pandas - 常用功能函数
1.drop_duplicates函数
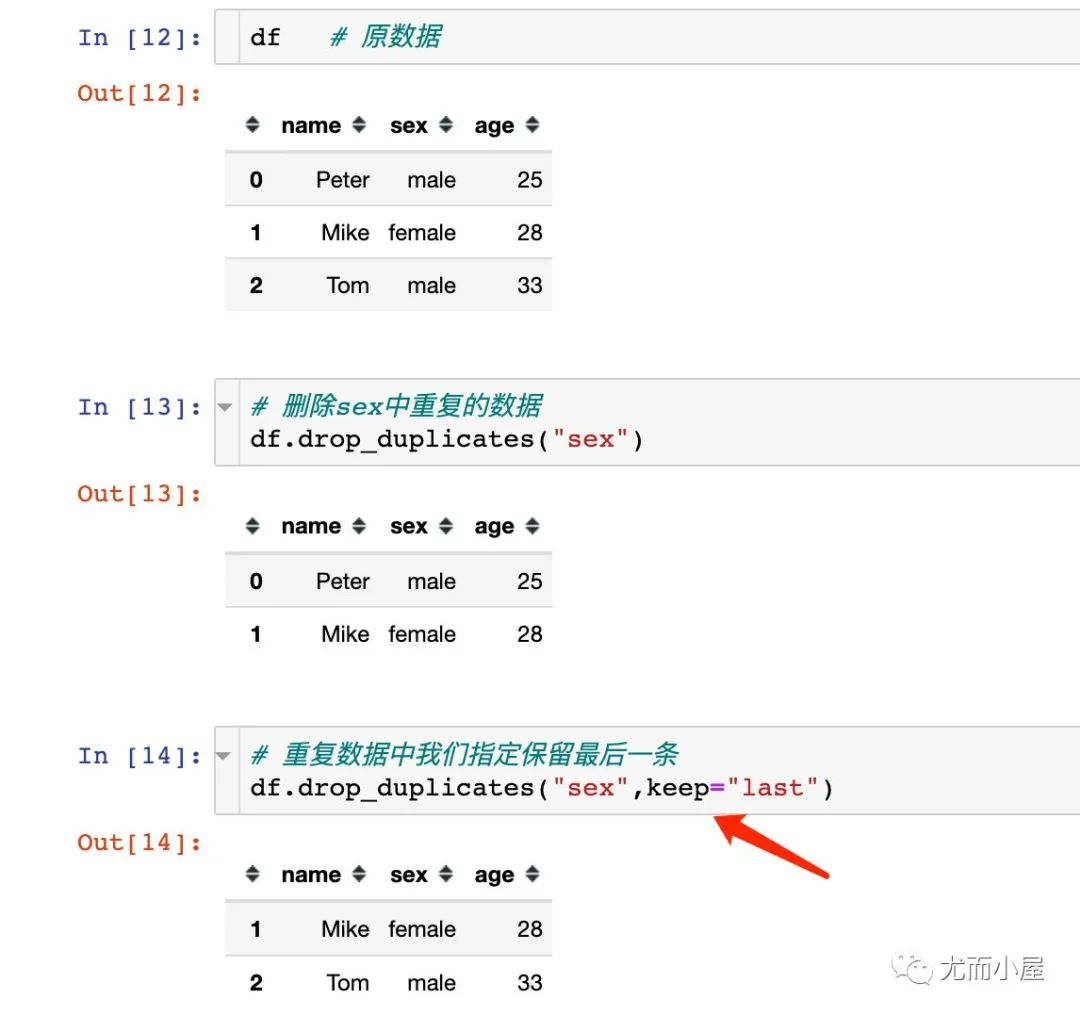
删除数据中的重复值;可以选择根据某个或者多个字段来删除。
在删除数据的时候,默认保留的是第一条重复的数据,我们可以通过参数keep来指定保留最后一条
data = [{'name': '小明', 'age': '18', 'set': 'a'},
{'name': '徐先生', 'age': '18', 'set': 'b'},
{'name': '赵先生', 'age': '18', 'set': 'c'},
{'name': '刘女士', 'age': '18', 'set': 'a'}]
df = pd.DataFrame(data)
drop_df = df.drop_duplicates('set', keep='last')
print(drop_df)
结果:
name age set
1 徐先生 18 b
2 赵先生 18 c
3 刘女士 18 a
2.contains函数
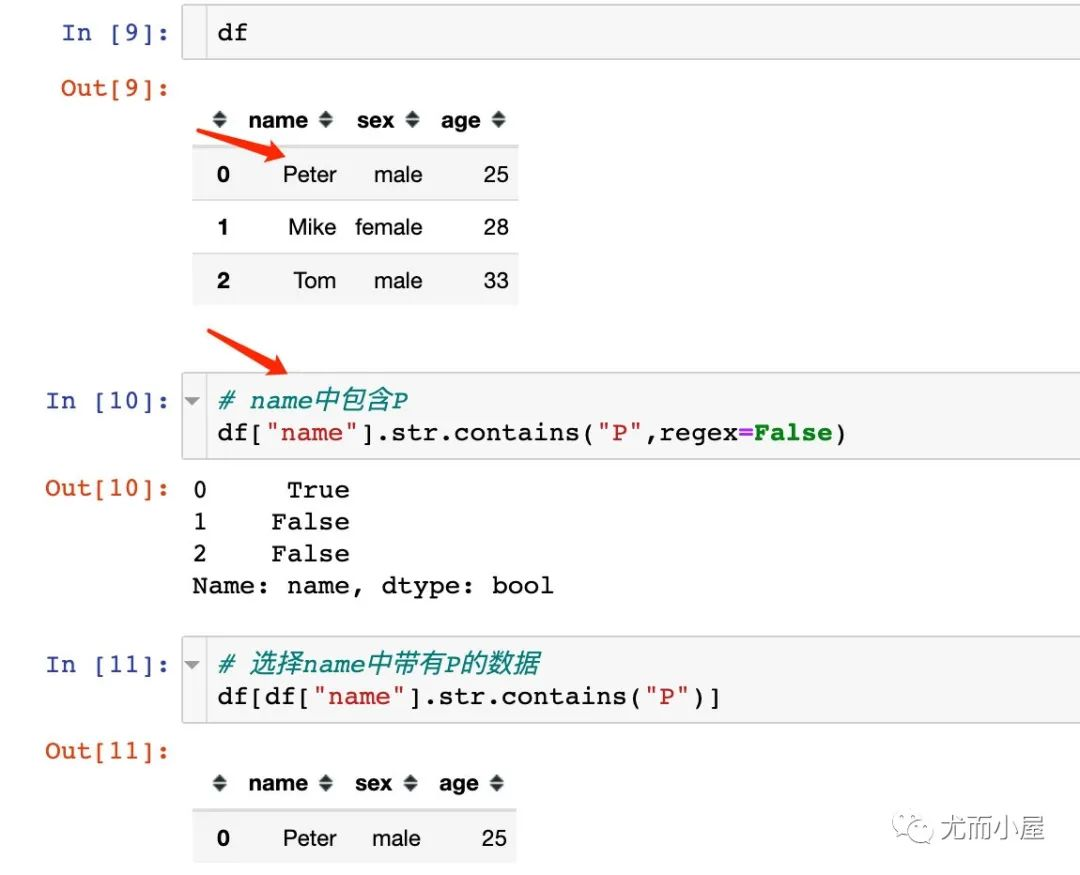
针对Series中的包含字符信息:
筛选某字段中,保函字符的信息
data = [{'name': '小明', 'age': '18', 'set': 'a'},
{'name': '徐先生', 'age': '18', 'set': 'b'},
{'name': '赵先生', 'age': '18', 'set': 'c'},
{'name': '刘女士', 'age': '18', 'set': 'a'}]
df = pd.DataFrame(data)
