

linxu centos7 搭建elk7.11(elasticsearch7.11,logstash7.10,kibana7.11,filebeat7.11)
搭建elk,本人用了三台服务器,elasticsearch一主两从,其他的都是单节点。本人在华为云镜像上下载的: https://mirrors.huaweicloud.com/home
下载安装的软加入下
- elasticsearch 7.11 端口号:外部 9200,内部 9300
- logstash 7.10(logstash没有7.11版本) 端口号:5044
- kibana 7.11 端口号:5601
- filebeat 7.11 端口号:没有,这里让filebeat监听logstash的端口号5044
logstash,kibana,filebeat都放到了11.249.2.12上(因为服务器不够用)
三台服务器
- 11.249.2.11
- 11.249.2.12
- 11.249.2.13
总结启动命令,我们统一使用esuser来启动
启动elasticsearch
# 启动elasticsearch,三台服务都要启动 su esuser # 后台启动 ./elasticsearch -d # 前台启动 ./elasticsearch
# 浏览器访问
11.249.3.12:9200
启动logstash
su esuser -- 前台启动,可以看到信息 /usr/local/logstash-7.11.0/bin/logstash -f /usr/local/logstash-7.11.0/script/logstash-script.conf -- nohup:后台启动 nohup /usr/local/logstash-7.11.0/bin/logstash -f /usr/local/logstash-7.11.0/script/logstash-script.conf &
启动filebeat
su esuser # 进入filebeat目录 cd /usr/local/filebeat-7.11.1 # 运行filebeat nohup ./filebeat & # 查看运行状态 ps -ef |grep filebeat # 关闭filebeat kill -9 pid
启动kibana
su esuser /usr/local/kibana-7.11.1/bin/kibana & # 浏览器访问 11.249.3.12:5601
kibana通过nginx转发,请看最后
elasticsearch通过nginx转发请看最后
一 安装elasticsearch
1.1 将下载好的tar包放到服务器上
其中elasticsearch要分别放到三台服务器上,因为要做集群。其他的放到需要安装的服务器上。

1.2 解压elasticsearch,三台服务器需要同时操作
tar -zxvf elasticsearch-7.11.1-linux-x86_64.tar.gz
## 移动到 /usr/local 目录下并重命名
mv elasticsearch-7.11.1-linux-x86_64 /usr/local/elasticsearch-7.11.1
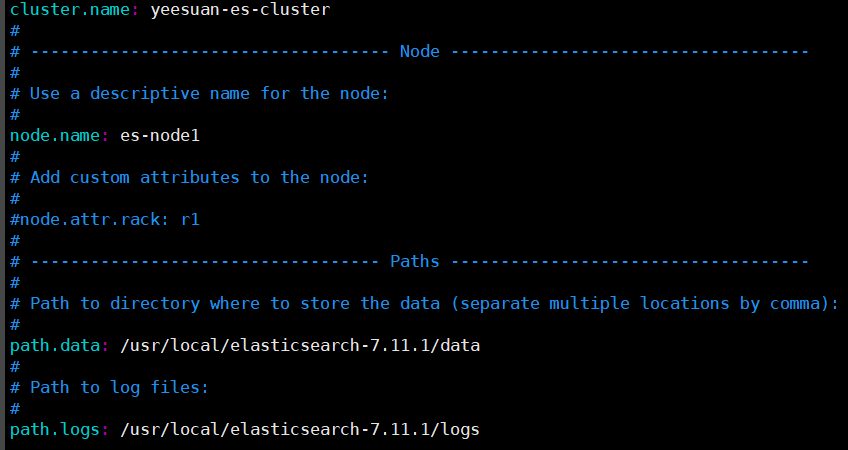
1.3 修改配置文件 elasticsearch.yml,三台服务器都要修改
// 进入目录 cd /usr/local/elasticsearch-7.11.1/config vim elasticsearch.yml
三台机器的配置文件,只有node.name不同
# 集群名称,三台机器要统一
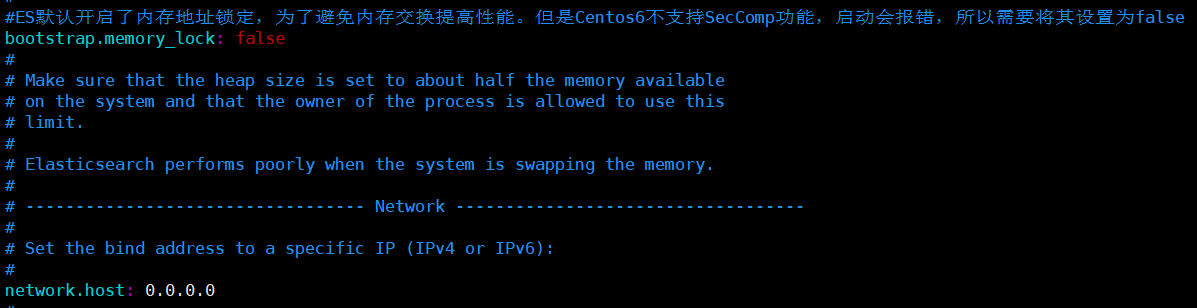
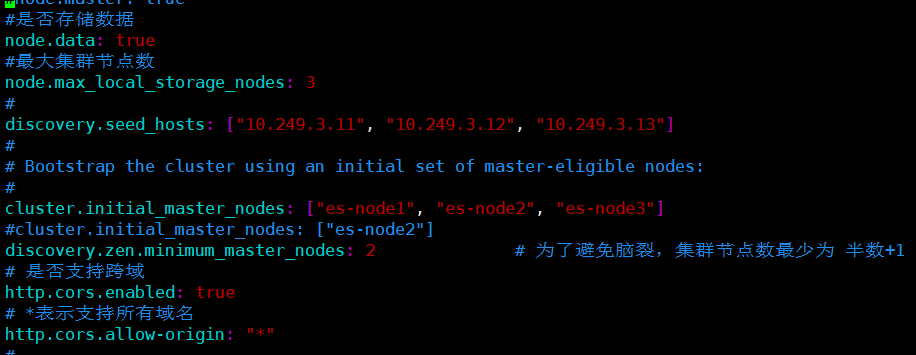
cluster.name: yeesuan-es-cluster # 节点名称(三台机器名称不同) node.name: es-node1 # 数据路径 path.data: /usr/local/elasticsearch-7.11.1/data # 日志路径 path.logs: /usr/local/elasticsearch-7.11.1/logs # ES默认开启了内存地址锁定,为了避免内存交换提高性能。但是Centos6不支持SecComp功能,启动会报错,所以需要将其设置为false bootstrap.memory_lock: false # 允许所有的网络访问 network.host: 0.0.0.0 #是否存储数据,三台机器都设置为true node.data: true #最大集群节点数 node.max_local_storage_nodes: 3 # 三台节点的ip discovery.seed_hosts: ["11.249.3.11", "11.249.3.12", "11.249.3.13"] # 是否允许选举主节点,三台节点的名称 cluster.initial_master_nodes: ["es-node1", "es-node2", "es-node3"] discovery.zen.minimum_master_nodes: 2 # 为了避免脑裂,集群节点数最少为 半数+1 # 是否支持跨域 http.cors.enabled: true # *表示支持所有域名 http.cors.allow-origin: "*"
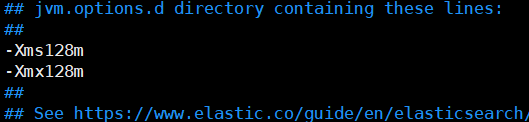
1.4 修改配置文件 jvm.options,三台服务器都要修改
cd /usr/local/elasticsearch-7.11.1/config vim jvm.options
修改Xms和Xmx,我的机器内存比较小,所以设置为128m
1.5 修改默认jdk路径,三台服务器都要修改
文件有两个 1 /bin/elasticsearch,2 /bin/elasticsearch.cli
由于我这边环境JDK使用的1.8,而ElasticSearch7.11.1要求JDK版本必须为JDK11+,否则启动会报错,在这种情况下如想在不升级环境JDK版本下启动ES需修改ES的JDK配置,其实ElasticSearch7.X安装包中都自带有JDK(系统无配置JDK环境变量时启动会使用自带JDK),我这里通过修改bin目录下elasticsearch和elasticsearch-cli来指向自带JDK。
1)/bin/elasticsearch,下图中标记的是新增的部分
cd /usr/local/elasticsearch-7.11.1/bin vim elasticsearch
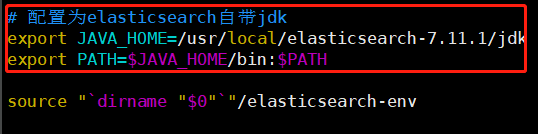
