


Zookeeper
zookeeper介绍
• Hadoop系统
• 开源的,高效的,可靠的协同工作系统
• 名字服务器,分布式同步,组服务
• Google内部实现叫Chubby
• 基于Paxos协议
zookeeper概述
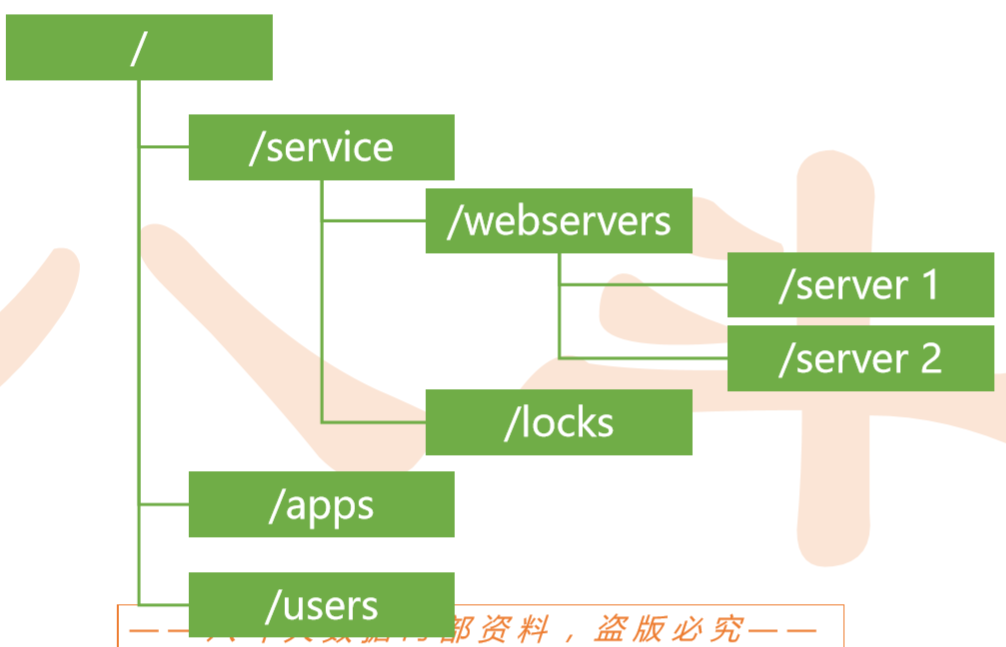
数据模型
– 命名空间
– 与标准文件系统很相似
– 以 / 为间隔的路径名序列组成
– 只有绝对路径,没有相对路径
每个节点自身的信息
– 数据
– 数据长度
– 创建时间
– 修改时间
具有文件,路径的双重特点
zookeeper中的几种基本节点
• Persistent Nodes
– 永久有效地节点,除非client显式的删除,否则一直存在
• Ephemeral Nodes
– 临时节点,仅在创建该节点client保持连接期间有效,一旦连接丢失,zookeeper会自动删除该节 点
• Sequence Nodes
– 顺序节点,client申请创建该节点时,zk会自动在节点路径末尾添加递增序号,这种类型是实现分布式锁,分布式queue等特殊功能的关键
监控机制(watch)
– 数据节点上设置
– 客户端被动收到通知
– 各种读请求,如getData(),getChildren(),和exists()
三个关键点
– 一次性监控,触发后,需要重新设置
– 保证先收到事件,再收到数据修改的信息
– 传递性
• 如create会触发节点数据监控点,同时也会触发父节点的监控点
• 如delete会触发节点数据监控点,同时也会触发父节点的监控点
风险
– 客户端有可能看不到所有数据的变化
– 多个事件的监控,有可能只会触发一次