cont_df=df['name'].str.contains('先生', regex=False)
print(cont_df)
结果:
0 False
1 True
2 True
3 False
Name: name, dtype: bool
# 选择name中带有 ‘先生’的数据
a=df[df['name'].str.contains('先生')]
print(a)
结果:
name age set
1 徐先生 18 b
2 赵先生 18 c
3.iterrows函数
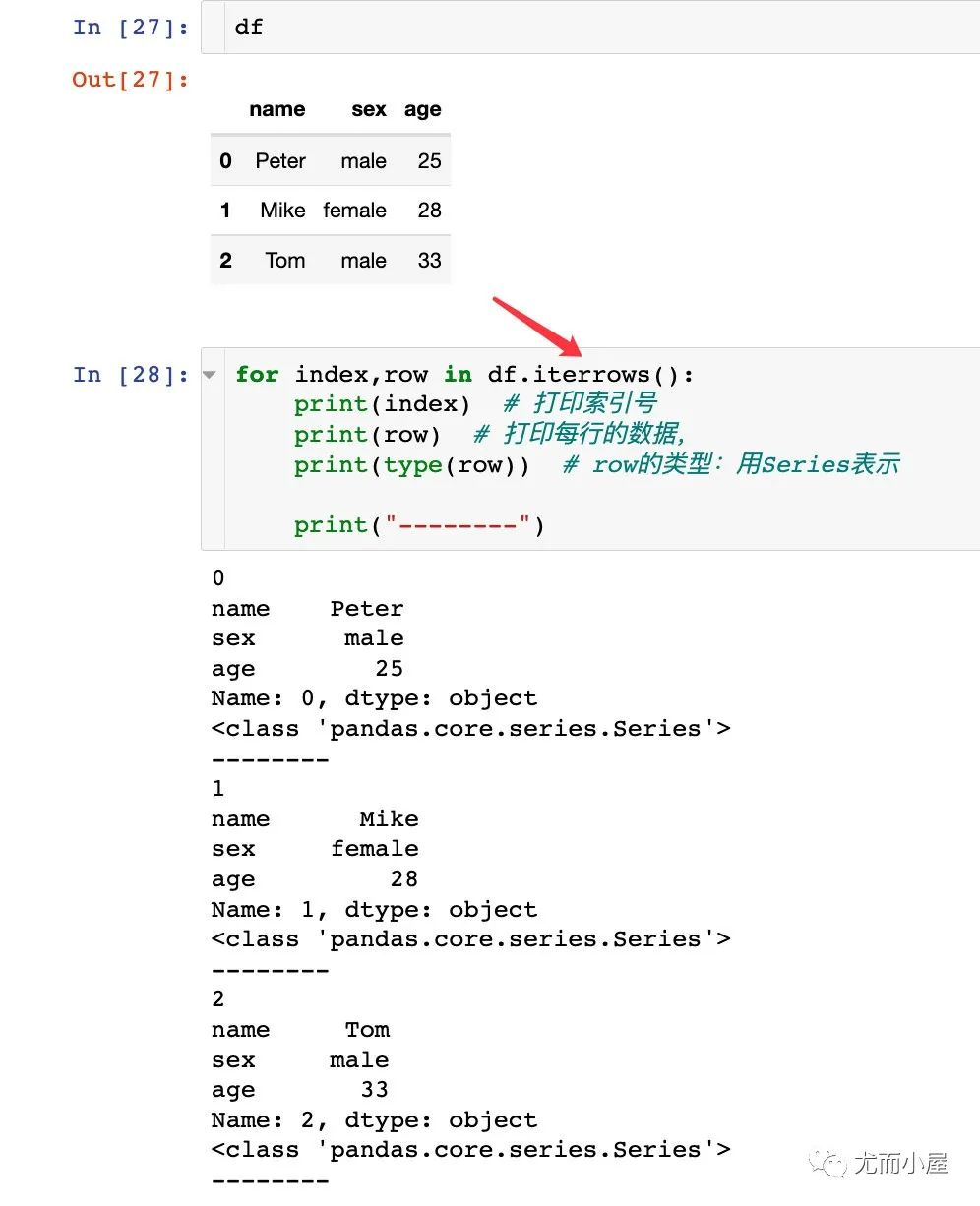
iterrows函数用于对DataFrame进行迭代循环
data = [{'name': '小明', 'age': '18', 'set': 'a'},
{'name': '徐先生', 'age': '18', 'set': 'b'},
{'name': '赵先生', 'age': '18', 'set': 'c'},
{'name': '刘女士', 'age': '18', 'set': 'a'}]
df = pd.DataFrame(data)
for index, row in df.iterrows():
print(index) # 打印索引号
print(row) # 打印每行数据
print(type(row)) # row的类型,Series表示
print(tuple(row)) # row数据转换为元组类型
print('--------')
结果:
0
name 小明
age 18
set a
Name: 0, dtype: object
<class 'pandas.core.series.Series'>
('小明', '18', 'a')
--------
1
name 徐先生
age 18
set b
Name: 1, dtype: object
<class 'pandas.core.series.Series'>
('徐先生', '18', 'b')
--------
2
name 赵先生
age 18
set c
Name: 2, dtype: object
<class 'pandas.core.series.Series'>
('赵先生', '18', 'c')
--------
3
name 刘女士
age 18
set a
Name: 3, dtype: object
<class 'pandas.core.series.Series'>
('刘女士', '18', 'a')
--------
4.join函数
join函数用于合并不同的DataFrame


5.merge函数
merge()函数,根据相同的列将两个不同的表进行合并。
import pandas as pd # 创建第一个表 df1 = pd.DataFrame({'A': [1, 2, 3], 'B': ['a', 'b', 'c'], 'C': ['x', 'y', 'z']}) # 创建第二个表 df2 = pd.DataFrame({'A': [3, 4, 5], 'D': ['m', 'n', 'o'], 'E': ['p', 'q', 'r']}) # 根据'A'列合并两个表 merged_df = pd.merge(df1, df2, on='A') print(merged_df) #
A B C D E 0 3 c z m p

 浙公网安备 33010602011771号
浙公网安备 33010602011771号