

多模态预训练模型
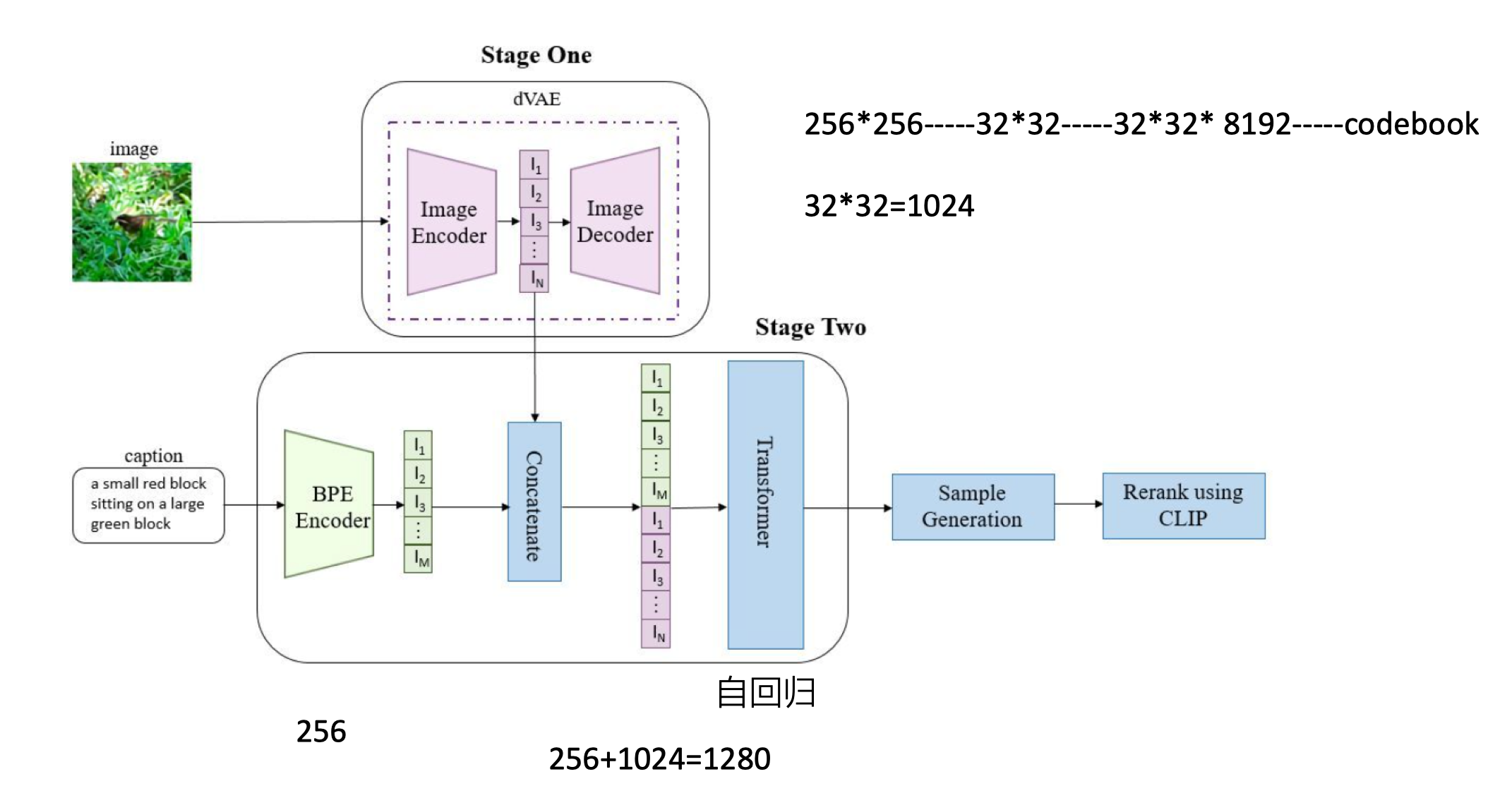
DALL-E
关键词:dVAE,图像生成,Transformer,codebook
https://github.com/openai/DALL-E
https://openai.com/blog/dall-e/
https://arxiv.org/abs/2102.12092,

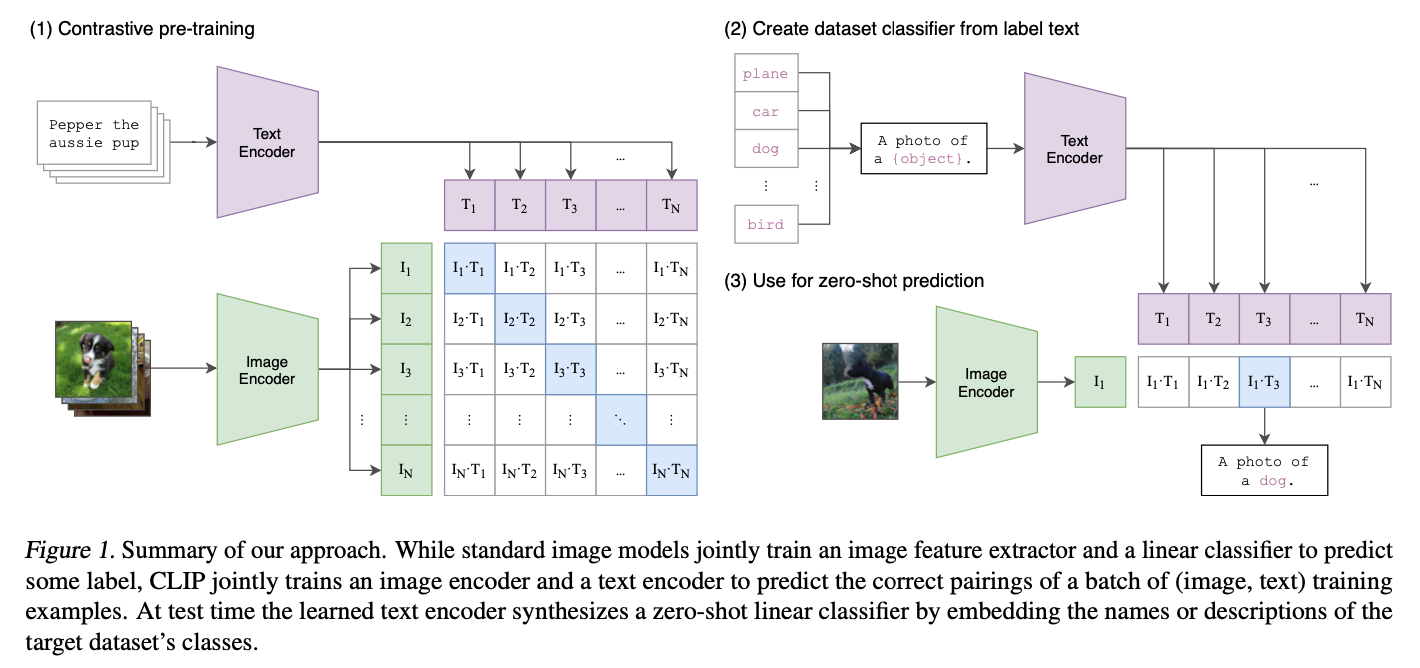
