
flux查询语言精进
背景说明
该文章内容,基于influxdb 2.7版本撰写。
influxdb官方支持两种查询语言:
1、influxql
2、flux
influxql让开发人员使用sql查询influxdb。优点是学习成本低,缺点功能不够强大。
而flux查询语言,功能很强大,学习成本较高。另外由于influxdb UI只支持这一种语言,所以还是得学一学。
官方现在主推的也是flux语言:https://blog.51cto.com/u_15075523/4538255
flux学习资料:
1、https://github.com/influxdata/flux
先简单了解下它的语法。语法了解之后,就会觉得并不复杂
2、学习它的逻辑(数据模型)
https://docs.influxdata.com/flux/v0/get-started/data-model/
3、参考手册
https://docs.influxdata.com/flux/v0/stdlib/universe/
https://github.com/influxdata/flux/blob/master/docs/SPEC.md
更正:
在influxdb3.0版本中,flux语言已经处于维护状态。官方改变路线,准备采纳SQL标准。
https://www.influxdata.com/blog/the-plan-for-influxdb-3-0-open-source/
Flux is in maintenance mode. We will continue to support and run it for our customers with security and critical fixes, but our current focus is on our core SQL and InfluxQL query engine.
关于flux语言的历史,可以参考https://news.ycombinator.com/item?id=17567554&ref=timescale.com
