

MapReduce初步
最基本的海量数据分流思想
• 传统Hash,最基本的划分方法
– 如何将大数据、流量均分到N台服务器
– 找到合理的key,hash(key)尽量分布均匀
– hash(key)mod N == 0 分到 第0台,
– hash(key)mod N == i 分到 第i台
– hash(key)mod N == N-1 分到 第N-1台
• 随机划分
• 一致性Hash:支持动态增长,更高级的划分方法
MapReduce基本思想:分治思想
• MapReduce映射
– 分:map
• 把复杂的问题分解为若干“简单的 任务”
– 合:reduce
MapReduce计算框架- 执行流程
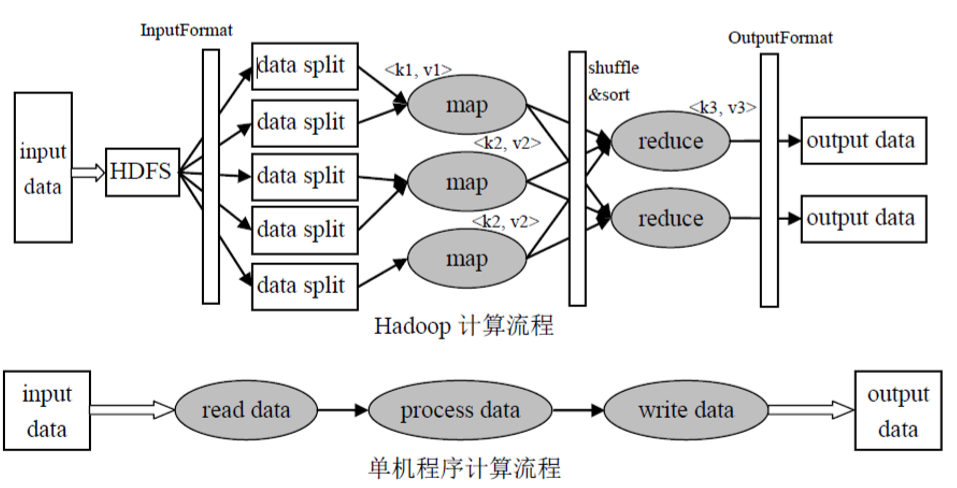

MapReduce编程模型
• 借鉴函数式的编程方式
• 用户只需要实现两个函数接口:
• Map
(in_key, in_value) -> (out_key, intermediate_value) list
• Reduce
(out_key, intermediate_value list) ->out_value list
MapReduce实现架构
• 两个重要的进程
– JobTracker
• 主进程,负责接收客户作业提交,调度任务到作节点上运行,并提供诸如监控工作节点状态及任务进度等 管理功能,一个MapReduce集群有一个jobtracker,一般运行在可靠的硬件上。
• tasktracker是通过周期性的心跳来通知jobtracker其当前的健康状态,每一次心跳包含了可用的map和 reduce任务数目、占用的数目以及运行中的任务详细信息。Jobtracker利用一个线程池来同时处理心跳和 客户请求。
– TaskTracker
• 由jobtracker指派任务,实例化用户程序,在本地执行任务并周期性地向jobtracker汇报状态。在每一个工 作节点上永远只会有一个tasktracker

 浙公网安备 33010602011771号
浙公网安备 33010602011771号