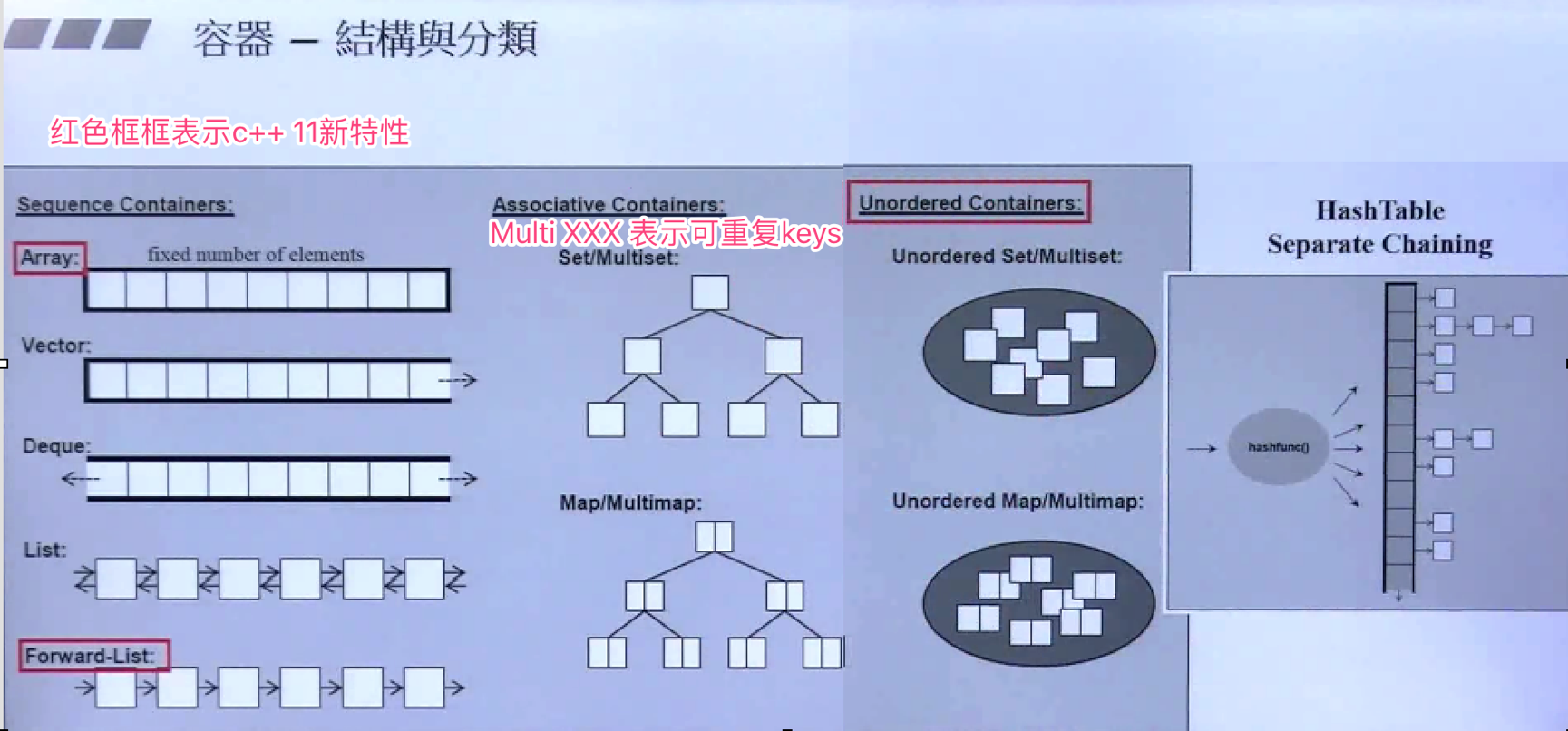
| 容器名称 |
说明 |
| vector |
典型的序列容器,C++标准严格要求次容器的实现内存必须是连续的,唯一可以和标准C兼容的stl容器,任意元素的读取、修改具有常数时间复杂度,在序列尾部进行插入、删除是常数时间复杂度,但在序列的头部插入、删除的时间复杂度是O(n),可以 在任何位置插入新元素,有随机访问功能,插入删除操作需要考虑。
本质上vector使用动态分配数组来存储它的元素,当新的元素插入时,这个数组需要被重新分配大小为了增加存储空间,其做法是:分配一个新数组,然后将全部元素移动到这个数组,就时间而言,代价高,因为每当一个新的元素加入到容器时
|
| deque |
序列容器,内存也是连续的,和vector相似,区别在于在序列的头部插入和删除操作也是常数时间复杂度, 可以 在任何位置插入新元素,有随机访问功能。 |
| list |
序列容器,内存是不连续的,任意元素的访问、修改时间复杂度是O(n),插入、删除操作是常数时间复杂度, 可以 在任何位置插入新元素。 |
| set |
关联容器,元素不允许有重复,数据被组织成一棵红黑树,查找的速度非常快,时间复杂度是O(logN)。
- set以RBTree作为底层容器;
- 所得元素的只有key没有value,value就是key;
- 不允许出现键值重复;
- 所有的元素都会被自动排序(中序遍历出来是有序的);
- 不能通过迭代器来改变set的值,因为set的值就是键。
|
| multiset |
- 关联容器,和set一样,区别是允许有重复的元素,具备时间复杂度O(logN)查找功能。
|
| unordered_set |
- unordered_set它的实现基于HashTable;
- 有unordered_set就一定有unordered_multiset,跟set和multiset一样,前者key不可以重复,后者key可以重复;
- unordered_set是一种无序集合,既然跟底层实现基于HashTable那么它一定拥有快速的查找和删除、添加的优点.缺点是基于HashTable失去了基于rbtree的自动排序功能。
|
| map |
- 关联容器,按照{键,值}方式组成集合,按照键组织成一棵红黑树,查找的时间复杂度O(logN),其中键不允许重复,值可以重复;
- map是按照operator<比较判断元素是否相同,以及比较元素的大小,然后选择合适的位置插入到树中。所以,如果对map进行遍历(中序遍历)的话,输出的结果是有序的。顺序就是按照operator< 定义的大小排序;
- 缺点: 空间占用率高,因为map内部实现了红黑树,虽然提高了运行效率,但是因为每一个节点都需要额外保存父节点、孩子节点和红/黑性质,使得每一个节点都占用大量的空间;
- 适用处:对于那些有顺序要求的问题,用map会更高效一些。
|
| multimap |
|
| unordered_map |
- 优点: 因为内部实现了哈希表,因此其查找速度非常的快;
- 缺点: 哈希表的建立比较耗费时间;
- 适用处:对于查找问题,
unordered_map会更加高效一些,因此遇到查找问题,常会考虑一下用unordered_map。
- 对于map和unordered_map:内存占有率的问题就转化成红黑树 VS hash表 , 还是unorder_map占用的内存要高,但是unordered_map执行效率要比map高很多 。
- unordered_set内部解决冲突采用的是----链地址法。
|
| |
|



 浙公网安备 33010602011771号
浙公网安备 33010602011771号