

LLM4Rec:快手召回KuaiFormer
背景
本文提出了KuaiFormer,号称从根本上重新定义了检索过程,从传统的分数估计任务(例如点击率估计)转变为 Transformer 驱动的next action预测范式,可以更有效地实时获取兴趣和提取多兴趣,从而显着提高检索性能
方法
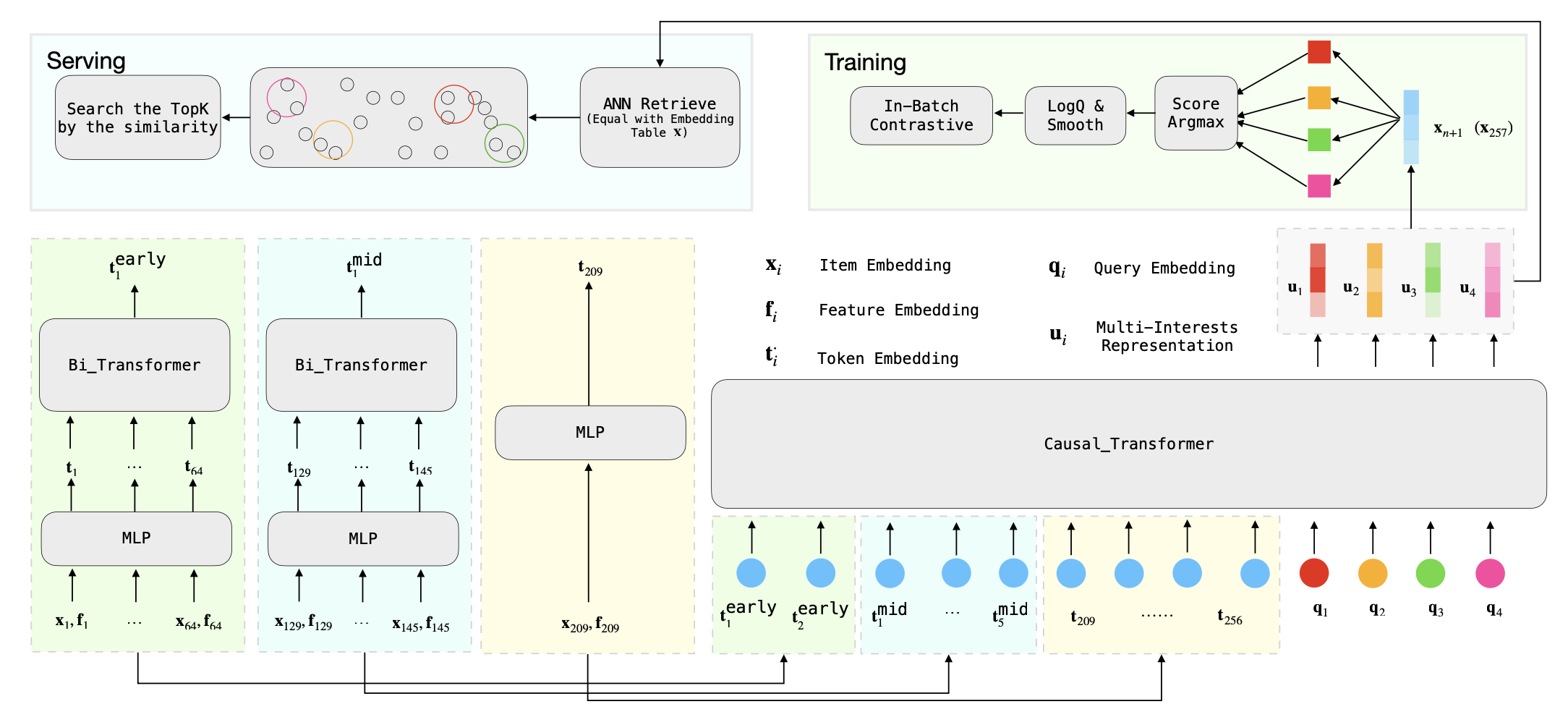
模型结构如上所示,就是输入用户前n个行为序列,采用transform结构预估下一个n+1时刻行为
序列压缩
建模的用户行为序列越长,效果一般会越好,但是transform的时间复杂度是O(n2),随着序列长度增加,复杂度以平方级上涨。直观感受上最近的行为序列影响最大,无法精简,但是很久以前的行为序列影响较小,可以做压缩节省计算量。因此作者将用户历史行为序列, 按交互时间顺序分成了早中晚三部分,对于早和中序列,分别按64和16一组过taransform后求mean聚合为一个embedding

多兴趣
借鉴Bert中使用[CLS]特殊token将其对应的输出向量作为整篇文本的语义表示的思想, 作者这里使用了多个特殊的token{q1, . . . , q𝑘 } 作为用户的个兴趣query token, 将这个token对应位置的输出{u1, . . . , u𝑘 } 作为用户的多兴趣表示

