

参数配置
GreenPlum关键参数详解
- GreenPlum关键参数详解
- Greenplum参数配置优化:
- 常用参数和配置建议
- work_mem
- mainteance_work_mem
- max_statement_mem
- statement_mem
- gp_vmem_protect_limit
- gp_vmem_protect_limit参数说明
- gp_workfile_limit_files_per_query
- gp_statement_mem
- effective_cache_size
- gp_resqueue_priority_cpucores_per_segment
- max_connections
- max_prepared_transactions
- max_files_per_process
- shared_buffers
- gp_fts_probe_threadcount:
- gp_workfile_compression
- 常用参数和配置建议
- 内存消耗参数
- Greenplum参数配置优化:
- 主要影响vacuum,analyze,create index等操作,默认值为64MB,设置大一点可以加速上述操作
- 共享内存参数,可以缓存表数据、索引和查询计划,默认为125MB,设置大一点,但是需要满足公式:(num_instances_per_host * ( shared_buffers + other_seg_shmem )) + other_app_shared_mem other_seg_shmem:segment为111MB,master为79MB
Greenplum参数配置优化:
查询参数语法
gpconfig --show max_connections
修改参数配置命令
gpconfig-c <parameter name> -v <parameter value> 比如:gpconfig-c log_statement -v DDL 删除配置 gpconfig -r <parameter name>
常用参数和配置建议
work_mem
work_mem(,global,物理内存的2%-4%),segment用作sort,hash操作的内存大小
当PostgreSQL对大表进行排序时,数据库会按照此参数指定大小进行分片排序,将中间结果存放在临时文件中,这些中间结果的临时文件最终会再次合并排序,所以增加此参数可以减少临时文件个数进而提升排序效率。当然如果设置过大,会导致swap的发生,所以设置此参数时仍需谨慎。
查看现有配置值
gpconfig -s work_mem
Values on all segments are consistent
GUC : work_mem
Master value: 32MB
Segment value: 32MB
修改配置
gpconfig -c work_mem -v 128MB
另一种写法:SET work_mem TO '64MB' 配置成功返回: gpadmin-[INFO]:-completed successfully with parameters
mainteance_work_mem
global,CREATE INDEX, VACUUM等时用到,segment用于VACUUM,CREATE INDEX等操作的内存大小,缺省是16兆字节(16MB)。因为在一个数据库会话里, 任意时刻只有一个这样的操作可以执行,并且一个数据库安装通常不会有太多这样的工作并发执行, 把这个数值设置得比work_mem更大是安全的。 更大的设置可以改进清理和恢复数据库转储的速度。
查看现有配置值
gpconfig -s maintenance_work_mem
GUC : maintenance_work_mem
Master value: 64MB
Segment value: 64MB 修改配置 gpconfig -c maintenance_work_mem -v 256MB
max_statement_mem
设置每个查询最大使用的内存量,该参数是防止statement_mem参数设置的内存过大导致的内存溢出.
查看现有配置值
gpconfig -s max_statement_mem
Values on all segments are consistent
GUC : max_statement_mem
Master value: 2000MB Segment value: 2000MB 修改配置 gpconfig -c max_statement_mem -v 2000MB
statement_mem
设置每个查询在segment主机中可用的内存,该参数设置的值不能超过max_statement_mem设置的值,如果配置了资源队列,则不能超过资源队列设置的值。
服务器配置参数是分配给segment数据库中任何单个查询的内存量。
如果一个 语句要求额外的内存,它将溢出到磁盘。用下面的公式计算statement_mem的值:
(gp_vmem_protect_limit * .9) / max_expected_concurrent_queries
=(8*0.9)/
