

专业术语
1. 专业术语
- 1. 专业术语
- 1.1. mysql RPO是什么意思_揭开数据库RPO等于0的秘密(上)
- 1.2. PITR (按时间点恢复)
- 1.3. ACID (事物)
- 1.4. MVCC (多版本并发控制)
- 1.5. HTAP(混合事物分析)
- 1.6. MPP(并行计算)
- 1.7. 单点登陆
- 1.8. "To B" 和 "To C"
- 1.9. RPO(Recovery Point Objective)和RTO(Recovery Time Objective)
- 1.10. TCP和UDP
1.1. mysql RPO是什么意思_揭开数据库RPO等于0的秘密(上)
1.1.1. 前言
传统商业关系数据库都声称可以做到故障恢复后不丢数据(即RPO为0),跟故障前的数据状态是强一致的,实际是否一定如此? 开源数据库MySQL在金融核心业务都不敢用,最重要的一个原因是做不到不丢数据。但是有些基于MySQL修改的数据库为何又说自己是强一致的呢?新兴的分布式数据库OceanBase声称是金融级的分布式关系型数据库,强一致,绝对不丢数据,这个是真的吗?
本文分为上下两篇。 上篇分析传统关系数据库Oracle/MySQL在应对故障时保障数据不丢失的机制,以及分析AliSQL和PolarDB在这方面探索的改进措施。下篇分析蚂蚁的OceanBase在数据安全方面的创新之处。
1.1.2. 数据库的容灾设计
数据库写策略:WAL机制(Write Ahead Logging)
数据库在读数据的时候,会将数据所在块读入到数据库内部的缓存中。如Oracle里称为Buffer Cache,MySQL称为Buffer Pool。当数据修改后,这些缓存中的块就被称为脏块(Dirty Block)。为了性能考虑,数据库(DBWn进程)并不会立即把这些脏块写回到磁盘上。这个有个风险,当数据库进程宕掉时,磁盘上的数据并不是最新的数据。即使数据库进程恢复了,也找不回原来的数据修改。所以,数据库在修改数据之前,都会先在日志缓冲区记录块修改的日志(即事务日志),并把这个日志先写回磁盘上。有个例外如Oracle的direct load。
这个技术就是Write Ahead Logging技术。有了这个事务日志,数据库就有能力维持缓存和磁盘上数据最终一致,即使数据库宕机。对于一个数据库软件来说,发生异常的时候只要事务日志没有丢失,它就敢承诺数据库服务恢复后,数据绝对不丢。即RPO为0。或者说事务日志是安全可靠的,那么数据就是安全可靠的。当然,严格的说还有一个前提是数据文件没有损坏,或者有数据文件的备份可以还原。否则会比较麻烦。比如说从第一个事务日志开始恢复到最新的状态。时间太久意义不大。
1.1.3. 日志文件打开方式:Direct IO和Buffered IO
这节继续说事务日志的安全性。数据库(LGWR进程)在写事务日志时,为了性能也是会先写入一个日志缓存(Log Buffer)。然而不同数据库对将Log Buffer中的事务日志写到盘上的策略不尽相同,这个后面每个数据库再具体分析。这里要说的是写到磁盘上这个动作是否可靠。
OS里为了提升文件的读写性能,设计了缓存机制(Page Cache和Buffer Cache)。数据库有自己的缓存(Buffer Cache和Log Buffer),不需要使用OS的缓存(因为数据库更懂自己的数据)。Direct IO选项就是指定数据库打开数据文件和事务日志文件的方式。另外一种方式就是Buffered IO,数据写到内核缓冲区就返回了。这有个风险就是一旦操作系统宕机再恢复,这个内核缓冲区数据就丢失了,磁盘上的数据很可能也不是最新的。
所以数据库的事务日志打开方式必须使用Direct IO,才可以保证事务日志的绝对安全可靠。
1.1.4. 副本复制(Replication)技术
上节说了如果保证事务日志在单机上的可靠性,这节继续说事务日志的安全性。当机器因为存储硬件宕机再也起不来时,或者机器起来了,但是硬盘损坏导致事务日志文件损坏打不开时,数据库里的数据还是找不回来,还是保证不了RPO为0.
