Flume日志采集无法写入HDFS
环境hadoop3.3.0,Flume1.9.0
任务背景:基于java程序生成测试数据,实时写入nginx文件,编写Flume任务进行数据采集,整个过程在单台虚拟机进行
结论:未加时间戳拦截器缺失导致动态路径解析失败
需防范的其他情况:空数据未过滤导致写入校验失败
Flume采集配置文件WebLog.conf
初始配置如下
a1.sources = r1
a1.sinks = k1
a1.channels = c1
#指定当前任务类型
a1.sources.r1.type = exec
a1.sources.r1.command = tail -f /export/data/weblog/nginx.log
#指定sink写入类型
a1.sinks.k1.type = hdfs
#指定写入地址与文件名称
a1.sinks.k1.hdfs.path = /weblog/%y-%m-%d/%H-%M/
#指定文件名称前缀与文件类型
a1.sinks.k1.hdfs.filePrefix = itcast-
a1.sinks.k1.hdfs.fileType = DataStream
#指定文件名称中转义符对应日期是否根据虚拟机时间
a1.sinks.k1.hdfs.useLocalTimeStamp = true
#指定channel类型,指定允许缓存数据的最大数量,指定一次事务写入的数量
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
执行Flume任务时报错
flume-ng agent --name a1 --conf conf/ --conf-file conf/WebLog.conf \ -Dflume.root.logger=INFO,console
这里会从环境变量查找可执行文件flume-ng的地址
等效于bin/flume-ng agent --name a1 --conf conf/ --conf-file conf/WebLog.conf -Dflume.root.logger=INFO,console
带有bin的弊端:这里的bin是指flume-ng文件的具体地址 仅限于在bin的父目录,执行,否则找不到该文件
错误情况
日志采集界面无写入hdfs日志响应
解决路程:
-
1修改flume的日志展示的级别 查看具体情况 -- 无效 结果就是debug日志也看不出来
全局修改:
vi conf/log4j.properties
![image]()
当前命令修改:
-Dflume.root.logger=DEBUG,console
此参数临时指定当前命令的日志输出级别 和 输出地点 本应输出到日志文件的日志被控制台拦截 好处是无效tail -200 /上图展示的日志文件地址 坏处当前窗口被占用 -