例如,如果gp_vmem_protect_limit被设置为8GB(8192MB),对于40个并发查询, statement_mem的计算可以是:
(8192MB * .9) / 40 = 184MB
在每个查询被溢出到磁盘之前,它被允许使用184MB内存。
要安全地增加statement_mem的值,用户必须增加gp_vmem_protect_limit 或者减少并发的查询数量。要增加gp_vmem_protect_limit,
用户必须增加物理RAM或者交换空间, 也可以减少每台主机上的segment数量。
注意在集群中增加segment主机无助于内存不足错误,除非用户使用额外的主机来减少每台主机上的segment数量。
当不能提供足够的内存来映射所有的输出时,才会创建溢出文件。通常发生在缓存空间占据达到80%以上时。
使用statement_mem分配每个segment数据库中一个查询所使用的内存。如果要求额外的内存, 将会溢出到磁盘。按照下面的方式为statement_mem设置最优值
(vmprotect * .9) / max_expected_concurrent_queries
查看现有配置值
gpconfig -s statement_mem
Values on all segments are consistent
GUC : statement_mem
Master value: 125MB Segment value: 125MB 修改配置 gpconfig -c statement_mem -v 256MB
gp_vmem_protect_limit
控制了每个segment数据库为所有运行的查询分配的内存总量。如果查询需要的内存超过此值,则会失败。
gp_vmem_protect_limit 显示每个节点所有语句使用内存的上限,计算公式
(SWAP + (RAM * vm.overcommit_ratio)) * 0.9 / number_Segments_per_server
建议:
(物理内存*90%)/每台主机上的primary数量
例如: 64G内存的每台主机有 2primary+2mirror
(64*0.9)/2
查看现有配置值
gpconfig -s gp_vmem_protect_limit
Values on all segments are consistent
GUC : gp_vmem_protect_limit
Master value: 8192 Segment value: 8192
gpconfig -c gp_vmem_protect_limit -m 12288 -v 12288
gpstop -u
gp_vmem_protect_limit参数说明
1)在启用了基于资源队列的资源管理系统时,gp_vmem_protect_limit参数表示每个segment分配到的内存大小。预估值计算方式:所有GP数据库进程可用内存大小/发生故障时最大的primary segment个数。如果gp_vmem_protect_limit设置过高,则查询可能会失败。
2)该参数单位为MB
3)该参数推荐值计算方法:
先计算gp_vmem值,若总内存小于256GB:
gp_vmem = ((SWAP + RAM) – (7.5GB + 0.05 * RAM)) / 1.7
若总内存大于256GB:
gp_vmem = ((SWAP + RAM) – (7.5GB + 0.05 * RAM)) / 1.17
以内存为32G+SWAP16G为列,(每个节点上4个实例,两主两从,那么最多可能有4个实例全部是primary实例)
(48-7.5+0.05*32)/1.7
=22.8
再计算max_acting_primary_segments:当mirror segment启动后,可以在主机上运行primary segment最大个数。块镜像配置下,比如4台主机,每个主机上8个primary segment:SDW2坏掉,会导致SDW3上对应的3个mirror提升主提供服务,也就是说一个主机上最多8+3=11个primary segment(SDW1有2个mirror提升主,SDW4有3个mirror提升主)。
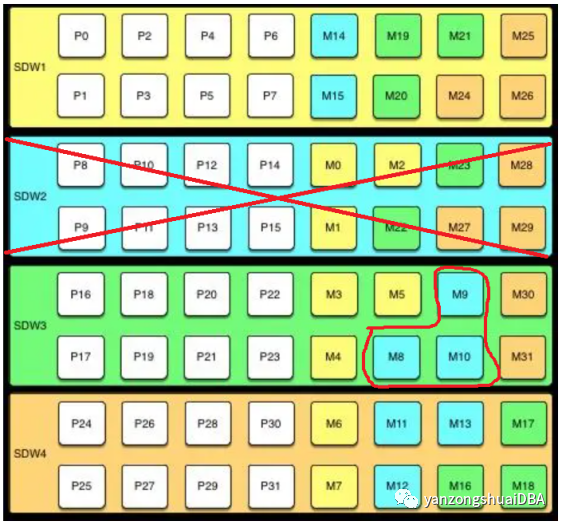
最后计算gp_vmem_protect_limit值:
gp_vmem_protect_limit = <gp_vmem> / <acting_primary_segments>
gp_vmem_protect_limit=22.8/4
gp_workfile_limit_files_per_query
SQL查询分配的内存不足,Greenplum数据库会创建溢出文件(也叫工作文件)。在默认情况下,一个SQL查询最多可以创建 100000 个溢出文件,这足以满足大多数查询。
该参数决定了一个查询最多可以创建多少个溢出文件。0 意味着没有限制。限制溢出文件数据可以防止失控查询破坏整个系统。
查看现有配置值
gpconfig -s gp_workfile_limit_files_per_query
Values on all segments are consistent
