谈谈我对OpenStack的理解
摘要
OpenStack 是当今最具影响力的云计算管理工具——通过命令或者基于 Web 的可视化控制面板来管理 IaaS 云端的资源池(服务器、存储和网络)。它最先由美国国家航空航天局(NASA)和 Rackspace 在 2010 年合作研发,现在参与的人员和组织汇集了来自 100 多个国家的超过 9500 名的个人和 850 多个世界上赫赫有名的企业,如 NASA、谷歌、惠普、Intel、IBM、微软等。
OpenStack 支持 KVM、Xen、Lvc、Docker 等虚拟机软件或容器,默认为 KVM。通过安装驱动,也支持 Hyper-V 和 VMware ESXi,不过有些功能暂时不支持。
OpenStack 采用 Python 语言开发,遵循 Apache 开源协议,因此相比 CloudStack 来说,更轻量化,效率更高。
一、云计算服务模型
1.1、基础设施及服务(Infrastructure as a Service,Iaas)
云服务提供商把IT系统的基础设施层作为服务租出去,由消费者自己安装操作系统、中间件、数据库和应用程序
面向对象一般是IT管理人员
1.2、平台即服务(Platform as a Service,Paas)
云服务提供商把IT系统中的平台软件层作为服务租出去,消费者自己开发或者安装程序,并运行程序
面向对象一般是开发人员
1.3、软件即服务(Software as a Service,SaaS)
云服务提供商把IT系统中的应用软件层作为服务租出去,消费者不用自己安装应用软件,直接使用即可,这进一步降低了云服务消费者的技术门槛
面向对象一般是普通用户
二、OpenStack服务
2.1、OpenStack核心组件、可选组件以及其他组件介绍
|
分类 |
服务 |
项目名称 |
功能 |
|
核心组件 |
Compute |
Nova |
管理虚拟机的整个生命周期:创建、运行、挂起、调度、关闭、销毁等。这是真正的执行部件。接受 DashBoard 发來的命令并完成具体的动作。但是 Nova 不是虛拟机软件,所以还需要虚拟机软件(如 KVM、Xen、Hyper-v 等)配合 |
|
Network |
Neutron |
管理网络资源,提供/一组应用编程接口(API),用户可以调用它们来定义网络(如 VLAN ),并把定义好的网络附加给租户。Networking 是一个插件式结构,支持当前主流的网络设备和最新网铬技术 |
|
|
Object Storage (对象存储服务) |
Swift |
是 NoSQL 数据库,类似 HBase,为虚拟机提供非结构化数据存储,它把相同的数据存储在多台计箅机上,以确保数据不会丢失。用户可通过 RESTful 和 HTTP 类型的 API 来和它通信。这是实际的存储项目,类似 Ceph,不过在 OpcnStack 具体实施时,人们更愿意采用 Ceph。 |
|
|
Block Storage (块存储服务) |
Cinder |
管理块设备,为虚拟机管理 SAN 设备源。但是它本身不是块设备源, 需要一个存储后端来提供实际的块设备源(如 iSCSI、FC等)。 Cinder 相当于一个管家,当虚拟机需要块设备时,询问管家去哪里获取具体的块设备。它也是插件式的,安装在具体的 SAN 设备里。 |
|
|
Identity |
Keystone |
为其他服务提供身份验证、权限管理、令牌管理及服务名册管理。要使用云计算的所有用户事先需要在 Keystone 中建立账号和密码,并定义权限(注意:这里的“用户”不是指虚拟机里的系统账户,如 Windows 7 中的 Administrator )。另外,OpenStack 服务(如 Nova、Neutron、Swift、Cinder 等)也要在里面注册,并且登记具体的 API,Keystone 本身也要注册和登记 API |
|
|
Image Service |
Glance |
存取虚拟机磁盘镜像文件,Compute 服务在启动虚拟机时需要从这里获取镜像文件。这个组件不同于上面的 Swift 和 Cinder,这两者提供的 存储是在虚拟机里使用的 |
|
|
Dashboard |
Horizon |
提供了一个网页界面,用户登录后可以做这些操作:管理虚拟机、配置权限、分配 IP 地址、创建租户和用户等。本质上就是通过图形化的 操作界面控制其他服务(如 Compute、Networking 等)。当然,如果你熟悉命令,也可以直接采用命令来完成相应的任务 |
|
|
Telemetry |
Ceilometer |
结合 Aodh、CloudKitty 两个组件,完成计费任务,如结算、消耗的 资源统计、性能监控等。OpenStack 之所以能管理公共云,一是因为 Ceilometer 的存在,二是因为引人了租户的概念 |
|
|
可选组件 |
|
Heat |
如果要在成千上万个虚拟机里安装和配置同一个软件,该怎么办?采用 Orchestrates 是一个不错的主意,它向每个虚拟机里注人一个名叫 heat-cfntools 的客户端工具,然后就能同时操作很多虚拟机 |
|
|
Sahana |
使用户能够在 OpenStack 平台上(利用虚拟机)一键式创建和管理 Hadoop 集群,实现类似 AWS 的 EMR(Amazon Elastic MapReduce Service)功能。用户只需要提供简单的配置参数和模板,如版本信息(CDH 版本)、集群拓扑(几个 Slave、几个 Datanode)、节点配置信息(CPU、内存)等,Sahara 服务就能够在几分钟内根据提供的模板快速 部署 Hadoop、Spark 及 Storm 集群。Sahana 是一个大数据分析项目 |
|
|
|
Ironic |
把裸金属机器(与虚拟机相对)加人到资源池中 |
|
|
|
Zaqar |
Zaqar 为 Web 和移动开发者提供多租户云消息和通知服务,开发人员可以通过 REST API 在其云应用的不同组件中通过不同的通信模式(如 生产者/消费者或发布者/订阅者)来传递消息 |
|
|
|
Barbican |
是 OpenStack 的密钥管理组件,其他组件可以调用 Barbican 对外暴露的 REST API 来存储和访问密钥 |
|
|
|
Manila |
为虚拟机提供文件共享服务,不过需要存储后端的配合 |
|
|
其他组件 |
Congress(策略服务)、Designate(DNS 服务)、Freezer(备份及还原服务)、Magnum(容器支持)、Mistral(工作流服务)、Monasca(监控服务)、Searchlight(索引和搜索)、Senlin(集群服务)、Solum(APP集成开发平台)、Tacker(网络功能 虚拟化)、Trove(数据库服务) |
