

Meta生成式推荐论文《Actions Speak Louder than Words: Trillion-Parameter Sequential Transducers for Generative Recommendations》
背景
LLM在推荐系统中的应用存在以下几个挑战:
- 特征缺乏统一的结构描述: 推荐系统中的特征是异质的, 缺乏明确一致的结构描述, 比如交叉特征, 高基数id特征, 计数特征, 比率特征等, 这些特征有些是sparse的, 有些是dense的。
- 物料池规模大&动态变化: 推荐系统中物料池经常是数以亿计的, 且物料池动态变化, 不像NLP那样只有相对静态的几十万量级词汇量, 这使得推荐系统训练和推理的开销都很高。
- 计算成本高: 推荐系统每天需要处理的token比GPT-3在1-2个月内处理的token还要多上几个数量级。
为了解决上述问题, 实现推荐系统的scaling effect, 作者提出了生成式推荐(Generative Recommenders, 下文简称GRs), 将当前推荐系统异质的特征结构进行统一描述, 同时为了加速训练和减少推理开销, 提出了"分层序列直推单元"框架(Hierarchical Sequential Transduction Units, 下文简称HSTU)。
方法
统一的特征空间
现代推荐系统通常在海量稀疏类别型特征(sparse)和稠密型数值特征(dense)上训练。在GRs中,作者将这些特征统一编码进时间行为序列中,如下图所示:
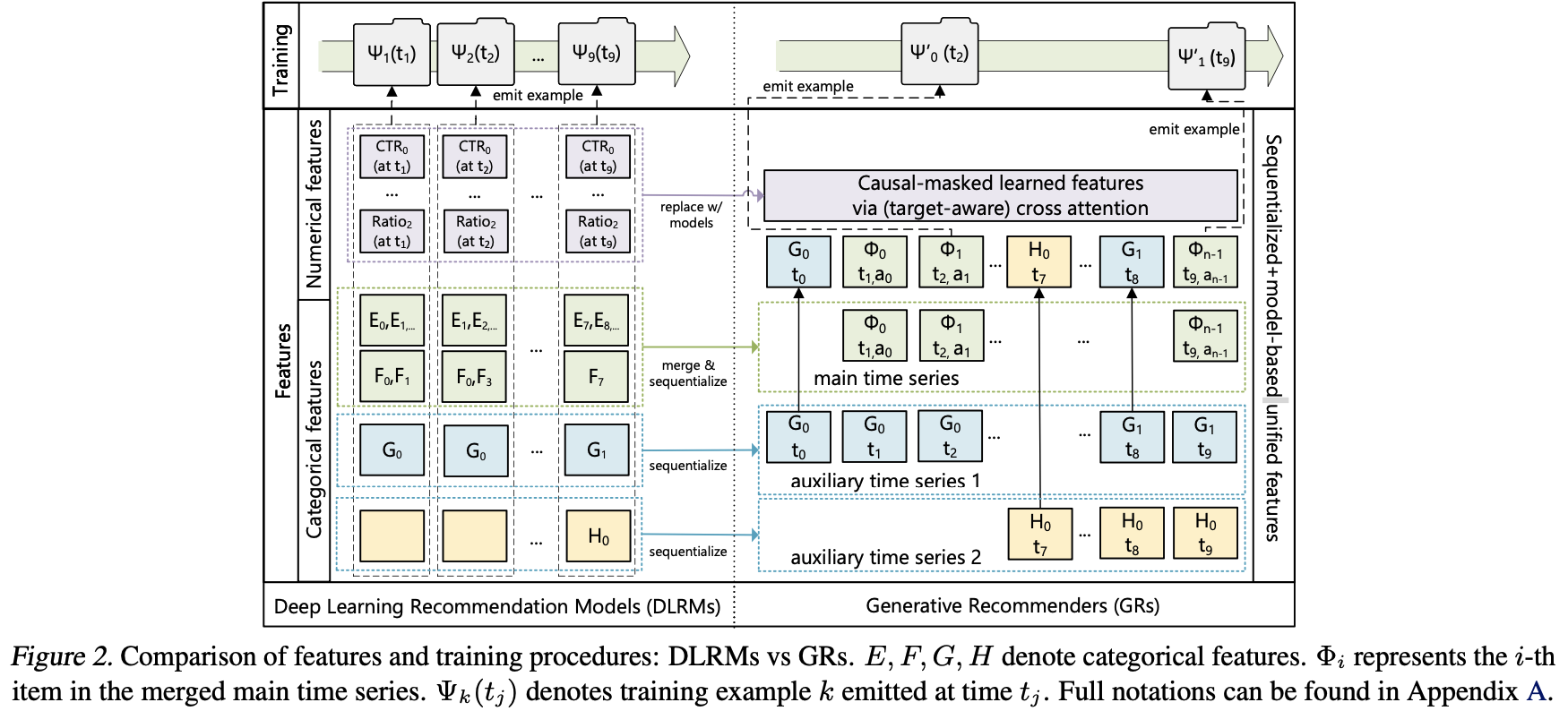
1. 选择时间跨度最长的序列作为主时间序列, 按时间顺序记录用户交互过的Item特征, 将它们合并进主时间序列中, 序列中的信息主要包含交互itemID、交互时间戳、交互的行为类型等(这些信息实际是如何处理的呢?embedding求sum pooling吗?)
