片字段可能是一个范围,或者分片字段存在多个限制。
- select 和其他类型不同的是,返回结果是一个 list,而其他三种 sql 直接返回状态和影响行数即可。同时 select 可能出现关联查询,以及针对查询结果进行筛选的操作,例如where 条件中除了普通的判断表达式,还可能存在 limit,order by,group by,having等,select 的结果中也可能包含聚合统计等信息,例如 sum,count,max,min,avg等,这些都需要解析出来方便后续结果集的处理,后续重新生成 sql 主要是替换逻辑表名为物理表名,并获取对应的数据库物理连接。
- 针对 avg 这种操作,如果涉及查询多个物理表的,可能需要改写 sql 去查询 sum 和count 的数据或者 avg 和 count 的数据,改写需要注意可能原 sql 里面已经包含了count,sum等操作了。
分片路由算法
分片算法,主要通过一个表达式,从分片字段对应的值获取到分片结果,可以提供简单地 EL表达式,就可以实现从值中截取某一段作为分表数据,也可以提供通用的一致性哈希算法的实现,应用方只需要在 xml 或者注解中配置即可,以下为一致性哈希在铜板街的实现。
/**
* 最大真实节点数
*/
private int max;
/**
* 真实节点的数量
*/
private int current;
private int[] bucket;
private Set suffixSet;
public void init() {
bucket = new int[max];
suffixSet = new TreeSet();
int length = max / current;
int lengthIndex = 0;
int suffix = 0;
for (int i = 0; i < max; i++) {
bucket[i] = suffix;
lengthIndex ++;
suffixSet.add(suffix);
if (lengthIndex == length){
lengthIndex = 0;
suffix = i + 1;
}
}
}
public VirtualModFunction(int max, int current){
this.current = current;
this.max = max;
this.init();
}
@Override
public Integer execute(String columnValue, Map<String, Object> extension) {
return bucket[((Long) (Long.valueOf(columnValue) % max)).intValue()];
}
这里也可以顺带做一下读写分离,配置一些读操作路由到哪个实例,写操作路由到哪个实例,并且做到负载均衡,对应用层透明。
结果集合并
如果需要在多个物理表上执行查询,则需要对结果集进行合并处理,此处需要注意返回是一个迭代器 resultset。
- 统计类 针对 sum count,max,min 只需要将每个结果集的返回结果在做一个 max 和min,count 和 sum 直接相加即可,针对 avg 需要通过上面改写的 sql 获取 sum 和count 然后相除计算平均值。
- 排序类大部分的排序都伴随着 limit 限制查询条数。例如返回结果需要查询最近的2000条记录,并且根据创建时间倒序排序,根据路由结果需要查询所有的物理表,假设是4张表,如果此时4张表的数据没有时间上的排序关系,则需要每张表都查询2000条记录,并且按照创建时间倒序排列,现在要做的就是从4个已经排序好的链表,每个链表最多2000条数据,重新排序,选择2000条时间最近的,我们可以通过插入排序的算法,每次分别从每个链表中取出时间最大的一个,在新的结果集里找到位置并插入,直到结果集中存在2000条记录,但是这里可能存在一个问题,如果某一个链表的数据普遍比其他链表数据偏大,这样每个链表取500条数据肯定排序不准确,所以我们还需要保证当前所有链表中剩下的数据的最大值比新结果集中的数据小。 而实际上业务层的需求可能并不是仅仅取出2000条数据,而是要遍历所有的数据,这种要遍历所有数据集的情况,建议在业务层控制一张表一张表的遍历,如果每次都要去每张表中查询在排序严重影响效率,如果在应用层控制,我们在后面在聊。
- 聚合类 group by 应用层需要尽量避免这种操作,这些需求最好能交给搜索引擎和数据分析平台进行,但是作为一个中间件,对于group by 这种我们经常需要统计数据的类型还是应该尽量支持的,目前的做法是 和统计类处理类似,针对各个子集进行合并处理。
优化
以上流程基本可以实现一个简易版本的数据库分库分表中间件,为了让我们的中间件更方便开发者使用,为日常工作提供更多地遍历性,我们还可以从以下几点做优化。