大概在18年,官方发明了flux语言,对它的定义:
- flux是面向流式数据,通过管道,对数据进行转换、聚合等。
- flux管道的语法,使得可易测试。很容易对中间结果做测试,sql这方面比较差
- 可以自定义函数,并且自定义的函数易分享,易复用。 简单说,要打造一个生态。
- flux是一门脚本语言,不仅仅是查询语言。flux在数据查询之外,还可以对数据进行处理(窗口函数、去重、求差值等),这些工作之前往往是由python等应用层来做的。
当时的愿景轰轰烈烈,今天花了半天时间,学习了flux,感觉到对于时序数据处理来说,它确实挺好。
由于官方在influxdb3.0版本中弃用了flux语言,因此呢,为了兼容即将到来了inlfluxdb 3.0社区版本,就不再计划把flux应用到项目中了。比如在使用java查询influxdb时,应该采用的是influxql,而不是flux语言。
influxdb UI 挺难用,分享下我的解决办法
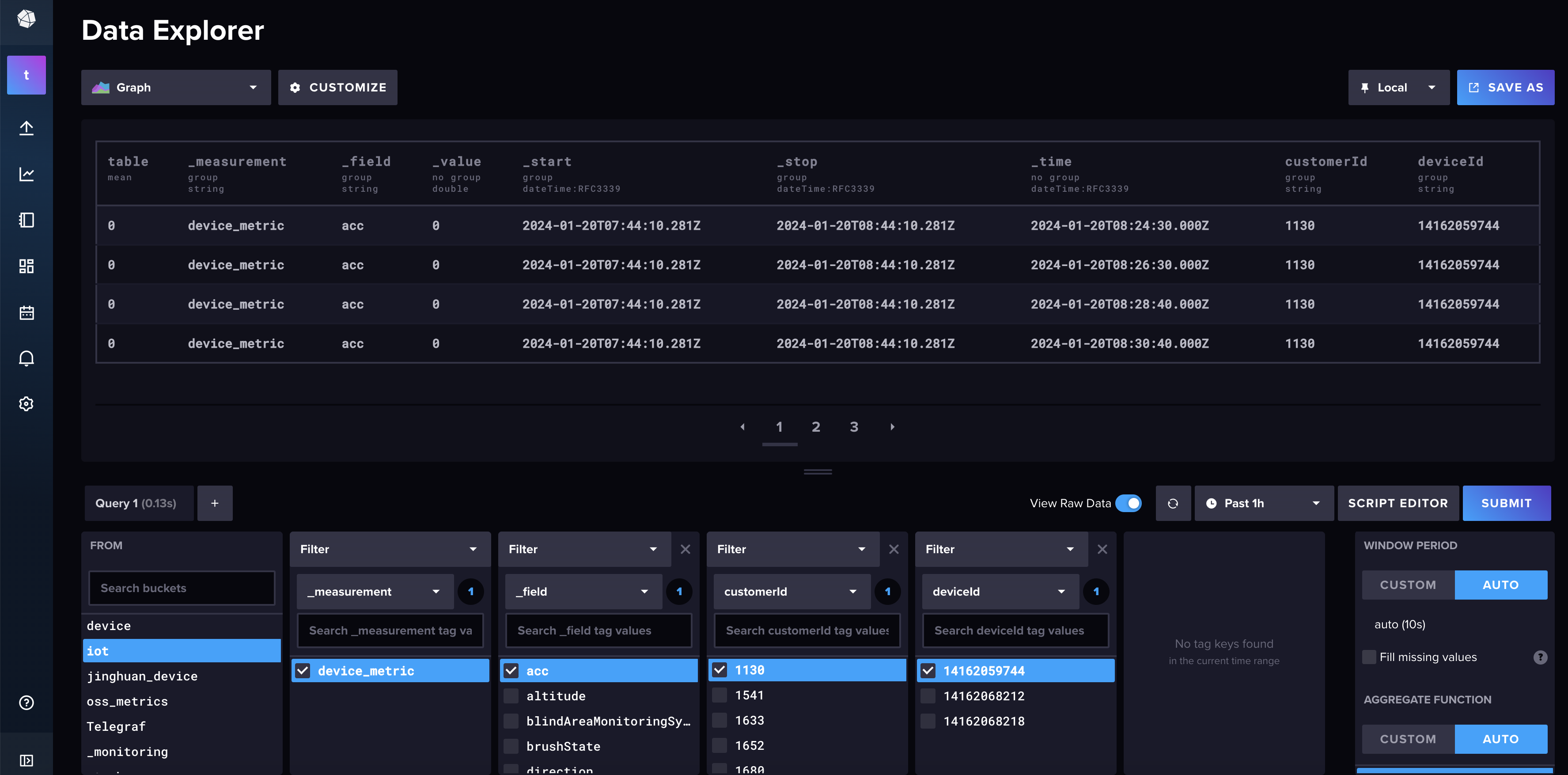
这是UI提供的查询界面,在我看来有几个问题:
1、时间的时区,默认是UTC,需要在脑子中做转换
2、无效的列太多,并且不能全局修改。 如我想隐藏_start、_stop列
3、表格中每页展示行数太少。如果想展示更多行,就需要把下面的query面板往下拉,然后query这块就不方便了(体验下就能明白)
解决办法:
使用UI提供的dashboard功能,然后通过自定义flux查询语言,对列、时区等进行定制,后续做相关查询时,直接通过dashboard进入找到模版,然后修改相关参数就能使用了。
看效果:
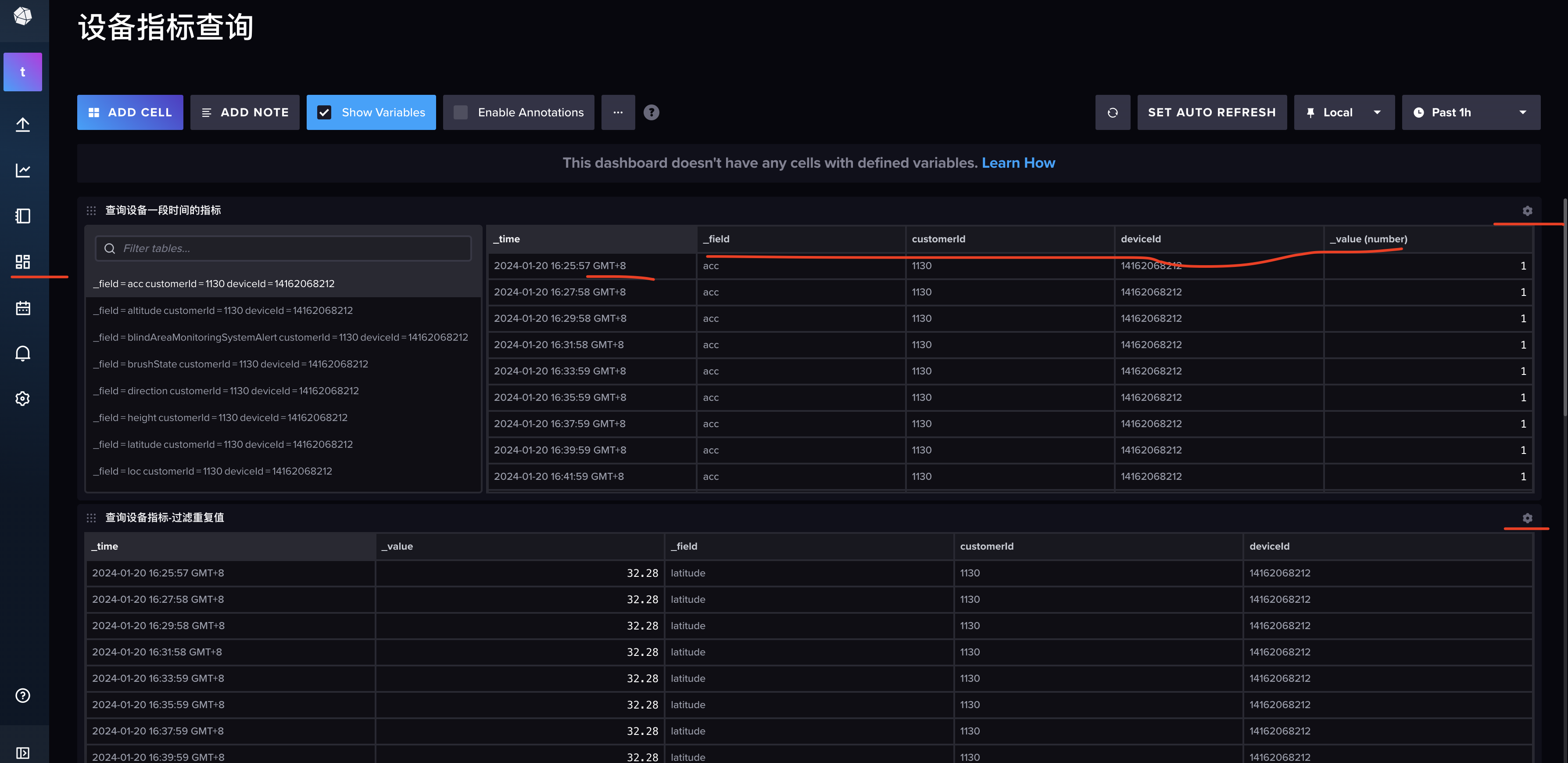
然后点击右侧的编辑功能:
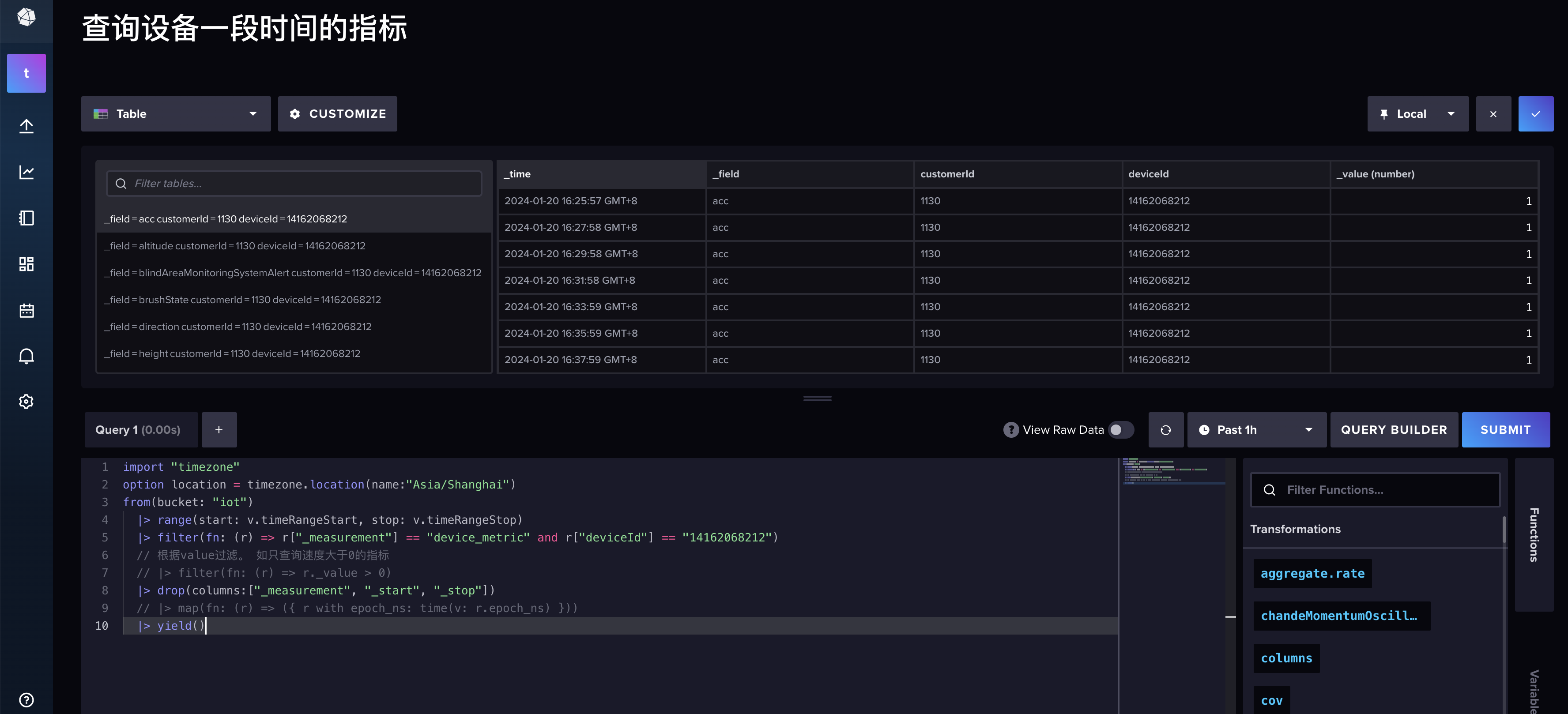
这样每次时,如果需要查询指定设备的数据,修改flux的参数就可以了。
通过dashboard,还有个好处:我可以把常用的查询语句(窗口函数、数据去重、单设备数据查询等),分别作为一个独立的panel,添加到dashboard,其他同事通过这里,很快就可以做influxdb的查询了(降低他们的学习成本)。