GUC : gp_workfile_limit_files_per_query
Master value: 100000 Segment value: 100000
gp_statement_mem
服务器配置参数 gp_statement_mem 控制段数据库上单个查询可以使用的内存总量。如果语句需要更多内存,则会溢出数据到磁盘。
建议
(gp_vmem_protect_limit*0.9) /segment数据库上最大查询数。
effective_cache_size
(master节点,可以设为物理内存的85%)
这个参数告诉PostgreSQL的优化器有多少内存可以被用来缓存数据,以及帮助决定是否应该使用索引。这个数值越大,优化器使用索引的可能性也越大。因此这个数值应该设置成shared_buffers加上可用操作系统缓存两者的总量。通常这个数值会超过系统内存总量的50%以上。
查看现有配置值:
gpconfig -s effective_cache_size
Values on all segments are consistent
GUC : effective_cache_size
Master value: 512MB Segment value: 512MB 修改配置 gpconfig -c effective_cache_size -v 40960MB
gp_resqueue_priority_cpucores_per_segment
master和每个segment的可以使用的cpu个数,每个segment的分配线程数;
每个segment分配的分配的cpu的个数,例如:在一个20核的机器上有4个segment,则每个segment有5个核,而对于master节点则是20个核,master节点上不运行segment的信息,因此master反映了cpu的使用情况
按照不同集群的核数以及segment修改此参数即可,下面的实例是修改成8核
查看现有配置值
gpconfig -s gp_resqueue_priority_cpucores_per_segment
Values on all segments are consistent
GUC : gp_resqueue_priority_cpucores_per_segment
Master value: 4 Segment value: 4 gpconfig -s checkpoint_segments 修改配置 gpconfig -c gp_resqueue_priority_cpucores_per_segment -v 8
max_connections
限制并发连接
要限制对Greenplum数据库系统的活动并发会话的数量,用户可以配置max_connections服务器配置参数。这是一个本地参数,意味着用户必须在Master、后备Master和每个Segment实例(主Segment和镜像Segment)的postgresql.conf文件中设置它。Segment上max_connections的值必须是Master上该值的5-10倍。
在用户设置max_connections时,还必须设置依赖参数max_prepared_transactions。在Master上,这个值必须被设置为至少和max_connections值一样大,而在Segment实例上应该设置为和Master上一样的值。
在$MASTER_DATA_DIRECTORY/postgresql.conf(包括后备Master)中:
max_connections=100
max_prepared_transactions=100
在所有Segment实例的SEGMENT_DATA_DIRECTORY/postgresql.conf中:
max_connections=500
max_prepared_transactions=100
Note: 注意: 调高这些参数的值可能会导致Greenplum数据库请求更多共享内存。为了缓和这种影响,考虑降低其他内存相关的参数,例如 gp_cached_segworkers_threshold。
要更改允许的连接数:
最大连接数,Segment建议设置成Master的5-10倍。
max_connections = 200 #(master、standby)
max_connections = 1200 #(segment)
查看现有配置值:
gpconfig -s max_connections
GUC : max_connections
Master value: 250
Segment value: 750 修改配置 gpconfig -c max_connections -v 1200 -m 300
调整过程:
1.停止Greenplum数据库系统:
$ gpstop
2.在Master主机上,编辑$MASTER_DATA_DIRECTORY/postgresql.conf并且更改下面两个参数:
max_connections – 想要允许的活动用户会话数加上superuser_reserved_connections的数量
max_prepared_transactions – 必须大于等于 max_connections.