• 一个客户端设置了关于某个数据点exists和getData的监控,则当该数据被删除的时候,只会触发 “文件被删除”的通知。
– 客户端网络中断的过程的无法收到监控的窗口时间,要由模块进行容错设计
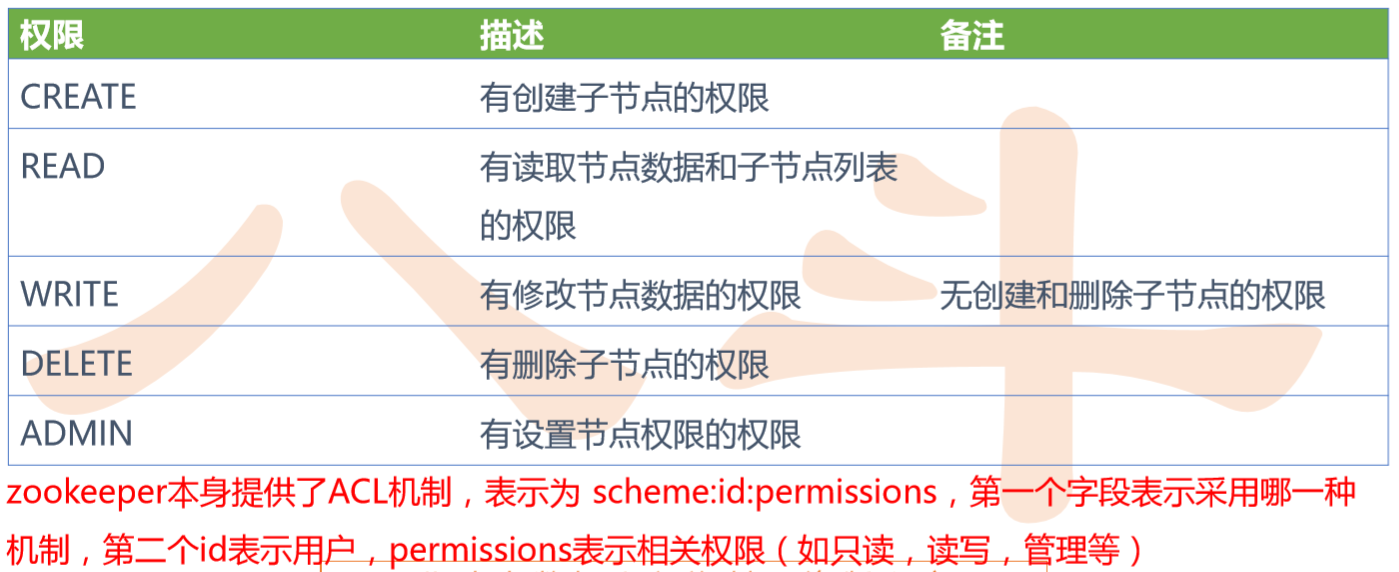
数据访问
– 每个节点上的“访问控制链”(ACL, Access Control List)保存了各客户端对于该节点的访问 权限。
– 用一个三元组来定义客户端的访问权限:(scheme:expression, perms)
• ip:19.22.0.0/16, READ)表示IP地址以19.22开头的主机有该数据节点的读权限。

一致性保证
– 序列一致性:客户端发送的更新将按序在Zookeeper进行更新
– 原子一致性:更新只能成功或者失败,没有中间状态
– 单系统镜像:无论连接哪台Zookeeper服务器,客户端看到的服务器数据一致
– 可靠性:任何一个更新成功后都会持续生效,直到另一个更新将它覆盖。可靠性有两个关键点: 第 一,当客户端的更新得到成功的返回值时,可以保证更新已经生效,但在某些异常情况下(超时 ,连接失败),客户端无法知道更新是否成功;第二,当更新成功后,不会回滚到以前的状态, 即使是在服务器失效重启之后
– 实时性:Zookeeper保证客户端将在一个时间间隔范围内获得服务器的更新信息,或者服务器失效的信息。但由于网络延时等原因,Zookeeper不能保证两个客户端能同时得到刚更新的数据, 如果需要最新数据,应该在读数据之前调用sync()接口

 浙公网安备 33010602011771号
浙公网安备 33010602011771号