

阿里超长序列建模ETA:《End-to-End User Behavior Retrieval in Click-Through Rate Prediction Model》
背景
这里是阿里继SIM之后提出的长序列建模方法,虽然SIM能够处理上万甚至几十万的序列长度,但是也面临几方面的问题:
- 目标不一致:GSU建立索引使用的item embedding不是SIM模型生成的,可能是预训练的,也有可能是直接拿item的类别建立的索引,比如是拿家电、女装、生鲜这样的类别
- 更新频率不一致:SIM两阶段的更新频率不一致。线上模型都是以online learning的方式频繁更新的,以捕捉用户实时的兴趣变化,但是SIM中所使用的索引都是离线建立好的,成为性能的短板
方法
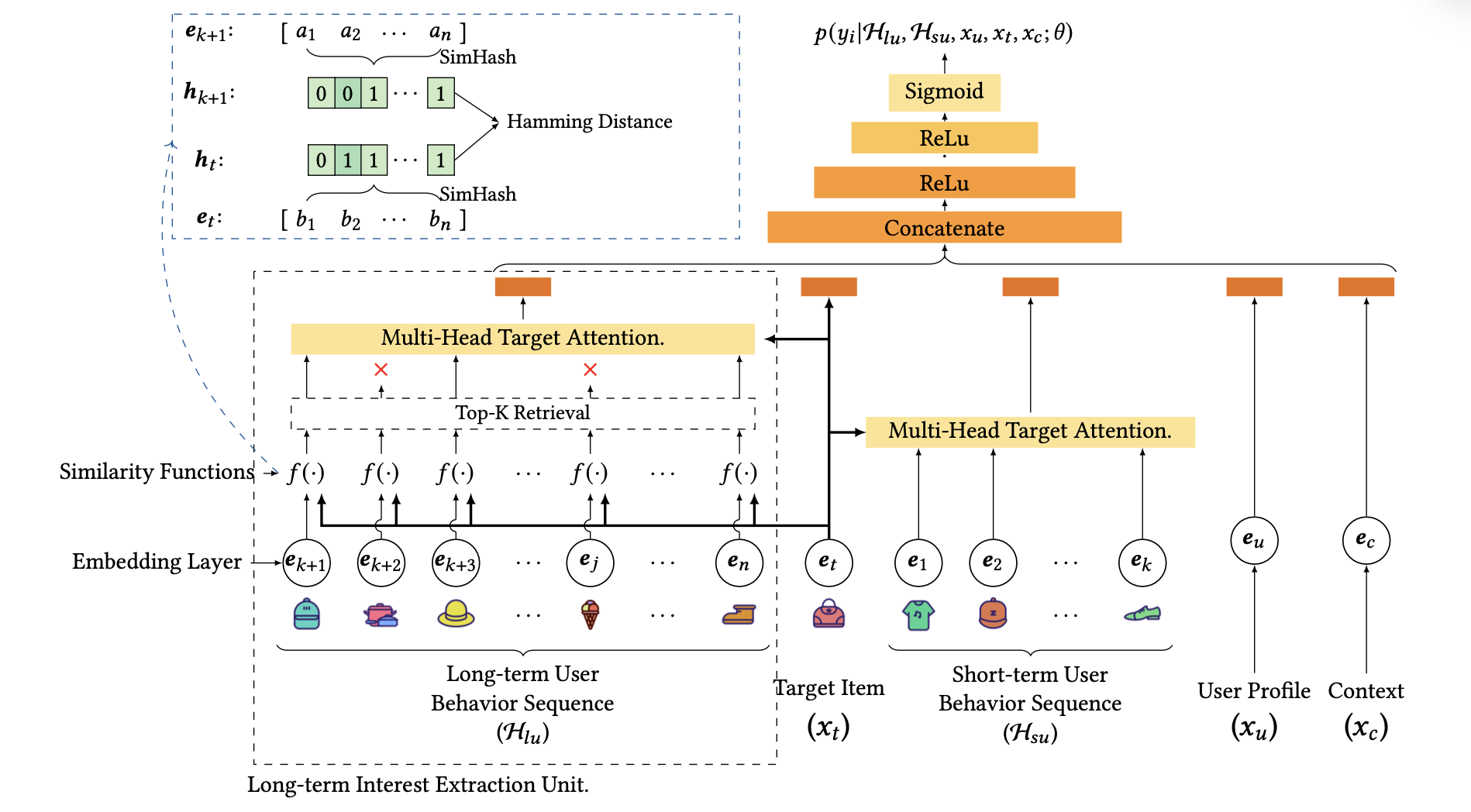
ETA的模型结构如上图所示,核心的就是左下的长序列建模的Top-K Retrieval部分,为了减少现实serving开销,会从序列中检索出最相似的top k过Multi-head Target Attention
如果检索过程中用内积计算相似度,时间复杂度是O(d),论文采用了SimHash这种O(1)的相似度计算方法
问题:离线训练阶段,如国用完整的长序列训练的,那资源开销应该难以承受,看论文训练过程应该也是用的检索出的top k结果训练的,这样是否会导致一个问题:在刚开始训练的时候,embedding还是随机初始化的状态,此时检索出的top k是不准的,是否会导致模型训偏
下面是SimHash算法计算流程:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号