

腾讯用户冷启动召回论文《Cold & Warm Net: Addressing Cold-Start Users in Recommender Systems》
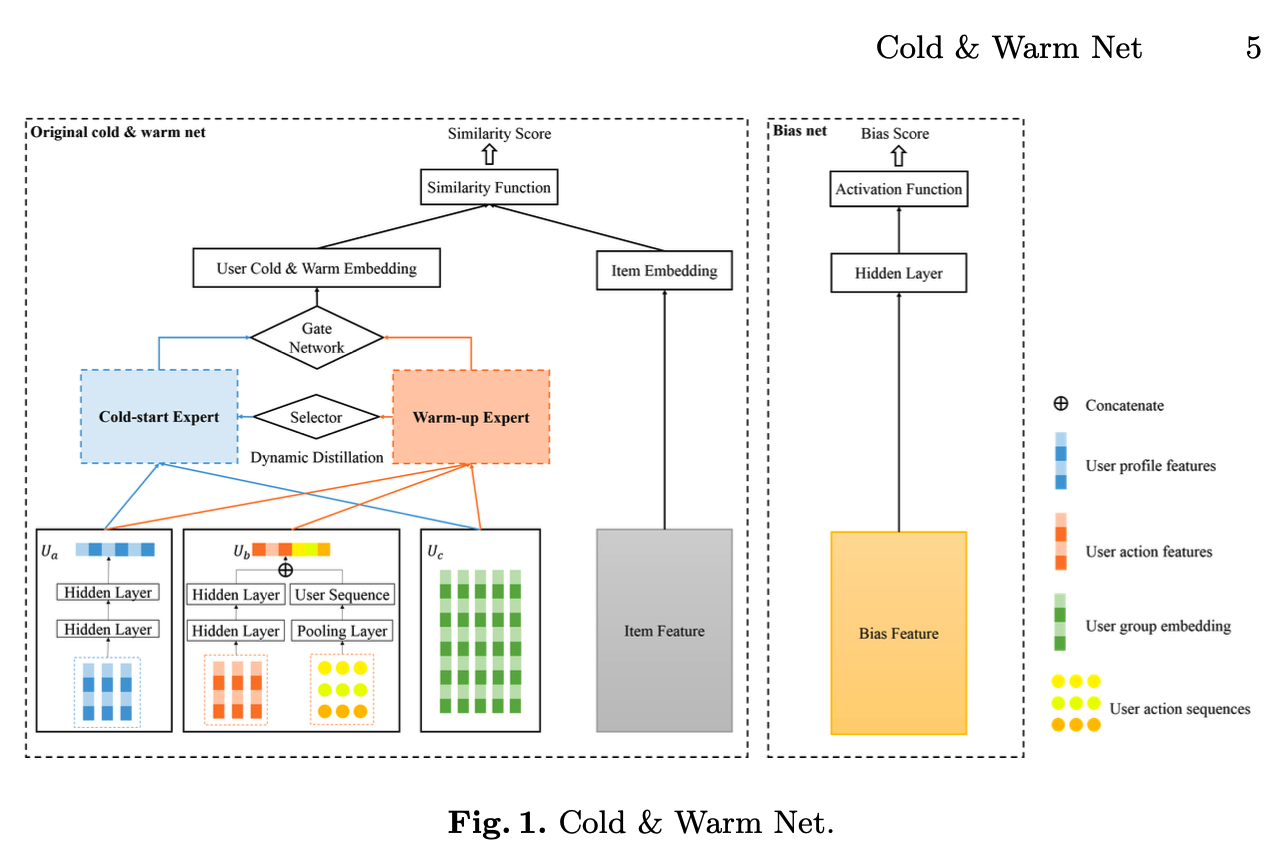
模型结构如上图所示,左边是一个标准的双塔结构,论文中称为original cold & warm net,右边是个bias net
original cold & warm net
original cold & warm net 由左侧 user tower 和右侧的 item tower组成,item tower 就是输入 item features 得到 item embedding,重点关注 user tower部分
user tower输入特征包含3类:
- 用户属性特征$\mathcal{X}_{up}$,对应用户属性 embedding $\boldsymbol{\vec{e}}_{up}$,经过隐藏层后得到输出$U_a$
- 用户行为特征$\mathcal{X}_{ua}$,对应用户行为 embedding $\boldsymbol{\vec{e}}_{ua}$,经过隐藏层后得到输出$U_b$
- 用户聚类 embedding $\boldsymbol{\vec{e}}_{ug}$ (先通过预训练模型得到活跃用户embedding,然后聚类,avg pooling后得到聚类embedding),经过隐藏层后得到输出$U_c$
输入$U_a, U_b, U_c$经过下图所示的 User cold & warm embedding layer ,该结构由冷热两个专家网络组成:
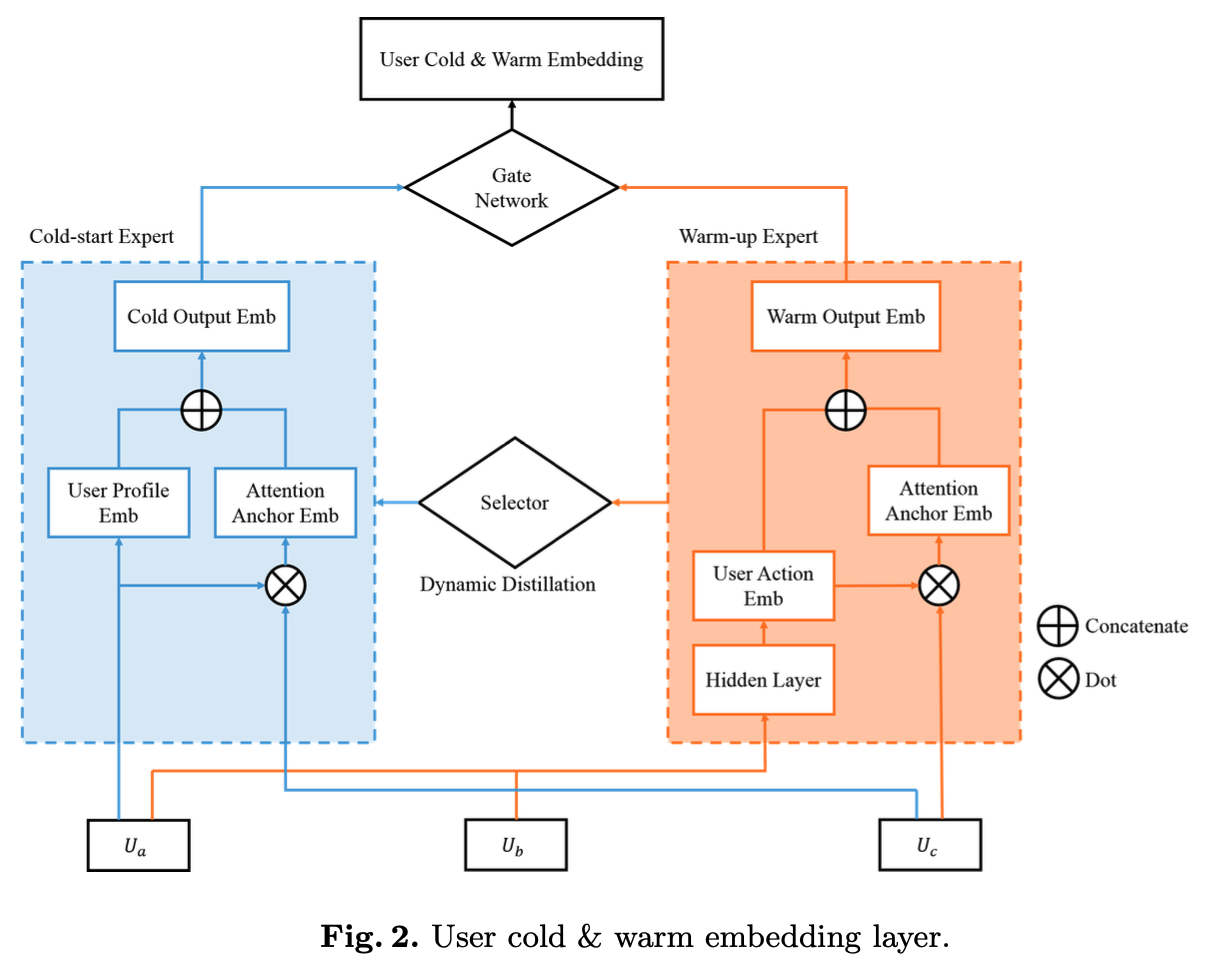