CLIP
关键词:对比学习,图文匹配,特征空间对齐
CLIP: Contrastive Language-Image Pre-training
https://github.com/OpenAI/CLIP
https://arxiv.org/abs/2103.00020v1
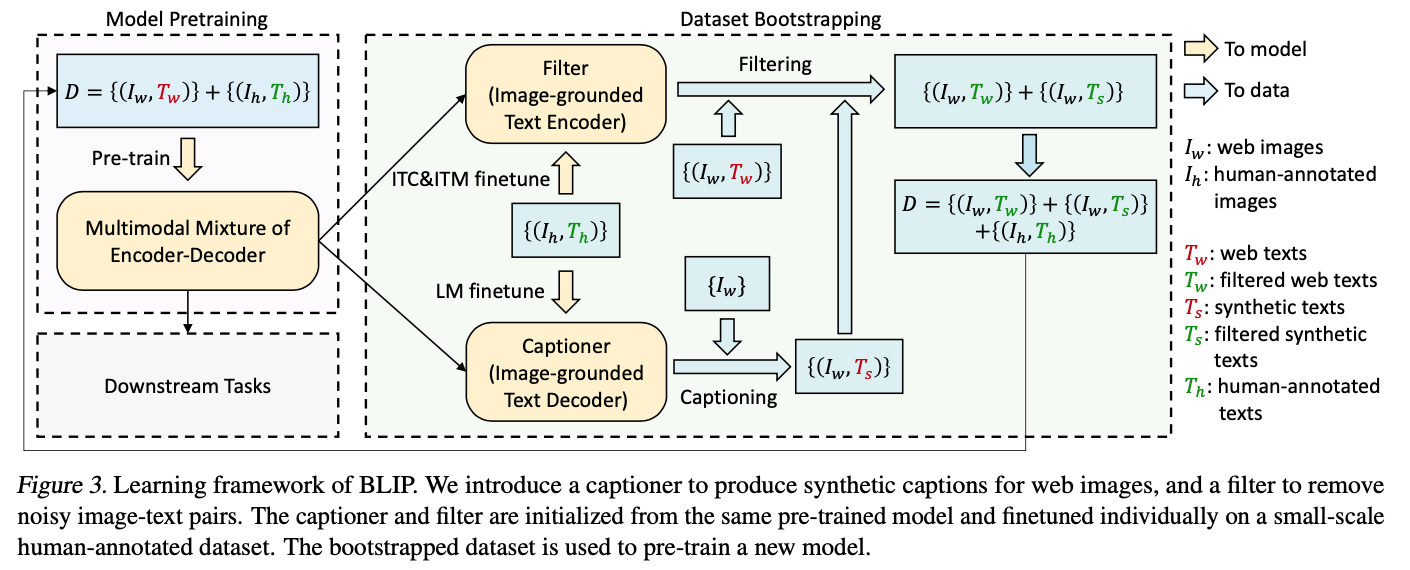
BLIP