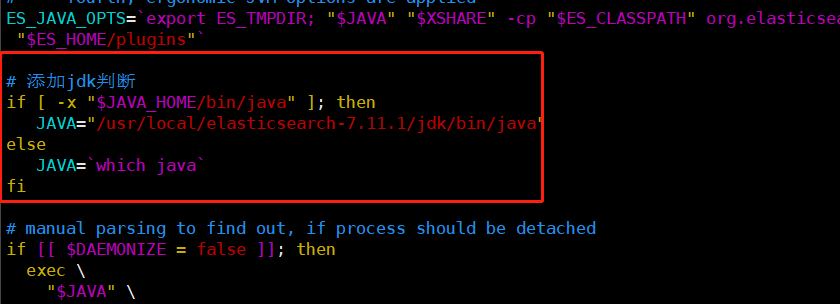
本人配置文件如下
#!/bin/bash # CONTROLLING STARTUP: # # This script relies on a few environment variables to determine startup # behavior, those variables are: # # ES_PATH_CONF -- Path to config directory # ES_JAVA_OPTS -- External Java Opts on top of the defaults set # # Optionally, exact memory values can be set using the `ES_JAVA_OPTS`. Example # values are "512m", and "10g". # # ES_JAVA_OPTS="-Xms8g -Xmx8g" ./bin/elasticsearch # 配置为elasticsearch自带jdk export JAVA_HOME=/usr/local/elasticsearch-7.11.1/jdk export PATH=$JAVA_HOME/bin:$PATH source "`dirname "$0"`"/elasticsearch-env CHECK_KEYSTORE=true DAEMONIZE=false for option in "$@"; do case "$option" in -h|--help|-V|--version) CHECK_KEYSTORE=false ;; -d|--daemonize) DAEMONIZE=true ;; esac done if [ -z "$ES_TMPDIR" ]; then ES_TMPDIR=`"$JAVA" "$XSHARE" -cp "$ES_CLASSPATH" org.elasticsearch.tools.launchers.TempDirectory` fi # get keystore password before setting java options to avoid # conflicting GC configurations for the keystore tools unset KEYSTORE_PASSWORD KEYSTORE_PASSWORD= if [[ $CHECK_KEYSTORE = true ]] \ && bin/elasticsearch-keystore has-passwd --silent then if ! read -s -r -p "Elasticsearch keystore password: " KEYSTORE_PASSWORD ; then echo "Failed to read keystore password on console" 1>&2 exit 1 fi fi # The JVM options parser produces the final JVM options to start Elasticsearch. # It does this by incorporating JVM options in the following way: # - first, system JVM options are applied (these are hardcoded options in the # parser) # - second, JVM options are read from jvm.options and jvm.options.d/*.options # - third, JVM options from ES_JAVA_OPTS are applied # - fourth, ergonomic JVM options are applied ES_JAVA_OPTS=`export ES_TMPDIR; "$JAVA" "$XSHARE" -cp "$ES_CLASSPATH" org.elasticsearch.tools.launchers.JvmOptionsParser "$ES_PATH_CONF" "$ES_HOME/plugins"` # 添加jdk判断 if [ -x "$JAVA_HOME/bin/java" ]; then JAVA="/usr/local/elasticsearch-7.11.1/jdk/bin/java" else JAVA=`which java` fi # manual parsing to find out, if process should be detached if [[ $DAEMONIZE = false ]]; then exec \ "$JAVA" \ "$XSHARE" \ $ES_JAVA_OPTS \ -Des.path.home="$ES_HOME" \ -Des.path.conf="$ES_PATH_CONF" \ -Des.distribution.flavor="$ES_DISTRIBUTION_FLAVOR" \ -Des.distribution.type="$ES_DISTRIBUTION_TYPE" \ -Des.bundled_jdk="$ES_BUNDLED_JDK" \ -cp "$ES_CLASSPATH" \ org.elasticsearch.bootstrap.Elasticsearch \ "$@" <<<"$KEYSTORE_PASSWORD" else exec \ "$JAVA" \ "$XSHARE" \ $ES_JAVA_OPTS \ -Des.path.home="$ES_HOME" \ -Des.path.conf="$ES_PATH_CONF" \ -Des.distribution.flavor="$ES_DISTRIBUTION_FLAVOR" \ -Des.distribution.type="$ES_DISTRIBUTION_TYPE" \ -Des.bundled_jdk="$ES_BUNDLED_JDK" \ -cp "$ES_CLASSPATH" \ org.elasticsearch.bootstrap.Elasticsearch \ "$@" \ <<<"$KEYSTORE_PASSWORD" & retval=$? pid=$! [ $retval -eq 0 ] || exit $retval if [ ! -z "$ES_STARTUP_SLEEP_TIME" ]; then sleep $ES_STARTUP_SLEEP_TIME fi if ! ps -p $pid > /dev/null ; then exit 1 fi exit 0 fi exit $?