3.在每个Segment实例上,编辑SEGMENT_DATA_DIRECTORY/postgresql.conf并且更改下面两个参数:
max_connections – 必须是Master上值的5-10倍。
max_prepared_transactions – 必须等于Master上的值。
4.重启Greenplum数据库系统:
$ gpstart
max_prepared_transactions
这个参数只有在启动数据库时,才能被设置。它决定能够同时处于prepared状态的事务的最大数目(参考PREPARE TRANSACTION命令)。如果它的值被设为0。则将数据库将关闭prepared事务的特性。它的值通常应该和max_connections的值一样大。每个事务消耗600字节(b)共享内存。
查看现有配置值:
gpconfig -s max_prepared_transactions
Values on all segments are consistent
GUC : max_prepared_transactions
Master value: 250 Segment value: 250 修改配置 gpconfig -c max_prepared_transactions -v 300
max_files_per_process
设置每个服务器进程允许同时打开的最大文件数目。缺省是1000。 如果内核强制一个合理的每进程限制,那么你不用操心这个设置。 但是在一些平台上(特别是大多数BSD系统), 内核允许独立进程打开比个系统真正可以支持的数目大得多得文件数。 如果你发现有"Too many open files"这样的失败现像,那么就尝试缩小这个设置。 这个值只能在服务器启动的时候设置。
查看现有配置值:
gpconfig -s max_files_per_process
Values on all segments are consistent
GUC : max_files_per_process
Master value: 1000 Segment value: 1000 修改配置 gpconfig -c max_files_per_process -v 1000
shared_buffers
只能配置segment节点,用作磁盘读写的内存缓冲区,开始可以设置一个较小的值,比如总内存的15%,然后逐渐增加,过程中监控性能提升和swap的情况。
gpconfig -s shared_buffers
Values on all segments are consistent
GUC : shared_buffers
Master value: 64MB Segment value: 125MB 修改配置 gpconfig -c shared_buffers -v 1024MB gpconfig -r shared_buffers -v 1024MB
temp_buffers: 即临时缓冲区,拥有数据库访问临时数据,GP中默认值为1M,在访问比较到大的临时表时,对性能提升有很大帮助。
查看现有配置值:
gpconfig -s temp_buffers
Values on all segments are consistent
GUC : temp_buffers
Master value: 1024 Segment value: 1024 修改配置 gpconfig -c temp_buffers -v 4096
gp_fts_probe_threadcount:
设置ftsprobe线程数,此参数建议大于等于每台服务器segments的数目。
查看现有配置值:
gpconfig -s gp_fts_probe_threadcount
Values on all segments are consistent
GUC : gp_fts_probe_threadcount
Master value: 16 Segment value: 16
重启数据库,使参数生效
gpstop -u 重新加载配置文件 postgresql.conf 和 pg_hba.conf
转载于:https://www.cnblogs.com/kuang17/p/9968415.html
gp_workfile_compression
如果有很多溢出文件,则设置gp_workfile_compression来压缩这些溢出文件。 压缩溢出文件可能有助于避免IO操作导致磁盘子系统过载。
当你的系统中存在大表间的hash聚合或者hash连接操作,内存无法缓冲相应数据时,就需要溢出到临时空间(类似ORACLE的临时表空间,只不过GP就是文件目录罢了)。指定参数gp_workfile_compress_algorithm可以对溢出数据进行压缩,在IO密集的环境中,该参数的设置可以帮助系统提升10%~20%的性能。
该参数有两个值可以设置
none 默认值,表示不用压缩选项
zlib 使用zlib算法压缩
该参数只需要在master上修改,只需重新reload参数文件,即可生效。它也可以在不同连接会中动态设置。
statement_timeout
控制语句执行时长,单位是ms。超过设定值,该语句将被中止。
不推荐在postgresql.conf中设置,因为会影响所有的会话,如非要设置,应该设置一个较大值。
lock_timeout
锁等待超时。语句在试图获取表、索引、行或其他数据库对象上的锁时等到超过指定的毫秒数,该语句将被中止。
不推荐在postgresql.conf中设置,因为会影响所有的会话。
内存消耗参数
这些参数控制系统的内存使用,可以通过调整gp_vmem_protect_limit来避免segment hosts在查询过程中内存耗尽。
gp_vmem_protect_limit:
默认8192,内存资源限制。计算公式为(x单台机器物理内存)/主segment数目。x为1到1.5之间。例如物理机126G内存,主segment16个。(1126)/16=7.875GB.7.875*1024=7971MB,则该值设置为7971。 当查询需要的内存达到这个上限,内存不能够再分配,将导致查询失败
gp_vmem_protect_segworker_cache_limit:
cache限制,当查询执行器消耗的内存超过这个上限,这个过程不会缓存下来,不会为后续的查询提供缓存。默认500MB。如果系统有大量的连接或者是空闲的进程,可以减小这个上限来释放内存。
gp_workfile_limit_files_per_query:
每个查询最大可使用的tmp spill file数目,当超过上限时查询终止。默认100000,设置为0为不限制。(在执行查询时,当需要的内存大于给分配的内存时就会在硬盘上产生spill files)
max_prepared_transactions:
该值至少要和master的最大连接数相等。设置处于准备好状态的事务数,master和segement的该配置项要相等。默认250.