所以,为了抵抗单机故障数据丢失风险,要将事务日志的安全级别提高,要在另外一台主机上也保存一份事务日志。这是日志复制(Relication)技术。为了减少在异机恢复时间,也在该主机上维护一份数据副本。先简单称这个副本为备副本。当前的主库上的数据称为主副本。备副本的数据要尽可能的跟主副本数据保持一致,这种一致性保持不是通过业务双写实现(那是业务层面的容灾方案),而是通过将主副本的事务日志复制到备副本机器上并在备副本上应用。类似于在备副本上恢复数据。
大部分关系数据库都是这么做的。在Oracle里这个技术叫Dataguard,在MySQL里叫Replication,SQLServer里叫Mirror。当然SQLServer也有Replication技术。不同数据库在这个Replication细节上会有点区别。
首先是复制的事务日志的格式分两类。一类就是原始的事务日志,记录的是数据块的变化。备副本在应用这个事务日志的时候会严格比对数据块的相关内容是否一致。不一致就会报坏块错误。这种复制技术也称物理复制。所以只要备副本应用了主副本的所有事务日志,备副本跟主副本就是严格一致的。Oracle的物理备库(Physical Standby)、SQL Server的镜像实例(Mirror)都是物理复制。
第二类就是复制的事务日志是数据变化的SQL表示。即复制的事务日志是一组sql(这个sql可以是主副本上导致数据变化的原始sql,也可以是针对每一行变化的数据行的数据更新sql)。这种复制技术也称逻辑复制。Oracle的逻辑备库(Logical Standby,听说11g以后不再发展这个了。)、 SQL Server的Replication技术、MySQL的Slave Replication 都是逻辑复制。在逻辑复制下,备副本数据通常可以跟主副本保持一致,但是如果有异常导致备副本数据跟主副本数据不一致时,备副本应用这个事务日志会报错。有些数据库会提供修复备副本数据的途径,从而决定了数据库自身不能绝对保证备副本跟主副本的强一致。
其次是事务日志传输的可靠性策略分为三类。跟前面单机上数据库写事务日志到本地盘时有两种IO策略可选一样,主库在写事务日志到备库时也有两种写策略可选。这是在安全和性能之间的取舍。具体如下:同步写备库。事务日志在备库上落盘成功主库上请求才返回。至少有一个备库要将事务日志落盘才算可靠;否则,主库事务失败回滚或者主库降级拒绝服务。这种策略也叫安全最大化。
异步写备库。事务日志发往备库上主库请求即反馈。事务日志在备库落盘有可能失败,不影响主库,但是备副本跟主副本就不是强一致。这种策略也叫性能最大化。
只有高安全的这种策略才可以保证备副本和主副本是强一致的。使用这种策略的风险就是如果备库不可用了,会导致主库写失败或者主库也降级不可用。所以通常会至少配置两个备库。这样只要有一个备库将事务日志落盘成功,事务日志还是安全可靠的。当然理论上事务日志可靠了,实际恢复时还要在主库不可用的时候,要准确挑选出那个拥有全部事务日志的备库提供服务。这个传统商业数据库就没有提供自动化手段。
1.1.5. Oracle的事务日志相关逻辑
Oracle事务日志单机写特点
Oracle维护了一个Log Buffer,DBWn进程修改Buffer Cache中的数据块之前,LGWR进程会先写相应的事务日志到Log Buffer,也叫Redo。这个Redo 也包含Oracle Undo块的Redo。Redo缓存在数据库内存里是不可靠的,所以Oracle会有些策略将Log Buffer中的Redo写到磁盘上的事务日志文件(Redo Log File)。
当一个事务提交(COMMIT)是
- 每3秒钟一次
- 当Log Buffer使用率达到1/3时
- 当DBWn进程将“脏”数据写入磁盘时
Oracle打开Redo Log File的方式是建议Direct IO。Oracle还支持裸设备,使用裸设备的时候默认就是Direct IO。
Oracle的Redo日志里既包含已提交的事务,也包含未提交的事务。在应用Redo的时候就能够将数据库的数据缓存还原到宕机前的那一刻,然后未提交的数据会结合Undo里的数据再回滚。
1.1.6. Oracle Dataguard特点
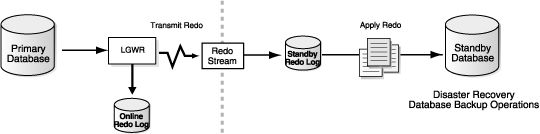
图:Oracle的Dataguard架构图
Oracle的Dataguard有三种模式:
- 最大保护模式:至少两个物理备库,确保事务日志至少传输到至少一台备库上并落盘;否则主库事务失败直接关闭。强一致是保证了,可用性没了
- 最大性能模式:默认模式,事务日志会传输到备库。备库如果不可用不影响主库的读写。不能保证强一致。
- 最大可用模式:是最大保护和最大性能的折衷。当备库可用的时候,事务日志在备库落盘成功后主库事务才返回;当无备库可用时,退化为最大性能模式,主库继续读写服务。 兼顾了强一致和可用性,有时候不能保证强一致。
Oracle的事务日志在传输上还有自己的特点。由于Oracle的事务日志分在线事务日志(Online Redo Log)和归档事务日志(Archived Log)。在线事务日志有正在运行的事务相关日志,会定时归档然后重复利用。归档事务日志的事务会比当前时间落后一段时间(具体由归档时间参数控制)。所以,如果只有归档事务日志的时候,宕机恢复时还是会丢数据,即丢了最少一个在线事务日志的内容。
在最大保护模式和最大可用模式下,Oracle传输到备库的事务日志是跟主库的在线事务日志内容一致的。在最大性能模式下,Oracle传输到备库的事务日志可能是主库的在线事务日志或者归档事务日志。这是可以配置的。这个会影响备库的RPO.
