

LLM中的归一化方法和位置
LLM常见归一化方法
LayerNorm
在早期的研究中,批次归一化(Batch Normalization, BN)是一种广泛采用的归一化方法。然而,该方法难以处理可变长度的序列数据和小 批次数据。因此,相关研究提出了层归一化这一技术 ,针对数据进行逐层归一化。具体而言,层归一化会计算每一层中所有激活值的均值 𝝁 和方差 𝝈,从而重新调整激活值的中心和缩放比例
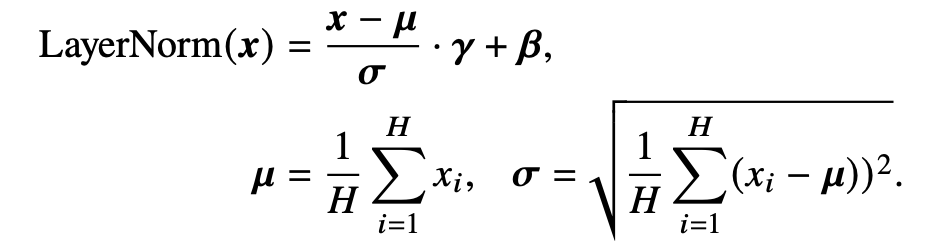
RMSNorm
为了提高层归一化的训练速度,RMSNorm 仅利用激活值总和的均方根RMS(𝒙) 对激活值进行重新缩放,对于layerNorm和RMSNorm,layerNorm包含缩放和平移两部分,RMSNorm去除了平移部分,只保留了缩放部分。有研究认为layerNorm取得成功的关键是缩放部分的缩放不变性,而不是平移部分的平移不变性
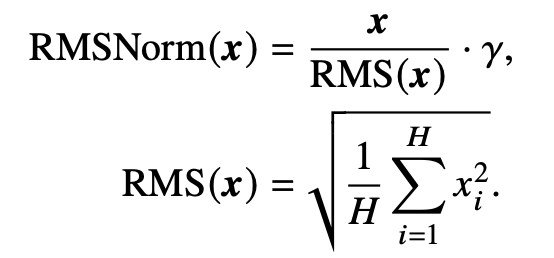
DeepNorm
DeepNorm 由微软的研究人员提出,旨在稳定深层 Transformer 的训练。具体而言,DeepNorm 在 LayerNorm 的基础上,在残差连接中对 之前的激活值 𝒙 按照一定比例 𝛼 进行放缩。通过这一简单的操作,Transformer 的层数可以被成功地扩展至 1,000 层 ,进而有效提升了模型性能与训练稳定性。
![]()
归一化层的位置
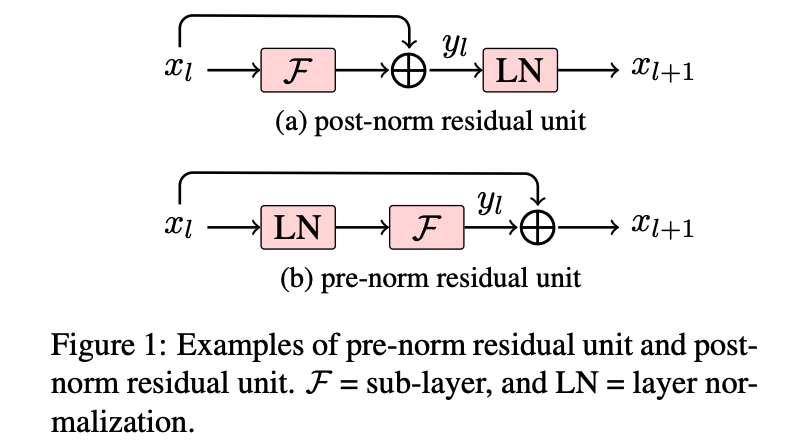
为了加强大语言模型训练过程的稳定性,除了归一化方法外,归一化模块的 位置也具有重要的影响。如图 5.2(a) 所示,归一化模块的位置通常有三种选择,分别是层后归一化(Post-Layer Normalization, Post-Norm)、层前归一化(Pre-Layer Normalization, Pre-Norm)和夹心归一化(Sandwich-Layer Normalization, Sandwich-Norm)
Post-Norm
归一化模块被放置于残差计算之后,模型训练稳定性不如Pre-Norm,但是最终效果优于Pre-Norm,苏剑林博客指出是因为Pre-Norm增加了模型宽度,Post-Norm增加了模型深度
![]()
Pre-Norm
![]()
参考资料
苏剑林. (Mar. 29, 2022). 《为什么Pre Norm的效果不如Post Norm? 》[Blog post]. Retrieved from https://kexue.fm/archives/9009
为什么大模型结构设计中往往使用postNorm而不用preNorm?

 浙公网安备 33010602011771号
浙公网安备 33010602011771号