

腾讯冷启动论文阅读《Enhancing User Interest based on Stream Clustering and Memory Networks in Large-Scale Recommender Systems》
背景
用户冷启动一直是推荐系统中的一个难题,新用户(或非活跃用户)由于缺少行为数据,模型预估不准确。为了改善用户冷启动,腾讯提出了User Interest Enhancement (UIE)模型(论文中提到也可以用于item的冷启动)。基本思想是先对用户聚类,然后用user embedding检索最相似的k个聚类中心来表示用户属性,其实就是用相似用户来补充冷启用户的兴趣表示。
模型结构
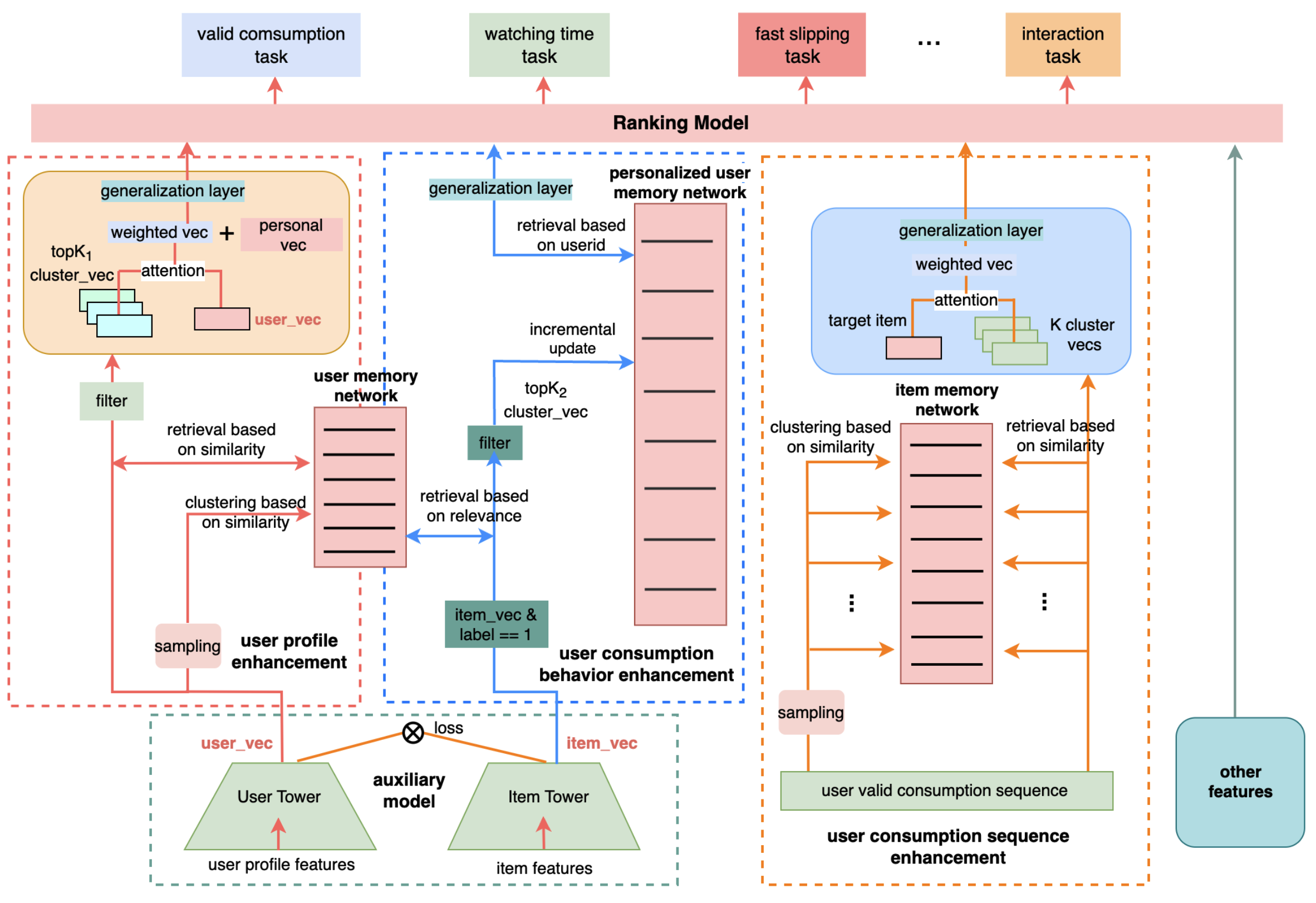
模型结构如上图所示,论文采用了PLE模型作为主模型框架,模型主要变化在于使用UIE结构生成了3个enhancement vector来加强用户的兴趣表示
UIE主要包含3个部分:
1. User Profile Enhancement (UPE)
2. User Consumption Behavior Enhancement (UCBE)
3. User Consumption Sequence Enhancement (UCSE)
User Profile Enhancement (UPE)
UPE的结构如上图最左部分所示:
1. 首先通过一个辅助tower得到user profile vector(辅助tower embedding和主模型共享,为了不影响主模型,辅助tower不回传梯度到embedding)
2. 更新聚类中心,训练之前,会对N个聚类中心进行随机初始化(每个聚类中心是一个d维的向量),用户会被划分到最近的聚类中心中,然后会按如下公式更新聚类中心:
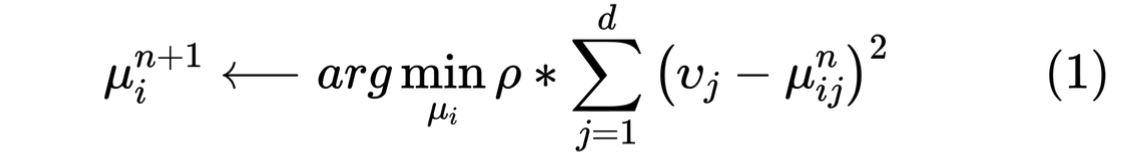
其中𝜌 是更新率,是个超参数,vj是第j维用户属性向量,uij是第i个聚类中心向量的第j维
这个公式论文描述有点模糊,没怎么看懂,猜测是可以把上面的公式看作均方误差的loss来更新聚类中心
论文还提到,为了加快计算速度以及平衡不同类型用户对聚类中心的影响(防止被活跃用户主导),会对不同类型的用户做均匀采样
3. 使用用户向量检索出最相似的k1个聚类中心,为了保证检索出来的聚类中心和用户向量是正相关的,会对相似度是负的聚类向量置0
4. 使用attention方法生成增强向量,然后拼接personal vector通过generalization layer生成最终的用户增强向量
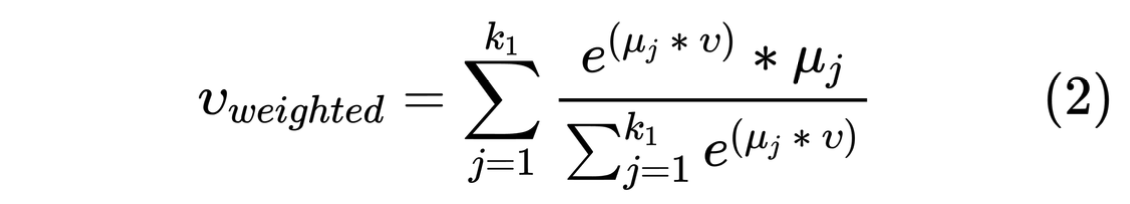