和 spring 集成
针对哪些表需要进行分片,分片规则等,这些需要定制化的配置,我们可以在程序里面手工编码,但是这样业务层又耦合了分表的逻辑,我们可以借助 spring 的配置文件,直接将 xml 里的内容映射成对应的 bean 实例。
- 我们首先要设计好对应的配置文件的格式,有哪些节点,每个节点包含哪些属性,然后设计自己命名空间,和对应的 XSD 校验文件,XSD 文件放在 META-INF下。
- 编写 NamespaceHandlerSupport 类,注册每个节点元素对应的解析器
-
public class BaymaxNamespaceHandler extends NamespaceHandlerSupport {
-
-
//com.alibaba.dubbo.config.spring.schema.DubboNamespaceHandler
-
-
public void init() {
-
registerBeanDefinitionParser("table", new BaymaxBeanDefinitionParser(TableConfig.class, false));
-
registerBeanDefinitionParser("context", new BaymaxBeanDefinitionParser(BaymaxSpringContext.class, false));
-
registerBeanDefinitionParser("process", new BaymaxBeanDefinitionParser(ColumnProcess.class, false));
-
}
-
-
}
- 在 META-INF 文件中增加配置文件 spring.handlers 中配置 spring遇到某个namespace下的节点后 通过哪个解析器解析,最终返回配置实例。
http://baymax.tongbanjie.com/schema/baymax-3.0=com.tongbanjie.baymax.spring.BaymaxNamespaceHandler
- 在 META-INF 文件中增加配置文件 spring.schema 中配置 spring遇到某个namespace下的节点后 通过哪个XSD文件进行校验。
http://baymax.tongbanjie.com/schema/baymax-3.0.xsd=META-INF/baymax-3.0.xsd
- 可以借助ListableBeanFactory的getBeansOfType(Class clazz) 来获取某个class类型的所有实例,从而获得所有的配置信息。
当然也可以通过自定义注解进行申明,这种方式我们可以借助 BeanPostProcessor 的时候判断类上是否包含指定的注解,但是这种方式比较笨重,而且所加注解的类必须在spring 容器管理中,也可以借助 ClassPathScanningCandidateComponentProvider 和 AnnotationTypeFilter 实现,或者直接通过 classloader 扫描指定的包路径。
如何支持分布式事务
由于框架本身通过定制 JDBC 协议实现,虽然最终执行 sql 的是通过原生 JDBC,但是对上层应用透明,同时也对上层基于 JDBC 实现的事物透明,spring 的事物管理器可以直接使用。
我们考虑下以下问题,如果我们针对多张表在一个线程池内并发的区执行 sql,然后在合并结果,这是否会影响 spring的 事物管理器?
首先 spring 的声明式事物是通过 aop 在切面做增强,事物开始先获取 connection 并设置 setAutocommit 为 fasle,事物结束调用 connection 进行 commit 或者 rollback,通过 threadlocal 保存事物上下文和所使用的 connection 来保证事物内多个 sql共用一个 connection 操作。但是如果我们在解析 sql 后发现要执行多条 sql 语句,我们通过线程池并发执行,然后等所有的结果返回后进行合并,(这里先不考虑,多个 sql 可能需要在不同的数据库实例上执行),虽然通过线程池将导致 threadlocal 失效,但是我们在 threadlocal 维护的是我们自己定制的 connection,并不是原生的 JDBC 里的 connection ,而且这里并发执行并不会让事物处理器没办法判断是否所有的线程都已经结束,然后进行 commit 或者 rollback 。因为这里的线程池是在我们定制的 connection 执行 sql 过程中运用的,肯定会等到所有线程处理结束后并且合并数据集才会返回。所以在本地事物层面,通过定制化 JDBC 可以做到对上层事物透明。