||
2.2、Openstack优势
①模块松耦合:与其他开源软件相比,OpenStack模块分明。添加独立功能的组件非常简单。有时候,不需要通读整个OpenStack的代码,只需要了解其接口规范及API使用,就可以轻松地添加一个新的模块
②组件配置较为灵活:OpenStack也需要不同的组件。但是OpenStack的组件安装异常灵活。可以全部都装在一台物理机上,也可以分散至多个物理机中,甚至可以把所有的结点都装在虚拟机中。
③二次开发容易:OpenStack发布的OpenStack API是Rest-full API。其他所有组件也是采种这种统一的规范。因此,基于OpenStack做二次开发,较为简单。而其他3个开源软件则由于耦合性太强,导致添加功能较为困难。
④兼容性:OpenStack兼容其他公有云,方便用户进行数据迁移。
⑤可扩展性:模块化设计,可以通过横向扩展,增加节点、添加资源。
三、OpenStack架构
OpenStack是由一系列具有RESTful接口的Web服务所实现的,是一系列组件服务集合。如下图为OpenStack的概念架构,我们看到的是一个标准的OpenStack项目组合的架构。这是比较典型的架构,但不代表这是OpenStack的唯一架构,我们可以选取自己需要的组件项目,来搭建适合自己的云计算平台,设计的基本原则如下:
- 按照不同的功能和通用性来划分不同项目并拆分子系统
- 按照逻辑计划、规格子系统之间的通信
- 通过分层设计整个系统架构
- 不同的功能子系统间提供统一的API接口
3.1、概念架构图
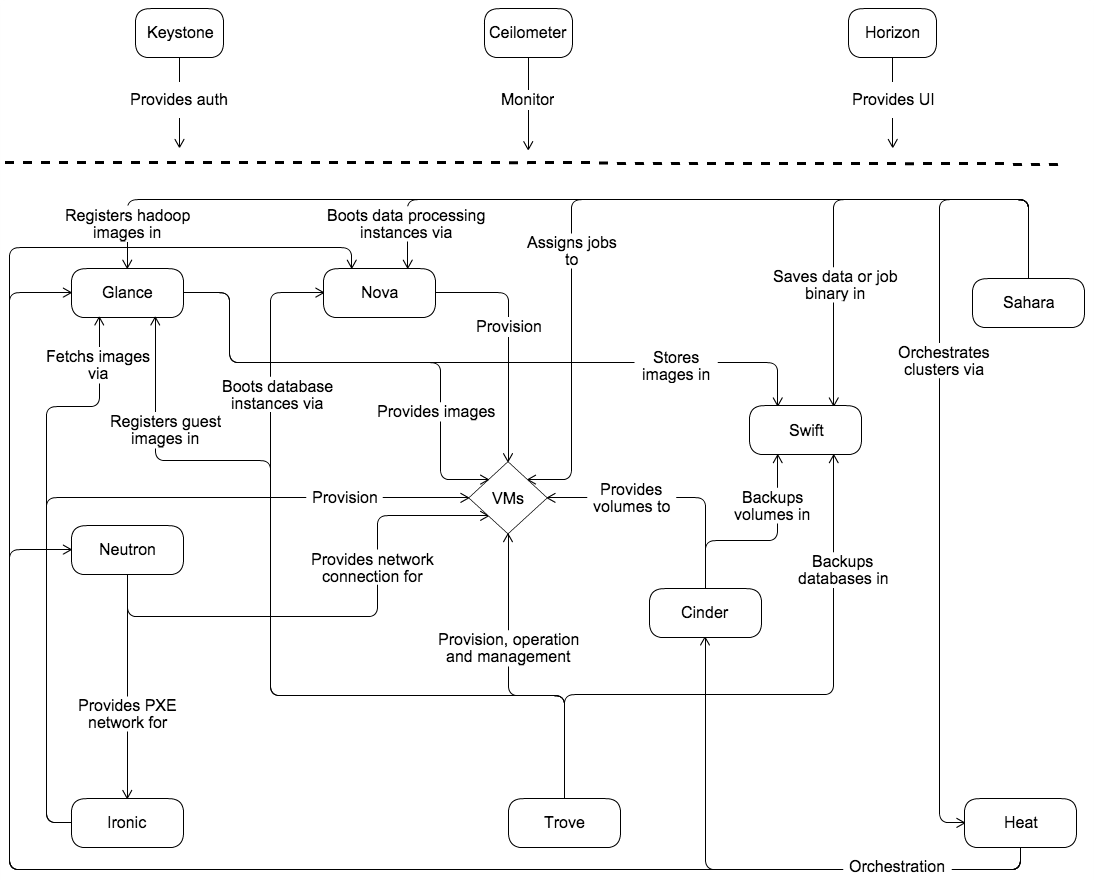
云平台用户在经过Keystone服务认证授权后,通过Horizon或者Reset API模式创建虚拟机服务,创建过程中包括利用Nova服务创建虚拟机实例,虚拟机实例采用Glance提供镜像服务,然后使用Neutron为新建的虚拟机分配IP地址,并将其纳入虚拟网络中,之后再通过Cinder创建的卷为虚拟机挂载存储块,整个过程都在Ceilometer模块资源的监控下,Cinder产生的卷(Volume)和Glance提供的镜像(Image)可以通过Swift的对象存储机制进行保存。
3.2、逻辑架构图
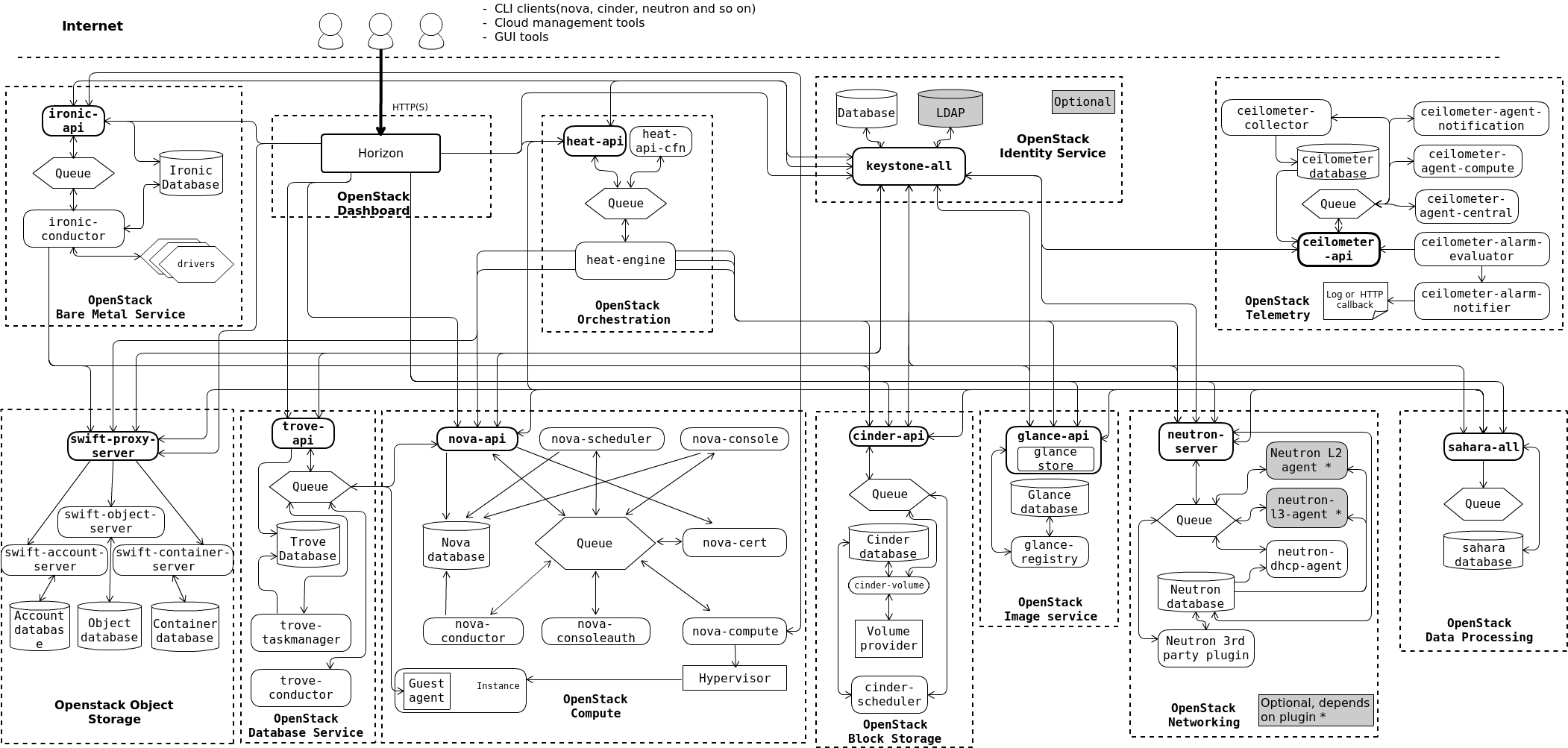
- 虽然上面这幅图看上去很复杂,但是分层去看的话,就可以较为容易的去了解它,OpenStack包括若干个服务的独立组件,像之前我们提到的核心组件以及一些可选组件都是在这幅图里面的,比如nova、keystone、Horizon等,我们先去找到这些组件,然后再去分析下一层
- 每个组件里有各自的一些服务,所有服务都需要通过keystone进行身份验证,每个服务之间又可以关联若干个组件,每个服务至少有一个API进程,通过去监听API的请求,并对这些请求进行预处理,并将它们发送到相对于该服务的其他组件,服务之间可以通过公共API进行交互
- 服务之间的通信使用AMQP消息代理,将服务的状态信息存储在数据库中
OpenStack组件通信关系:
- 基于HTTP协议进行通信:通过各项目的API建立的通信关系,API都是RESTful Web API
- 基于SQL的通信:用于各个项目内部的通信
- 基于AMQP协议的通信:用于每个项目内部各个组件之间的通信
- 通过Native API实现通信:Openstack各组件和第三方软硬件之间的通信
3.3、OpenStack物理架构
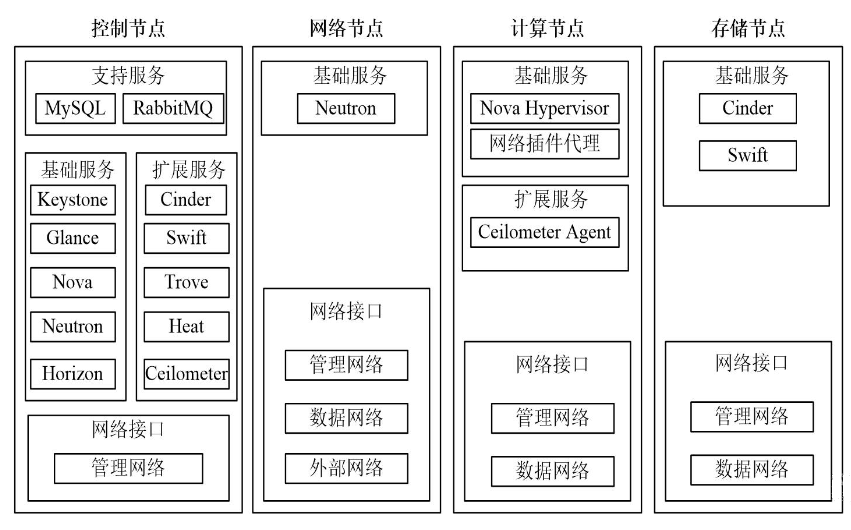
整个OpenStack是由控制节点,计算节点,网络节点,存储节点四大部分组成。
控制节点负责对其余节点的控制,包含虚拟机建立,迁移,网络分配,存储分配等等
计算节点负责虚拟机运行
网络节点负责对外网络与内网络之间的通信
存储节点负责对虚拟机的额外存储管理等等
①控制节点
控制节点包括支持服务、基础服务、扩展服务以及管理网络
- 因为控制节点是管理整个OpenStack进行运作的,所有需要keystone身份认证服务以及Harizon控制面板服务这样的全局组件来对OpenStack进行管控和操作
- 为虚拟机提供一些相对应的基础资源,比如glance镜像服务为虚拟机提供磁盘镜像文件、network网络服务对网络资源进行管理,提供/一组应用编程接口(API),用户可以调用它们来定义网络以及nova计算服务管理虚拟机的整个生命周期
- 数据的存储以及通信支持,我们使用到的是Mysql与RabbitMQ,后续我们需要对数据进行管理需要使用Cinder、Swift以及trove服务,并且提供对物理资源以及虚拟资源的监控,并记录这些数据,对该数据进行分析,在一定条件下触发相应动作的ceilometer计量服务
- 而且还需要基于模板来实现云环境中资源的初始化,依赖关系处理,部署等基本操作,也可以解决自动收缩,负载均衡等高级特性的heat服务
- 管理私有网段与公有网段的通信,以及管理虚拟机网络之间的通信/拓扑,所以需要网络接口和外面进行连通
②网络节点
只有一个基础服务,Neutron网络服务。负责整个openstack架构的网络通信。整个网络接口又可分为管理网络、数据网络、外部网络。管理网络负责关联其他节点的网络,让控制节点可管控其他节点的网络。数据网络负责整个架构的数据通信。外部网络负责架构与外部物理网络的连接通信。
③计算节点
计算节点包括基础服务、扩展服务、网络接口。基础服务有Nova Hypervisor 和网络插件代理。扩展服务为ceilometer agent 计量代理服务。网络接口为管理网络和数据网络。
④存储节点
存储节点包括cinder和swift两个基础的存储服务和网络接口。网络接口为管理网络和数据网络。
四、核心服务概述
4.1、Keystone身份认证服务
4.1.1、Keystone概念
Keystone (OpenStack Identity Service)是OpenStack中的一个独立的提供安全认证的模块,主要负责openstack用户的身份认证、令牌管理、提供访问资源的服务目录、以及基于用户角色的访问控制。
Keystone类似一个服务总线,或者说是整 个Openstack框架的注册表,其他服务通过keystone来注册其服务的Endpoint (服务访问的URL),任何服务之间相互的调用,需要经过Keystone的身 份验证,来获得目标服务的Endpoint来找到目标服务。
4.1.2、主要功能
- 身份认证:负责令牌的发放和校验