关键词:Captioning and Filtering (CapFilt),Bootstrapping,理解和生成
https://github.com/salesforce/BLIP
https://arxiv.org/abs/2201.12086

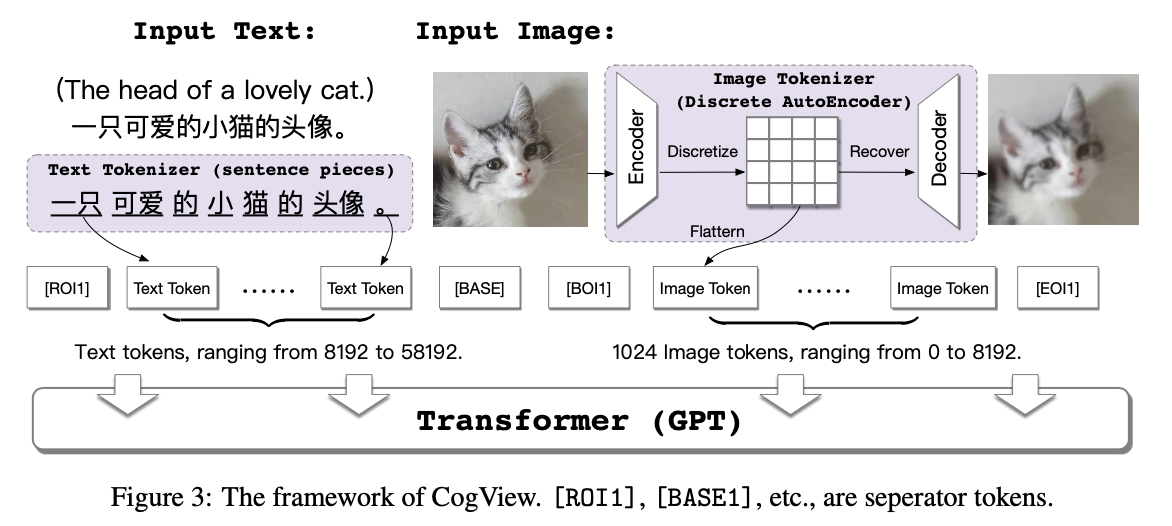
CogView
关键词:中文图像生成,迁移学习,Sandwich-LN,VQ-VAE,GPT
https://github.com/THUDM/CogView
