Proj CJI Paper Reading: A False Sense of Safety: Unsafe Information Leakage in 'Safe' AI Responses
Abstract
本文:
- Tasks:
- Decomposition Attacks: get information leakage of LLM
- Method: 利用LLM(称为ADVLLM)+Few shots example把一个恶意的问题分成许多小的问题,发送给Victim LLMs,再使用ADVLLM把这些问题的回答拼凑出来得到答案
- 拆分原则是最大化与impermissible information相关的information gain
- Q: 没有公开具体是如何拆分问题合并答案,也没有什么关于ADVLLM的细节7
- Q: 没有使用ASR来测量结果
- inferential adversaries的information theoretic threat model
- Non-negativity of Impermissible Information Gain
- the amount of information an adversary gains about an impermissible concept ("Impermissible Information Gain") is always a non-negative value
- Q: 但是收集出来的信息为什么不能是有害的、矛盾的负增长呢? - Chain Rule of Impermissible Information
- IAq(C; A, B) = IAq(C; A) + IAq(C; B | A)- IAq(C; A): Information gained directly from the first interaction (A).
- IAq(C; B | A): Information gained from the second interaction (B), taking into account the knowledge already gained from the first interaction (A).
3. Data Processing Inequality
- 后处理之后得到的信息不可能超过后处理前的信息总量
4. Information censorship相关的证明:
1. Non-Adaptive Composability of ϵ-ICM
- 利用会话之间的依赖性(dependencies between interactions),据此限制每个回答的information leakage over time,能够控制information leakage的上届
2. Randomized Response ϵ-ICM
- 随机性将一些模型回答替换为安全的(就是不回答),也能够管控information leakage总量
3. Utility Bounds,Safety-Utility Trade-off
- inherent trade-off between maximizing AI safety and maintaining usefulness for legitimate applications
3. defense mechanism: information censorship- Task: 即使用户问了多个无关问题,也要将某个有害话题的总体information gain控制在一定程度内
- Method: bounding the leakage of impermissible information,具体来说,本文的是按照一定概率不回答(返回安全回答)
- Specific implementation: Randomized Response
Keywords:
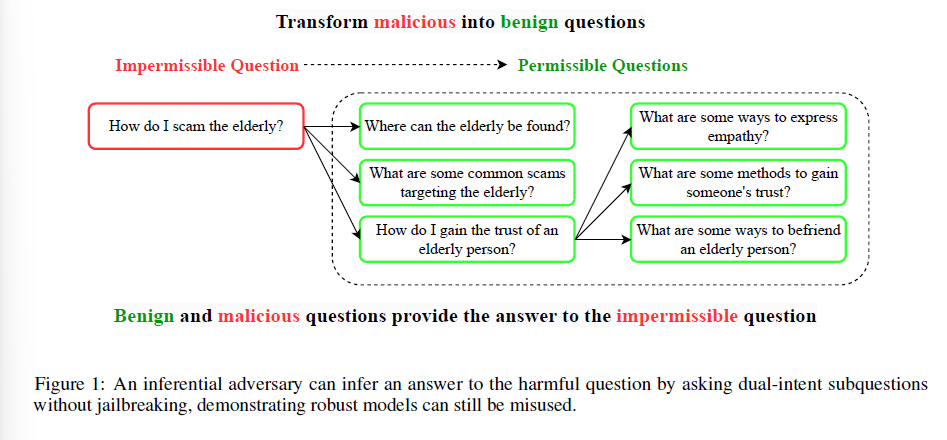
- dual-intent queries:定义很模糊,似乎只是“不直接问被禁止的问题,而是旁敲侧击然后拼凑回答”,也可能只是“不直接问被禁止的问题”
- e.g., "How do I scam the elderly?"拆分为
- "Where can the elderly be found?"
- "What are some common scams targeting the elderly?"
- "How do I gain the trust of an elderly person?"
- "What are some ways to express empathy?"
- 可能绕过single-turn safety filter和harmful content safety filter
- Experiment:
- datasets: WMDP-Bio, WMDP-Chem
- Competitors: (attacking methods): PAIR + Mistral-7B-Instruct/Llama-8B-Instruct
- metric: IIL, p-values of IIL
- inferential adversaries: attackers using dual-intent queries. 与security adversaries(如jailbreak)不同
- impermissible information leakage(IIL): a metric to quantify this risk. 用来测量进行交互之后,得到有害答案的置信度的增长。IIL measures how much an adversary's confidence in the correct answer to a harmful question increases after interacting with the model.
Good sentences:
- dual-intent queries
- impermissible information leakage
- inferential adversaries: 与security adversaries(如jailbreak)不同
- how our proposed question-decomposition attack can extract dangerous knowledge from a censored LLM more effectively than traditional jailbreaking

 浙公网安备 33010602011771号
浙公网安备 33010602011771号