2. sparse特征:压缩其它变化比较慢的稀疏特征特征,如人口统计信息,用户关注的作者等,在一段时间内只保留最早的特征值,合并进时间序列中。如上图中的两个辅助时间序列中的$G_0$、$H_0$和$G_1$,这些是偏静态的特征,一段时间内只插入一次到主序列中。
3. dense特征:dense特征变化比较快(如ctr、cvr),不好加到序列中,且作者认为这部分信息是可以被模型从序列中学到的,因此不用加到序列中
重塑召回与排序

-
$\mathbb{X}$: 动态更新的物料池(全集)
-
$\mathbb{X}_c$: 用户历史交互的物料
-
$x_0, x_1, \ldots, x_{n - 1}$: 输入的tokens
-
$y_0, y_1, \ldots, y_{n - 1}$: 输出的tokens,$y_i \in \mathbb{X} \cup \{\varnothing\}$, 当$y_i = \varnothing$时表示$y_i$的值是undefined的(因此这个位置的输入不是一个item,而是一个action或特征)
-
$a_i$与$\Phi_i \in \mathbb{X}_c$ ($\mathbb{X}_c \subseteq \mathbb{X}$): 用户行为(如收藏,完播等), 以及行为所对应的内容(如视频,商品)
-
$t_0, t_1, \ldots, t_{n - 1}$: 行为所对应的时间点
-
$m_0, m_1, \ldots, m_{n - 1}$: 掩码序列, $m \in \{0, 1\}$, 当$m_i = 0$时表示$y_i$的值是undefined的。
召回
召回任务学习一个概率分布$p(x_{i + 1} \mid u_i)$,其中$u_i$为第$i$个时刻所对应的用户表征,学习目标可以为: $\arg\ max_{x \in \mathbb{X}_c}p(x \mid u_i)$
这种方式与标准自回归方法存在两个区别:
- 下一个token $x_{i + 1}$不一定是前面$x_i, y_i$的监督信号,因为用户可能对$x_{i + 1}$负反馈
- 当下一个token $x_{i + 1}$是像前面提到人口统计信息这样相对静态的特征时,这些特征会被压缩,并不是交互的Item,即$x_{i + 1} \notin \mathbb{X}_c$,这时$y_i$是undefined 对于前面的两种情况,会将对应的掩码$m_i$设置为0,其它情况则是按自回归方式处理。
召回的候选是全量item吗?如果把item看作LLM中的token,那么推荐系统中token是几亿甚至几十亿量级的,且不断有新的token生成,token集合是不断变化的,LLM中next token训练方式如何在推荐系统中进行?知乎有博主推测是用双塔建模的
排序
