分类算法--knn算法
一.什么是knn算法
1.简介
K最近邻(k-Nearest Neighbor,KNN)分类算法可以说是最简单的机器学习算法了。它采用测量不同特征值之间的距离方法进行分类。它的思想很简单:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。
2.算法分析
kNN算法的核心思想是用距离最近的k个样本数据的分类来代表目标数据的分类。
其原理具体地讲,存在一个训练样本集,这个数据训练样本的数据集合中的每个样本都包含数据的特征和目标变量(即分类值),输入新的不含目标变量的数据,将该数据的特征与训练样本集中每一个样本进行比较,找到最相似的k个数据,这k个数据出席那次数最多的分类,即输入的具有特征值的数据的分类。
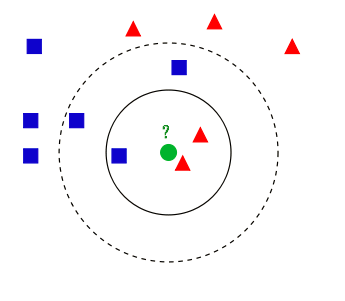
例如,训练样本集中包含一系列数据,这个数据包括样本空间位置(特征)和分类信息(即目标变量,属于红色三角形还是蓝色正方形),要对中心的绿色数据的分类。运用kNN算法思想,距离最近的k个样本的分类来代表测试数据的分类,那么:
当k=3时,距离最近的3个样本在实线内,具有2个红色三角和1个蓝色正方形**,因此将它归为红色三角。
当k=5时,距离最近的5个样本在虚线内,具有2个红色三角和3个蓝色正方形**,因此将它归为蓝色正方形。
3.特点
一.优点
(1)监督学习:可以看到,kNN算法首先需要一个训练样本集,这个集合中含有分类信息,因此它属于监督学习。
(2)通过计算距离来衡量样本之间相似度,算法简单,易于理解和实现。
(3)对异常值不敏感
二.缺点
(4)需要设定k值,结果会受到k值的影响,通过上面的例子可以看到,不同的k值,最后得到的分类结果不尽相同。k一般不超过20。
(5)计算量大,需要计算样本集中每个样本的距离,才能得到k个最近的数据样本。
(6)训练样本集不平衡导致结果不准确问题。当样本集中主要是某个分类,该分类数量太大,导致近邻的k个样本总是该类,而不接近目标分类。
4.流程分析

5.使用knn算法进行简单的测试示例一
(1).knn算法测试代码
from numpy import * import operator #1.构造KNN算法分类器函数 #定义KNN算法分类器函数 #函数参数包括:(测试数据,训练数据,分类,k值) def classify(inX,dataSet, labels, k): dataSetSize = dataSet.shape[0] diffMat = tile(inX,(dataSetSize,1))-dataSet sqDiffMat=diffMat**2 sqDistances=sqDiffMat.sum(axis=1) distances=sqDistances**0.5 #计算欧式距离 sortedDistIndicies=distances.argsort() #排序并返回index #选择距离最近的k个值 classCount={} for i in range(k): voteIlabel=labels[sortedDistIndicies[i]] #D.get(k[,d]) -> D[k] if k in D, else d. d defaults to None. classCount[voteIlabel]=classCount.get(voteIlabel,0)+1 #排序 sortedClassCount=sorted(classCount.items(),key=operator.itemgetter(1),reverse=True) return sortedClassCount[0][0] #2.构造一个生成生成数据的的函数 #定义一个生成“训练样本集”的函数,包含特征和分类信息 def createDataSet(): group=array([[1,1.1],[1,1],[0,0],[0,0.1]]) labels=['A','A','B','B'] return group,labels #3.约会网站数据的测试 #定义一个将文本转化为numpy的函数 def file2matrix(filepath): fr=open(filepath)#读取文件 arraylines=fr.readlines() numberOfLines=len(arraylines)#得到行数 returnMat=zeros((numberOfLines,3))#构造全为0的零矩阵 classLabelVector= [] index=0 #解析文件 for line in arraylines: line=line.strip() #删除空白符(包括'\n', '\r', '\t', ' ') listFromLine=line.split('\t') #按照('\t')进行拆分 returnMat[index,:]=listFromLine[0:3] #得到特征变量 classLabelVector.append(listFromLine[-1]) #得到目标分类变量 index+=1 return returnMat,classLabelVector #3.归一化处理函数 def autoNorm(dataSet): minVals=dataSet.min(0) #最小值 maxVals=dataSet.max(0) #最大值 ranges=maxVals-minVals #最大最小值之差 normDataSet=zeros(shape(dataSet)) #构造零矩阵 m=dataSet.shape[0] #行数,shape返回[nrow,ncol] normDataSet=dataSet-tile(minVals,(m,1))#tile复制minval normDataSet=normDataSet/tile(ranges,(m,1)) return normDataSet,ranges,minVals #4.