
Hadoop Streaming
Hadoop Streaming
Streaming简介
• MapReduce和HDFS采用Java实现,默认提供Java编程接口
• Streaming框架允许任何程序语言实现的程序在Hadoop MapReduce中 使用
• Streaming方便已有程序向Hadoop平台移植
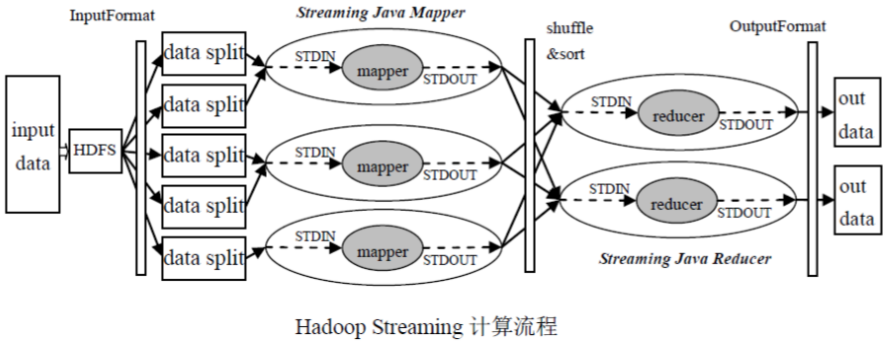
Streaming原理
python MapReduce运行脚本示例
HADOOP_CMD="/usr/local/src/hadoop-1.2.1/bin/hadoop" STREAM_JAR_PATH="/usr/local/src/hadoop-1.2.1/contrib/streaming/hadoop-streaming-1.2.1.jar" #INPUT_FILE_PATH_1="/The_Man_of_Property.txt" INPUT_FILE_PATH_1="/1.data" OUTPUT_PATH="/output" $HADOOP_CMD fs -rmr -skipTrash $OUTPUT_PATH # Step 1. $HADOOP_CMD jar $STREAM_JAR_PATH \ -input $INPUT_FILE_PATH_1 \ -output $OUTPUT_PATH \ -mapper "python map_new.py" \ -reducer "python red_new.py" \ -file ./map_new.py \ -file ./red_new.py
运行:bash run.sh
jobconf

输出数据压缩
• 输出数据量较大时,可以使用Hadoop提供的压缩机制对数据进行压缩,减少网络传输带宽 和存储的消耗。
• 可以指定对map的输出也就是中间结果进行压缩
• 可以指定对reduce的输出也就是最终输出进行压缩
• 可以指定是否压缩以及采用哪种压缩方式。
• 对map输出进行压缩主要是为了减少shuffle过程中网络传输数据量
• 对reduce输出进行压缩主要是减少输出结果占用的HDFS存储。
示例:
HADOOP_CMD="/usr/local/src/hadoop-1.2.1/bin/hadoop" STREAM_JAR_PATH="/usr/local/src/hadoop-1.2.1/contrib/streaming/hadoop-streaming-1.2.1.jar" INPUT_FILE_PATH_1="/The_Man_of_Property.txt" OUTPUT_PATH="/output_cachearchive_broadcast" $HADOOP_CMD fs -rmr -skipTrash $OUTPUT_PATH # Step 1. $HADOOP_CMD jar $STREAM_JAR_PATH \ -input $INPUT_FILE_PATH_1 \ -output $OUTPUT_PATH \ -mapper "python map.py mapper_func WH.gz" \ -reducer "python red.py reduer_func" \ -jobconf "mapred.reduce.tasks=10" \ -jobconf "mapred.job.name=cachefile_demo" \ -jobconf "mapred.compress.map.output=true" \ -jobconf "mapred.map.output.compression.codec=org.apache.hadoop.io.compress.GzipCodec" \ -jobconf "mapred.output.compress=true" \ -jobconf "mapred.output.compression.codec=org.apache.hadoop.io.compress.GzipCodec" \ -cacheArchive "hdfs://master:9000/w.tar.gz#WH.gz" \ -file "./map.py" \ -file "./red.py"
对多个文件内容进行排序
方法1:采用单个reduce
缺点:效率低


set -e -x HADOOP_CMD="/usr/local/src/hadoop-1.2.1/bin/hadoop" STREAM_JAR_PATH="/usr/local/src/hadoop-1.2.1/contrib/streaming/hadoop-streaming-1.2.1.jar" INPUT_FILE_PATH_A="/a.txt" INPUT_FILE_PATH_B="/b.txt" OUTPUT_SORT_PATH="/output_sort" $HADOOP_CMD fs -rmr -skipTrash $OUTPUT_SORT_PATH # Step 3. $HADOOP_CMD jar $STREAM_JAR_PATH \ -input $INPUT_FILE_PATH_A,$INPUT_FILE_PATH_B\ -output $OUTPUT_SORT_PATH \ -mapper "python map_sort.py" \ -reducer "python red_sort.py" \ -jobconf "mapred.reduce.tasks=1" \ -file ./map_sort.py \ -file ./red_sort.py \
方法2:采用多个reduce,增加一个key用来分桶(partition)
set -e -x HADOOP_CMD="/usr/local/src/hadoop-1.2.1/bin/hadoop" STREAM_JAR_PATH="/usr/local/src/hadoop-1.2.1/contrib/streaming/hadoop-streaming-1.2.1.jar" INPUT_FILE_PATH_A="/a.txt" INPUT_FILE_PATH_B="/b.txt" OUTPUT_SORT_PATH="/output_sort" $HADOOP_CMD fs -rmr -skipTrash $OUTPUT_SORT_PATH # Step 3. $HADOOP_CMD jar $STREAM_JAR_PATH \ -input $INPUT_FILE_PATH_A,$INPUT_FILE_PATH_B\ -output $OUTPUT_SORT_PATH \ -mapper "python map_sort.py" \ -reducer "python red_sort.py" \ -file ./map_sort.py \ -file ./red_sort.py \ -jobconf mapred.reduce.tasks=2 \ -jobconf stream.num.map.output.key.fields=2 \ -jobconf num.key.fields.for.partition=1 \ -partitioner org.apache.hadoop.mapred.lib.KeyFieldBasedPartitioner #-jobconf stream.map.output.field.separator=' ' \

 浙公网安备 33010602011771号
浙公网安备 33010602011771号