- 用户授权:授权用户有指定的可执行动作的范围
- 用户管理:管理用户的账户
- 服务目录:提供可用服务的API端点位置
4.1.3、Keystone的管理对象
Keystone服务贯穿整个架构,在进行身份认证服务的整个流程中,有几个重要的概念。
- 用户(user):指的是使用openstack架构的用户。
- 证书(credentials):用于确认用户身份的凭证,证明自己是自己,包括用户的用户名和密码,或是用户名和API密钥,或者身份管理服务提供的认证令牌。
- 认证(authentication):确定用户身份的过程。
- 项目(project):可以理解为一个人,或服务所拥有的资源的集合。
- 角色(role):用于划分权限,通过给user指定role,使user获得role对应操作权限
- 服务(service):openstack架构的组件服务,如nova、neutron、cinder、swift、glance等。
- 令牌(token):由字符串表示,作为访问资源的凭证,是用户的身份/权限证明文件;token决定了用户的权限范围,在指定的权限内进行操作;也包括令牌的有效期,在指定的时间范围内用户才有这些权限。
- 端点(endpoint):一个可以通过网络来访问和定位某个openstack service的地址,即用户创建一个项目过程中需要的各个服务资源的位置
Keystone工作流程
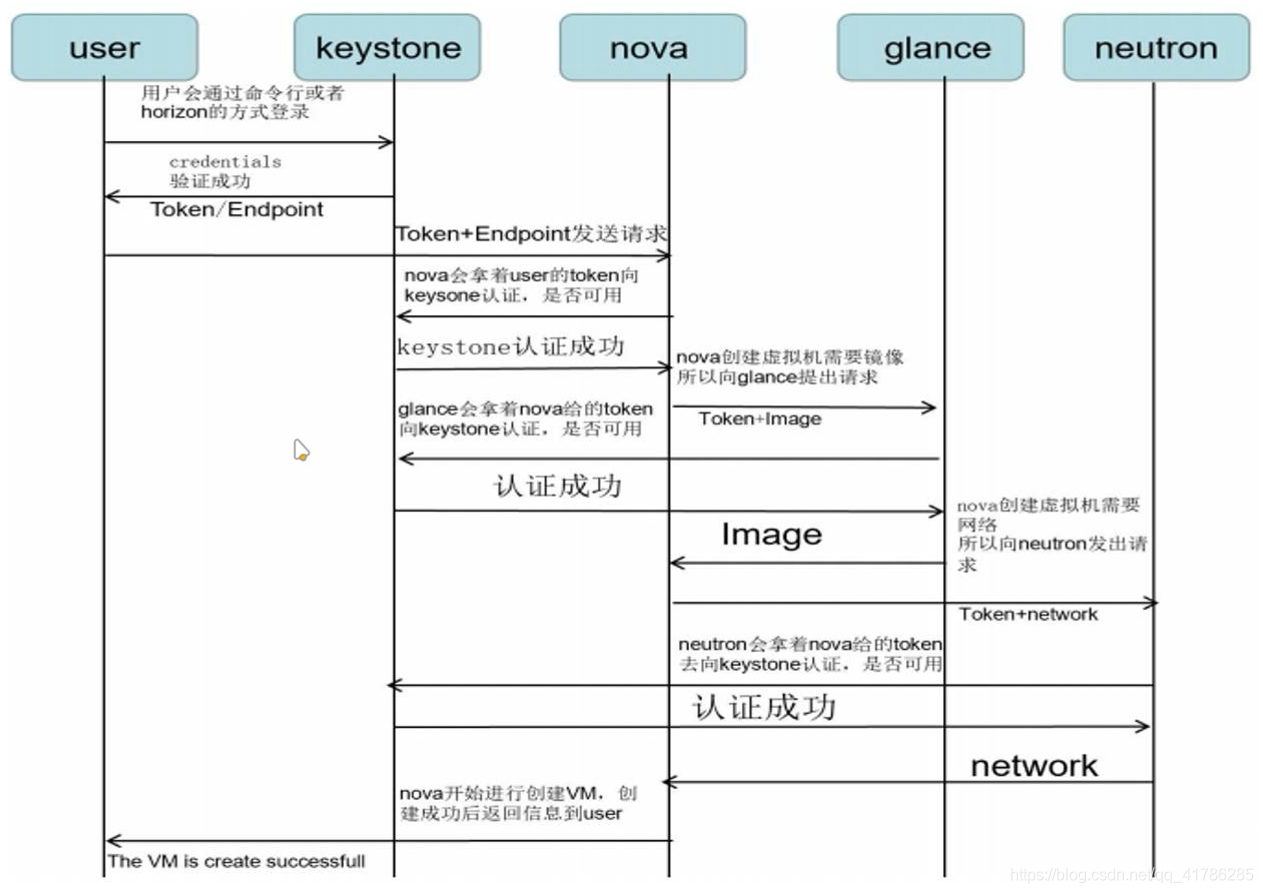
- 用户通过命令行或者horizon控制面板的方式登录openstack,凭借自己的证书(credentials)给keystone验证。
- Keystone对用户的证书验证,验证通过则会发布一个令牌(token)和用户所需服务的位置点(endpoint)给用户。
- 用户得到了位置点(endpoint)之后,携带自己的令牌,向nova发起请求,请求创建虚拟机。
- nova会拿着用户的token向keystone进行认证,看是否允许用户执行这样的操作。
- keystone认证通过之后,返回给nova,nova即开始执行创建虚拟机的请求。首先需要镜像资源,nova带着令牌(token)和所需要的镜像名向glance提出镜像资源的请求。
- glance会拿着token去向keystone进行认证,看是否允许提供镜像服务。keystone认证成功后,返回给glance。glance向nova提供镜像服务。
- 创建虚拟机还需要网络服务,nova携带token向neutron发送网络服务的请求
- neutron拿着nova给的token向keystone进行认证,看是否允许向其提供网络服务。keystone认证成功后,返回给nuetron。nuetron则给nova提供网络规划服务。
- nova获取了镜像和网络之后,开始创建虚拟机,通过hypervisior可调用底层硬件资源进行创建。创建完成返回给用户,成功执行了用户的请求。
4.2、Glance镜像服务
它在OpenStack中的项目名称为Glance。在早期的OpenStack版本中,Glance只有管理镜像的功能,并不具备镜像存储功能。现在,Glance已发展成为集镜像上传、检索、管理和存储等多种功能的OpenStack核心服务
4.2.1、镜像
镜像的英文名为Image,又译为映像,通常是指一系列文件或一个磁盘驱动器的精确副本。镜像文件其实和ZIP压缩包类似,它将特定的一系列文件按照一定的格式制作成单一的文件,以方便用户下载和使用
4.2.2、镜像服务
镜像服务就是用来管理镜像的,让用户能够发现、获取和保存镜像。在OpenStack中提供镜像服务的是Glance,其主要功能如下:
- 查询和获取镜像的元数据和镜像本身
- 注册和上传虚拟机镜像,包括镜像的创建、上传、下载和管理
- 维护镜像信息,包括元数据和镜像本身
- 支持多种方式存储镜像,包括普通的文件系统、Swift、Amazon S3等
- 对虚拟机实例执行创建快照命令来创建新的镜像,或者备份虚拟机的状态
4.2.3、Image API的版本
Glance提供的RESTful API目前只有两个版本:API v1和API v2
- v1只提供基本的镜像和成员操作功能,包括镜像创建、删除、下载、列表、详细信息查询、更新,以及镜像租户成员的创建、删除和列表
- v2除了支持v1的所有功能外,主要增加了镜像位置的添加、删除、修改、元数据和名称空间操作,以及镜像标记操作
两个版本对镜像存储支持相同,v1从N版开始已经过时,迁移路径使用v2进行替代
4.2.4、镜像格式
虚拟机镜像文件磁盘格式
- raw:无结构的磁盘格式
- vhd:改格式通用于VMware、Xen、VirtualBox以及其他虚拟机管理程序
- vhdx:vhd格式的增强版本,支持更大的磁盘尺寸
- vmdx:一种比较通用的虚拟机磁盘格式
- vdl:由VirtualBox虚拟机监控程序和QEMU仿真器支持的磁盘格式
- iso:用于光盘(CD-ROM)数据内容的档案格式
- ploop:由Virtualzzo支持,用于运行OS容器的磁盘格式
- qcow2:由QEMU仿真支持,可动态扩展,支持写时复制(Copy on Write)的磁盘格式
- aki:在Glance中存储的Amazon内核格式
- ari:在Glance中存储的Amazon虚拟内存盘(Ramdisk)格式
- ami:在Glance中存储的Amazon机器格式
虚拟机镜像文件容器格式
- bare:没有容器或元数据“信封”的镜像
- ovf:开放虚拟化格式
- ova:在Glance中存储的开放虚拟化设备格式
- aki:在Glance中存储的Amazon内核格式
- ari:在Glance中存储的Amazon虚拟内存盘(Ramdisk)格式
- Docker:在Glance中存储的容器文件系统的Docker的tar档案
如果不能确定选择哪种容器格式,那么简单地容器格式指定为bare是最安全地
4.2.5、镜像状态
镜像从上传到识别的过程:
- queued:初始化过程,镜像文件刚被创建,在Glance数据库只有其元数据,镜像数据还没有上传至数据库中
- saving:导入数据库过程,是镜像地原始数据在上传到数据库中地一种过渡状态,表示正在上传镜像
- uploading:提交给服务识别过程,指示已进行导入数据提交调用,此状态下不允许调用PUT/file(saving状态会执行PUT/file,这是另外一种上传的方法)
- importing:准使用状态,指示已经完成导入调用,但是镜像还未准备好使用
镜像上载完成后的状态
- active:表示可使用