max_stack_depth:
声明服务器的执行栈的最大安全深度。该值不要超过ulimit -s得出来的值,最好比ulimit -s小于1024。默认2MB。
shared_buffers:默认128MB,共享缓冲区。至少是128KB并且至少是max_connections的16K倍。
maintenance_work_mem = 2GB
主要影响vacuum,analyze,create index等操作,默认值为64MB,设置大一点可以加速上述操作
shared_buffers = 6GB
共享内存参数,可以缓存表数据、索引和查询计划,默认为125MB,设置大一点,但是需要满足公式:(num_instances_per_host * ( shared_buffers + other_seg_shmem )) + other_app_shared_mem other_seg_shmem:segment为111MB,master为79MB
常用的优化参数
work_mem
work_mem(,global,物理内存的2%-4%),segment用作sort,hash操作的内存大小 当PostgreSQL对大表进行排序时,数据库会按照此参数指定大小进行分片排序,将中间结果存放在临时文件中,这些中间结果的临时文件最终会再次合并排序,所以增加此参数可以减少临时文件个数进而提升排序效率。当然如果设置过大,会导致swap的发生,所以设置此参数时仍需谨慎。刚开始可设置总内存的5%
[gpadmin@mdw ~]$ gpconfig -s maintenance_work_mem
Values on all segments are consistent
GUC : maintenance_work_mem
Master value: 64MB
Segment value: 64MB
[gpadmin@mdw ~]$
max_statement_mem
设置每个查询最大使用的内存量,该参数是防止statement_mem参数设置的内存过大导致的内存溢出.
[gpadmin@mdw ~]$ gpconfig -s max_statement_mem
Values on all segments are consistent
GUC : max_statement_mem
Master value: 2000MB
Segment value: 2000MB
[gpadmin@mdw ~]$
gp_vmem_protect_limit
控制了每个segment数据库为所有运行的查询分配的内存总量。如果查询需要的内存超过此值,则会失败。
[gpadmin@mdw ~]$ gpconfig -s gp_vmem_protect_limit
Values on all segments are consistent
GUC : gp_vmem_protect_limit
Master value: 16384
Segment value: 16384
[gpadmin@mdw ~]$
gp_workfile_limit_files_per_query
SQL查询分配的内存不足,Greenplum数据库会创建溢出文件(也叫工作文件)。在默认情况下,一个SQL查询最多可以创建 100000 个溢出文件,这足以满足大多数查询。 该参数决定了一个查询最多可以创建多少个溢出文件。0 意味着没有限制。限制溢出文件数据可以防止失控查询破坏整个系统。
gpconfig -s gp_workfile_limit_files_per_query
Values on all segments are consistent
GUC : gp_workfile_limit_files_per_query
Master value: 100000
Segment value: 100000
gp_statement_mem
effective_cache_size
(master节点,可以设为物理内存的85%) 这个参数告诉PostgreSQL的优化器有多少内存可以被用来缓存数据,以及帮助决定是否应该使用索引。这个数值越大,优化器使用索引的可能性也越大。因此这个数值应该设置成shared_buffers加上可用操作系统缓存两者的总量。通常这个数值会超过系统内存总量的50%以上。
查看现有配置值:
gpconfig -s effective_cache_size
Values on all segments are consistent
GUC : effective_cache_size
Master value: 512MB
Segment value: 512MB
gpconfig -c effective_cache_size -v 32GB
max_connections
最大连接数,Segment建议设置成Master的5-10倍。
max_connections = 200 #(master、standby) max_connections = 1200 #(segment)
查看现有配置值:
gpconfig -s max_connections
GUC : max_connections
Master value: 250
Segment value: 750
max_prepared_transactions
这个参数只有在启动数据库时,才能被设置。它决定能够同时处于prepared状态的事务的最大数目(参考PREPARE TRANSACTION命令)。如果它的值被设为0。则将数据库将关闭prepared事务的特性。它的值通常应该和max_connections的值一样大。每个事务消耗600字节(b)共享内存。
gpconfig -s max_prepared_transactions
Values on all segments are consistent
GUC : max_prepared_transactions
Master value: 250
Segment value: 250
max_files_per_process
设置每个服务器进程允许同时打开的最大文件数目。缺省是1000。 如果内核强制一个合理的每进程限制,那么你不用操心这个设置。 但是在一些平台上(特别是大多数BSD系统), 内核允许独立进程打开比个系统真正可以支持的数目大得多得文件数。 如果你发现有"Too many open files"这样的失败现像,那么就尝试缩小这个设置。 这个值只能在服务器启动的时候设置。
