


Storm
相关概念
流式处理
• 时效性高
• 逐条处理数据
• 低延时
• 不是一个新概念
– 管道(PIPE)
• Cat input | grep pattern | sort | uniq > output
分布式流处理
• 单机处理不了
– 内存
– CPU
– 存储
• 多机流式系统
– 流量控制
– 容灾冗余
– 路径选择
– 扩展
Storm特点
• 没有持久化层
• 保证消息得到处理
• 支持多种编程语言
• 高效,用ZeroMQ作为底层消息队列
• 支持本地模式,可模拟集群所有功能
• 使用原语 – 类同MapReduce中的Map、Reduce
Storm vs Hadoop
• Storm任务没有结束,Hadoop任务执行完结束
• Storm延时更低,得益于网络直传、内存计算,省去了批处理的收集数据的时间
• Hadoop使用磁盘作为中间交换的介质,而storm的数据是一直在内存中流转的
• Storm的吞吐能力不及Hadoop,所以不适合批处理计算模型
相关概念:
1. 延时,指数据从产生到运算产生结果的时间
2. 吞吐,指系统单位时间处理的数据量
Storm基本概念
Stream
以Tuple为基本单位组成的一条有向无界的数据流
Tuple: Integer,long,short,byte,string,double,float,boolean和byte array,包括自定义类型
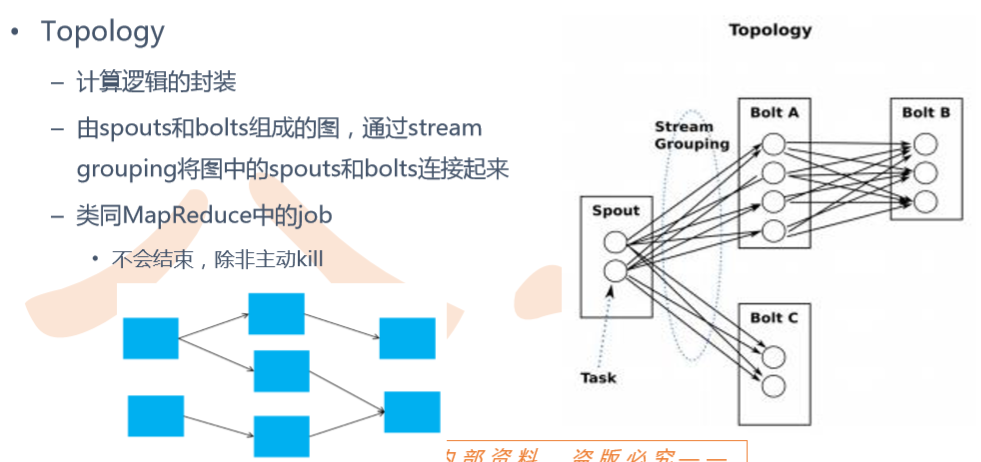
Topology
Topology介绍
Topology任务执行
– Storm jar code.jar MyTopology arg1 arg2
• storm jar负责连接到Nimbus并且上传jar包