2猜测无法定位到日志文件 a1.sources.r1.command = tail -f /export/data/weblog/nginx.log --无关 很明显这个命令没有问题
tail -f 是实时侦测文件变化的命令 他不会侦测该文件之前的内容 且 通过文件描述符(FD) 定位文件
其他
tail -F 相较于前者 不同之处:通过文件路径名称定位文件 ,会重新尝试找到同名文件 -
3猜测无找到hdfs的文件路径 a1.sinks.k1.type = hdfs 模式正确 a1.sinks.k1.hdfs.path = /weblog/%y-%m-%d/%H-%M/ --无关
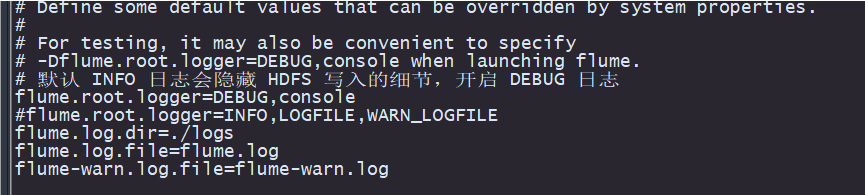
a1.sinks.k1.hdfs.path = /weblog/%y-%m-%d/%H-%M/
当前未指定hdfs的地址 会读取 当前环境变量下的Hadoop的 core-site.xml 里的 fs.defaultFS的值 即hdfs://hadoop1:9000,这样配置的兼容性更好
因为不是死地址,也兼容HA下的hadoop( fs.defaultFS的值未hdfs://ns1)(这个HA无端口哈)
等效于
a1.sinks.k1.hdfs.path = hdfs://hadoop1:9000/weblog/%y-%m-%d/%H-%M/
-
4猜测日期参数不合标准/%y-%m-%d/%H-%M/导致无法生成对应文件 --无关 很明显对照下表
转义字符 描述
%{host} 获取headers中键为host的值,host为用户自定义
%t 以毫秒为单位的Unix时间
%a 根据获取的时间生成简短工作日名称,如Mon、Tue等
%A 根据获取的时间生成完整工作日名称,如Monday、Tuesday等
%b 根据获取的时间生成简短的月份,如Jan、Feb等
%B 根据获取的时间生成完整的月份,如January、February等
%c 根据获取的时间生成日期和时间,如Thu Mar 3 23:05:25 2005
%d 根据获取的时间计算所属当前月份的第几天,如第一天为01
%e 根据获取的时间计算所属当前月份的第几天,如第一天为1
%D 根据获取的时间生成日期,其格式与%m/%d/%y相同
%H 根据获取的时间生成小时,即24小时制
%I 根据获取的时间生成小时,即12小时制
%j 根据获取的时间计算所属当前年份的第几天
%k 根据获取的时间生成小时,没有0填充,即24小时制
%m 根据获取的时间生成月份
%n 根据获取的时间生成月份,没有0填充
%M 根据获取的时间生成分钟
%p 根据获取的时间生成am(上午)或pm(下午)