如果我们进行了分库,同一个表可能在多个数据库实例里,这种如果要对不同实例里的表进行更新,那么将无法在使用本地事物,这里我们不在讨论分布式事物的实现,由于二阶段提交的各种缺点,目前很少有公司会基于二阶段做分布式事物,所以我们的中间件也可以根据自己的具体业务考虑是否要实现 XA,目前铜板街大部分分布式事物需求都是通过基于 TCC 的事物补偿做的,这种方式对业务幂等要求较高,同时要基于业务层实现回滚逻辑。
提供一个通用发号器
为什么要提供一个发号器,我们在单表的时候,可能会用到数据库的自增ID,但当分成多表后,每个表都进行单独的ID自增,这样一个逻辑表内的ID 就会出现重复。
我们可以提供一个基于逻辑表自增的主键ID 获取方式,如果没有分库只分表,可以在数据库中增加一个表维护每张逻辑表对应的自增ID。每次需要获取ID 的时候都先查询这个标当前的ID 然后加一返回,然后在写入数据库,为了并发获取的情况,我们可以采用乐观锁,类似于CAS,update的时候传人以前的ID。如果被人修改过则重新获取,当然我们也可以一次性获取一批ID例如一次获取100个,等这100个用完了在重新获取,为了避免这100个还没用完,程序正常或非正常退出,在获取这100个值的时候就将数据库通过CAS更新为已经获取了100个值之和的值。
不推荐用 UUID,无序,太长占内存影响索引效果,不携带任何业务含义。
借助 ZOOKEEPER 的 zone 的版本号来做序列号。
借助 REDIS 的 INCR 命令,进行自增,每台 redis 设置不同的初始值,但是设置相同的歩长。
A:1,6,11,16,21 B:2,7,12,17,22 C:3,8,13,18,23 D:4,9,14,19,24 E:5,10,15,20,25
snowflake算法:其核心思想是:使用41bit作为毫秒数,10bit作为机器的ID(5个bit是数据中心,5个bit的机器ID),12bit作为毫秒内的流水号(意味着每个节点在每毫秒可以产生 4096 个 ID)。
铜板街目前所使用的订单号规则: - 15位时间戳,4位自增序列,2位区分订单类型,7位机器ID,2位分库后缀,2位分表后缀 共32位 - 7位机器ID 通过IP来获取 - 15位时间戳精确到毫秒,4位自增序列,意味着单JVM1毫秒可以生成9999个订单 。
最后4位可以方便的根据订单号定位到物理表,这里需要注意分库分表如果是根据一致性哈希算法,这个地方最好存最大值, 例如 用户id % 64 取余 最多可以分64张表,而目前可能用不到这么多,每相邻4个数字分配到一张表,共16张表,既 userID % 64 / 4 * 4 ,而这个地方存储 userID % 64 即可,不必存最终分表的结果,这种方式方便后续做扩容,可能分表的结果变更了,但是订单号却无法进行变更。
-
@Override
-
public String routeDbByUserId(String userId) {
-
Assert.hasLength(userId, "用户ID不能为空");
-
-
Integer userIdInteger = null;
-
try {
-
userIdInteger = Integer.parseInt(userId);
-
} catch (Exception ex) {
-
logger.error("解析用户ID为整数失败" + userId, ex);
-
throw new RuntimeException("解析用户ID为整数失败");
-
}
-
-
//根据路由规则确定,具体在哪个库哪个表 例如根据分库公式最终结果在0到63之间 如果要分两个库 mod为32 分1个库mod为64 分16个库 mod为4
-
//规律为 64 = mod * (最终的分库数或分表数)
-
int mod = orderSplitConfig.getDbSegment();
-
-
Integer dbSuffixInt = userIdInteger / 64 % 64 / mod * mod ;
-
-
return StringUtils.leftPad(String.valueOf(dbSuffixInt), 2, '0');
-
}
-
-
-
@Override
-
public String routeTableByUserId(String userId) {
-
-
Assert.hasLength(userId, "用户ID不能为空");
-
-
Integer userIdInteger = null;
-
try {
-
userIdInteger = Integer.parseInt(userId);
-
} catch (Exception ex) {
-
logger.error("解析用户ID为整数失败" + userId, ex);
-