在得到用户的多维兴趣表示{u1, . . . , u𝑘 }后, 就可以预估Next Item:
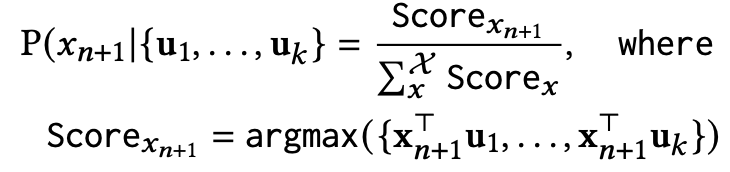
这里把每个兴趣emb和item embedding计算相似度 (论文里没看到怎么得到这个item embedding,可能就是输入序列的embedding) ,并把最大的相似度作为预估分
Softmax加速训练
为了加速训练,采用了inbatch softmax采样 + 纠偏的方法
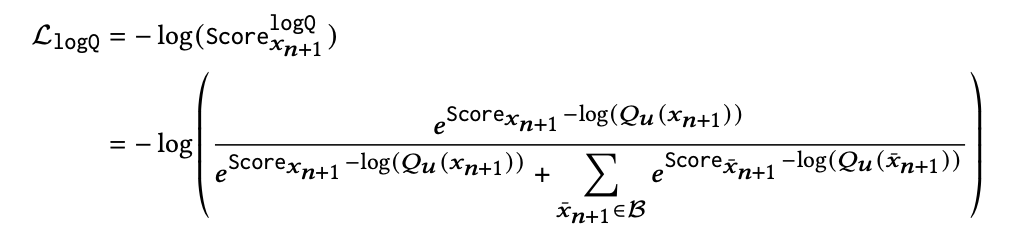
Smooth稳定训练
在短视频推荐中,用户往往对观看各种内容有更高的容忍度,这使得将下一个Item分类为明确的“积极”或“消极”比较困难。因此,作者引入标签平滑方法, 避免使用严格的0-1标签进行模型训练

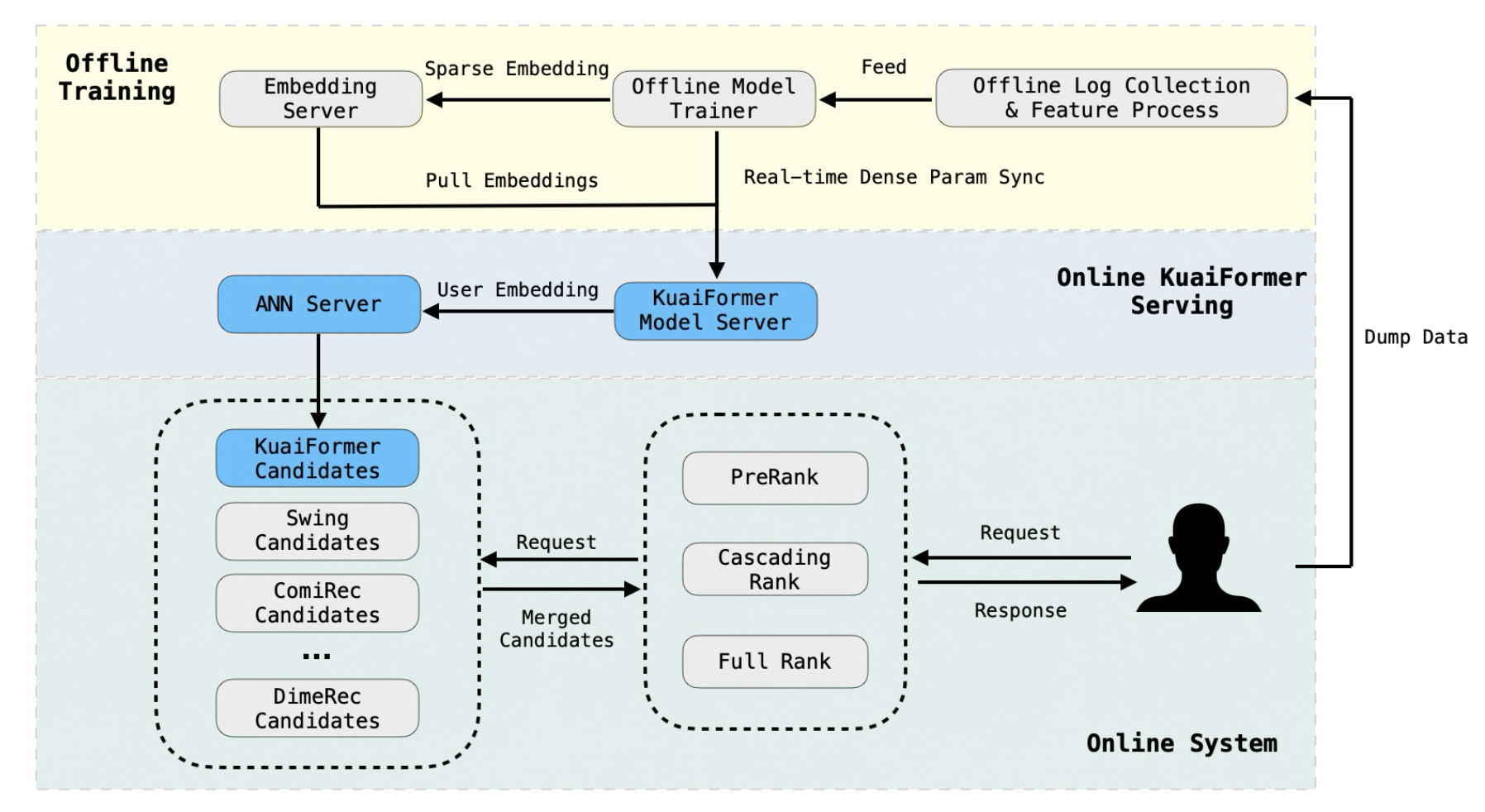
在线检索
参考资料
论文链接:https://arxiv.org/abs/2411.10057
快手KuaiFormer:基于Transformer架构的召回实践
「快手」召回新范式|KuaiFormer: Transformer-Based Retrieval at Kuaishou

 浙公网安备 33010602011771号
浙公网安备 33010602011771号