cold-start expert 只使用用户属性特征和用户聚类特征,首先使用attention结构以用户属性特征为query从聚类中心中检索相似聚类中心embedding:
$\boldsymbol{\vec{e}}_{cold}^a = \mathrm{softmax}\left( \frac{\boldsymbol{\vec{e}}_{up} E_{ug}^T}{\sqrt{d}} \right) E_{ug}$
$\boldsymbol{\vec{e}}_{cold} = \mathrm{mlp}(\boldsymbol{\vec{e}}_{up}; \boldsymbol{\vec{e}}_{cold}^a)$
warm-up expert 使用所有特征,以 $\mathcal{X}_{up}$ 和 $\mathcal{X}_{ua}$ 为输入,得到嵌入表示 $\boldsymbol{\vec{e}}_{ut} \in \mathbb{R}^{1 \times d}$ :
$\boldsymbol{\vec{e}}_{warm}^a = \mathrm{softmax}\left( \frac{\boldsymbol{\vec{e}}_{ut} E_{ug}^T}{\sqrt{d}} \right) E_{ug}$
$\boldsymbol{\vec{e}}_{warm} = \mathrm{mlp}(\boldsymbol{\vec{e}}_{ut}; \boldsymbol{\vec{e}}_{warm}^a)$
输入用户注册时间、活跃度等特征经过一个gate网络得到冷热双塔的权重:
$w_{\text{cold}}, w_{\text{warm}} = f_{\text{weight}}(\mathcal{X}_{\text{us}})$
bias net
为了解决冷启动用户建模时的行为偏差问题,我们引入一个额外的偏差网络。偏差网络之所以有效,是因为在实际推荐场景中,冷启动用户和活跃用户之间的行为偏差较大。例如,活跃用户的点击率比新用户高出数倍,因此需要借助偏差网络来描述这种偏差。我们的目标是找到一组与用户行为高度相关的用户特征 $\mathcal{X}_b$,并将其输入到偏差网络中,以得到偏差分数 $y_{\text{bias\_score}}$ 。为了挖掘行为偏差的关键特征,我们使用互信息来衡量用户特征与行为之间的相关性。我们选取相关性最高的前 $\beta$ 个特征作为偏差特征 $\mathcal{X}_b$ 。输出的偏差分数 $y_{\text{bias\_score}}$ 计算方式如下:
$y_{\text{bias\_score}} = f_{\text{bias}}(\mathcal{X}_b)$
个人理解偏差网络起到一个纠偏的作用但是不会最终的排序结果,最终的预估分为:
$y_{\text{sim\_score}} = \frac{\boldsymbol{\vec{e}}_u \cdot \boldsymbol{\vec{e}}_i}{\|\boldsymbol{\vec{e}}_u\| \|\boldsymbol{\vec{e}}_i\|}$
$y = \mathrm{sigmoid}(y_{\text{sim\_score}} + y_{\text{bias\_score}})$
Dynamic knowledge distillation