%s 根据获取的时间计算自1970-01-01 00:00:00以来的秒数
%S 根据获取的时间生成秒
%y 根据获取的时间生成当前年份的后两位
%Y 根据获取的时间生成年份 -
5猜测日志积累数量未达到执行写入hdfs的标准 设置兜底参数,尝试强制写入 -- 无效 后续正面与此无关
# 批量5条
a1.sinks.k1.hdfs.batchSize = 5
# 10秒强制滚动
a1.sinks.k1.hdfs.rollInterval = 10
# 关闭按条数滚动(仅按时间)
a1.sinks.k1.hdfs.rollCount = 0
# 5秒空闲强制写入(关键)
a1.sinks.k1.hdfs.idleTimeout = 5
# 关闭时间轮询(避免延迟)
a1.sinks.k1.hdfs.round = false
效果不大,转变策略
但是通过强制写入报的日志(应该是)可以看出 source channel sink流程无错误
这里有些许猜测--
版本不兼容导致--无关 之前有过成功案例 且guava包已经替换
唯一的可疑点是
非单机模式采集写入(之前成功案例) 说是采用的avro协议写入hdfs 与hdfs版本无关
当前单机模式 由于flume的起源是hdfs的模块 单机模式采用的是flume对应hdfs的api 可以直接写入hdfs
-- 验证方法
1升级flume版本 2使用非单机模式写入hdfs 即仿照之前的案例重写当前任务 --后续证明并非协议问题
一边下新版本安装包(下的太慢了),一边更改架构
双向执行
根据之前的成功案例仿写flume日志采集(成功案例为非单机模式,即日志采集和写入不发生在同一个虚拟机)
成功案例:
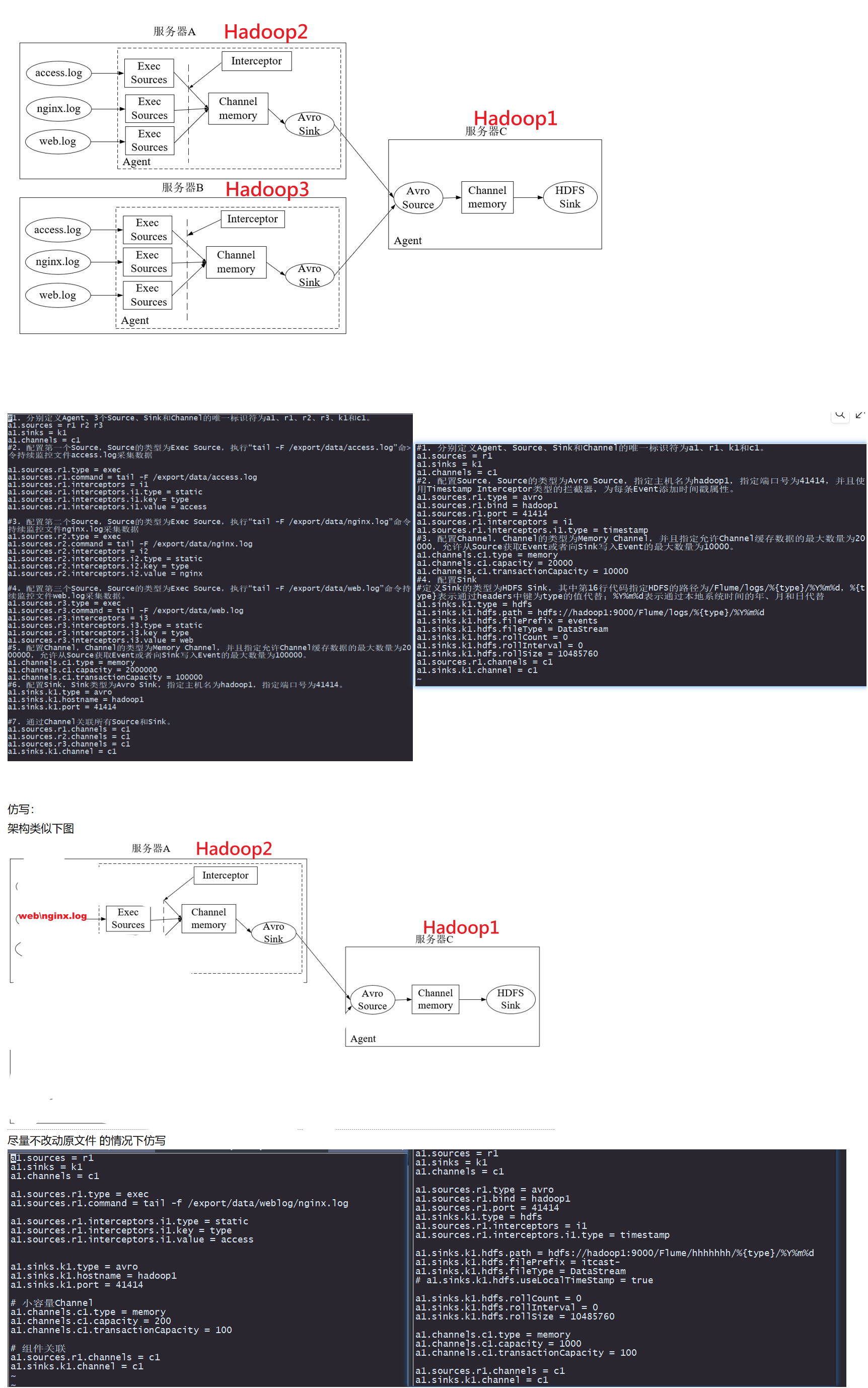
先启动 写入端
bin/flume-ng agent --name a1 --conf conf/ --conf-file conf/flume-avro-hdfs.conf -Dflume.root.logger=DEBUG,console > flume-hdfs.log
使用类似的写入数据命令
while true; do echo "164.164.54.67 [26/Aug/2022:11:12:58 +0800] \"GET /article/113.html HTTP/1.1\" 500" >> /export/data/weblog/nginx.log;done
启动采集端
bin/flume-ng agent --name a1 --conf conf/ --conf-file conf/flume-exec-avro.conf -Dflume.root.logger=INFO,console
结果也是成功写入了
可是真的是架构文件题吗?
