

阿里序列建模论文:《BERT4Rec: Sequential Recommendation with Bidirectional Encoder Representations from Transformer》
背景
论文指出,SASRec 和 基于RNN的序列推荐模型存在以下几个限制:
- 只利用了单向的信息进行建模,单向结构限制了用户行为序列中隐藏表示的能力
- 假定存在一个严格有序的序列,但这并非总是可行的
为了解决这些局限性,论文提出了一种名为 BERT4Rec 的序列推荐模型,该模型采用深度双向自注意力机制对用户行为序列进行建模。为了避免信息泄露并有效训练双向模型,论文将Cloze目标应用于序列推荐
模型结构
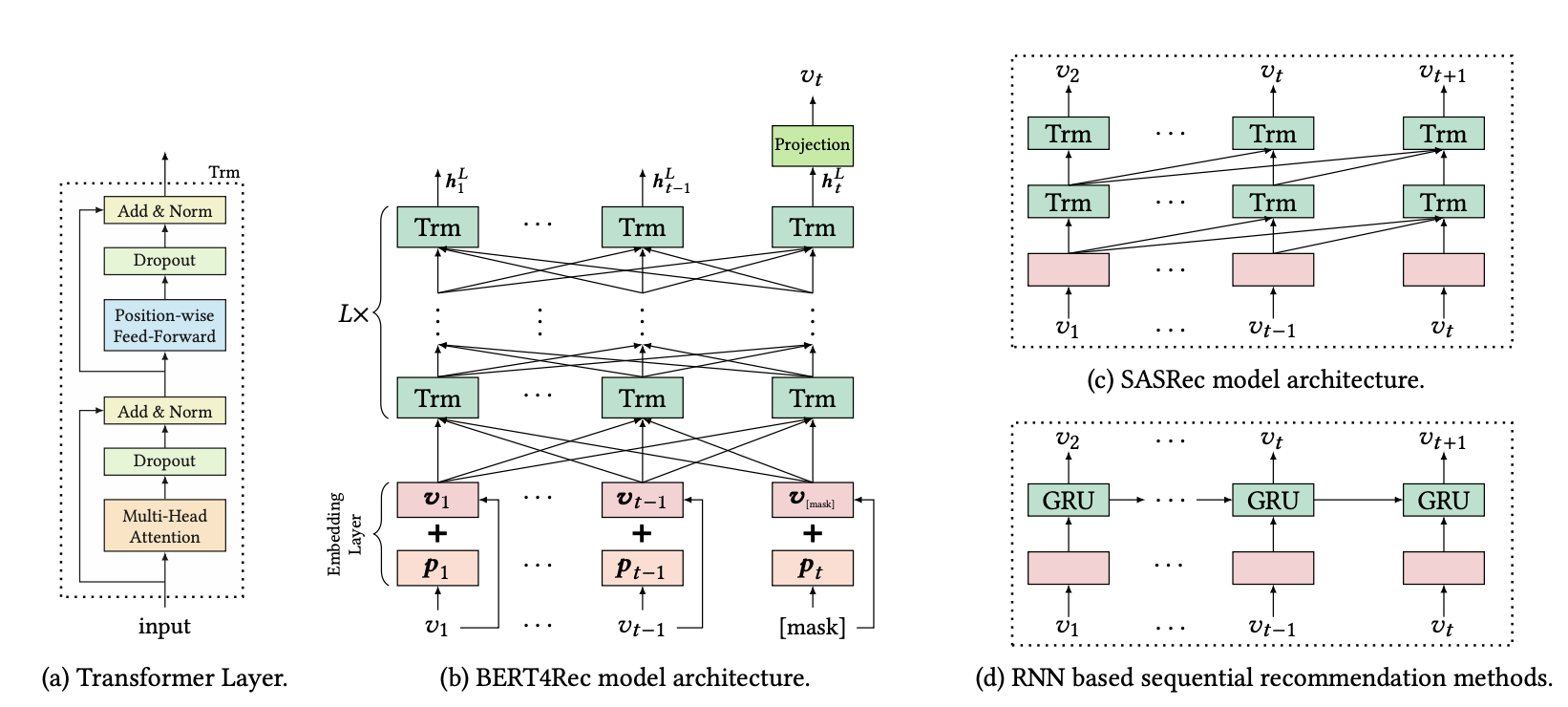
模型结构如上图(b)所示,就是一个BERT结构:
1. 输入item embedding 和 position embedding的和
2. 经过L层encoder
3. 经过L层的信息交换之后,我们得到输入序列中所有items的最终输出 $H^L = \{h^L_1, \ldots, h^L_{t - 1}, h^L_t\}$。如上图(b)所示,我们在第t步掩盖掉物品$v_t$,然后基于 $h^L_t$预测被掩盖的物品$v_t$。这里使用两层带有GELU激活函数的前馈网络得到最终的输出:
\[ P(v) = softmax(GELU(h^L_tW^P + b^P)E^T + b^O) \]
其中,$W^P$是前馈网络的权重矩阵;$b^P$和$b^O$是偏置项;$E$是item集合的embedding矩阵。BERT4Rec模型在输 入层和输出层用了共享的物品embedding矩阵,目的是减轻过拟合和减少模型大小。
模型训练和预测
在训练阶段,为了提升模型的泛化能力,让模型训练到更多的东西,同时也能够创造更多的样本,借鉴了BERT中的Masked Language Model的训练方式,随机的把输入序列的一部分掩盖(即变为[mask]标记),让模型来预测这部分盖住地方对应的物品
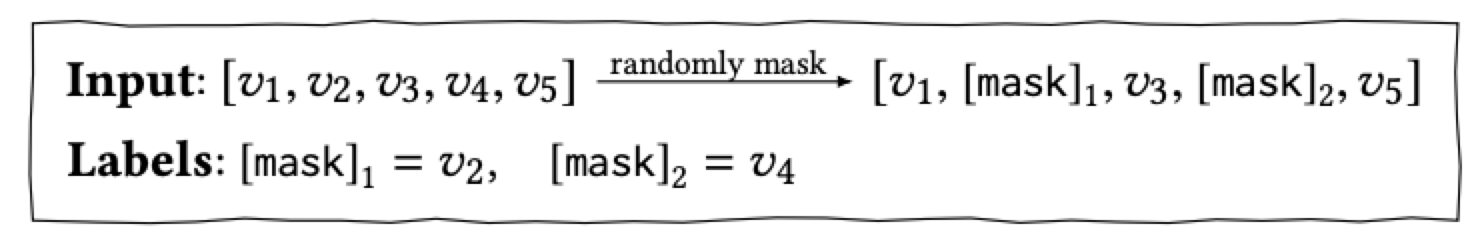
采用这种训练方式,最终的损失函数为:
\[ L = \frac{1}{|S^m_u|} \sum_{v_m \in S^m_u} -\log P(v_m = v^*_m | S'_u) \]
在预测阶段我们将masked附加到用户行为序列的末尾,然后根据该masked的最终隐藏表示来预测下一项。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号