def upe(user_vec, trainable=False, N=256, topK1=3, alpha=0.01, dim=32): """ user_vec: 用户向量, [batch_size, dim] N: 聚类中心数目 topK1: 最相似聚类中心数目 alpha: upe loss权重 dim: 聚类中心向量维度 """ user_vec = tf.stop_gradient(user_vec) # 聚类中心 umn = tf.get_variable( "umn", shape=[N, dim], dtype=tf.float32, initializer=tf.uniform_unit_scaling_initializer(factor=math.sqrt(N / 3.0)), trainable=trainable) # 计算user_vec和聚类中心相似度 sim_metrix = tf.matmul(user_vec, tf.transpose(umn)) # 求最相似聚类中心 centroid_score, centroid_idx = tf.math.top_k(sim_metrix, k=1) centroid_vec = tf.gather_nd(umn, centroid_idx) # 计算upe loss upe_loss = alpha * tf.reduce_sum(tf.math.pow(user_vec - centroid_vec, 2), axis=-1, keepdims=True) # 计算最相似topK1聚类中心 centroid_score_infer, centroid_idx_infer = tf.math.top_k(sim_metrix, k=K1) centroid_infer = tf.gather_nd(umn, tf.expand_dims(centroid_idx_infer, axis=-1)) # mask score小于等于0的聚类中心,计算topK1聚类中心加权和 centroid_weight = tf.where( centroid_score_infer > 0, tf.math.exp(centroid_score_infer), tf.zeros_like(centroid_score_infer)) centroid_weight = tf.expand_dims(centroid_weight, axis=-1) upe_vec = tf.reduce_sum(centroid_weight * centroid_infer, axis=1) / (tf.reduce_sum(centroid_weight, axis=1) + 0.001) upe_vec = tf.stop_gradient(upe_vec) return upe_vec, upe_loss
User Consumption Behavior Enhancement (UCBE)
1. 通过辅助tower得到用户正反馈行为的item embedding
2. 使用item embedding检索最相似的k2个聚类中心向量
3. 增量更新personalized enhancement vectors,存储在personalized user memory network(实现时就是一个user embedding)
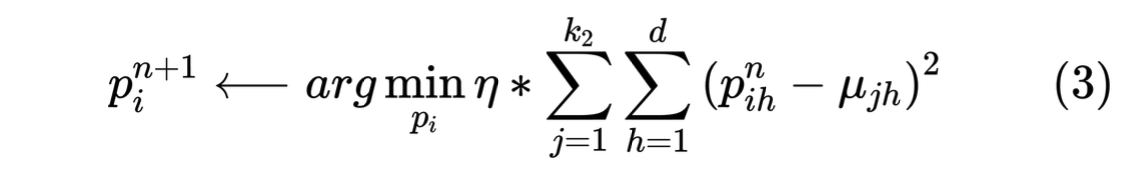