此外,Oracle备库在应用事务日志的时候,也有两种选择。一是选择应用备库的重做事务日志(Standby Redo);一是选择应用备库的归档事务日志(Archived Redo)。很明显,如果只是应用归档事务日志,备库的备副本数据跟主副本数据之间是一定有延时的。在主备切换的时候,为了把数据恢复到跟主库宕机之前的强一致状态,会需要更多的时间。即不可用时间会更长一些。这就是在发生故障(分区事件)时可用性和强一致性不可兼得(CAP理论的观点)。
总体而言,Oracle的Dataguard是绝对有能力做到备副本和主副本的强一致的。不足之处就是可用性方面不能提供自动化保障技术。
1.1.7. MySQL Slave 设计
1.1.7.1. MySQL的事务日志特点
MySQL是开源数据库,架构上分为Server层和Pluggable Storage引擎层,可以对接多种数据库引擎,使用最多的是事务引擎Innodb。本文只讨论InnoDB引擎。
MySQL的Server层对每个写操作 SQL有自己的日志,即Binary Log,简称Binlog。里面记录的是修改的SQL。对接InnoDB 时,Binlog还会记录事务提交事件。同时InnoDB对每笔事务也有自己的事务日志,即InnoDB Redo Log(后面简称Redolog)。 Binlog里记录的是修改的sql(可能是原始sql,也可能是针对每笔修改记录转换的sql),并且Binlog 只记录已提交事务的SQL。Redolog里记录的是InnoDB数据块的变化日志,会包含未提交的事务信息。Binlog更像逻辑复制的事务日志,Redolog像是物理复制用的事务日志。
MySQL单实例是否丢数据,就取决于InnoDB引擎是否丢数据。InnoDB的Redo Log设计原理决定了它有能力做到不丢数据(强一致)。因为它有完整的Redo Log,在恢复的时候,结合Undo Log就可以将宕机时未提交的事务回滚掉。这是通常关系数据库的设计思路。不过MySQL在这方面有自己的特点。
1.1.7.2. MySQL的两阶段提交
对于同一个事务,MySQL的Binlog和Redolog两个日志都有描述,为了保持二者内容一致,MySQL引入两阶段提交协议。由于Binlog的内容是sql,并且只包含已提交的事务,因此不可能跟Redolog绝对一致。两阶段提交发生在应用发出commit请求时。下图示例还不涉及到Slave复制过程。此外这里描述的是MySQL 5.7及之前版本逻辑。
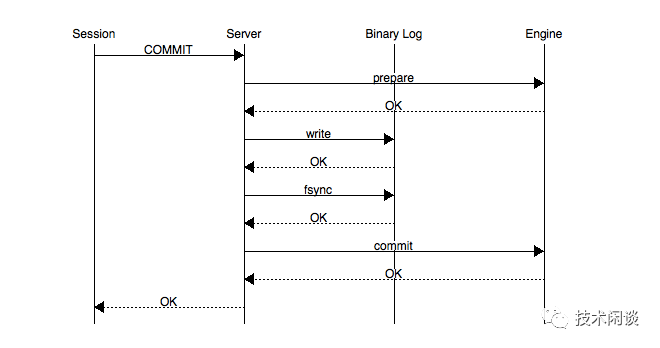
- Prepare阶段:Binlog不用做什么。InnoDB将Undo状态设置为PREPARED,把Redo Log Buffer中的Redolog刷写到磁盘。