冷启动用户的数据比较少,可能会导致cold-start expert网络欠拟合,这里使用了warm-up expert来的预估分作为label蒸馏cold-start expert,具体来说就是如果warm-up expert输出结果和真实label算出的交叉熵loss大于warm-up expert输出结果和真实label算出的交叉熵loss,那么就会增加一个warm-up expert输出结果和warm-up expert输出结果的交叉熵loss(这个loss里应该需要对warm-up expert输出结果左stop gradient),具体做法如下所示(论文符合写错了,大于应该改为小于):

损失函数
$L = -\frac{1}{N} \sum_{i=1}^{N} \left( y_i \log \hat{y}_i + (1 - y_i) \log (1 - \hat{y}_i) \right)$
$L_d = -\frac{1}{N} \sum_{i=1}^{N} l_d$
$L_o = L + \alpha \cdot L_d$
实验
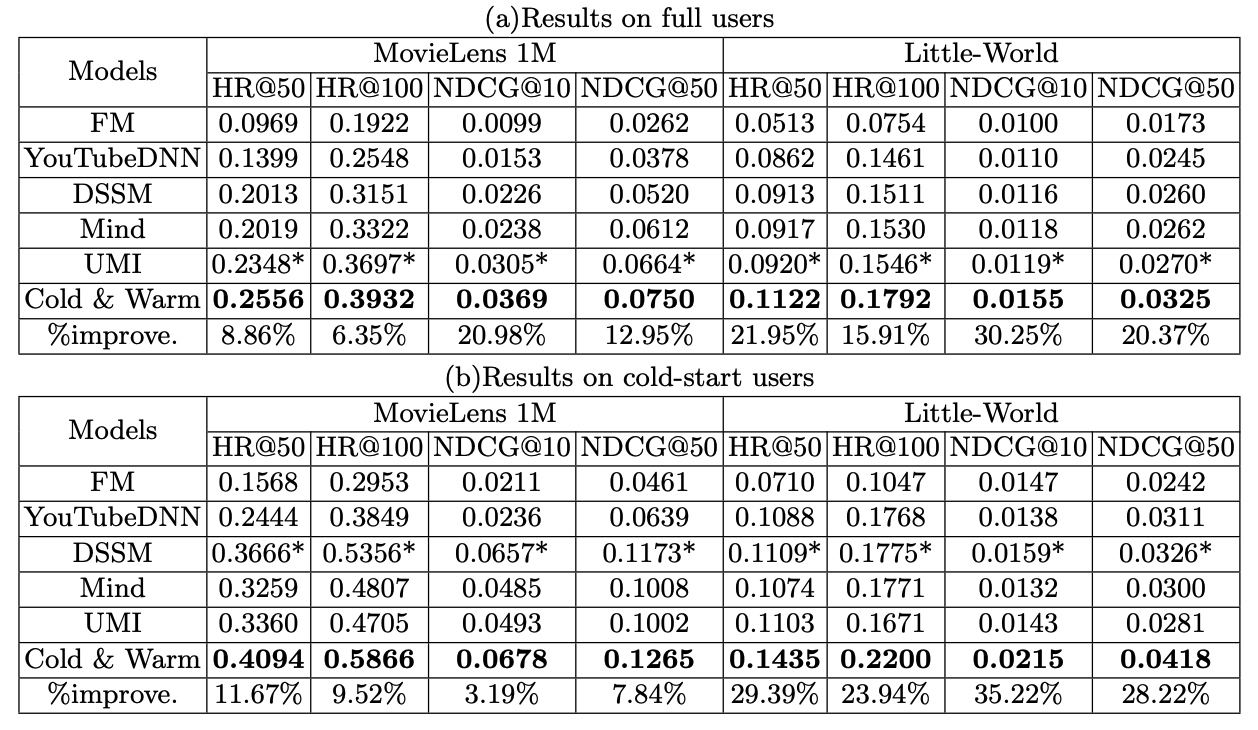
离线实验使用了Hit rate 和 NDCG作为评价指标:
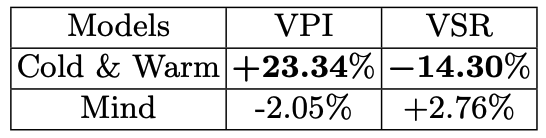
在线实验使用视频完播率和视频跳过率作为评价指标:
总结
- 为了弥补冷启动用户行为数据稀疏的问题使用了用户聚类特征,但是由于用户聚类也在是其它模型产出的,维护成本较高
- 采用了冷热双塔融合的方式来表示user embedding
- 使用热塔蒸馏冷塔,有助于冷塔的充分训练
参考资料

 浙公网安备 33010602011771号
浙公网安备 33010602011771号