当然了,这里就必须先学习flux语言,才能办到。
分享下我的flux查询语句
查询一个设备的指标数据。
要求:
- 使用北京时间
- 只返回我需要的列
import "timezone"
option location = timezone.location(name:"Asia/Shanghai")
from(bucket: "iot")
|> range(start: v.timeRangeStart, stop: v.timeRangeStop)
|> filter(fn: (r) => r["_measurement"] == "device_metric" and r["deviceId"] == "14162068212")
// 根据value过滤。 如只查询速度大于0的指标
// |> filter(fn: (r) => r._value > 0)
|> drop(columns:["_measurement", "_start", "_stop"])
// |> map(fn: (r) => ({ r with epoch_ns: time(v: r.epoch_ns) }))
|> yield()
对连续时间内重复指标值进行去重。
举例,一个车辆在不间断地上报位置数据,如果车停止不动,可能连续1小时上报的GPS信息都是不变的,业务上需要对数据进行过滤,此类场景只保留最早的一个点就可以。
from(bucket: "iot")
|> range(start: v.timeRangeStart, stop: v.timeRangeStop)
|> filter(fn: (r) => r["_measurement"] == "device_metric" and r["deviceId"] == "14162068212" and r["_field"] == "latitude")
// 根据value过滤。 如只查询速度大于0的指标
// |> filter(fn: (r) => r._value > 0)