- deactivated:表示只对管理员开放的权限
- killed:表示镜像上传中发生错误
- deleted:镜像将在不久后自动删除,镜像不可用(保留数据)
- pending_delete:与deleted类似,但是删除后无法恢复
4.2.6、访问权限
- Public(公共的):可以被所有的项目使用
- Private(私有的):只有被镜像所有者所在的项目使用
- Shared(共享的):一个非共有的镜像可以共享给其他项目,这是通过项目成员(member-*)操作来实现的
- Protected(受保护的):这种镜像不能被删除
4.2.7、架构图
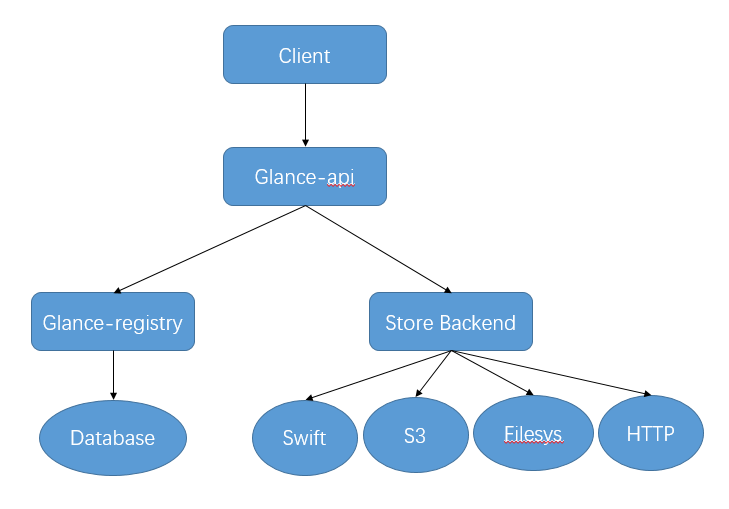
- glance-api 是 glance服务后台运行的服务进程,是进入glance的入口,对外提供REST API ,负责接收外部客户端的服务请求,如响应镜像查询、获取和存储的调用。
- glance-registry 是服务后台远程的镜像注册服务,负责处理与镜像的元数据相关的外部请求,如镜像大小、类型等信息。glance-api 接收外部请求,若与元数据相关,则将请求转发给glance-registry,glance-registry会解析请求的内容,并与数据库交互,进行存储、处理、检索镜像的元数据,元数据所有信息即存储在后端的数据库中。
- glance的DB模块存储的是镜像的元数据,可以选用MySQL、mariaDB、SQLite等数据库。镜像的元数据是通过glance-registry存放在数据库中。镜像本身(chunk 块数据)是通过glance的存储驱动存储在后端的各种存储系统中。
- 存储后端(store backend)将镜像本身的数据存放在后端存储系统,存储系统有多种存储方式,支持本地文件系统存储、对象存储、RBD块存储、Cinder块存储、分布式文件存储等。具体使用哪种backend,可以在glance的配置文件 /etc/glance/glance-api.conf 中配置 [glance-store] 模块。
4.2.8、流程解析
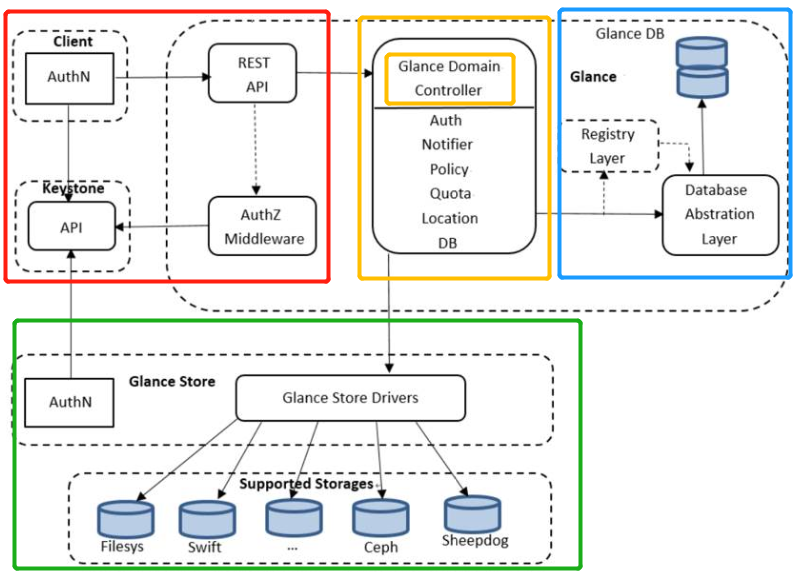
①红色方框是对客户端的请求进行认证和授权的服务流程:openstack的操作都需要经过keystone进行身份认证,并授权,glance也不例外,授权成功再去请求glance服务,glance服务接收到外部请求后,会去keystone进行认证,此请求是否已授权,认证通过后,才会将请求传到后端。
- Auth(授权):用来控制镜像的访问权限,决定镜像信息是否可以修改
②黄色方框的glance domain controller 是主用的中间件,相当于调度器,作用是将glance 内部服务的操作分发到下面的各个功能层
- Policy(规则定义):定义镜像操作的访问规则
- Quota(配额限制):管理员对用户定义了镜像大小的镜像上传上限
- Location(定位):通过glance_store与后台进行交互,在该层新位置添加进行时检查位置URI是否正确,防止镜像位置重复
③蓝色方框里镜像的元数据是通过glance-registry存放在数据库中。镜像本身(chunk 块数据)是通过glance的存储驱动存储在后端的各种存储系统中。
- Registry Layer(注册层):通过使用单独的服务控制Glance Controller与Glance DB之间的安全交互
- Glance DB:存储镜像的元数据信息
- Glance Store:用来处理Glance和各种存储后端的交互,提供了一个统一接口来访问后端的存储
④绿色方框是存储后端(store backend)将镜像本身的数据存放在后端存储系统
- DB(数据库):实现与数据库进行交互的API,将镜像转换为响应的格式存储在数据库中
4.3、Nova计算服务
4.3.1、Nova计算服务
- nova计算服务是openstack最核心的服务之一,负责维护和管理云环境的计算资源
- nova本身并不提供虚拟化的能力,他通过计算服务使用不同的虚拟化驱动来与底层的Hypervisor进行交互,nova对所有的计算实例进行生命周期的管理
- nova需要其他服务组件的支持,比如Glance、Keystone、Neutron以及Cinder等,通过与这些服务的支持实现实例的管理
4.3.2、Nova系统架构
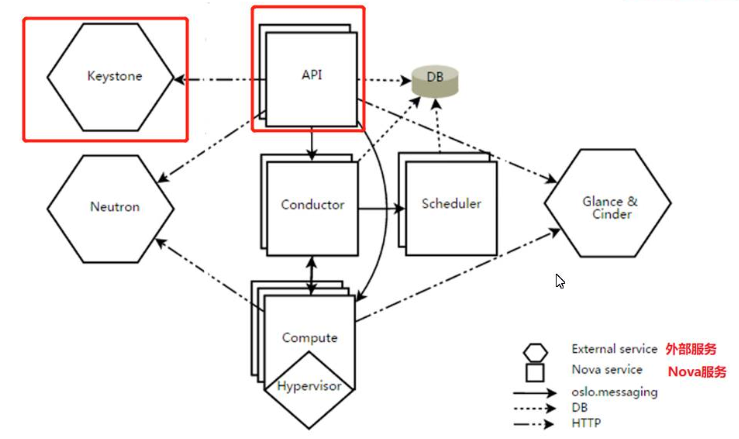
Nova由多个服务器进程构成,每个进程执行不同的功能,下面介绍各个组件的功能
①DB:用于数据存储的sql数据库
②API:用于接收HTTP请求、通过消息队列或HTTP与其他组件通信
- API是访问nova的接口,nova-api服务接收和处理来自用户的所有计算api请求,它是openstack对外服务最主要的接口并且提供了可以查询所有api的端点,也是外部访问并使用nova提供的各种服务的唯一途径,nova-api对接收到的api请求有以下几个步骤,首先检查客户端传过来的参数是否合法,如果合法则调用其他服务来处理客户端的HTTP请求,最后格式化nova其他子服务返回结果并返回给客户端
- API提供REST标准调用服务,便于与第三方系统集成,只要与虚拟机生命周期相关的操作,nova-api都会响应
- 用户不会直接发送RESTful API请求,而是通过命令行、控制台和其他需要跟nova交换的组件来使用这些API
③Scheduler:用于决定那台计算节点承载计算实例的nova调度器
简介
- 调度器,它主要由nova-scheduler服务实现,它可以解决如何选择在哪个节点上启动实例,并通过调度算法来确定虚拟机具体创建在哪一个计算服务器上,nova-scheduler服务会通过读取数据库的内容,从可用的资源中选择最合适的计算节点来吃新的虚拟机实例
- 创建虚拟机的过程中,用户会提出各种各样的资源要求,比如Cpu、内存以及磁盘各需要多少,openstack会根据用户的需求,来确定具体使用哪个实例
调度器的类型
- 随机调度器:从所有正常运行nova-compute服务的节点中随机选择
- 缓存调度器:是随机调度器的一种特殊类型,在随机调度器的基础上,将主机资源信息缓存在本地内存中,然后通过后台的定时任务,定时从数据库中获取最新的主机资源信息,周期性同步而不是实时获取主机资源信息。
- 过滤器调度器:根据指定的过滤条件以及权重选择最佳的计算节点,又称为筛选器。
过滤器调度器的调度过程
主要分为两个阶段:
- 通过指定的过滤器选择满足条件的计算节点,比如内存使用率,可以使用多个过滤器依次进行过滤。(预选)