https://arxiv.org/abs/2105.13290
https://wudao.aminer.cn/CogView/index.html

BriVL/WenLan
关键词:弱语义相关,RoBERTa,InfoNCE,MoCo,中文图文检索,Faster-RCNN,EfficientNet B7
https://arxiv.org/abs/2103.06561,WenLan 1.0
https://arxiv.org/abs/2110.14378,WenLan 2.0

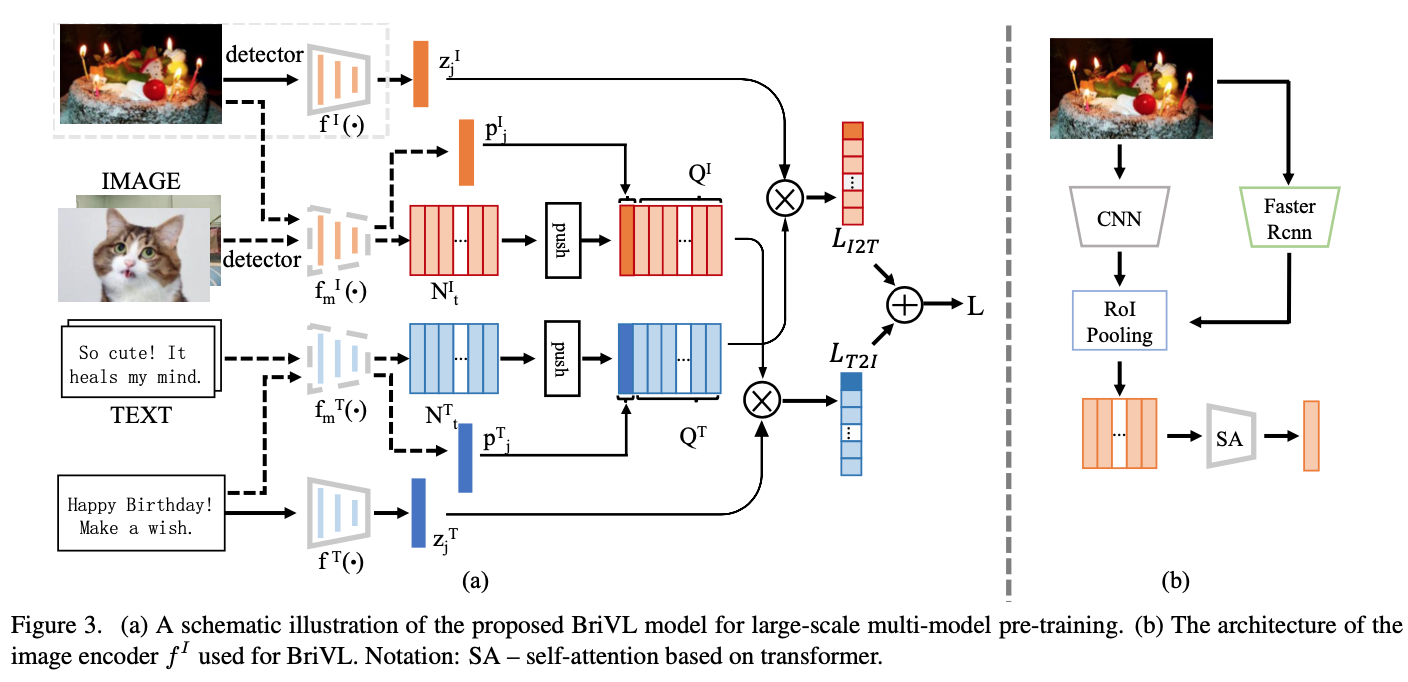
WenLan 2.0
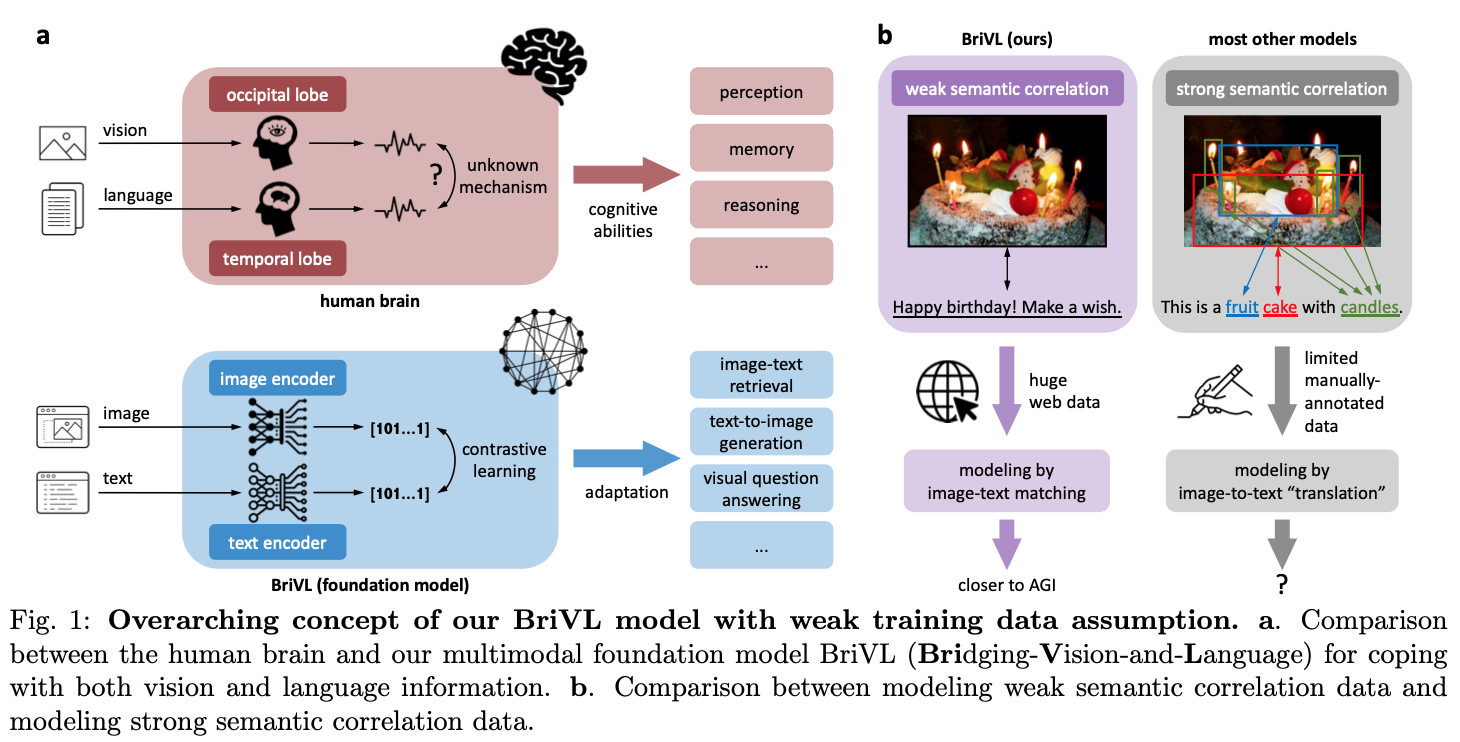
UniT
关键词:多模态、多任务、统一Transformer,DETR,BERT
Facebook
https://arxiv.org/abs/2102.10772
https://mmf.sh/