2) /bin/elasticsearch.cli
和elasticsearch一样,这里直接贴代码了
#!/bin/bash set -e -o pipefail # 配置为elasticsearch自带jdk export JAVA_HOME=/usr/local/elasticsearch-7.11.1/jdk export PATH=$JAVA_HOME/bin:$PATH source "`dirname "$0"`"/elasticsearch-env IFS=';' read -r -a additional_sources <<< "$ES_ADDITIONAL_SOURCES" for additional_source in "${additional_sources[@]}" do source "$ES_HOME"/bin/$additional_source done IFS=';' read -r -a additional_classpath_directories <<< "$ES_ADDITIONAL_CLASSPATH_DIRECTORIES" for additional_classpath_directory in "${additional_classpath_directories[@]}" do ES_CLASSPATH="$ES_CLASSPATH:$ES_HOME/$additional_classpath_directory/*" done # use a small heap size for the CLI tools, and thus the serial collector to # avoid stealing many CPU cycles; a user can override by setting ES_JAVA_OPTS ES_JAVA_OPTS="-Xms4m -Xmx64m -XX:+UseSerialGC ${ES_JAVA_OPTS}" # 添加jdk判断 if [ -x "$JAVA_HOME/bin/java" ]; then JAVA="/usr/local/elasticsearch-7.11.1/jdk/bin/java" else JAVA=`which java` fi exec \ "$JAVA" \ "$XSHARE" \ $ES_JAVA_OPTS \ -Des.path.home="$ES_HOME" \ -Des.path.conf="$ES_PATH_CONF" \ -Des.distribution.flavor="$ES_DISTRIBUTION_FLAVOR" \ -Des.distribution.type="$ES_DISTRIBUTION_TYPE" \ -cp "$ES_CLASSPATH" \ "$ES_MAIN_CLASS" \ "$@"
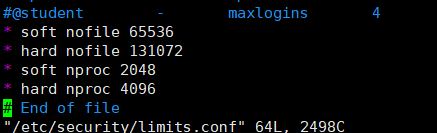
1.6 编辑limits.conf配置文件(解决无法创建本地文件问题,用户最大可创建文件数太小),三台服务器都要修改
vim /etc/security/limits.conf
添加以下配置
注:* 代表Linux所有用户名称
* soft nofile 65536 * hard nofile 131072 * soft nproc 2048 * hard nproc 4096
1.7 编辑/etc/sysctl.conf配置文件(解决最大虚拟内存太小),三台服务器都要修改
vim /etc/sysctl.conf
# 添加如下配置: vm.max_map_count=262144

保存后执行命令,进行刷新
sysctl -p
1.8 创建用户用来启动es(我们同样使用这个用户来启动:filebeat,kibana,logstash),三台服务器都要修改
# 创建用户 useradd esuser cd /usr/local/elasticsearch-7.11.1 # 授权 chown -R esuser /usr/local/elasticsearch-7.11.1 chown -R esuser:esuser /usr/local/elasticsearch-7.11.1
启动,先启动es-node1,然后在启动其他两台
# 使用创建的用户进行启动 su esuser # 后台启动 ./elasticsearch -d # 前台启动 ./elasticsearch
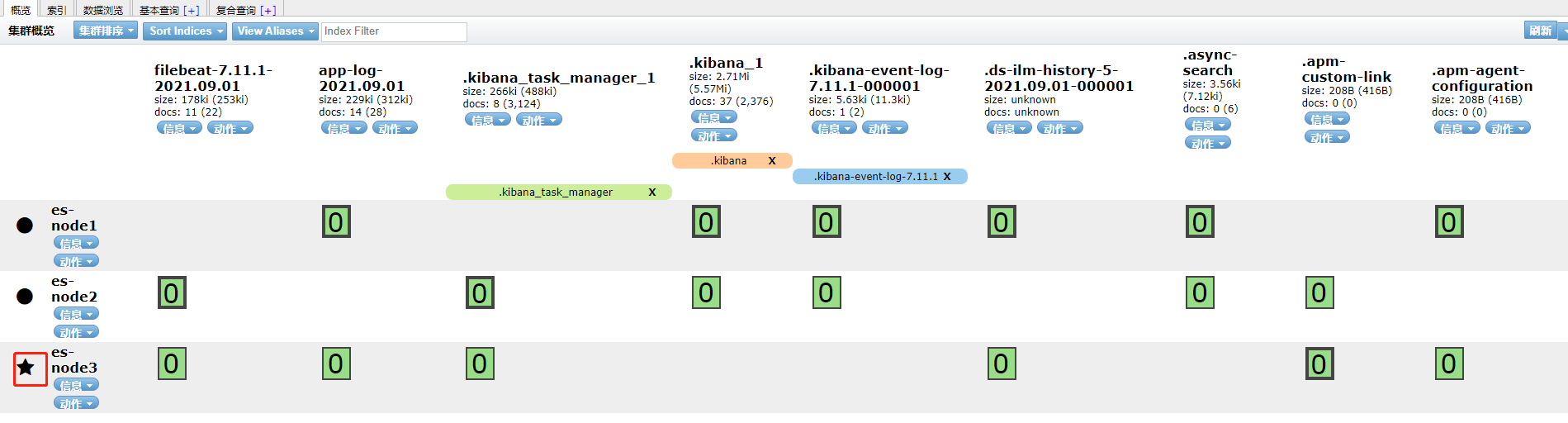
# 访问一下,出现下图就表示成功了。 11.249.2.11:9200 11.249.2.12:9200 11.249.2.13:9200

使用Chrome插件来访问,如下图,有三台节点。其中es-node3是主节点(前面有个星号)
二 安装logstash
2.1 解压并移动
tar -zxvf logstash-7.11.0-linux-x86_64.tar.gz mv logstash-7.11.0-linux-x86_64 /usr/local/logstash-7.11.0
2.2 编辑配置文件
1) 将原来的logstash-sample.conf复制一份为:logstash.conf
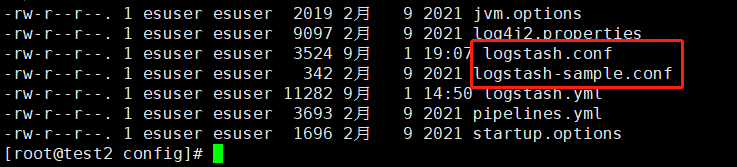
cd /usr/local/logstash-7.11.0/config # 拷贝 cp logstash-sample.conf ./logstash.conf
vim logstash.conf
具体配置文件如下:
# Sample Logstash configuration for creating a simple
# Beats -> Logstash -> Elasticsearch pipeline.
input {
beats {
client_inactivity_timeout => 3000
port => 5044
}
}
filter {
## 时区转换
ruby {
code => "event.set('index_time',event.timestamp.time.localtime.strftime('%Y.%m.%d'))"
}
# 这里的fields和service要和filebeat中的对应起来
if [fields][service] == "app-log"{
grok {
## 表达式
match => ["message", "\[%{NOTSPACE:currentDateTime}\] \[%{NOTSPACE:level}\] \[%{NOTSPACE:thread-id}\] \[%{NOTSPACE:class}\] \[%{DATA:hostName}\] \[%{DATA:ip}\] \[%{DATA:applicationName}\] \[%{DATA:location}\] \[%{DATA:messageInfo}\] ## (\'\'|%{QUOTEDSTRING:throwable})"]
}
}
if [fields][service] == "error-log"{
grok {
## 表达式
match => ["message", "\[%{NOTSPACE:currentDateTime}\] \[%{NOTSPACE:level}\] \[%{NOTSPACE:thread-id}\] \[%{NOTSPACE:class}\] \[%{DATA:hostName}\] \[%{DATA:ip}\] \[%{DATA:applicationName}\] \[%{DATA:location}\] \[%{DATA:messageInfo}\] ## (\'\'|%{QUOTEDSTRING:throwable})"]
}
}
}
# 输出到elasticsearch,这里的fields和services要和filebeat中的对应起来
output {
if [fields][service] == "app-log" {
elasticsearch {
hosts => ["http://10.249.3.11:9200","http://10.249.3.12:9200","http://10.249.3.13:9200"]
#index => "%{[@metadata][beat]}-%{[@metadata][version]}-%{+YYYY.MM.dd}"
index => "%{[fields][service]}-%{index_time}"
#user => "elastic"
#password => "changeme"
}
}else if [fields][service] == "error-log" {
elasticsearch {
hosts => ["http://10.249.3.11:9200","http://10.249.3.12:9200","http://10.249.3.13:9200"]
#index => "%{[@metadata][beat]}-%{[@metadata][version]}-%{+YYYY.MM.dd}"
index => "%{[fields][service]}-%{index_time}"
#user => "elastic"
#password => "changeme"
}
}
}
2)配置logstash.yml
cd /usr/local/logstash-7.11.0/config # 拷贝 cp logstash-sample.conf ./logstash.conf vim logstash.yml
path.data: /usr/local/logstash-7.11.0/data path.logs: /usr/local/logstash-7.11.0/logs pipeline.ordered: auto http.host: 0.0.0.0 xpack.monitoring.enabled: true xpack.monitoring.elasticsearch.hosts: ["11.249.3.11:9200", "11.249.3.12:9200", "11.249.3.13:9200"]
启动logstash
-- 前台启动,可以看到信息 /usr/local/logstash-7.11.0/bin/logstash -f /usr/local/logstash-7.11.0/script/logstash-script.conf -- nohup:后台启动 nohup /usr/local/logstash-7.11.0/bin/logstash -f /usr/local/logstash-7.11.0/script/logstash-script.conf & # 也可以使用上面创建的用户来启动 # 授权 chown -R esuser /usr/local/logstash-7.11.0 chown -R esuser:esuser /usr/local/logstash-7.11.0 su esuser
三 安装filebeat
3.1 解压并移动
tar -zxvf filebeat-7.11.1-linux-x86_64.tar.gz mv tar filebeat-7.11.1-linux-x86_64 /usr/local/filebeat-7.11.1
3.2 配置配置文件
cd /usr/local/filebeat-7.11.1 vim filebeat.yml
- 配置日志收集路径
- 配置不同paths下不同文件,传输到logstash
- 关闭filebeat输出到elasticsearch(这是默认的)
- 打开filebeat输出到logstash
- 本人使用的是7.11.1版本,配置文件中的document_type配置属性舍弃了,取而代之的是fields:service。这里要和logstash中的对应起来
# Paths that should be crawled and fetched. Glob based paths.
paths:
# - /var/log/*.log
- /home/logs/app.log
#- c:\programdata\elasticsearch\logs\*
fields:
service: app-log
- type: log
enabled: true
paths:
- /home/logs/error.log
#- c:\programdata\elasticsearch\logs\*
fields:
service: error-log
# output.elasticsearch:
# Array of hosts to connect to.
# hosts: ["localhost:9200"]
output.logstash:
# The Logstash hosts
hosts: ["11.249.3.12:5044"]
配置文件中我们配置了两个- type: log,作用是将不同的log文件输出到logstash中,并且可以在logstash中通过fields:service: app-log或者fields:service: error-log确定是哪一个log,以便elasticsearch以不同的index输出。详见下面的logstash配置文件。
启动filebeat
# 进入filebeat目录 cd /usr/local/filebeat-7.11.1 # 运行filebeat nohup ./filebeat & # 查看运行状态 ps -ef |grep filebeat # 关闭filebeat kill -9 pid # 也可以使用上面创建的用户来启动 # 授权 chown -R esuser /usr/local/filebeat-7.11.1 chown -R esuser:esuser /usr/local/filebeat7.11.1 su esuser
四 安装kibana
4.1 解压并移动
tar -zxvf kibana-7.11.1-linux-x86_64.tar.gz mv kibana-7.11.1-linux-x86_64 /usr/local/kibana-7.11.1
4.2 配置配置文件
cd /usr/local/kibana-7.11.1/config vim kibana.yml
server.port: 5601 server.host: "0.0.0.0" elasticsearch.hosts: ["http://11.249.3.11:9200","http://11.249.3.12:9200","http://10.249.3.13:9200"] kibana.index: ".kibana" logging.dest: /usr/local/kibana-7.11.1/logs/kibana.log
启动kibana
# kibana不能使用root启动,我们使用之前创建的esuser来启动 # 授权 chown -R esuser /usr/local/kibana-7.11.1 chown -R esuser:esuser /usr/local/kibana-7.11.1 su esuser /usr/local/kibana-7.11.1/bin/kibana &
五 测试
到此所有的服务都已经启动了,我们来测试一下,在filebeat中配置的path目录下的文件中新增信息
vim /home/logs/app.log 添加一些信息在文件里,然后保存退出

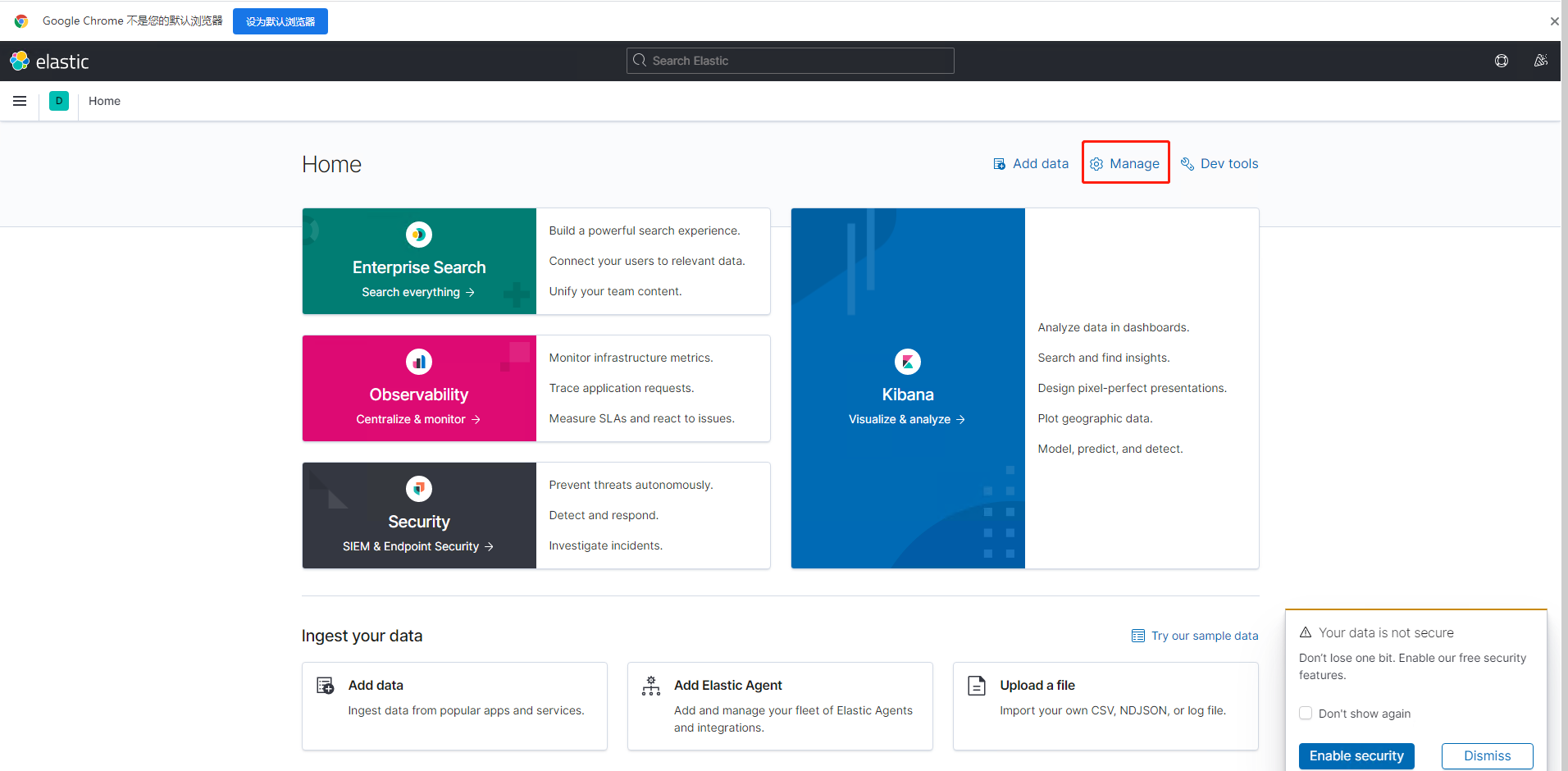
浏览器访问 http://10.249.3.12:5601/app/home#/
1.选择Manage,我们来创建index
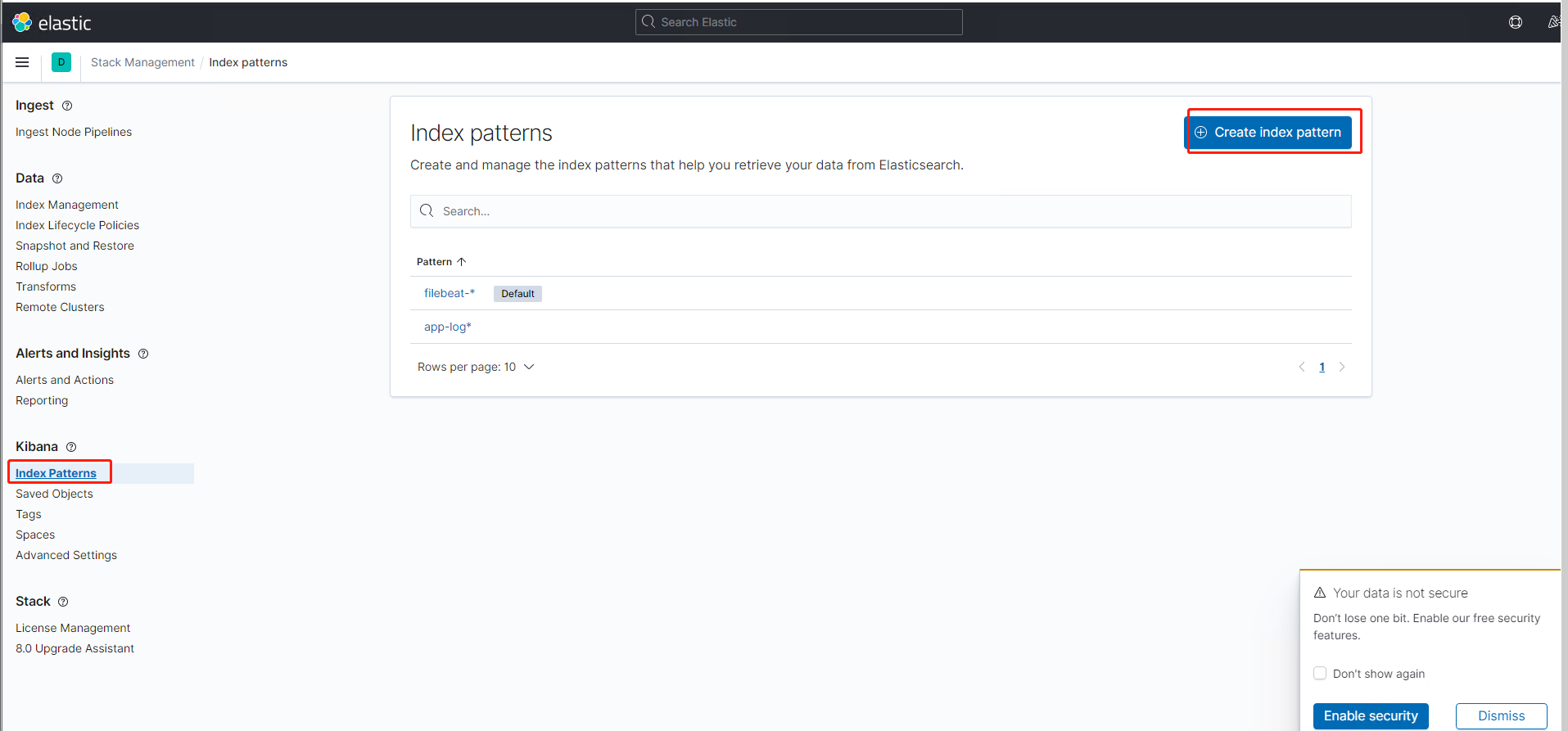