- 对过滤之后的主机列表进行权重计算并排序,选择最优的计算节点来创建虚拟机实例。(优选)
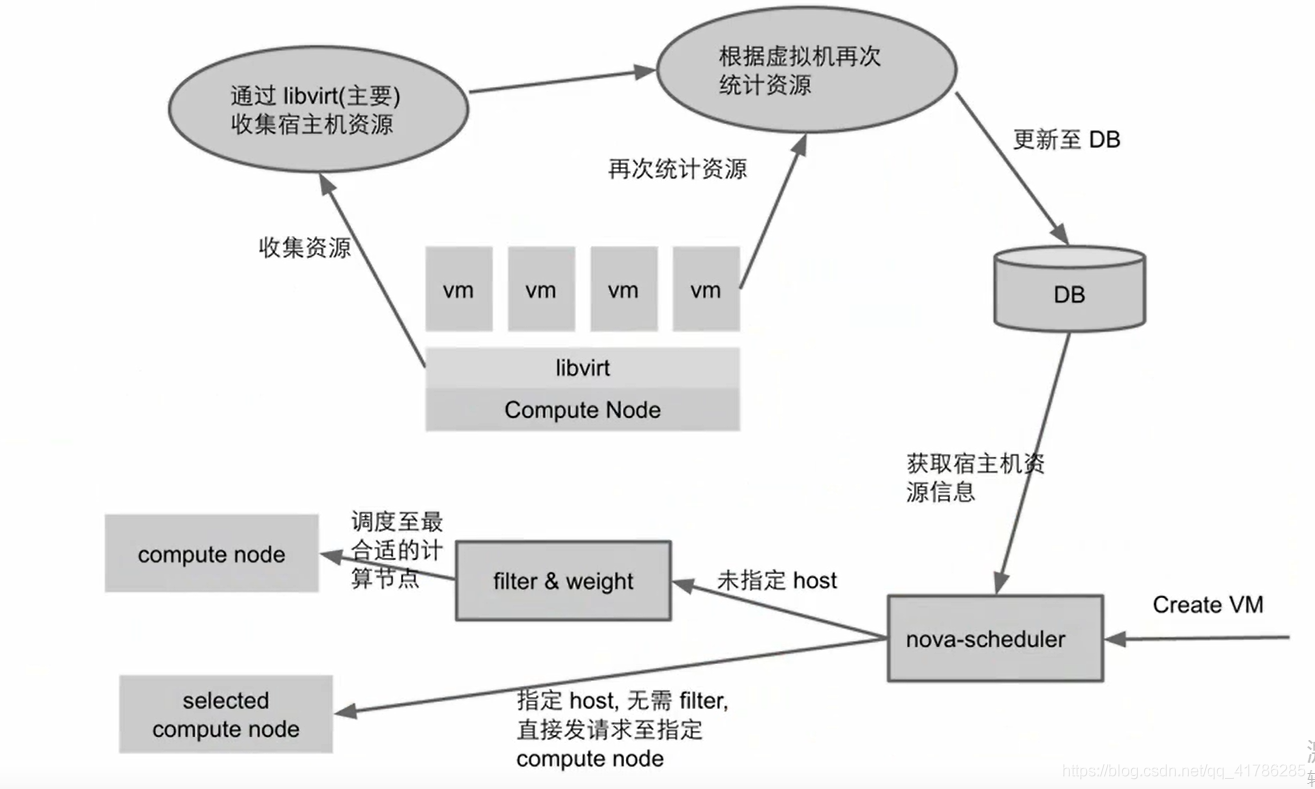
调度器与DB的交互过程:
- scheduler组件决定的是虚拟机实例部署在哪台计算节点上并调度,在调度之前,会先向数据库获取宿主机资源信息作为依据;
- 之后可通过过滤器和权重选择最合适的节点调度,或者指定节点直接调度;
- 计算节点的 libvirt 工具负责收集宿主机的虚拟化资源,根据已创建的实例再次统计资源,将资源信息更新到数据库中,整个更新资源信息的过程是周期性执行的,而不是实时的;
- 所以存在一个问题,当刚创建完一个实例,随即又需要创建时,数据库还未来得及更新宿主机的最新状态,那么调度器依据的信息就不正确,有可能所选的节点资源并不够用,而导致调度失败。
- 这同时也是缓存调度器的缺陷,无法实时获取租主机资源信息。我们可在调度完成时,直接将资源信息返回给数据库,更新数据库状态,解决这个问题。
过滤器
- 当过滤调度器需要执行调度操作时,会让过滤器对计算节点进行判断,返回ture或false,按照主机列表中的顺序依次过滤。
- scheduler_available_filters 选项用于配置可用过滤器,默认是所有nova自带的过滤器都可以使用。
- scheduler_default_filters 选项用于指定nova-schedule 服务真正使用的过滤器。
过滤器类型
- RetryFilter(再审过滤器)
主要作用是过滤掉之前已经调度过的节点(类比污点)。如A、B、C都通过了过滤,A权重最大被选中执行操作,由于某种原因,操作在A上失败了。Nova-filter 将重新执行过滤操作,再审过滤器直接过滤掉A,以免再次失败。
- AvailabilityZoneFilter(可用区域过滤器)
主要作用是提供容灾性,并提供隔离服务,可以将计算节点划分到不同的可用区域中。Openstack默认有一个命名为nova的可用区域,所有计算节点一开始都在其中。用户可以根据需要创建自己的一个可用区域。创建实例时,需要指定将实例部署在那个可用区域中。通过可用区过滤器,将不属于指定可用区的计算节点过滤掉。
- RamFilter(内存过滤器)
根据可用内存来调度虚拟机创建,将不能满足实例类型内存需求的计算节点过滤掉,但为了提高系统资源利用率, Openstack在计算节点的可用内存允许超过实际内存大小,可临时突破上限,超过的程度是通过nova.conf配置文件中ram_ allocation_ ratio参数来控制的, 默认值是1.5。(但这只是临时的)Vi /etc/nova/nova . conf
Ram_ allocation_ ratio=1 .5
- DiskFilter(硬盘过滤器)
根据磁盘空间来调度虚拟机创建,将不能满足类型磁盘需求的计算节点过滤掉。磁盘同样允许超量,超量值可修改nova.conf中disk_ allocation_ ratio参数控制,默认值是1.0,(也是临时的)
Vi /etc/nova/nova.conf
disk_ allocation_ ratio=1.0
- CoreFilter(核心过滤器)
根据可用CPU核心来调度虚拟机创建,将不能满足实例类型vCPU需求的计算节点过滤掉。vCPU也允许超量,超量值是通过修改nova.conf中cpu_ allocation_ratio参数控制,默认值是16。
Vi /etc/nova/nova. conf
cpu_allocation_ ratio=16.0
- ComputeFilter(计算过滤器)
保证只有nova-compute服务正常工作的计算节点才能被nova-scheduler调度,它是必选的过滤器。
- ComputeCapabilitiesFilter(计算能力过滤器)
根据计算节点的特性来过了,如不同的架构。
- ImagePropertiesFilter(镜像属性过滤器)
根据所选镜像的属性来筛选匹配的计算节点,通过元数据来指定其属性。如希望镜像只运行在KVM的Hypervisor上,可以通过Hypervisor Type属性来指定。
- 服务器组反亲和性过滤器
要求尽量将实例分散部署到不同的节点上,设置一个服务器组,组内的实例会通过此过滤器部署到不同的计算节点。适用于需要分开部署的实例。
- 服务器组亲和性过滤器
此服务器组内的实例,会通过此过滤器,被部署在同一计算节点上,适用于需要位于相同节点的实例服务。
权重
- 在对计算节点进行过滤时,多个过滤器依次进行过滤,而不是并行,相当于一个个预选,避免重复对同一个节点进行所有过滤项检验。过滤之后的节点再通过计算权重选出最终的计算节点。
- 所有权重位于nova/scheduler/weights 目录下,目前默认是RAMweighter,根据计算节点空闲的内存计算权重,内存空闲越多权重越大,实例将被部署到内存空闲最大的计算节点。
④Network:管理IP转发、网桥或虚拟局域网的nova网络组件
⑤Compute:管理Hypervisor与虚拟机之间通信的nova计算组件
⑥Conductor:处理需要协调的虚拟处理对象转换
schedule组件小结:
定位:决定实例具体创建在哪个计算节点
调度流程:
有多个调度器、过滤器共同合作,一次过滤,首先筛选出符合要求的节点,接着以权重(一般是基于内存空闲)的方式,对节点打分排序,最终决定出一个节点。
子功能:
粗过滤(基础资源),例如CPU、内存、磁盘
精细化过滤,例如镜像属性,服务性能契合度
高级过滤,亲和性/反亲和性过滤
过滤之后,可以进行随机调度,会进行再筛选,即污点机制,对剩下的节点过滤,排除掉之前有故障的节点。
4.3.3、compute计算组件
Nova-compute在计算节点上运行,负责管理节点上的实例。通常一个主机运行一 个Nova-compute服务, 一个实例部署在哪个可用的主机上取决于调度算法。OpenStack对实例的操作最后都是提交给Nova-compute来完成。
Nova-compute可分为两类,一类是定向openstack报告计算节点的状态,另一类是实现实例生命周期的管理。
- 定期向OpenStack报告计算节点的状态
每隔一段时间,nova-compute就会报告当前计算节点的资源使用情况和nova-compute服务状态。nova-compute是通过Hypervisor的驱动获取这些信息的。 - 实现虚拟机实例生命周期的管理
OpenStack对虚拟机实例最主要的操作都是通过nova-compute实现的。包括创建、关闭、重启、挂起、恢复、中止、调整大小迁移、快照。
以实例创建为例来说明nova-compute的实现过程。