- Commit阶段:记录协调者日志,即Binlog。然后把Binlog Buffer中的Binlog刷写到磁盘。清理InnoDB的Undo状态,刷新后续Redolog到磁盘。
这里面Redolog和Binlog都有刷写磁盘的操作,实际过程每个日志都会经过MySQL内部的一个Log Buffer、OS的Pagecache最后才到磁盘文件。MySQL提供了两个参数innodb_flush_log_at_trx_commit和sync_binlog来控制这个写日志到哪个环节就可以返回。这种设计好处是有可能缓解MySQL实例IO性能瓶颈问题,坏处就是事务日志不再绝对可靠。这也是MySQL不安全的最主要的原因之一。
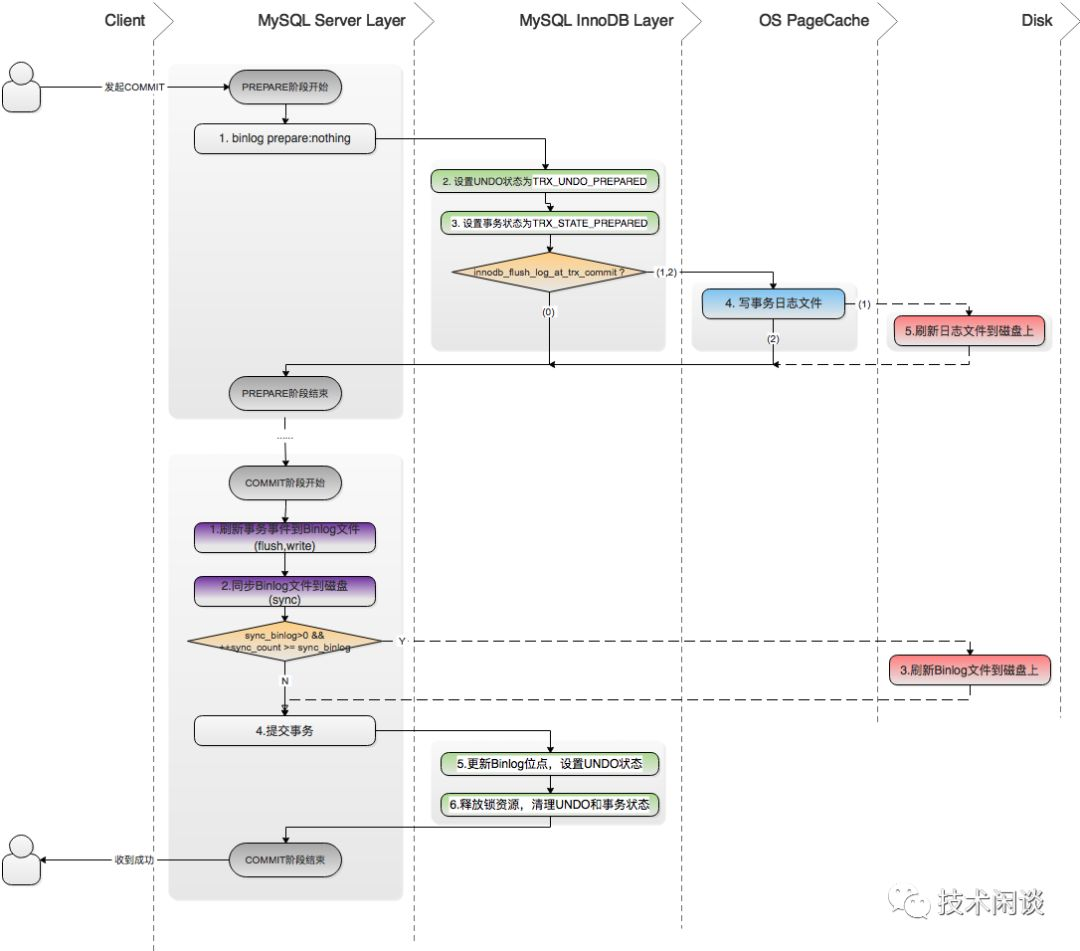
MySQL的Redolog是用于当前实例宕机后再起来时恢复数据的。假设Redo都是及时落盘(innodb_flush_log_at_trx_commit=1),当MySQL起来时,先应用Redo将InnoDB内存恢复到当前前那一刻的状态。然后对于事务状态是未提交状态的,搜索一下Binlog里相应的记录。如果能找到事务对应的Binlog日志,则MySQL认为该笔事务实际已经等同于提交了,就直接提交了这笔事务;否则跟传统逻辑一样回滚该笔事务。
所以,一个MySQL实例,如果宕机了再恢复起来,这个实例是有可能无法恢复到宕机前的那一刻(已提交的数据状态),即无法做到强一致。
在实际生产环境,业务可能等不了这个实例自己恢复,就要求尽快将Slave实例恢复服务。接下来再可靠Slave是否安全。
1.1.7.3. MySQL Slave同步
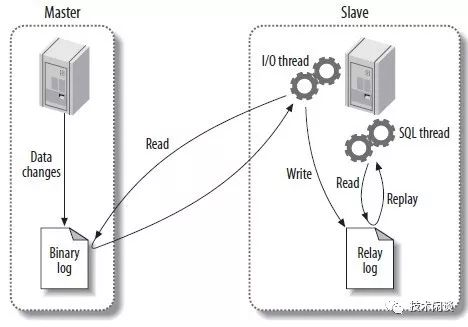
MySQL的Binlog用于Master和Slave之间的事务日志同步。Slave里会有个线程连接到Master来拉取Binlog并写入到Slave本机的Relaylog文件里。Relaylog的设计跟Binlog类似,也有缓冲区(详细查看MySQL参数sync_relay_log)。然后Master的sql线程会读取这个relaylog并应用。这个应用过程也会记录到Slave所在的Binlog和Redolog里。
使用Binlog和Relaylog来做主备同步是MySQL不能绝对保证主备强一致的原因之二。
Slave拉取Master的Binlog过程在Master的两阶段提交流程的COMMIT阶段。为了尽可能降低主备不一致的概率,MySQL引入了半同步(Semi-Sync)技术。当Master上事务提交时,在两阶段提交的COMMIT阶段会等待至少一个Slave将该Binlog拉取到本地并落盘才会返回。设计上认为这样Binlog就在Master和至少一个Slave上落盘了,那么就说主备一致了。由于前面说的Binlog不一定真正的落盘了,所以这种说法只是自欺欺人了。