根据单架构双架构逐项对照 让双架构文件配置趋向于单架构
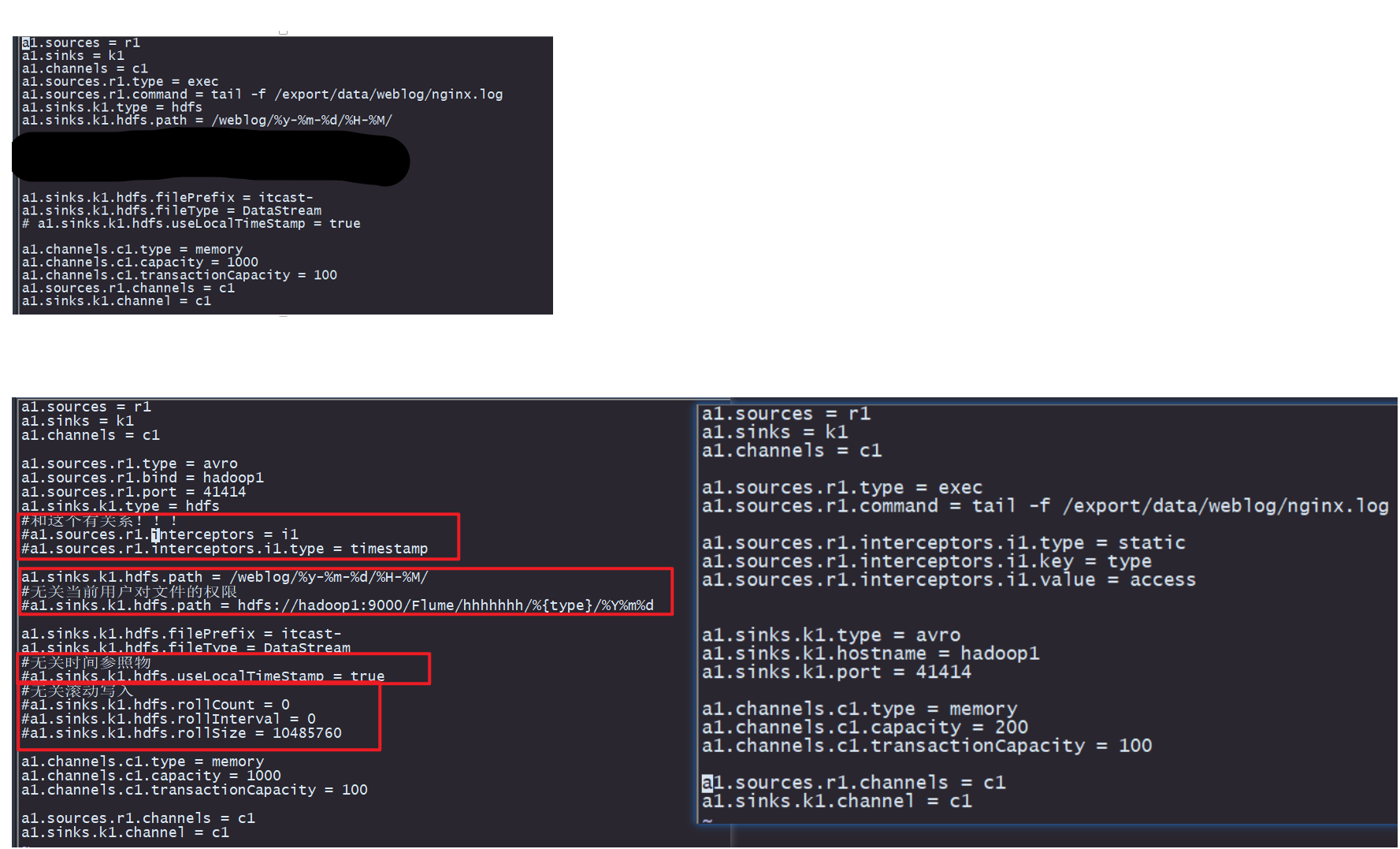
控制变量法逐个对比运行
bin/flume-ng agent --name a1 --conf conf/ --conf-file conf/flume-avro-hdfs.conf -Dflume.root.logger=DEBUG,console > flume-hdfs.log
while true; do echo "164.164.54.67 [26/Aug/2022:11:12:58 +0800] \"GET /article/113.html HTTP/1.1\" 500" >> /export/data/weblog/nginx.log;done
bin/flume-ng agent --name a1 --conf conf/ --conf-file conf/flume-exec-avro.conf -Dflume.root.logger=INFO,console
经查 和拦截器有关系
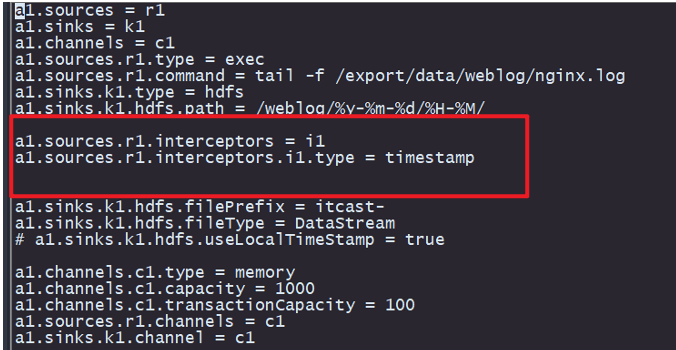
加上这两行也是成功写入了


 浙公网安备 33010602011771号
浙公网安备 33010602011771号