2.选择index pattern --》create index pattern,创建一个新的index
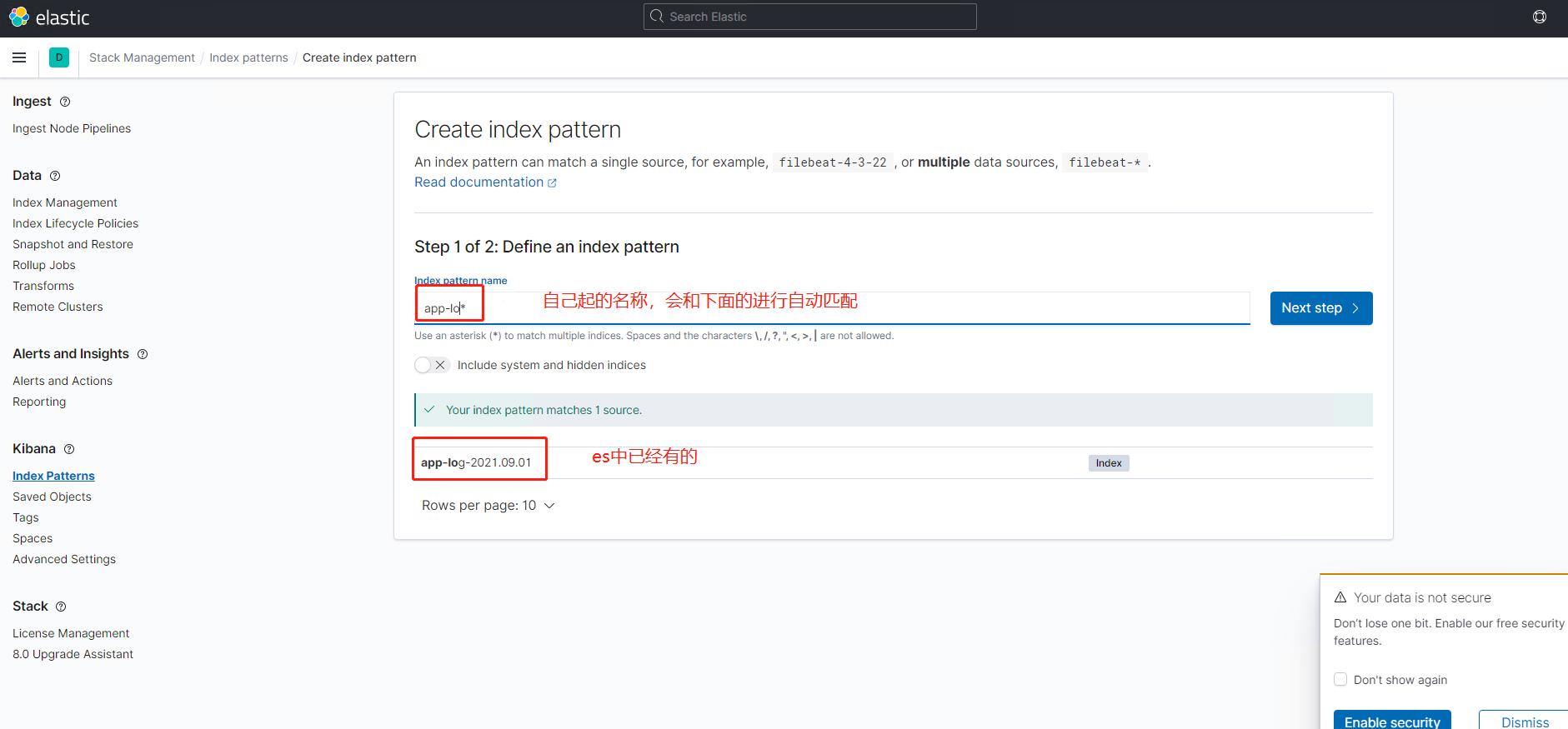
3.填写名称,在填写的时候,会自动匹配,假如说elasticsearch中没有数据的话,会显示为空。然后点击下一步
4.选择@timestamp,然后点击create index pattern。这样就创建完成了
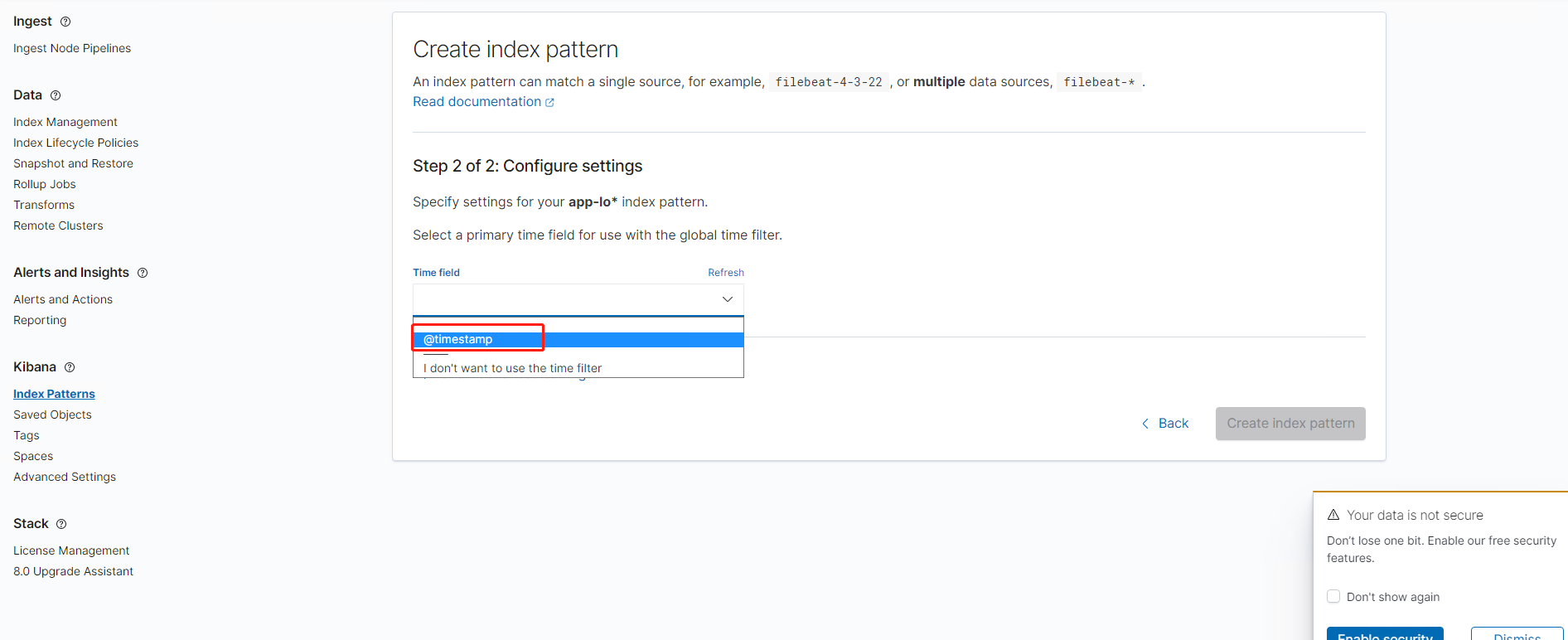
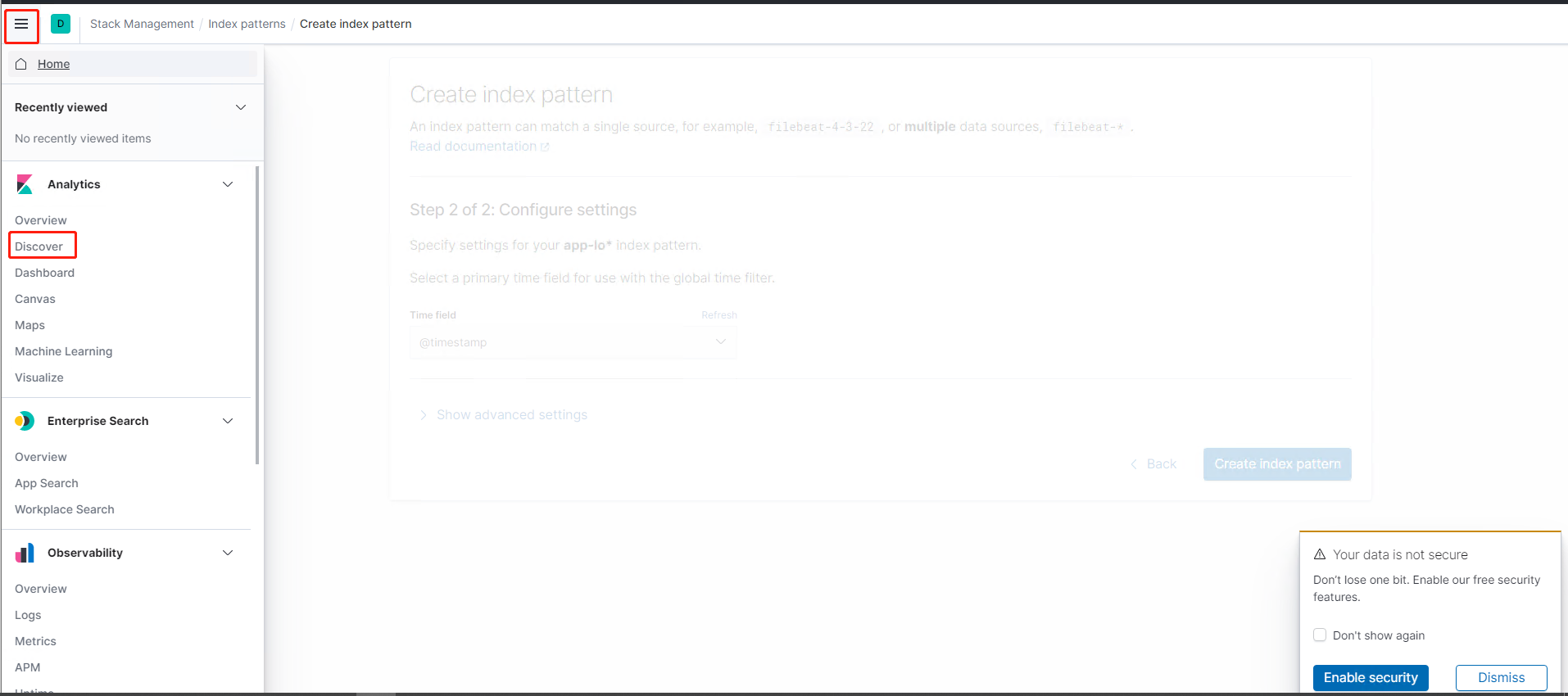
5.选择我们创建的index查看数据
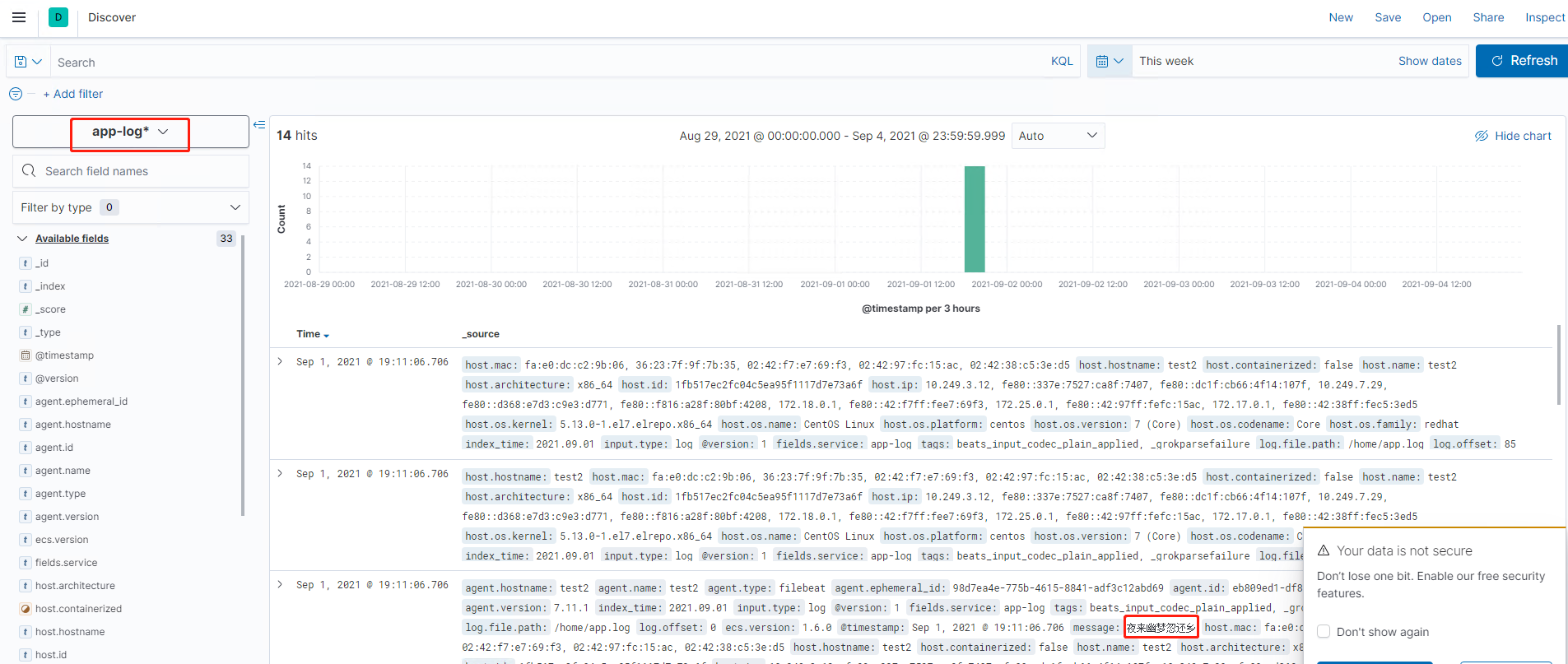
6.可以看到我们的数据,保存在了elasticsearch上,并通过kibana展示了出来。
到此elasticsearch,logstash,kibana,filebeat配置完成。
我们需要nginx转发kibana,按照上面的kibana配置是转发不出来的
六 kibana配置nginx转发
6.1 修改kibana.yml
cd /usr/local/kibana-7.11.1/config/ vim kibana.yml
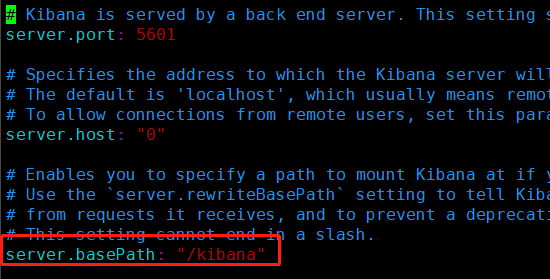
6.2 server.basePath: "/kibana"
/kibana:nginx要和这个对应起来,记得前面加斜杠“/”
6.3 配置nginx
location /kibana/{
proxy_pass http://kibana_host/;
rewrite ^/kibabna/(.*)$ /$1 break;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header Host $host:$server_port;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_http_version 1.1;
}
浏览器访问:http://11.249.2.101:8083/kibana
七 elasticsearch配置nginx转发
这里只需要配置nginx就可以了。
我们这里有三台服务器都安装了elasticsearch,他们是一主两从的关系,所以配置nginx转发的时候,elasticsearch的地址写一个就可以了,不论主从(我们设置了三台节点都作为数据存储了:node.data: true)
所以nginx配置如下,必须加rewrite,不然转不出来(不能通过elasticsearch-header连接)
location /es{
proxy_set_header Host $http_host;
rewrite ^/es/(.*)$ /$1 break;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header REMOTE-HOST $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_pass http://10.249.3.13:9200;
}


 浙公网安备 33010602011771号
浙公网安备 33010602011771号