此外,在细节上slave拉Binlog的时机是在Master的Binlog刷盘之前还是之后也有讲究,其丢数据的风险是不一样的。详情查看MySQL参数rpl_semi_sync_master_wait_point。
综上所述,MySQL的Master实例或者Slave实例宕机后再起来,主备同步可能会因为主备的数据出现不一致而中断,这个备库即使提供了服务也更加难以保证数据跟宕机之前的Master实例的数据强一致。 当然,MySQL的Slave还有个特点就是可以修改。如果DBA发现数据不一致,可以将Slave数据修改为一致,或者直接将这个同步跳过有问题的事务日志。由于备库数据和同步机制都可以人工修改,这也是MySQL主从复制在数据安全方面不靠谱的最大原因。
1.1.8. AliSQL在数据安全方面的探索
1.1.8.1. 主备切换时的回滚与回补
虽然MySQL在数据安全方面不靠谱,但并不妨碍它的推广使用。阿里巴巴电商集团相关业务的主要关系数据库还是MySQL(即AliSQL)。
阿里业务每个实例都是Master-Master架构,应用通过TDDL连接实例,默认只会读写其中一个Master实例。DBA开发了一个守护产品ADHA负责做高可用。当老Master实例宕机后,业务要求是可用性优先。因此ADHA在切换的时候会判断Slave和Master的同步状态以及延时,允许在一定延时范围内发起主备切换。
ADHA在主备切换后,如果老实例恢复了,ADHA会比对老Master和新Master实例的Binlog差异,找出没有传输到新master的那部分差异Binlog,生成对应的反向SQL(类似Undo),在老实例上执行反向SQL(称为回滚),在新实例上执行正向SQL(称为回补)。然后自动修复双向复制链路。当然,执行的时候会判断前后镜像数据,如果数据已经在新实例被修改,回补就会失败记录日志。当AliSQL实例启用semi-sync后,这个回补通常就不需要了。
此外ADHA还会针对复制中断的常见错误自动修复备库数据让同步链路恢复。如今ADHA还支持一主多备之间的高可用。
回滚与回补只是进一步降低了主备切换时不一致的概率,无法根本解决MySQL主备可能存在不一致的问题。
1.1.8.2. MySQL的高安全模式
半同步技术会尽可能的保证Master的Binlog在提交的时候也会传输到Slave上。如果Slave出现故障或者网络故障时,半同步技术会降级为异步同步,这样主备之间又出现了不一致。
AliSQL曾经在半同步基础上开发了一个类似Oracle的“高安全”的同步模式。如果Slave都不可用,就将Master实例降级,只能提供读服务,不能进行写操作。理论上为了可用性考虑,也需要至少两个Slave实例。这个是采取可能牺牲可用性和性能来保证数据强一致。
这个设计也需要ADHA相应调整,在做主备切换之前要先降级去掉“高安全"同步模式。在新的备库(老的主库)实例恢复后以及主备同步正常后,再自动调整为”高安全“模式。
