

快手直播推荐论文《Moment&Cross: Next-Generation Real-Time Cross-Domain CTR Prediction for Live-Streaming Recommendation at Kuaishou》
背景
论文指出直播推荐场景存在两个挑战:
1. 每场直播的时长一般在几个小时左右,同场直播的不同时段用户点击率是不一样的,如何精准的去推荐高处于点击率时刻的直播?
2. 快手app中90%都是短视频,只有10%是直播,直播数据比较稀疏,如何利用用户在短视频场景的行为去更好的推荐直播?
捕捉直播间实时点击率
解决挑战1最直接的想法就是实时训练模型,但是直播场景中一些用户行为存在较长时间的延迟,如送礼行为可能需要用户观看半小时后才会发生。如果样本拼接窗口设的过短就会引入许多假负例,设的过长实时性有损。
快慢窗口结合
论文在第一版尝试了快慢窗口结合的方案:
1. 快窗口等待时间为5min,期间会报告观察到的所有正付样本,此时训练loss为正常的交叉熵损失:
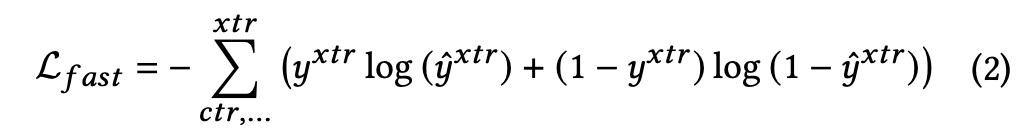
2. 慢窗口的等待时间为1h,只报告5min窗口之后的正样本,此的训练loss为(由于该正样本在5min窗口内被当作负样本训练了一次,训练减去原来作为负样本的loss):

30s实时数据流
快慢窗口的方法在一定程度上解决了上面提到的问题,但是由于在1h窗口正样本回流前,该样本在5min窗口内被当作负样本训练,此时会导致模型低估且仍不够实时,因此论文提出了第二种方案:
即每30s报告一次正例,负例等用户推出直播间后才报告,这样正反馈行为可以得到实时训练,可以捕捉直播高光时刻
但是这样做可能存在以下几个问题:
- 同一种正反馈被报告多次:如评论行为,用户可能评论多次,为了解决这个问题,论文里提到,对于同一种反馈,只用最早发生的那个正反馈行为训练模型
- 信息泄漏:浅层的正反馈行为会先进模型训练(如点击),深层的正反馈行为后进模型训练(如送礼),这样模型在训练送礼时已经获得了用户点击的这个信息,会不会造成高估呢?论文提到没有观察到这个现象,给的解释是模型是在拟合全体用户的分布,不容易在某个用户上过拟合(这个解释没怎么看懂)
- 样本数增多:等待固定窗口的方式是一条样本拼接所有label,但是这个方案因为不同正反馈行为报告时间不一样,所有会变成多条样本,论文提到样本数大概是快慢数据流方案的样本数的2倍
短视频transfer到直播
论文采用的方式就是把用户在短视频的行为作为序列特征,采用了GSU + ESU 两阶段的长序列建模方法:
(1)引入通用搜索单元(GSUs)来搜索用户历史,然后筛选出与目标直播候选人相关的项目序列;
(2)设计精确搜索单元(ESUs)来聚合序列信息以压缩用户兴趣,例如序列聚合、目标项目注意力。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号