(1)为实例准备资源。
(2)创建实例的镜像文件。
(3)创建实例的XML定义文件。
(4)创建虚拟网络并启动虚拟机。
通过Driver (驱动)架构支持多种Hypervisor虚拟机管理器:
面对多种Hypervisor, nova-compute为这些Hypervisor定义统一 的接口,Hypervisor只需要对接这个接口, 就可以Drive驱动的形式即插即用到OpenStack系统中,使得compute组件可以调用虚拟化的资源,创建实例。
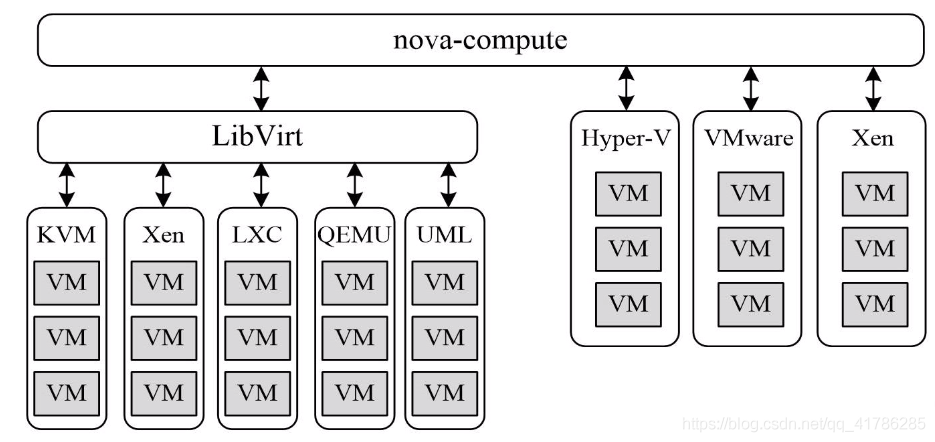
4.3.4、conductor协调组件
- 为数据库的访问提供一层安全保障。Nova-conductor作为nova-compute服务与数据库之间交互的中介,避免了compute直接访问,由nova-compute服务对接数据库,compute组件位于第三方上,与架构外部进行交互。这样就可避免一些越权操作,并且为数据库分压。
- Nova-compute访问数据库的全部操作都改到nova-conductor中,nova-conductor作为对数据库操作的一个代理,而且nova-conductor是部署在控制节点上的。
- Nova-conductor有助于提高数据库的访问性能,nova-compute可以创建多个线程使用远程过程调用(RPC)访问nova-conductor。
- 在一个大规模的openstack部署环境里,管理员可以通过增加nova-conductor的数量来应对日益增长的计算节点对数据库的访问量。
4.3.5、 Placement API
- 以前对资源的管理全部由计算节点承担,在统计资源使用情况时,只是简单的将所有计算节点的资源情况累加起来,但是系统中还存在外部资源,这些资源由外部系统提供。如ceph、nfs等提供的存储资源等。
面对多种多样的资源提供者,管理员需要统一的、简单的管理接口来统计系统中资源使用情况,这个接口就是Placement API。 - PlacementAPI由nova-placement-api服务来实现, 旨在追踪记录资源提供者的目录和资源使用情况。被消费的资源类型是按类进行跟踪的。 如计算节点类、共享存储池类、IP地址类等。
4.3.6、虚拟机实例化流程
- 用户访问控制台
可以通过多种方式访问虚拟机的控制台:
■ Nova-novncproxy守护进程: 通过vnc连接访问正在运行的实例提供一个代理,支持浏览器novnc客户端。(最常用的)
■ Nova-spicehtml5proxy守护进程: 通过spice连接访问正在运行的实例提供一个代理,支持基于html5浏览器的客户端。
■ Nova-xvpvncproxy守护进程: 通过vnc连接访问正在运行的实例提供一个代理,支持openstack专用的java客户端。
■ Nova-consoleauth守护进程: 负责对访问虚拟机控制台提供用户令牌认证。这个服务必须与控制台代理程序共同使用,即上面三种代理方式。
如果无法通过控制台/URL连接到内部实例:
1、实验场景中,虚拟机资源不足
2、实验场景中,镜像问题(公共镜像,作为测试用的镜像)
3、生产环境中,路由配置问题,路由网关配置到了其他实例地址,内部有多个实例项目。
- 首先用户(openstack最终用户或其他程序)执行nova client提供的用于创建虚拟机的命令。
- nova-api服务监听到来自客户端的http请求,会将请求转换为AMQP消息之后上传到消息队列。
- 通过消息队列调用conductor服务
- conductor服务从消息队列中接收到虚拟机的实例化请求后,进行准备工作
- conductor通过消息队列告诉scheduler服务去选择一个合适的计算节点创建虚拟机,此时scheduler会读取数据库的内容
- conductor服务从nova-schedule服务得到了计算节点的信息后,通过消息队列通知compute服务实现虚拟机的创建。
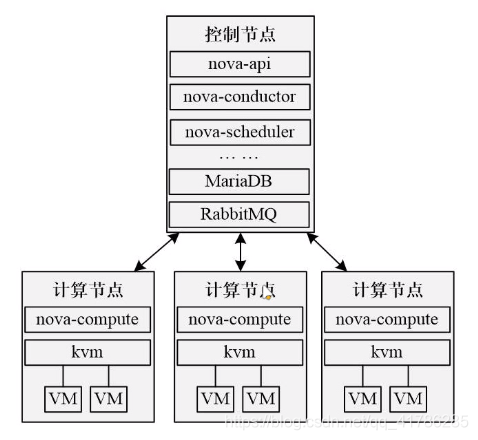
4.3.7、Nova部署架构
经典部署架构:
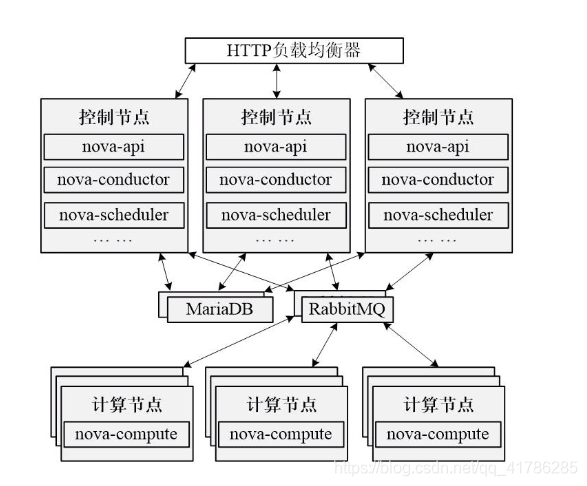
负载均衡部署架构:
4.3.8、Nova的Cell架构
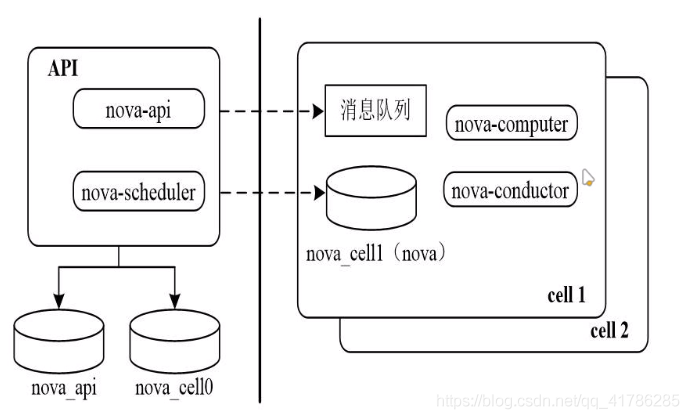
使用此架构原因
为了解决openstack nova集群的规模变大时,数据库和消息队列服务就会出现瓶颈问题。Nova为提高水平扩展及分布式、大规模的部署能力,同时又不想增加数据库和消息中间件的复杂度,从而引入了Cell概念。
cell概念
Cell可译为单元。为支持更大规模的部署,openstack将大的nova集群分成小的单元,每个单元都有自己的消息队列和数据库,可以解决规模增大时引起的瓶颈问题。在Cell中,Keystone、Neutron、 Cinder、Glance等资源是共享的。
cell架构的数据库
- nova-api数据库:存放全局信息,这些全局数据表是从nova库迁移过来的,包括实例模型信息,实例组,配额信息。
- nova-cell0数据ku:当实例调度失败时,实例的信息不属于任何一个cell,所以存放到cell0数据库中。
单cell部署:
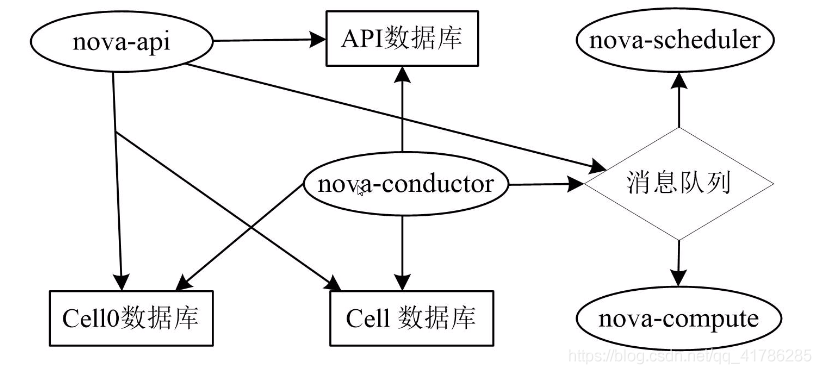
多cell部署:
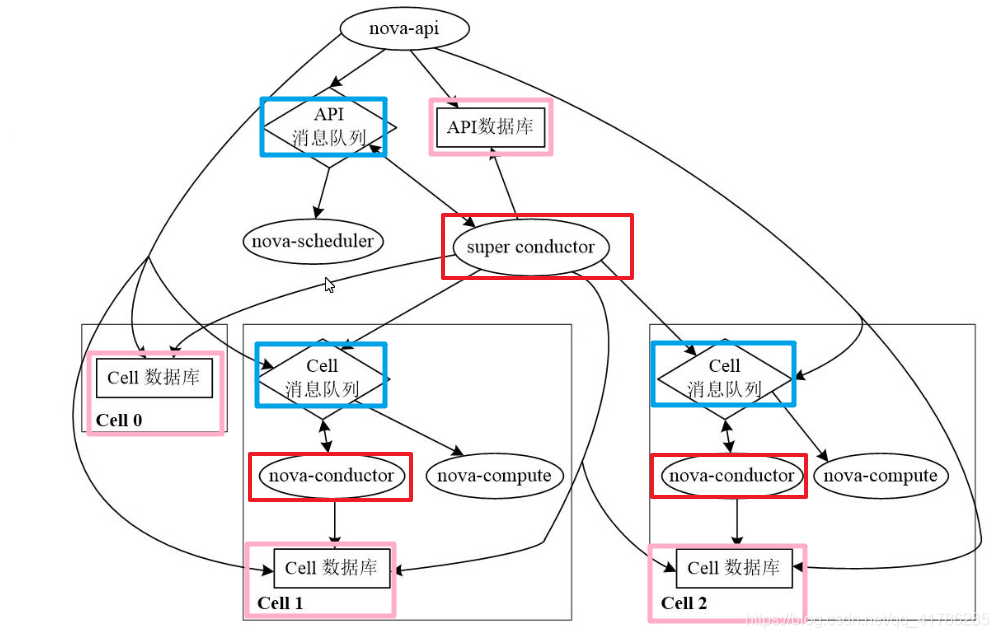
多cell部署的架构,可以从分层的角度来看:
为了应付集群规模的扩大,对数据库、消息队列进行扩容,实现nova规模的扩展。通过划分多个小的cell单元,多个单元同时处理业务,每个cell单元都有各自的数据库和消息队列。为了管理这些小的单元,需要一个集中化管理组件 super conductor,主conductor来管理cell单元,同时完成自身的工作。
蓝色方框:是对消息队列的划分。划分为API消息队列,和cell单元中的消息队列。API消息队列中是外部对nova的请求,以及nova内部子服务之间的通信请求,作为它们之间通信的载体。cell消息队列中是cell单元需要处理的业务请求。
红色方框:是对conductor的划分,super-conductor用于集中管理cell单元,同时负责通知 nova-scheduler 调度计算节点,调度失败直接写入cell0,成功则控制任务具体下发给哪个cell单元处理,将所有数据写入数据库。cell中的conductor,通过消息队列收到本cell需要创建实例的请求后,会通知nova-compute创建实例,进行具体的处理和协调。
