

google LTV预估论文《A Deep Probabilistic Model for Customer Lifetime Value Prediction》
问题
给定用户特征,预估未来n天的付费概率、付费金额
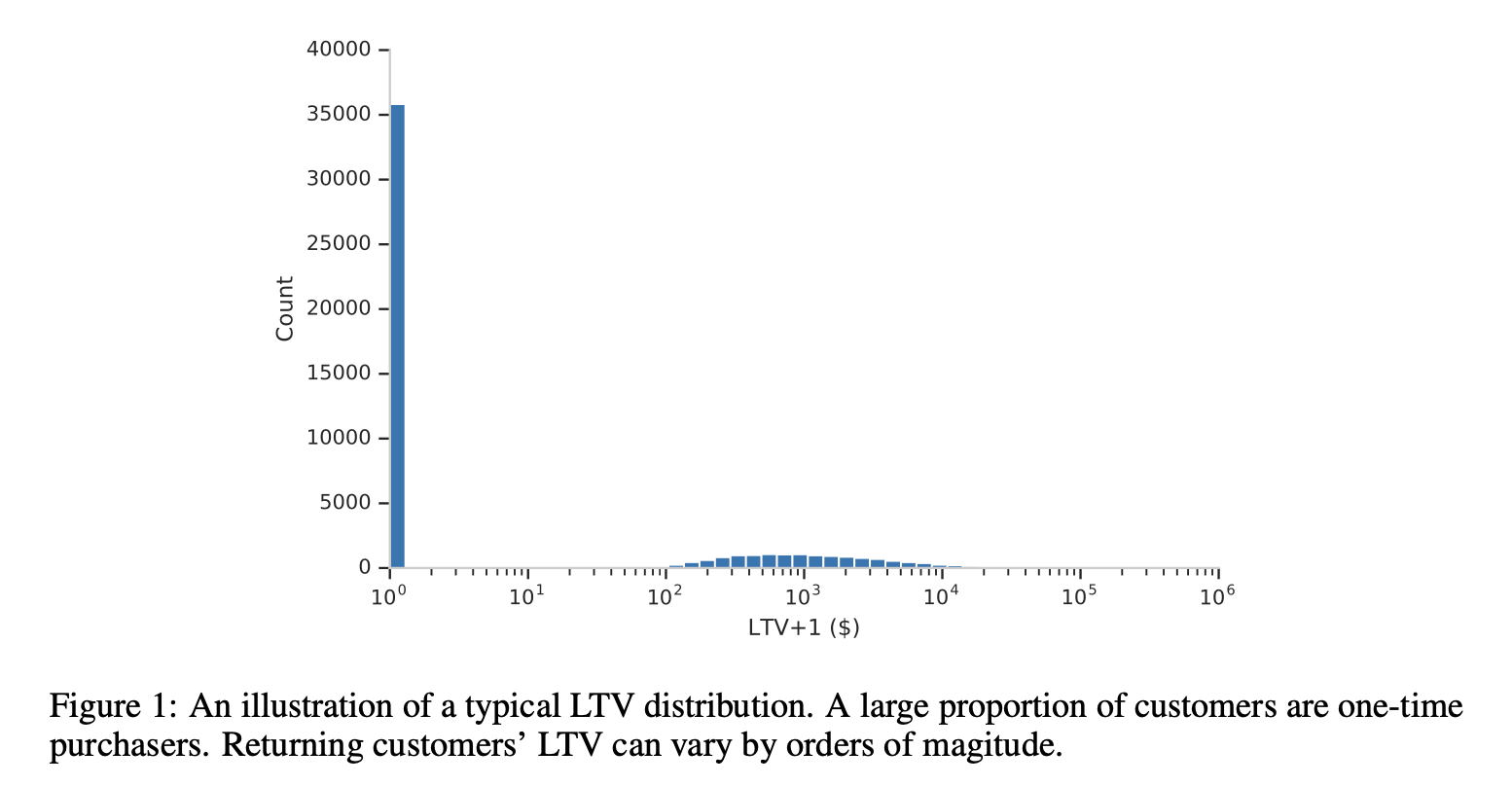
数据分布
- 长尾分布:90% 用户不付费,10% 用户付费
- 付费金额的范围非常广
建模方案
1. 直接用MSE建模LTV
缺点:由于用户LTR分布是0值和连续值的混合,而MSE假设label服从正态分布,容易被0值主导,模型倾向于预估一个接近0的值
2. 两阶段建模,先用BCE建模付费概率,然后用MSE建模付费金额,排除LTV为0的样本的影响
\[ pred\_ltv(x) = pay\_prob(x) \cdot pay\_amount(x) \]
缺点:需要两个模型,复杂度高,MSE对异常值太敏感,容易训崩
3. ZILN混合损失
本文提出了ZILN混合损失来同时建模用户是否付费以及付费金额:
\[ L_{\text{ZILN}}(x;p, \mu, \sigma) = L_{\text{CrossEntropy}}(\mathbb{1}_{\{x > 0\}};p) + \mathbb{1}_{\{x > 0\}}L_{\text{Lognormal}}(x;\mu, \sigma) \]
- 第一项用交叉熵来建模用户是否付费