查看现有配置值:
gpconfig -s max_files_per_process
Values on all segments are consistent
GUC : max_files_per_process
Master value: 1000
Segment value: 1000
修改配置
gpconfig -c max_files_per_process -v 1000
shared_buffers
只能配置segment节点,用作磁盘读写的内存缓冲区,开始可以设置一个较小的值,比如总内存的15%,然后逐渐增加,过程中监控性能提升和swap的情况。
shared_buffers:该参数决定了 Greenplum 数据库在内存中缓存数据的大小。建议将该参数设置为总内存的 25% 左右。官方文档中建议修改为机器物理内存的1/8-1/4,书籍推荐10-25%。
此值不易设置过大,过大或导致以下错误
[WARNING]:-FATAL: DTM initialization: failure during startup recovery, retry failed, check segment status (cdbtm.c:1603),详细的配置请查看
http://gpdb.docs.pivotal.io/4390/guc_config-shared_buffers.html
gpconfig -s shared_buffers
Values on all segments are consistent
GUC : shared_buffers
Master value: 64MB
Segment value: 125MB
修改配置
gpconfig -c shared_buffers -v 1024MB
gpconfig -r shared_buffers -v 1024MB
temp_buffers
: 即临时缓冲区,拥有数据库访问临时数据,GP中默认值为1M,在访问比较到大的临时表时,对性能提升有很大帮助。
查看现有配置值:
gpconfig -s temp_buffers
Values on all segments are consistent
GUC : temp_buffers
Master value: 1024
Segment value: 1024
修改配置
gpconfig -c temp_buffers -v 4096MB
gp_fts_probe_threadcount:
设置ftsprobe线程数,此参数建议大于等于每台服务器segments的数目。
查看现有配置值:
gpconfig -s gp_fts_probe_threadcount
Values on all segments are consistent
GUC : gp_fts_probe_threadcount
Master value: 16
Segment value: 16
重启数据库,使参数生效
gpstop -u
重新加载配置文件 postgresql.conf 和 pg_hba.conf
案例:
在部署了的GreenPlum集群中进行数据查询时,发现数据量一旦大了,查询一跑就中断,提示某个segment中断了连接。
ERROR 58M01 "Error on receive from seg0 slice1 192.168.110.84:6000 pid=xxx: server closed the connection unexpectedly"
This probably means the server terminated abnormally before or while processing the request
查看master的pg_log中的日志:
seg-1 could not connect to segment: initalization of segwork group failed (cdbgang.c:237)
经过简单的分析可以猜测是内存相关参数没有优化好,因为同样的SQL查询小一点时间间隔能很快出结果。那么就从两个方面着手:
1.服务器的内存不够,导致segment中断了交互。
2.数据库参数设置不合理,导致用不了那么多内存。
针对第一个问题:
1)首先排查虚拟机的内存,发现只有8G,感觉有点少,于是加到了32G,仍然出现之前的问题。
2)那么猜想是不是系统设置的限制了内存的使用?于是使用:
prctl -n project.max-shm-memory -i project default
prctl -n project.max-sem-ids -i project default
查看了相应的设置,都很大,不需要修改。因此可以排除是系统的瓶颈,接下来查看数据库的:
1)直接打开master节点的postgresql.conf文件查看配置,发现shared_buffers及所有的参数都是默认值,优化后。重启数据库仍然有上述问题。
2)查看max_statement_mem、statement_mem、gp_vmem_protect_limit三个参数,发现在master上没有设置,估计这里有问题。
3)使用gpconfig -s statement_mem报错,提示节点中断连接。感觉这个错误报的非常蛋疼,混淆了思路,以为数据节点有误。
4)确定gp_vmem_protect_limit参数,发现是8GB,完全够了。一度陷入停滞,经过查资料和对白配置文件,发现statement_mem参数在conf文件中没有,那么很可能就是默认值了,于是进了一步操作。
5)打开数据库,执行select * from gp_settings; 查看数据库的所有配置,发现statement_mem参数为默认的128MB,因此可以肯定问题了。
6)由于gpconfig查询参数失败,就没有尝试使用gpconfig来设置参数,采用手动修改每个节点的值。重启数据库后,成功解决问题。
后记,后来通过pgconfig -c statement_mem -v 2GB发现是可以设置参数的,就是-s来查询的时候报错。rlg,手动改了那么多文件完全可以很简单搞定的······

 浙公网安备 33010602011771号
浙公网安备 33010602011771号