粉色方框:是对数据库的划分。API数据库存放全局的交互数据,总的资源统计。cell0数据库存放实例创建失败的信息,cell1/2存放各自单元成功创建实例的信息,对应处理的请求数据。
nova-api:每个创建实例的请求都有编号,创建成功与否的结果会存储在cell数据库中,nova-api会根据编号,从cell数据库中调取到请求的最终结果,格式化后返回给用户。
4.4、Neutron 网络服务
简介:
网络是openstack最重要的资源之一, 没有网络,虚拟机将被隔离。Openstack的网络服务最主要的功能就是为虚拟机实例提供网络连接,最初由nova的一-个单独模块nova-compute实现,但是nova-compute支持的网络服务有限,无法适应大规模、高密度和多项目的云计算,现已被专门的网络服务项目Neutron所取代。
Neutron为整个openstack环境提供软件定义网络支持,主要功能包括二层交换、三层路由、防火墙、VPN, 以及负载均衡等。Neutron在由其他openstack服务 (如nova)管理的网络接口设备 (如虚拟网卡)之间提供网络连接即服务。
4.4.1、linux网络虚拟化
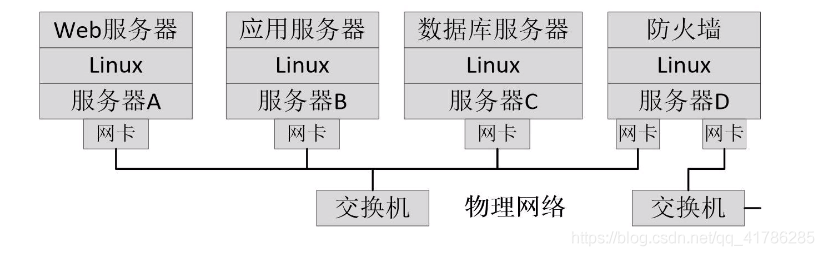
linux网络虚拟化:
传统的物理网络:
需要对二层物理网络进行抽象和管理:
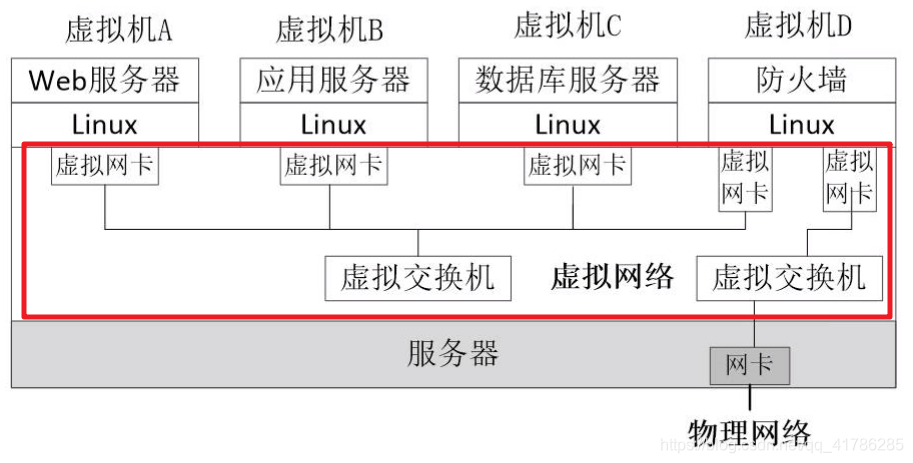
- 实现虚拟化后,多个物理服务器可以被虚拟机取代,部署在同一台物理服务器,上。虚拟机由虚拟机管理器(Hypervisor)实现,在Linux系统中Hypervisor通常采用kvm。在对服务器进行虚拟化的同时,也对网络进行虚拟化。
- Hypervisor为虚拟机创建一个或多个虚拟网卡(vNIC),虚拟网卡等同于虚拟机的物理网卡。物理交换机在虚拟网络中被虚拟为虚拟交换机(vSwitch),虚拟机的虚拟网卡连接到虚拟交换机上,虚拟机交换机再通过物理主机的物理网卡连接到外部网络。
- 对于物理网络来说,虚拟化的主要工作是对网卡和交换设备的虚拟化。
linux虚拟网桥:
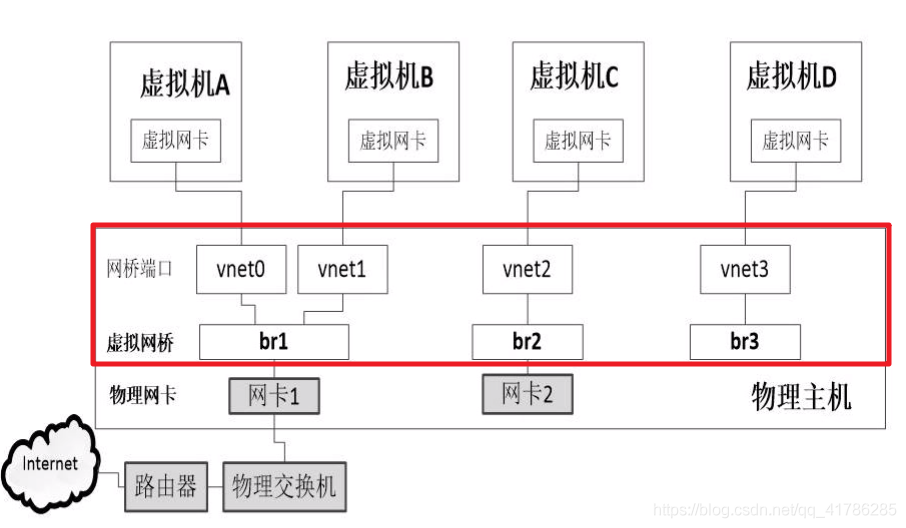
- 与物理机不同,虚拟机并没有硬件设备,但是也要与物理机和其他虚拟机进行通信。LinuxKVM的解决方案是提供虚拟网桥设备,像物理交换机具有若干网络接口(网卡) 一样,在网桥上创建多个虚拟的网络接口,每个网络接口再与KVM虚拟机的网卡相连。
- 在Linux的KVM虚拟系统中,为支持虚拟机的网络通信,网桥接口的名称通常以vnet开头,加上从0开始顺序编号,如vnet0、vnet1, 在创建虚拟机时会自动创建这些接口。虚拟网桥br1和br2分别连接到物理主机的物理网卡1和物理网卡2。
虚拟局域网:
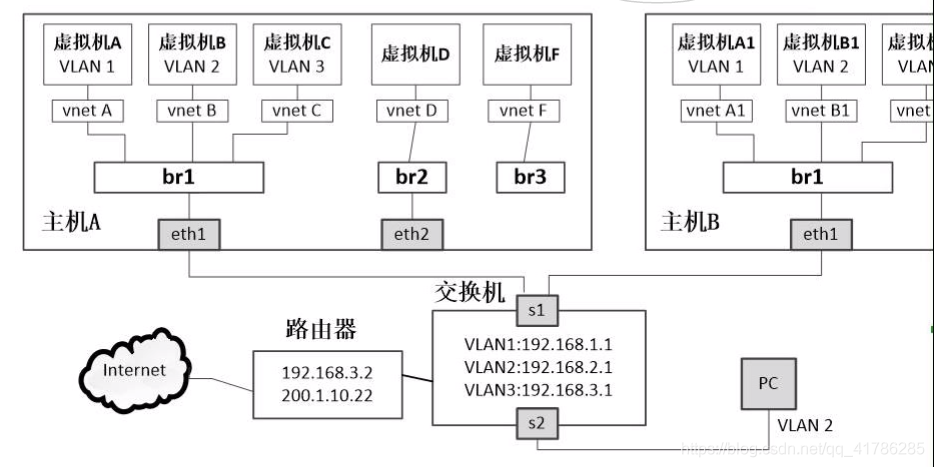
- 一个网桥可以桥接若干虚拟机,当多个虚拟机连接在同一网桥时,每个虚拟机发出的广播包会引发广播风暴,影响虚拟机的网络性能。通常使用虚拟局域网(VLAN)将部分虚拟机的广播包限制在特定范围内,不影响其他虚拟机的网络通信。
- 通常使用VLAN将部分虚拟机的广播包限制在特定范围内,不影响其他虚拟机的网络通信。
- 将多个虚拟机划分到不同的VLAN中,同一VL AN的虚拟机相当于连接同一网桥上。
- 在Linux虚拟化环境中,通常会将网桥与VLAN对应起来,也就是将网桥划分到不同的VLAN中
- VLAN协议为802.1Q,VLAN是具有802.1Q标签的网络。
开放虚拟交换机:
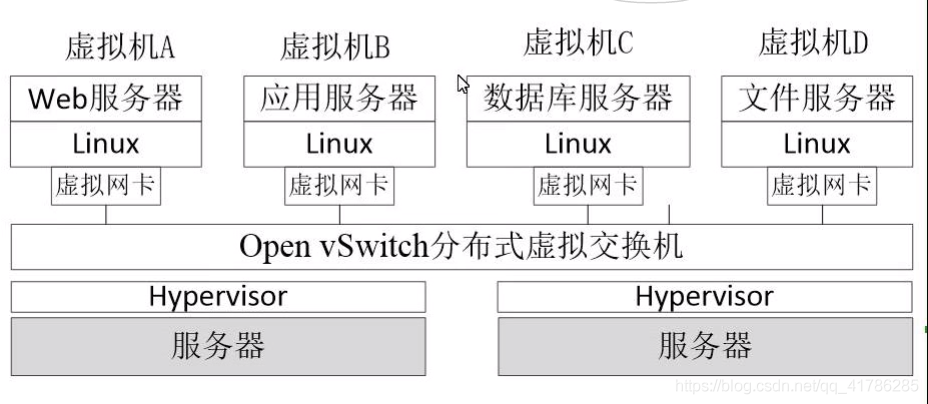
- 开放虚拟交换机 (Open vSwitch) 是与硬件交换机具备相同特性,可在不同虚拟平台之间移植(保持自己的功能特性,同时具有兼容性),具有产品级质量的虚拟交换机,适合在生产环境中部署。
- 交换设备的虚拟化对虚拟网络来说至关重要。在传统的数据中心,管理员可以对物理交换机进行配置,控制服务器的网络接入,实现网络隔离、流量监控、QoS配置、流量优化等目标。在云环境中,采用Open vSwitch技术的虚拟交换机可使虚拟网络的管理、网络状态和流量的监控得以轻松实现。
- Open Switch在云环境中的虚拟化平台上实现分布式虚拟交换机,可以将不同主机上的OpenvSwitch交换机连接起来,形成一个大规模的虚拟网络。
OpenStack网络服务提供一个API让用户在云中建立和定义网络连接。该网络服务的项目名称是Neutron。OpenStack网络负责创建和管理 虚拟网络基础架构,包括网络、交换机、子网和路由器,这些设备由OpenStack计算服务Nova管理。同时,网络服务还提供防火墙和VPN这样的高级服务。可以将网络服务部署到特定主机.上。OpenStack网络组件与身份服务、计算服务和仪表板等多个OpenStack组件进行整合
4.4.2、Neutron网络结构
- 一个简化的典型的Neutron网络结构如图所示,包括一个外部网络、一个内部网络和一个路由器。
- 外部网络负责连接OpenStack项目之外的网络环境,又称公共网络。与其他网络不同,它不仅仅是-一个虚拟网络,更重要的是,它表示OpenStack网络能被外部物理网络接入并访问。外部网络可能是企业的局域网(Intranet) ,也可能是互联网(Internet) ,这类网络并不是由Neutron直接管理。
- 内部网络完全由软件定义,又称私有网络。它是虚拟机实例所在的网络,能够直接连接到虚拟机。项目用户可以创建自己的内部网络。默认情况下,项目之间的内部网络是相互隔离的,不能共享。该网络由Neutron直接配置与管理。
- 路由器用于将内部网络与外部网络连接起来,因此,要使虚拟机访问外部网络,必须创建一个路由器。
- Neutron需要实现的主要是内部网络和路由器。内部网络是对二层(L 2)网络的抽象,模拟物理网络的二层局域网,对于项目来说,它是私有的。路由器则是对三层(L3) 网络的抽象,模拟物理路由器,为用户提供路由、NAT等服务。

网络子网与端口
- 网络:一个隔离的二二层广 播域,类似交换机中的VLAN。Neutron支持多种类型的网络, 如FLAT、VLAN、VXLAN等。
- 子网:一个IPV4或者IPV6的地址段及其相关配置状态。虚拟机实例的IP地址从子网中分配。每个子网需要定义IP地址的范围和掩码(这个有点像DHCP中定义的作用域的概念)。
- 端口:连接设备的连接点,类似虚拟交换机上的一个网络端口。端口定义了MAC地址和IP地址,当虚拟机的虚拟网卡绑定到端口时,端口会将MAC和IP分配给该虚拟网卡。
