

阿里两阶段长序列建模SIM:《Search-based User Interest Modeling with Lifelong Sequential Behavior Data for Click-Through Rate Prediction》
背景
用户的行为序列对于建模用户兴趣是非常重要的,但是像DIN/MHTA这种建模方式受性能的制约一般只能建模50~100长度的序列,但是在电商、短视频等用户行为比较丰富的场景,用户的行为序列长度可能过万。
直接对这么长的序列建模肯定不可行的,阿里提出了两阶段长序列建模的方案SIM:
- 用target item从用户行为序列中检索出最相关的k个item,构成一个短序列
- 用DIN/DIEN等方式对检索出的短序列建模
方法
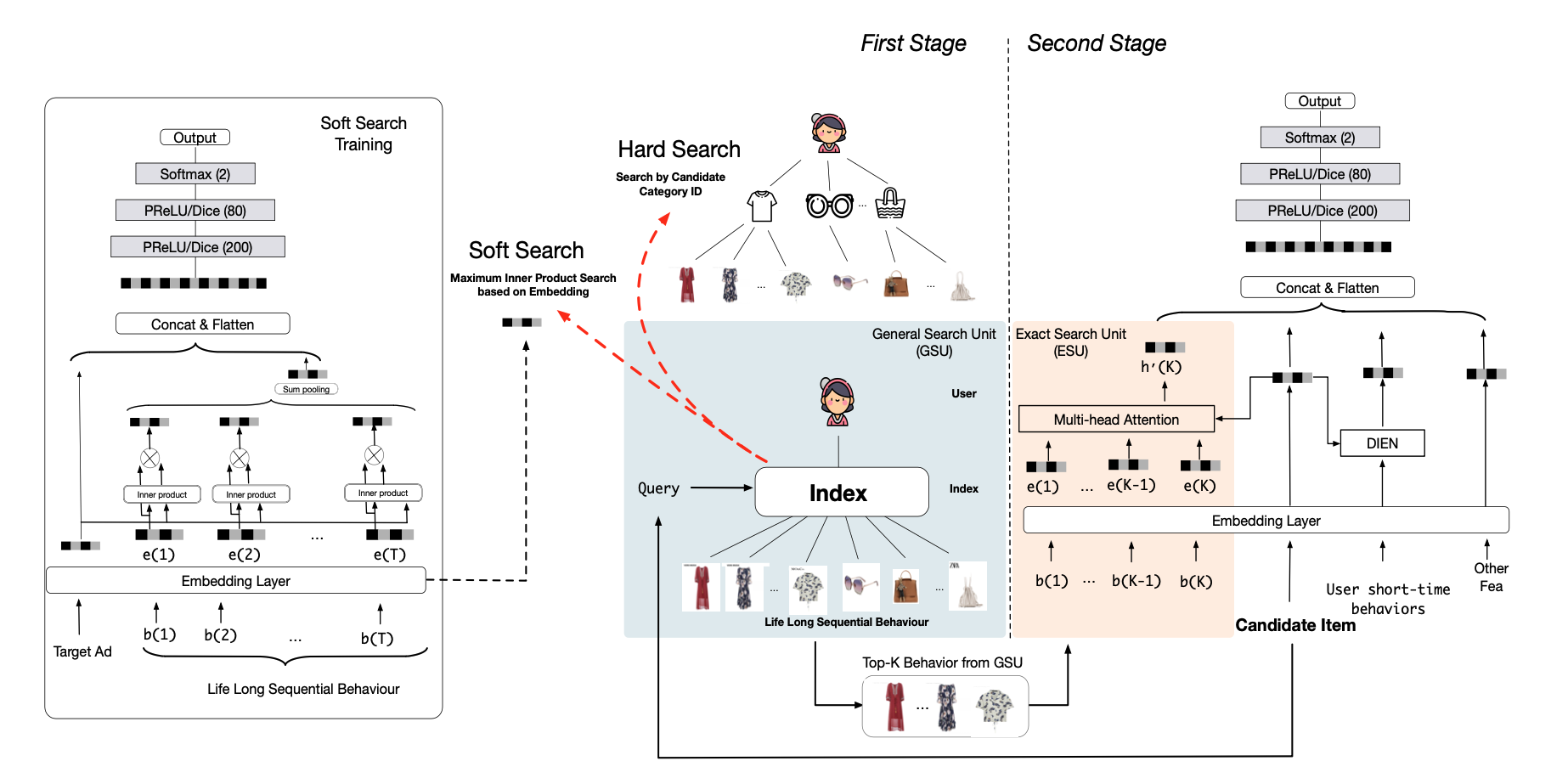
完整的系统架构如上图所示,包含两个阶段:
第一个阶段用target item从用户行为序列中检索出最相关的k个item,构成一个短序列
有Soft Search 和 Hard Search两种检索方法
- Soft Search:训练一个类似DIN结构的模型对用户长序列建模,建模后得到item embedding(用召回双塔训练的得到的item embedding是不是也可以?),检索时通过embedding相似度检索,为了提高效率可以用ANN检索方式(论文用的ALSH)
- Hard Search:用target item的类别/标签去检索同类别/标签的item
论文经过实验发现两种检索方式效果差不多,但是Hard Search更容易部署上线,因此最终采用了Hard Search的检索方式
第二阶段用DIN/DIEN等方式对检索出的短序列进行精确建模

 浙公网安备 33010602011771号
浙公网安备 33010602011771号