throw new RuntimeException("解析用户ID为整数失败");
-
}
-
-
//根据路由规则确定,具体在哪个库哪个表 例如根据分表公式最终结果在0到63之间 如果要分两个库 mod为32 分1个库mod为64 分16个库 mod为4
-
//规律为 64 = mod * (最终的分库数或分表数)
-
int mod = orderSplitConfig.getTableSegment();
-
-
Integer tableSuffixInt = userIdInteger % 64 / mod * mod;
-
-
return StringUtils.leftPad( String.valueOf(tableSuffixInt), 2, '0');
-
}
如何实现跨表遍历
如果业务需求是遍历所有满足条件的数据,而不是只是为了取某种条件下前面一批数据,这种建议在应用层实现,一张表一张表的遍历,每次查询结果返回下一次查询的起始位置和物理表名,查询的时候建议根据 大于或小于某一个 ID 进行分页,不要 limit500,500这种,以下为铜板街的实现方式。
-
public List<T> select(String tableName, SelectorParam selectorParam, E realQueryParam) {
-
-
List<T> list = new ArrayList<T>();
-
-
// 定位到某张表
-
String suffix = partitionManager.getCurrentSuffix(tableName, selectorParam.getLocationNo());
-
-
int originalSize = selectorParam.getLimit();
-
-
while (true) {
-
-
List<T> ts = this.queryByParam(realQueryParam, selectorParam, suffix);
-
-
if (!CollectionUtils.isEmpty(ts)) {
-
list.addAll(ts);
-
}
-
-
if (list.size() == originalSize) {
-
break;
-
}
-
-
suffix = partitionManager.getNextSuffix(tableName, suffix);
-
-
if (StringUtils.isEmpty(suffix)) {
-
break;
-
}
-
-
// 查询下一张表 不需要定位单号 而且也只需要查剩下的size即可
-
selectorParam.setLimit(originalSize - list.size());
-
selectorParam.setLocationNo(null);
-
}
-
-
return list;
-
}
提供一个扩容工具和管理控制台做配置可视化和监控
- 监控可以借助 druid,也可以在定制的 JDBC 层自己做埋点,将数据以报表的形式进行展示,也可以针对特定的监控指标进行配置,例如执行次数,执行时间大于某个指定时间。
- 管理控制台,由于目前配置是在应用层,当然也可以把配置独立出来放在独立的服务器上,由于分片配置基本上无法在线修改,每次修改可能都伴随着数据迁移,所以基本上只能做展示,但是分表后我们在测试环境执行 sql 去进行逻辑查询的时候,传统的 sql 工具无法帮忙做到自动路由,这样我们每次查询可能都需要手工计算下分片结果,或者要连续写好几个 sql 之后在聚合,通过这个管理控制台我们就可以直接根据逻辑表名写 sql,这样我们在测试环境或者在线上核对数据的时候,就提高了效率。
- 扩容工具,笨办法只能先从老表查询在 insert 到新表,等到新表数据完全同步完后,在切换到新的切片规则,所以我们设计分片算法的时候,需要考虑到后面扩容,例如一致性哈希就需要迁移一半的数据(扩容一倍的话) 数据迁移如果出现故障,那将是个灾难,如果我们要在不停机的情况下完成扩容,可以通过配置文件按以下流程来。
- 准备阶段.将截至到某一刻的历史表数据同步到新表 例如截至2017年10月1日之前的历史数据,这些历史数据最好不会在被修改;
- 阶段一.访问老表,写入老表;
- 阶段二.访问老表,写入老表同时写入新表 (插入和修改);
- 阶段三.将10月1日到首次写入新表之间的数据同步到新表 需要保证此时被迁移的数据全部都是终态;
- 阶段四.访问新表,写入老表和新表;
- 阶段五.访问新表,写入新表。
以上流程适用于,订单这种历史数据在达到终态后将不会在被修改,如果历史数据也可能被修改,则可能需要停机,或者通过 canel 进行数据同步。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号