4. 使用user id检索出personalized enhancement vectors作为最终的增强向量
def ucbe(item_vec, pumn, label, trainable=False, N=128, K2=3, alpha=0.05, job_type="", print_log=True): item_vec = tf.stop_gradient(item_vec) umn = tf.get_variable( "umn", shape=[N, 32], dtype=tf.float32, initializer=tf.uniform_unit_scaling_initializer(factor=math.sqrt(N / 3.0)), trainable=trainable) sim_metrix = tf.matmul(item_vec, tf.transpose(umn)) centroid_score_infer, centroid_idx_infer = tf.math.top_k(sim_metrix, k=K2) centroid_infer = tf.gather_nd(umn, tf.expand_dims(centroid_idx_infer, -1)) centroid_weight = tf.where( centroid_score_infer > 0, tf.ones_like(centroid_score_infer), tf.zeros_like(centroid_score_infer)) centroid_weight = tf.expand_dims(centroid_weight, axis=-1) centroid_infer = centroid_infer * centroid_weight centroid_infer = tf.stop_gradient(centroid_infer) ucbe_loss = alpha * tf.expand_dims( tf.reduce_sum( tf.math.pow(tf.expand_dims(pumn, axis=1) - centroid_infer, 2), axis=[1, 2]), axis=-1) ucbe_loss = ucbe_loss * label return tf.stop_gradient(pumn), ucbe_loss
User Consumption Sequence Enhancement (UCSE)
1. 得到用户的行为序列(论文提到直接用的主模型训练的用户行为序列embedding)
2. 和UPE的计算方式类似,更新聚类中心
3. 使用target attention的方式得到最终的增强向量
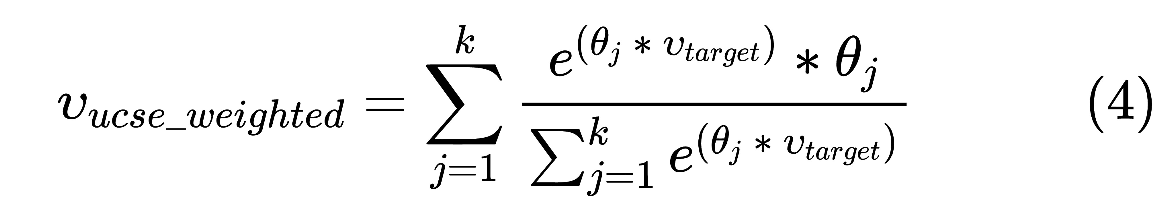
实践记录
1. 直接冷启动训练会出现收敛到少数几个聚类中心的现象,需要先训练好双塔,然后热启训练?
2. 可以尝试用softmax交叉熵loss代替mse loss

 浙公网安备 33010602011771号
浙公网安备 33010602011771号