- 第二项用对数正态分布建模LTV(假设了用户在已知付费的前提下付费金额服从对数正态分布),其中 x 为label,均值 μ 和方差 σ 为模型的输出值,线上infer时预估输出为学到的分布的期望 \(exp(\mu + \sigma^{2}/2)\)(是否需要乘以付费概率?):\[ L_{\text{Lognormal}}(x;\mu, \sigma) = \log(x\sigma\sqrt{2\pi}) + \frac{(\log x - \mu)^2}{2\sigma^2} \]
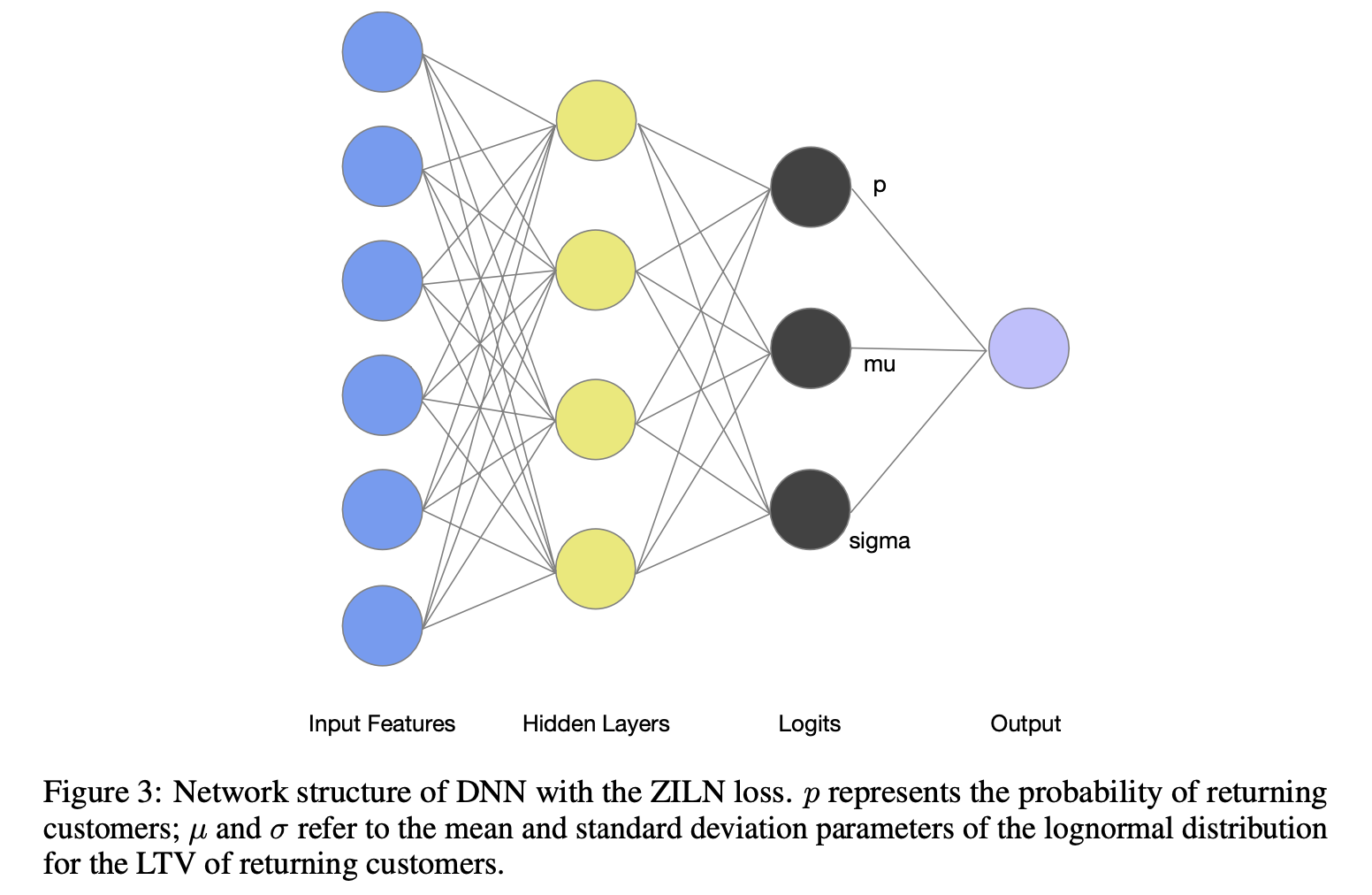
模型结构
模型结构入下图所示,DNN的最后一层保护3个输出,分别表示付费概率、均值 μ 和方差 σ(分别使用sigmoid、identity、softplus激活函数)
模型校准
按预测值从小到大排序,然后分桶校准:
\[ \text{MAPE} = \sum_{i = 1}^{10} \frac{|\hat{y}_i - y_i|}{y_i} \]
评价指标
使用AUC评估分类模型,使用基尼系数(对于任何二分类问题,基尼系数等于 2 倍的 AUC 减去 1)评估回归模型
基尼系数
核心定义与取值范围
论文中基尼系数计算方式:
用模型预估LTV计算出来的是模型基尼系数,用真实LTV label计算出来的是标签基尼系数,用模型基尼系数除以标签基尼系数可以得到归一化基尼系数
参考资料
https://zhuanlan.zhihu.com/p/250851222
https://zhuanlan.zhihu.com/p/553595964

 浙公网安备 33010602011771号
浙公网安备 33010602011771号