• 运行主类 MyTopology, 参数是arg1, arg2;这个类的main函数定义这个topology并且把它提 交给Nimbus
• Topology的定义是一个Thrift结构,并且Nimbus就是一个Thrift服务, 你可以提交由任何语言 创建的topology;
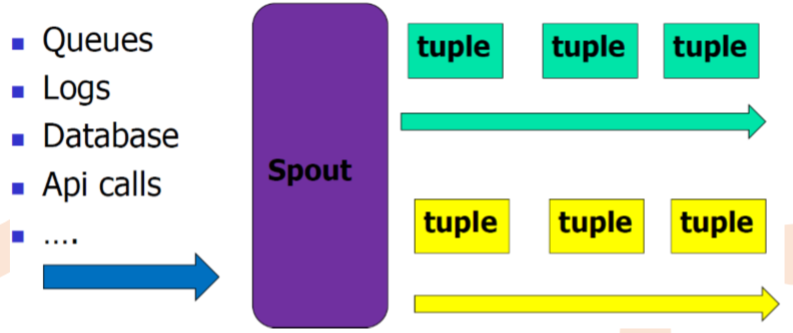
Spout
– 消息来源,消息生产者
– 可靠的,不可靠的
• 可靠的,如果没有被成功处理,可重新emit一个tuple
– 可指定emit多个Stream流
• OutFieldsDeclarer.declareStream定义
• SpoutOutputCollector指定
– nextTuple
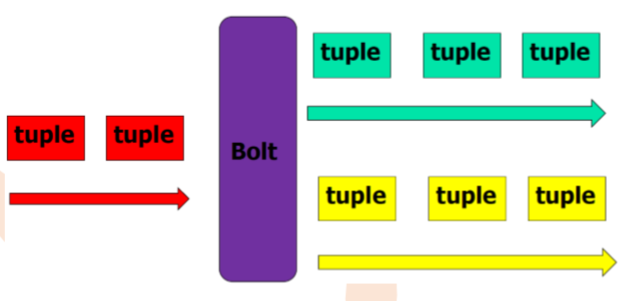
Bolt
– 消息处理逻辑
• 如过滤,访问数据库,聚合
– 多个bolt处理负责步骤
– 可以发射多个数据流
– 主方法为execute
• 以tuple为输入
• 处理具体的tuple
• 发射0或多个tuple
• OutputCollector的ack,确认
• IBasicBolt,会自动调节
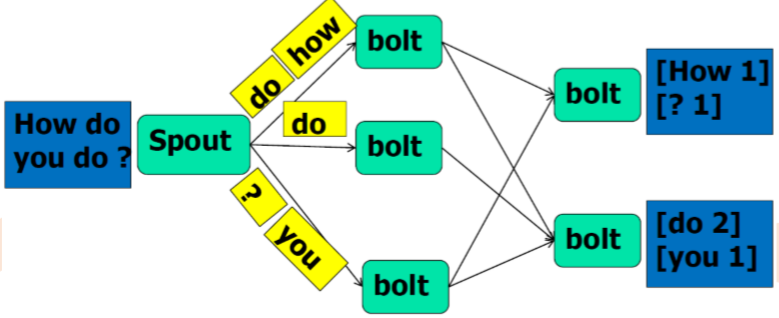
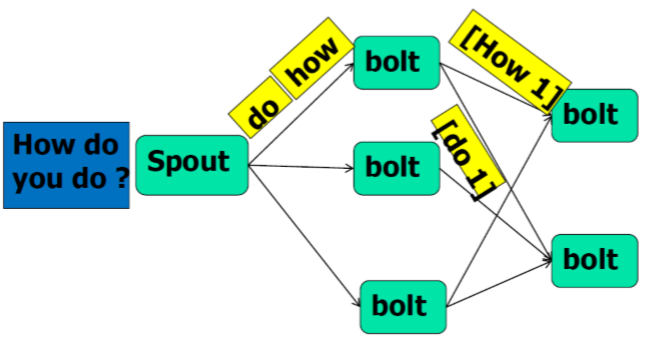
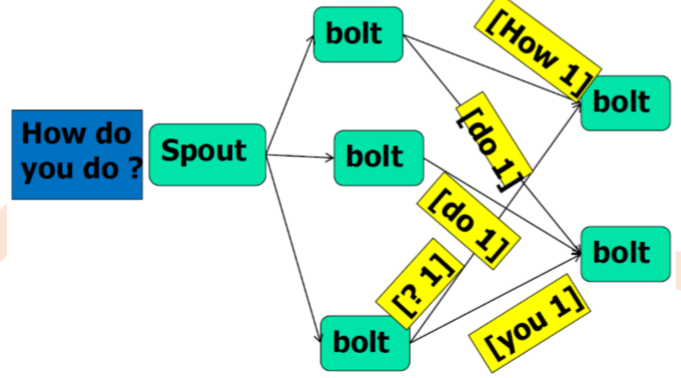
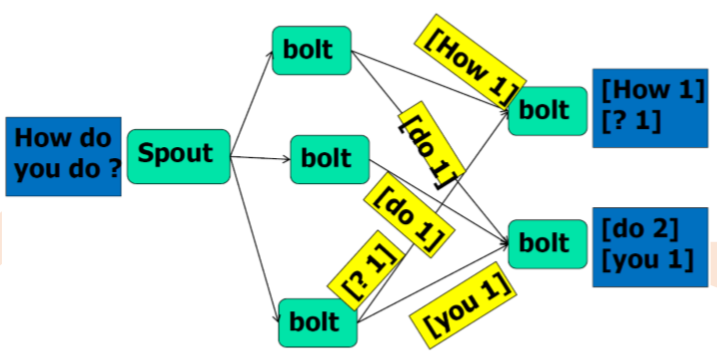
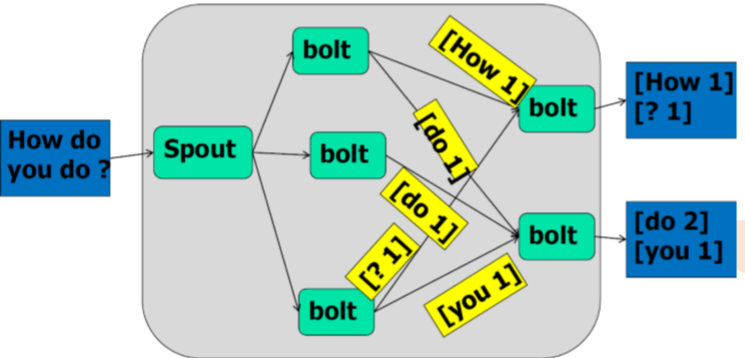
Storm计算流程示例(word count)


 浙公网安备 33010602011771号
浙公网安备 33010602011771号