- 通常可以创建和配置网络、子网和端口来为项目搭建虚拟网络。网络必须属于某个项目,一个项目中可以创建多个网络。一个子网只能属于某个网络,一个网络可以有多个子网。一个端口必须属于某个子网,一个子网可以有多个端口。
网络拓扑类型
- Local
Local网络与其他网络和节点隔离。该网络中的虚拟机实例只能与位于同-节点上同- -网络的虚拟机实例通信,实际意义不大,主要用于测试环境。位于同一Local网络的实例之间可以通信,位于不同Local网络的示例之间无法通信。一个Local网络只能位于同一个物理节点上,无法跨节点部署。 - Flat
Flat是一种简单的扁平网络拓扑,所有的虚拟机实例都连接在同一网络中,能与位于同一网络的实例进行通信,并且可以跨多个节点。这种网络不使用VLAN,没有对数据包打VLAN标签,无法进行网络隔离。Flat是基于不使用VLAN的物理网络实施的虚拟网络。每个物理网络最多只能实现- -个虚拟网络。 - VLAN
VLAN是支持802.1q协议的虚拟局域网,使用VLAN标签标记数据包,实现网络隔离。同一VLAN网络中的实例可以通信,不同VLAN网络中的实例只能通过路由器来通信。VLAN网络可以跨节点。 - VXLAN
VXLAN (虚拟扩展局域网)可以看作是VLAN的一种扩展,相比于VLAN,它有更大的扩展性和灵活性,是目前支持大规模多租房网络环境的解决方案。由于VLAN包头部限长是12位, 导致VLAN的数量限制是4096 (2^12) 个,不能满足网络空间日益增长的需求。目前VXLAN的封包头部有24位用作VXLAN标识符(VNID)来区分VXLAN网段,最多可以支持16777216 (2^24) 个网段。
VXLAN使用STP防止环路,导致- -半的网络路径被阻断。VXLAN的数据包是封装到UDP通过三层传输和转发的,可以完整地利用三层路由,能克服VLAN和物理网络基础设施的限制,更好地利用已有的网络路径。 - GRE
GRE (通用路由封装)是用一种网络层协议去封装另一种网络层协议的隧道技术。GRE的隧道由两端的源IP地址和目的IP地址定义,它允许用户使用IP封装IP等协议,并支持全部的路由协议。在OpenStack环境中使用GRE意味着"IP over IP”,GRE与VXLAN的主要区别在于,它是使用IP包而非UDP进行封装的。 - GENEVE
GENEVE(通用网络虚拟封装)的目标宣称是仅定义封装数据格式,尽可能实现数据格式的弹性和扩展性。GENEVE封装的包通过标准的网络设备传送,即通过单播或多播寻址,包从一个隧道端点传送到另一个或多个隧道端点。GENEVE帧格式由- -个封装在IPV4或IPV6的UDP里的简化的隧道头部组成。GENEVE推出的主要目的是为了解决封装时添加的元数据信息问题(到底多少位, 怎么用GENEVE自动识别与调整) ,以适应各种虚拟化场景。 - 总结
随着云计算、大数据、移动互联网等新技术的普及,网络虚拟化技术的趋势在传统单层网络基础上叠加一层逻辑网络。这将网络分为两个层次,传统单层网络称为Underlay (承载网络),叠加其上的逻辑网络称为Overlay (叠加网络或覆盖网络)。Overlay网络的节点通过虚拟的或逻辑的连接进行通信,每一个虚拟的或逻辑的连接对应于Underlay网络的一条路径,由多个前后衔接的连接组成。Overlay网络无须对基础网络进行大规模修改,不用关心这些底层实现,是实现云网融合的关键。
VXLAN、GRE、GENEVE都是基于隧道技术的overlay网络。
VLAN和VXLAN:vlan是虚拟局域网,通过不同的vlan标签进行网络隔离;vxlan是vlan的扩展,能充分利用三层路由,解决传统vlan和物理设备的环境限制问题,并且比vlan支持更多的网段,基于udp协议。
简单理解:随着目前互联网技术的发展,对于网络部分,使用虚拟化的方案,实现对传统网络的扩展,利用叠加的方式,常用的叠加网络VXLAN、GRE。
4.4.4、openstack中的网络基本架构
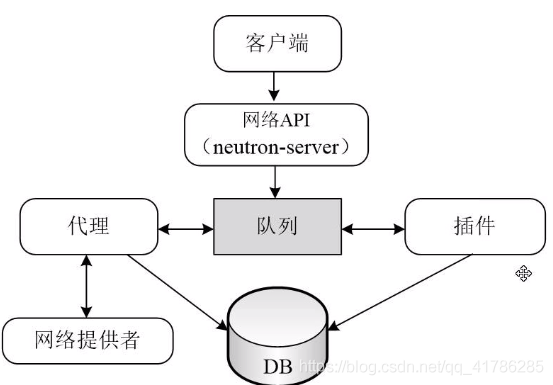
- Neutron仅有一个主要服务进程neutron-server。它是运行在控制节点上的,对外提供Openstack网络API作为访问Neutron的入口,收到请求后调用插件进行处理,最终由计算节点和网络节点上的各种代理完成请求。
- 网络提供者是指提供OpenStack网络服务的虚拟或物理网络设备,如Linux Bridge、Open vSwitch,或者其他支持Neutron的物理交换机。
- 与其他服务一样,Neutron的各组件服务之间需要相互协调和通信,neutron-server. 插件和代理之间通过消息队列进行通信和相互调用。
- 数据库用于存放OpenStack的网络状态信息,包括网络、子网、端口、路由器等。
- 客户端是指使用Neutron服务的应用程序,可以是命令行工具、Horizon和Nova计算服务等。
实例:以一个创建VLAN 100虚拟网络的流程为例说明这些组件如何协同工作。
- neutron-server收到创建网络的请求,通过消息队列通知已注册的Linux Bridge插件。(插件可以有很多,这里举例创建虚拟网络的插件是Linux Bridge插件)
- 该插件将要创建的网络信息(如名称、VLAN ID等)保存到数据库中,并通过消息队列通知运行在各节点上的代理
- 代理收到消息后会在节点上的物理网卡上创建VLAN设备(比如eth1.100),并创建一个网桥(比如brqxxx)来桥接VLAN设备。
neutron-server详解:
结构:
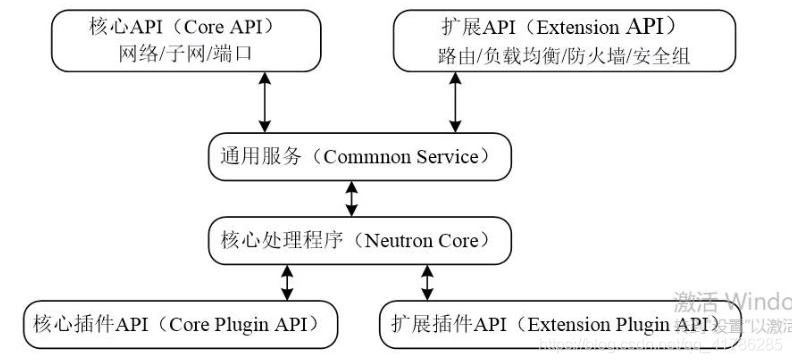
- RESTful API:直接对客户端提供API服务,属于最前端的API,包括Core API和Extension API两种类型。Core API提供管理网络、子网和端口核心资源的RESTful API; Extension API则提供管理路由器、防火墙、负载均衡、安全组等扩展资源的RESTful API。
- Common Service:通用服务,负责对API请求进行检验、认证,并授权。
- Neutron Core:核心处理程序,调用相应的插件API来处理API请求。
- Plugin API:定义插件的抽象功能集合,提供调用插件的API接口,包括Core Plugin API 和 ExtensionPlugin API两种类型。Neutron Core通过Core Plugin API调用相应的Core Plugin

 浙公网安备 33010602011771号
浙公网安备 33010602011771号