

腾讯多任务学习ple模型
背景
论文提出目前的mulitask模型存在以下两个问题:
- 负迁移(negative transfer):MTL(mul task learning)提出来的目的是为了不同任务,尤其是数据量较少的任务可以通过共享部分网络结构学习的更好。但经常事与愿违,当两个任务之间的相关性很弱或者非常复杂时,往往发生负迁移,即共享了之后效果反而很差,还不如不共享。
- 跷跷板现象:还是当两个task之间相关性很弱或者很复杂时,往往出现的现象是:一个task性能的提升是通过损害另一个task的性能做到的
MMOE模型在一定程度上缓解了这个问题,但是仍旧不够彻底,因此论文提出了PLE模型
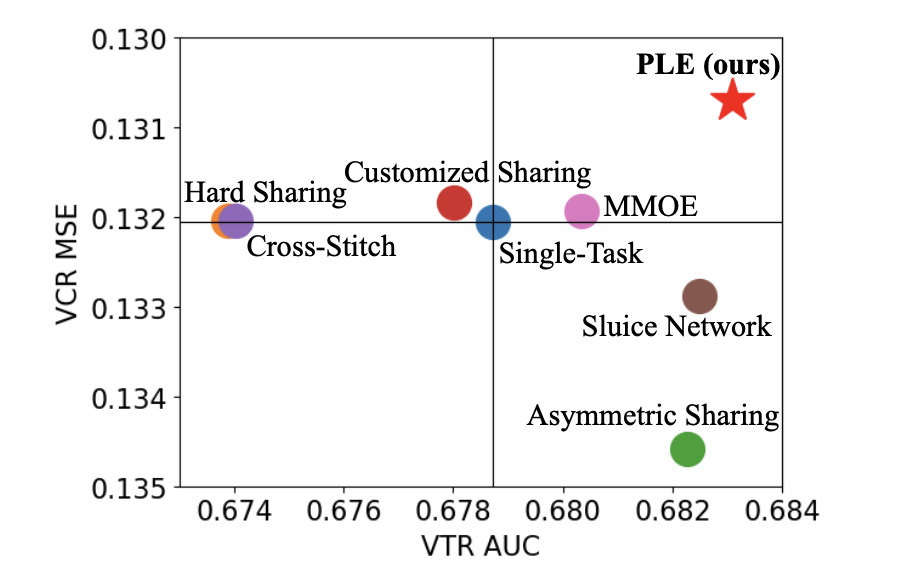
腾讯视频推荐架构