1.1.8.3. X-Cluster的Consensus Log
前面说了Binlog的设计是导致MySQL做不到强一致的关键原因。AliSQL For X-Cluster(AliSQL一个版本,后简称xcluster) 将Binlog模块(包括relaylog)拿掉,替换为一个叫consensuslog的日志。原有的InnoDB Redolog还在。xcluster是一个集群,至少有三个节点。不同于传统MySQL的一主两备,xcluster的三节点里,每份数据有三份,也称为三副本。其中一个Leader副本(对应于主副本),两个Follower副本(类似备副本)。Leader副本的consensus log在传输给Follower的时候使用的是Paxos协议,三个副本成员里只要有一半成员以上接受到这个consensus log并落盘,Leader副本上的事务commit流程就可以继续走下去;否则整个事务就失败(硬性限制)。 在xcluster里,leader副本如果出现故障,会从follower副本里自动选出新的leader副本,并且数据跟此前是绝对一致的。这里就不需要ADHA参与切换(选主)。不过ADHA仍然需要参与调整TDDL中一些配置,以实现客户端路由故障切换,应用就不需要修改配置。
这个跟半同步技术中的一主两备,虽然表现形式上很像,但是原理上有着根本的不同。所以xcluster在对MySQL在数据强一致方面有很大的创新。2017年双11,电商的库存数据库就是在xcluster上,横跨张北(3节点)、上海(1节点)和深圳(1节点)三地机房,跟TDDL一起提供了异地多活能力。
1.1.8.4. PolarDB使用Redo做主从同步
POLARDB是阿里云数据库团队研发的基于第三代云计算架构下的商用关系型云数据库产品。架构如下
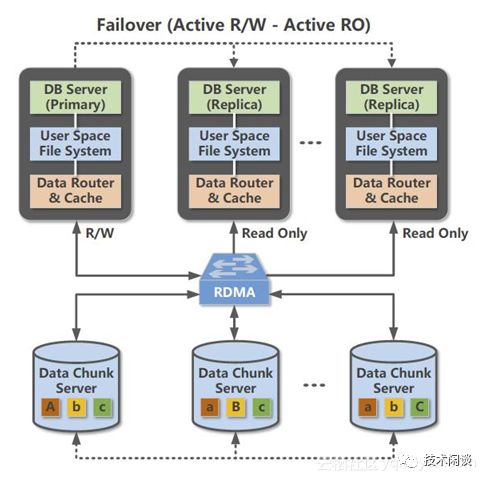
PolarDB的创新点很多,这里只看它事务日志部分。 PolarDB将从两个维度出发,从根本上改进多副本复制。一个是把网络、存储硬件提供的DMA能力串起,用硬件通道把主库的日志数据持久化到三个存储节点的磁盘中;另一个是实现了高效的只读节点,在主库和只读节点之间通过物理复制同步数据,直接更新到只读节点的内存里并应用。PolarDB也保留了Binlog(可选),不过只是为了兼容第三方程序,Binlog不再用于实例恢复和主备复制。
所以,PolarDB从根本上改变了MySQL主备可能不是强一致的问题。
后记
总结一下,分析一个数据库是否真的能做到不丢数据(RPO=0),关键看以下几点:是否支持WAL(Write-Ahead Logging)?
事务日志如何持久化到本地磁盘?
事务日志如何持久化到其他节点(即副本同步如何做)?
