

阿里多场景建模star模型《One Model to Serve All: Star Topology Adaptive Recommender for Multi-Domain CTR Prediction》
背景
这是阿里发表的多场景预估的论文,多场景和多任务的区别:
1. 多任务是一个场景内建模不同的目标,多场景是在多个场景建模相同目标
2. 多任务由于是一个场景内,所以数据分布是一样的,多场景不同场景的数据分布可能不同
模型结构

star模型结构如上图所示,和普通的ctr模型对比,主要有以下几个区别:
1. BN层换成了PN,简单来说就是对不同domain的样本采用了不同的BN
2. Star Topology FCN,不同domain有一个共享的FCN,每个domain也有自己的FCN
3. 加了一个辅助任务,强化模型区分不同domian
Partitioned Normalization
batch normalization (BN) 是模型中常见的一种结构
训练时:
\[ \mathbf{z}' = \gamma \frac{\mathbf{z} - \mu}{\sqrt{\sigma^2 + \epsilon}} + \beta, \]
预估时:
\[ \mathbf{z}' = \gamma \frac{\mathbf{z} - E}{\sqrt{Var + \epsilon}} + \beta. \]
BN假设了所有的样本都是服从相同分布的,BN适合单场景的任务,对于多场景的任务,不同场景的数据分布不同,为了解决这个问题,阿里star提出了partitioned normalization结构
训练时:
\[ z' = (\gamma * \gamma_p) \frac{z - \mu}{\sqrt{\sigma^2 + \epsilon}} + (\beta + \beta_p), \]
预估时:
\[ \mathbf{z}' = (\gamma * \gamma_p) \frac{\mathbf{z} - E_p}{\sqrt{Var_p + \epsilon}} + (\beta + \beta_p). \]
和普通BN相比,PN有以下几点不同:
1. 每个mini batch的样本要属于同一个domain
2. 训练时,不仅学习了所有domain共享的一对参数(γ,β),对于每个domain还另外学习了一对参数(γp,βp)
3. 预估时,每个domain都要计算它的期望和方差
Star Topology FCN
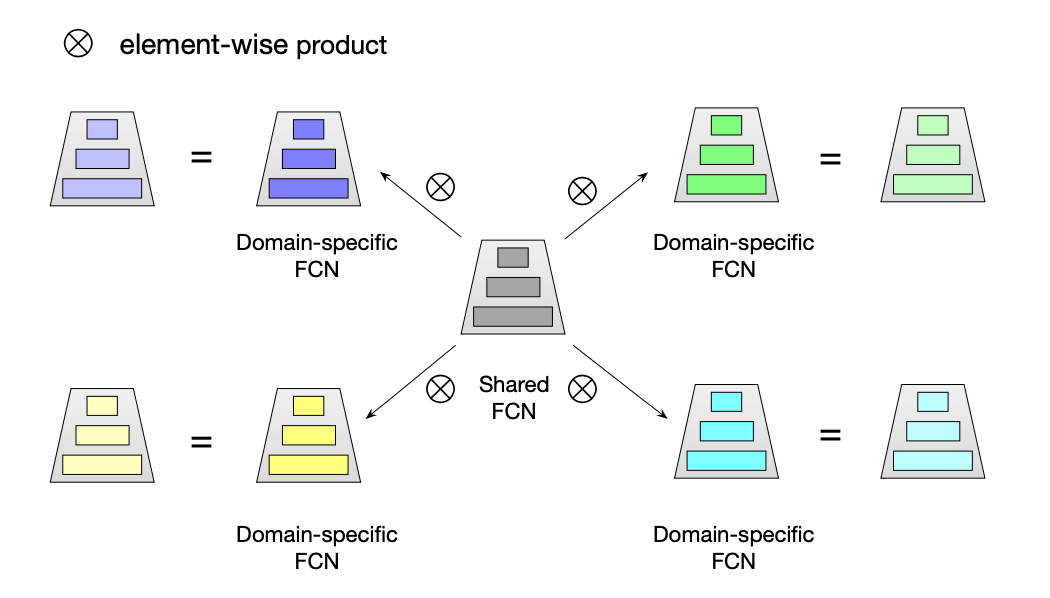
Star Topology FCN的结构如上图所示,由一个每个domian共享的FCN和多个每个domain私有的FCN组成
\[ W_p^\star = W_p \otimes W, b_p^\star = b_p + b, \]
\[ out_p = \phi((W_p^\star)^\top in_p + b_p^\star), \]
Auxiliary Network
为了加强模型对各个domain的区分能力,阿里star网路引入了一个辅助任务。每个domain的标识是一个ID特征,也会学习它的embedding,concat到其它特征上,然后通过两层的FCN得到一个1维的值,这里标记主任务的输出为sm,辅助任务的输出时sa,那么最终的输出是:
\[ \text{Sigmoid}(s_m + s_a). \]
这个辅助任务可以理解为为每个子任务学习了一个bias
Loss
\[ \min \sum_{p = 1}^{M} \sum_{i = 1}^{N_p} - y_i^p \log(\hat{y}_i^p) - (1 - y_i^p) \log(1 - \hat{y}_i^p). \]
参考资料
https://zhuanlan.zhihu.com/p/437246384

 浙公网安备 33010602011771号
浙公网安备 33010602011771号