定义测试算法的函数 def datingClassTest(h=0.1): hoRatio=h #测试数据的比例 datingDataMat,datingLabels=file2matrix(r'D:\project\test\datingTestSet2.txt') #准备数据 normMat,ranges,minVals=autoNorm(datingDataMat) #归一化处理 m=normMat.shape[0] #得到行数 numTestVecs=int(m*hoRatio) #测试数据行数 errorCount=0 #定义变量来存储错误分类数 for i in range(numTestVecs): classifierResult=classify(normMat[i,:],normMat[numTestVecs:m,:],datingLabels[numTestVecs:m],3) print('the classifier came back with: %d,the real answer is: %d'%(int(classifierResult),int(datingLabels[i]))) if (classifierResult!=datingLabels[i]): errorCount+=1 print('the total error rate is : %f'%(errorCount/float(numTestVecs))) #5.使用knn算法进行预测 def classifypersion(): resultList=['not at all','in small doses','in large doses'] percentTats=float(input('percentage of time spent playing video games?')) #raw_input->input,录入数据 ffMiles=float(input('frequent flier miles earned per year?')) iceCream=float(input('liters of ice creamconsued per year?')) datingDataMat,datingLabels =file2matrix(r'D:\project\test\datingTestSet2.txt') normMat,ranges,minVals=autoNorm(datingDataMat) inArr=array([ffMiles,percentTats,iceCream]) classifierResult=classify((inArr-minVals/ranges),normMat,datingLabels,3) print('You will probably like this persion :%s'%resultList[int(classifierResult)-1])
(2).对 上述的代码进行测试
#1.对生成训练样本集合测试的数据进行简单的测试 from knn import KNN #生成训练样本 group,labels=KNN.createDataSet() #对测试数据[0,0]进行KNN算法分类测试 a=KNN.classify([0,0],group,labels,3) print(a) #2.对约会网站的的数据转变成numpy格式的数据进行测试 datingDataMat,datingLabels=KNN.file2matrix(r'D:\project\test\datingTestSet2.txt') print(datingDataMat) print(datingLabels[:10]) #3.可视化数据分析 #运用Matplotlib创建散点图来分析数据: import matplotlib.pyplot as plt #对第二列和第三列数据进行分析: fig=plt.figure() ax=fig.add_subplot(111) ax.scatter(datingDataMat[:,1],datingDataMat[:,2],c=datingLabels) plt.xlabel('Percentage of Time Spent Playing Video Games') plt.ylabel('Liters of Ice Cream Consumed Per Week') plt.show() #对第一列和第二列进行分析: fig=plt.figure() ax=fig.add_subplot(111) ax.scatter(datingDataMat[:,0],datingDataMat[:,1],c=datingLabels) plt.xlabel('Miles of plane Per year') plt.ylabel('Percentage of Time Spent Playing Video Games') ax.legend(loc='best') plt.show() #4.对数据归一化函数进行测试 from imp import reload print(reload(KNN)) normMat,ranges,minVals=KNN.autoNorm(datingDataMat) print(normMat,'\n') print(ranges,'\n') print(minVals,'\n') #5.对knn算法测试函数进行测试 print(KNN.datingClassTest(0.3)) #6.对使用knn算法进行预测函数进行测试 print(KNN.classifypersion())

 浙公网安备 33010602011771号
浙公网安备 33010602011771号