下篇会继续分析蚂蚁的OceanBase作为一款完全自主研发的分布式关系型数据库,是如何做到绝对不丢数据的。 如果觉得本文有帮助,就帮忙点赞(好看)吧 _
参考Linux 中直接 I/O 机制的介绍 https://www.ibm.com/developerworks/cn/linux/l-cn-directio/
Introduction to Oracle Data Guard https://docs.oracle.com/cd/B19306_01/server.102/b14239/concepts.htm#g1049956
MySQL源码解读之事务提交过程 https://www.cnblogs.com/cchust/p/3295547.html
6倍性能差100TB容量,阿里云POLARDB如何实现 https://yq.aliyun.com/articles/214367
原文地址:https://blog.csdn.net/weixin_36081485/article/details/113289315
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.taodudu.cc/news/show-3332481.html 如若内容造成侵权/违法违规/事实不符,请联系淘嘟嘟网邮箱:809451989@qq.com进行投诉反馈,一经查实,立即删除!
1.2. PITR (按时间点恢复)
1.3. ACID (事物)
1.4. MVCC (多版本并发控制)
1.5. HTAP(混合事物分析)
1.6. MPP(并行计算)
1.7. 单点登陆
单点登录(Single Sign-On,简称SSO)是一种身份验证和授权的机制,允许用户使用一组凭据(如用户名和密码)登录到多个相关但独立的软件系统或应用程序中,而只需进行一次身份验证。简而言之,用户只需要登录一次,然后就能够访问与单点登录系统相关联的多个服务,而不需要在每个服务中重新输入凭据。
1.7.1. SSO的主要优势包括:
- 1.用户便利性: 用户只需要记住一组凭据,就能够访问多个服务,减少了需要记忆多个用户名和密码的负担。
- 2.提高安全性: 通过集中的身份验证和授权,SSO可以提高系统的安全性。用户只需要在一个地方进行身份验证,减少了因为多次输入密码而可能引发的安全问题。
- 3.简化管理: 管理员可以更轻松地管理用户的访问权限,因为所有的权限信息都集中在一个系统中。
- 4.减少密码遗忘问题: 用户只需要记住一个密码,减少了由于忘记密码而需要重置密码的情况。
常见的SSO实现方式包括基于标准协议的实现,如Security Assertion Markup Language(SAML)和OpenID Connect,以及使用专门的SSO软件或服务。很多大型组织和企业在其内部系统和云服务中采用SSO,以提高用户体验和系统的整体安全性。
1.8. "To B" 和 "To C"
1.8.1. "To B" 和 "To C" 是两个商业术语,用于描述不同的商业市场和目标客户群体。
1.8.1.1. To B (B2B - Business to Business):
"To B" 意指商业对商业,是指一家公司提供产品或服务给另一家公司的商业模式。在B2B市场中,交易通常是大规模的、面向企业的,涉及到供应链、批发和其他企业间的合作。例如,一家制造商向另一家公司提供零部件,或一家软件公司向企业客户提供企业级软件服务。
1.8.1.2. To C (B2C - Business to Consumer):
"To C" 意指商业对消费者,是指一家公司直接向最终消费者提供产品或服务的商业模式。在B2C市场中,交易通常是面向个人的,公司直接与消费者进行业务往来。例如,零售商向个人客户销售商品,或在线服务提供商向个人用户提供订阅服务。
这两个术语通常用于区分企业的目标市场和业务模式。如果一家公司主要与其他公司进行业务交往,那么它被归类为B2B;如果主要与最终消费者进行交易,那么它被归类为B2C。
1.9. RPO(Recovery Point Objective)和RTO(Recovery Time Objective)
1.9.1. 是与灾难恢复和业务连续性有关的两个重要概念。
1.9.1.1. RPO(Recovery Point Objective):
RPO定义了在发生故障或灾难性事件时,组织可以接受的数据丢失的时间范围。换句话说,RPO确定了在灾难发生时,最多允许丢失多少时间的数据。通常,RPO的度量是以时间为单位的,例如,一个RPO为4小时的系统表示在灾难发生时,系统能够从最近的备份中还原,最多丢失4小时的数据。
1.9.1.2. RTO(Recovery Time Objective):