在推荐系统(GRs)中的rank任务带来了独特的挑战,因为工业推荐系统通常需要一种 “target-aware” 建模。在这种情况下,目标 $\Phi_{i + 1}$ 与历史特征的 “交互” 需要尽早发生,而在标准的自回归设置中这是不可行的,因为在标准自回归设置中 “交互” 发生得较晚(例如,在编码器输出后通过softmax)。我们通过在交错item和action来解决这个问题(如上表所示),这使得rank任务可以被表述为 $p(a_{i + 1}|\Phi_0, a_0, \Phi_1, a_1,..., \Phi_{i + 1})$(在类别特征之前)。在实践中,我们应用一个小型神经网络将 $\Phi_{i + 1}$ 处的输出转换为多任务预测。重要的是,这使我们能够一次性将“target-aware”交叉注意力应用于所有 $n_c$ 次参与。
HSTU:新Encoder架构
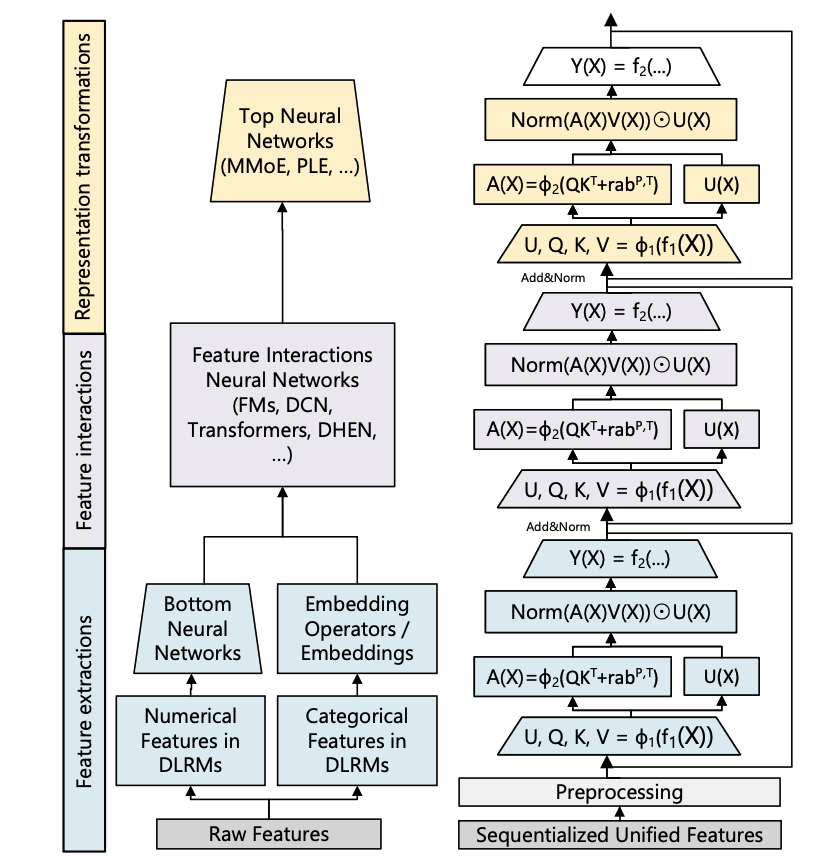
如上图所示,左边是DLRM模型结构,右边是论文提出的HSTU结构,类似Transformers,HSTU堆叠多个层,每个层包含三个主要的子层:
poinwise投影层
\[ U(X), V(X), Q(X), K(X) = Split(\phi_1(f_1(X))) \]
$f_1(x)$是单层MLP,$\phi_i$是激活函数,采用SiLU,对输入序列做了个非线性变换,其实就是在传统Q, K, V基础上,多了一个$U(X)$
pointwise空间聚合层
\[ A(X)V(X) = \phi_2(Q(X)K(X) + \text{rab}^{p,t})V(X) \]
整体类似传统的QKV self-attention, $\text{rab}^{p,t}$是attention bias,引入了位置$p$和时间$t$信息,执行attention操作。
这里采用了DIN类似的方式,没有对权重做softmax归一化,好处是可以保留原始的兴趣强度
pointwise转换层
\[ Y(X) = f_2(\text{Norm}(A(X)V(X)) \odot U(X)) \]
$f_2$是单层MLP,这里相当于和原始特征序列做了特征交叉,提高了模型的表达能力
线上服务优化
召回
用next predict位置的embedding作为user emb 和 item embedding 做ANN检索
排序
为了降低超长序列的重复运算,候选的结果会拆成多个batch放入序列,只是它会断掉候选之间的attention。
参考资料
行动胜过言语: Meta落地工业界首个万亿级别参数的生成式推荐系统模型
ICML'24 | Meta GRs : 万亿参数级别的生成式推荐

 浙公网安备 33010602011771号
浙公网安备 33010602011771号