\[ \begin{align*} score =& p_{VTR}^{w_{VTR}} \times p_{VCR}^{w_{VCR}} \times p_{SHR}^{w_{SHR}} \times \cdots \times \\ & p_{CMR}^{w_{CMR}} \times f(\text{video_len}), \end{align*} \]
模型结构
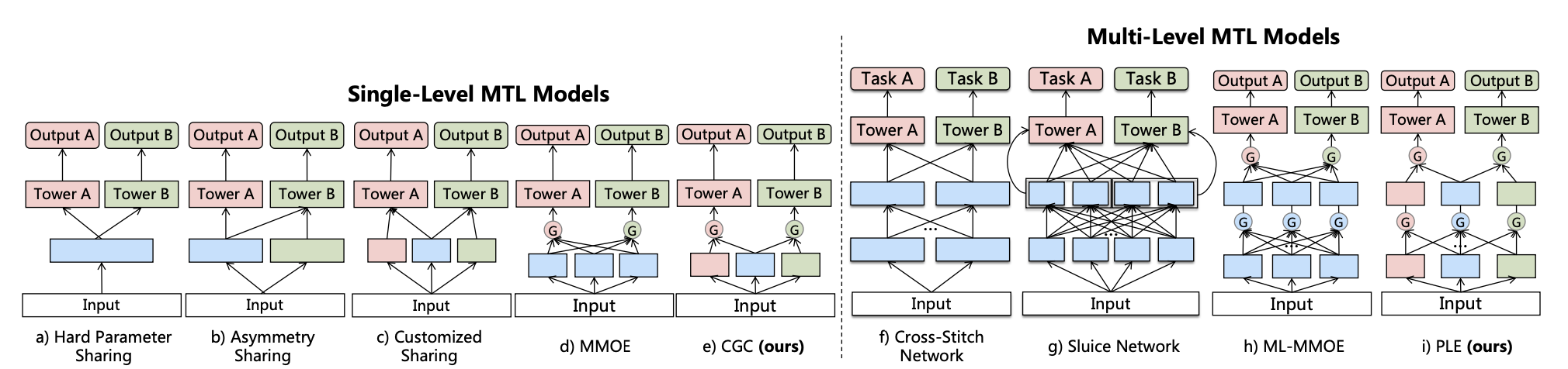
单层的PLE的模型(CGC)结构如上图左半部分所示,和MMOE相比,对于每个task,不仅有所有task共享的experts,还有每个task私有的experts,这样可以达到共享experts建模任务间的共性,私有experts建模task的个性,减少不同任务之间的冲突
如上图右边所示,还可以堆叠多个CGC,提高模型的建模能力
代码实现
import tensorflow as tf from tensorflow.keras.layers import Input, Dense from tensorflow.keras.models import Model import numpy as np # 定义专家网络 def expert_network(input_dim, expert_units): inputs = Input(shape=(input_dim,)) x = Dense(expert_units, activation='relu')(inputs) return Model(inputs=inputs, outputs=x) # 定义门控网络 def gate_network(input_dim, num_experts): inputs = Input(shape=(input_dim,)) x = Dense(num_experts, activation='softmax')(inputs) return Model(inputs=inputs, outputs=x) # 定义 cgc 层 def cgc_layer(inputs, num_experts_shared, num_experts_specific, expert_units, num_tasks, is_last_layer=False): print('inputs[i]', inputs[-1].shape[-1]) # 特定任务专家网络 experts_specific = [[expert_network(inputs[i].shape[-1], expert_units) for _ in range(num_experts_specific)] for i in range(num_tasks)] expert_outputs_specific = [] for i in range(num_tasks): task_expert_outputs = [expert(inputs[i]) for expert in experts_specific[i]] task_expert_outputs = tf.stack(task_expert_outputs, axis=1) expert_outputs_specific.append(task_expert_outputs) # 共享专家网络 experts_shared = [expert_network(inputs[-1].shape[-1], expert_units) for _ in range(num_experts_shared)] expert_outputs_shared = [expert(inputs[-1]) for expert in experts_shared] expert_outputs_shared = tf.stack(expert_outputs_shared, axis=1) task_outputs = [] for i in range(num_tasks): gate = gate_network(inputs[i].shape[-1], num_experts_shared + num_experts_specific) gate_output = gate(inputs[i]) gate_output = tf.expand_dims(gate_output, axis=-1) # 合并专家输出 all_expert_outputs = tf.concat([expert_outputs_shared, expert_outputs_specific[i]], axis=1) weighted_expert_output = all_expert_outputs * gate_output task_output = tf.reduce_sum(weighted_expert_output, axis=1) task_outputs.append(task_output) if not is_last_layer: gate = gate_network(inputs[-1].shape[-1], num_experts_shared + num_experts_specific * num_tasks) gate_output = gate(inputs[-1]) gate_output = tf.expand_dims(gate_output, axis=-1) # 合并专家输出 all_expert_outputs = tf.concat([expert_outputs_shared] + expert_outputs_specific, axis=1) weighted_expert_output = all_expert_outputs * gate_output task_output = tf.reduce_sum(weighted_expert_output, axis=1) task_outputs.append(task_output) return task_outputs # 定义 PLE 模型 def PLE(input_dim, num_experts_shared, num_experts_specific, expert_units, num_tasks, num_levels): inputs = Input(shape=(input_dim,)) ple_inputs = [inputs] * (num_tasks + 1) for i in range(num_levels): if i == num_levels - 1: ple_outputs = cgc_layer(ple_inputs, num_experts_shared, num_experts_specific, expert_units, num_tasks, is_last_layer=True) else: ple_outputs = cgc_layer(ple_inputs, num_experts_shared, num_experts_specific, expert_units, num_tasks, is_last_layer=False) ple_inputs = ple_outputs final_outputs = [Dense(1, activation='sigmoid')(output) for output in ple_outputs] model = Model(inputs=inputs, outputs=final_outputs) return model # 生成模拟数据 input_dim = 10 num_samples = 1000 num_tasks = 2 num_experts_shared = 3 num_experts_specific = 2 expert_units = 16 num_levels = 1 X = np.random.randn(num_samples, input_dim) y = [np.random.randint(0, 2, num_samples) for _ in range(num_tasks)] # 划分训练集和测试集 train_size = int(num_samples * 0.8) X_train, X_test = X[:train_size], X[train_size:] y_train = [y_task[:train_size] for y_task in y] y_test = [y_task[train_size:] for y_task in y] # 创建 PLE 模型 model = PLE(input_dim, num_experts_shared, num_experts_specific, expert_units, num_tasks, num_levels) # 编译模型 model.compile(optimizer='adam', loss=['binary_crossentropy'] * num_tasks, metrics=['accuracy']) # 训练模型 model.fit(X_train, y_train, epochs=10, batch_size=32, validation_split=0.1) # 测试模型 results = model.evaluate(X_test, y_test) losses = results[:num_tasks+1] accuracies = results[num_tasks+1:] print(f"Test losses: {losses}") print(f"Test accuracies: {accuracies}")

 浙公网安备 33010602011771号
浙公网安备 33010602011771号