RTO是指在发生故障或灾难性事件时,系统或服务需要恢复正常运行所需的时间。RTO确定了从灾难事件发生到系统完全恢复运行所经过的时间。RTO是一个关键的指标,影响着业务的连续性和服务可用性。例如,如果一个服务的RTO为2小时,那么在发生灾难时,组织必须在2小时内将服务恢复正常运行。
这两个指标是企业制定和评估灾难恢复计划的关键要素。通过明确定义RPO和RTO,组织可以更好地规划和实施灾难恢复策略,以确保在不可预测的事件发生时,能够最小化数据丢失并迅速恢复业务操作
1.10. TCP和UDP
TCP(传输控制协议)和UDP(用户数据报协议)是两种用于在计算机网络中传输数据的不同协议,它们有一些关键的区别:
1.10.1. 连接性:
TCP: 提供面向连接的服务。在数据传输之前,必须先建立一个TCP连接,然后再进行数据传输。连接是可靠的,数据会被按序传递,并且会进行错误检测和重传。
UDP: 是一种面向无连接的协议。UDP发送数据之前不需要建立连接,也不保证数据的可靠性和按序传递。UDP更适用于实时性要求较高的应用。
1.10.2. 可靠性:
TCP: 提供可靠的、面向连接的服务。它确保数据的完整性,会重传丢失的数据,并按照顺序传递数据。
UDP: 不提供可靠性。数据被尽最大努力传递,但不保证可靠性和数据的按序传递。
1.10.3. 流量控制:
TCP: 具有流量控制机制,可以防止发送方发送过多的数据导致接收方无法处理。
UDP: 没有流量控制机制,发送方会尽可能快地发送数据。
1.10.4. 头部开销:
TCP: 有较大的头部开销,包含大量控制信息,例如序列号、确认号、窗口大小等。
UDP: 头部较小,仅包含基本的必要信息。
1.10.5. 应用场景:
TCP: 适用于需要可靠数据传输、数据按序传递的应用,例如文件传输、电子邮件、Web浏览等。
UDP: 适用于对实时性要求较高,可以容忍一些数据丢失的应用,例如音频和视频流、在线游戏等。
QPS
1. QPS(Queries Per Second)
QPS 是指每秒查询次数,用于衡量数据库系统在单位时间内能够处理的查询请求数量。它是评估数据库性能的一个重要指标,尤其是在高并发场景下。
特点
- 衡量查询性能:QPS 主要反映数据库处理查询请求的能力,包括读操作(如 SELECT)。
- 高并发场景:在高并发环境下,QPS 能够直观地反映数据库的负载能力和响应速度。
- 单位:QPS 的单位是“次/秒”,表示每秒可以处理的查询请求数量。
示例
如果一个数据库系统在 10 秒内处理了 1000 次查询请求,那么它的 QPS 为:
QPS= 1000 次/10 秒 =100 次/秒
TPS
2. TPS(Transactions Per Second)
TPS 是指每秒事务处理次数,用于衡量数据库系统在单位时间内能够处理的事务数量。TPS 是评估数据库事务处理能力的重要指标,尤其是在涉及复杂事务处理的场景中。
特点
- 衡量事务性能:TPS 主要反映数据库处理事务的能力,包括写操作(如 INSERT、UPDATE、DELETE)。
- 复杂事务处理:TPS 能够反映数据库在处理复杂事务时的性能,尤其是在涉及多个步骤的事务中。
- 单位:TPS 的单位是“次/秒”,表示每秒可以处理的事务数量。
示例
如果一个数据库系统在 10 秒内处理了 500 次事务,那么它的 TPS 为:
TPS= 500 次/10 秒 =50 次/秒
TPC-C
TPC-C(Transaction Processing Performance Council Benchmark C)
TPC-C 是由事务处理性能委员会(Transaction Processing Performance Council,TPC)制定的一种基准测试标准,用于评估数据库系统的事务处理性能。TPC-C 模拟了一个典型的订单处理系统,包含多种事务类型,如新订单、支付、订单状态查询等。
特点
- 综合性能评估:TPC-C 不仅评估数据库的事务处理能力,还评估系统的整体性能,包括硬件、软件和网络等。
- 多种事务类型:TPC-C 包含多种事务类型,能够全面评估数据库在复杂业务场景下的性能。
- 标准化测试:TPC-C 是一个标准化的基准测试,结果具有可比性,适用于不同数据库系统的性能对比。
- 单位:TPC-C 的性能结果通常以 TPS(每秒事务处理次数)表示。
示例
假设一个数据库系统在 TPC-C 测试中,每秒能够处理 1000 次事务,那么它的 TPC-C 性能为 1000 TPS。
总结
- QPS:每秒查询次数,主要用于衡量数据库的查询性能。
- TPS:每秒事务处理次数,主要用于衡量数据库的事务处理能力。
- TPC-C:一种综合性能评估标准,通过模拟复杂的业务场景来评估数据库系统的整体性能,结果以 TPS 表示。
通过这些指标,可以全面评估数据库系统的性能,特别是在高并发和复杂事务处理场景下。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号