
Abstract
- Tool: PPL
- Findings:
- queries with adversarial suffixes have a higher perplexity, 可以利用这一点检测
- 仅仅使用perplexity filter对mix of prompt types不合适,会带来很高的假阳率
- Method: 使用Light-GDB根据perplexity和token length filter带有adversarial suffixes的prompts
- base model: GPT-2
- Metric for detection: Perplexity
- \(PPL(x) = exp{-\frac{1}{t}\sum_{i=1}^t{logp(x_i|x_{<i})}}\)
- the exponential of the average negative log-likelihood of the sequence
- Use Metric: \(F_{\beta}\) to assess detection performance
- \(F_{\beta} = (1+\beta^2) \times \frac{precision x recall}{\beta^2 \times precision + recall}\)
- beta = 2
- how to choose beta
- The cost of failing to respond to legitimate inquiries versus the cost of releasing forbidden responses.
- failing to respond to legitimate inquires: false positive
- releasing forbidden responses: false negative
- The expected distribution of different types of prompts, such as English, multilingual, or prompts containing symbols and math.
- The effectiveness of the LLM's built-in defenses or other defensive measures.
4. Data
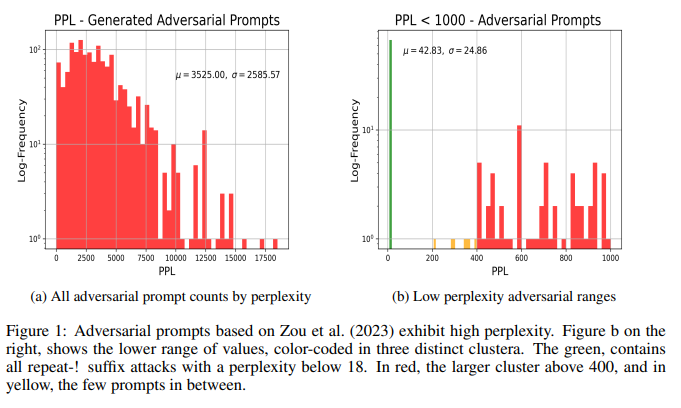
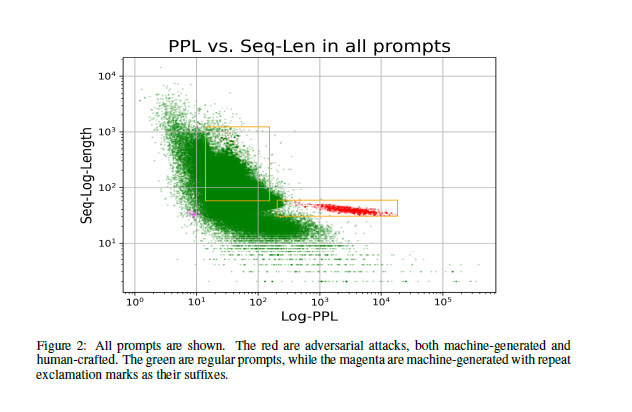
4.2 Adversarial prompt clusters
![]()
4.4 Non-adversarial prompts
- non-adversarial prompts
- 6994 prompts from humans with GPT-4. (see Appendix B.5).
- 998 prompts from the DocRED dataset (see Appendix B.1).
- 3270 prompts from the SuperGLUE (boolq) dataset (see Appendix B.2).
- 11873 prompts from the SQuAD-v2 dataset (see Appendix B.3).
- 24926 prompts with instructions from the Platypus dataset, which were used to train the Platypus models (see Appendix B.4).
- 116862 prompts derived from the “Tapir” dataset by concatenating instructions and input (see Appendix B.6).
- 10000 instructional code search prompts extracted from the instructional code-search-net python dataset (see Appendix B.7).
- adversarial prompts
- 1407 prompts generated from GCG + Vicuna-7b-1.5
- 79 human-designed prompts to break GPT-4
![]()
posted @
2025-02-08 01:46
雪溯
阅读(
56)
评论()
收藏
举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号