|> duplicate(column: "_value", as: "diff")
|> difference(columns: ["diff"],keepFirst: true)
|> filter(fn: (r) => not exists r.diff or r.diff != 0)
|> drop(columns:["_measurement", "_start", "_stop"])
|> yield()
计算车辆每天行驶里程(取每天最晚一条累计里程数据和最早一条累计里程数据,计算差值)
import "timezone"
option location = timezone.location(name:"Asia/Shanghai")
from(bucket: "iot")
|> range(start: v.timeRangeStart, stop: v.timeRangeStop)
|> filter(fn: (r) => r["_measurement"] == "device_metric" and r["deviceId"] == "10231858041" and r["_field"] == "mileage")
|> duplicate(column: "_value", as: "diff")
|> window(every: 1d)
|> spread(column: "diff")
|> filter(fn: (r) => not exists r.diff or r.diff != 0)
|> yield()
相关语法,就不过多做解释了,相信对照我前面的参考文档,就比较容易理解。
总结:
1、通过flux,我们发现,专业的时序数据库,针对时序数据的场景,提供了独特的查询功能,提升业务对时序数据处理的效率。
2、flux查询语言,不仅能查询influxdb,还能查询其他数据库。后面我计划了解下它的内核:一门新的数据查询数据,如何诞生的?如果我们要开发自己的查询语言,该如何开始?

 浙公网安备 33010602011771号
浙公网安备 33010602011771号