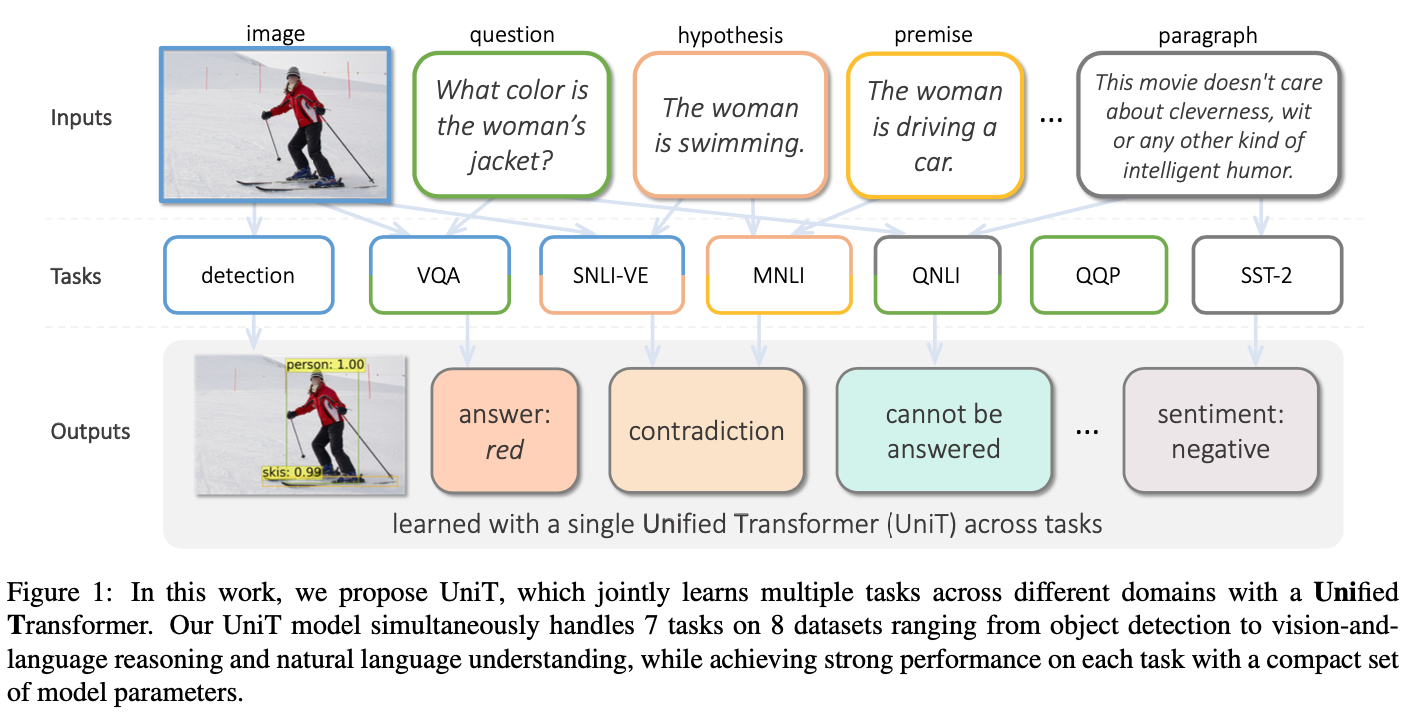

UNITER
关键词:集成、BERT、Faster R-CNN、图文匹配、多模态
2019 ECCV
李琳婕 多模态预训练模型UNITER, 通用的图像-文本语言表征学习
UNiversal Image-TExt Representation
https://arxiv.org/abs/1909.11740
https://github.com/ChenRocks/UNITER
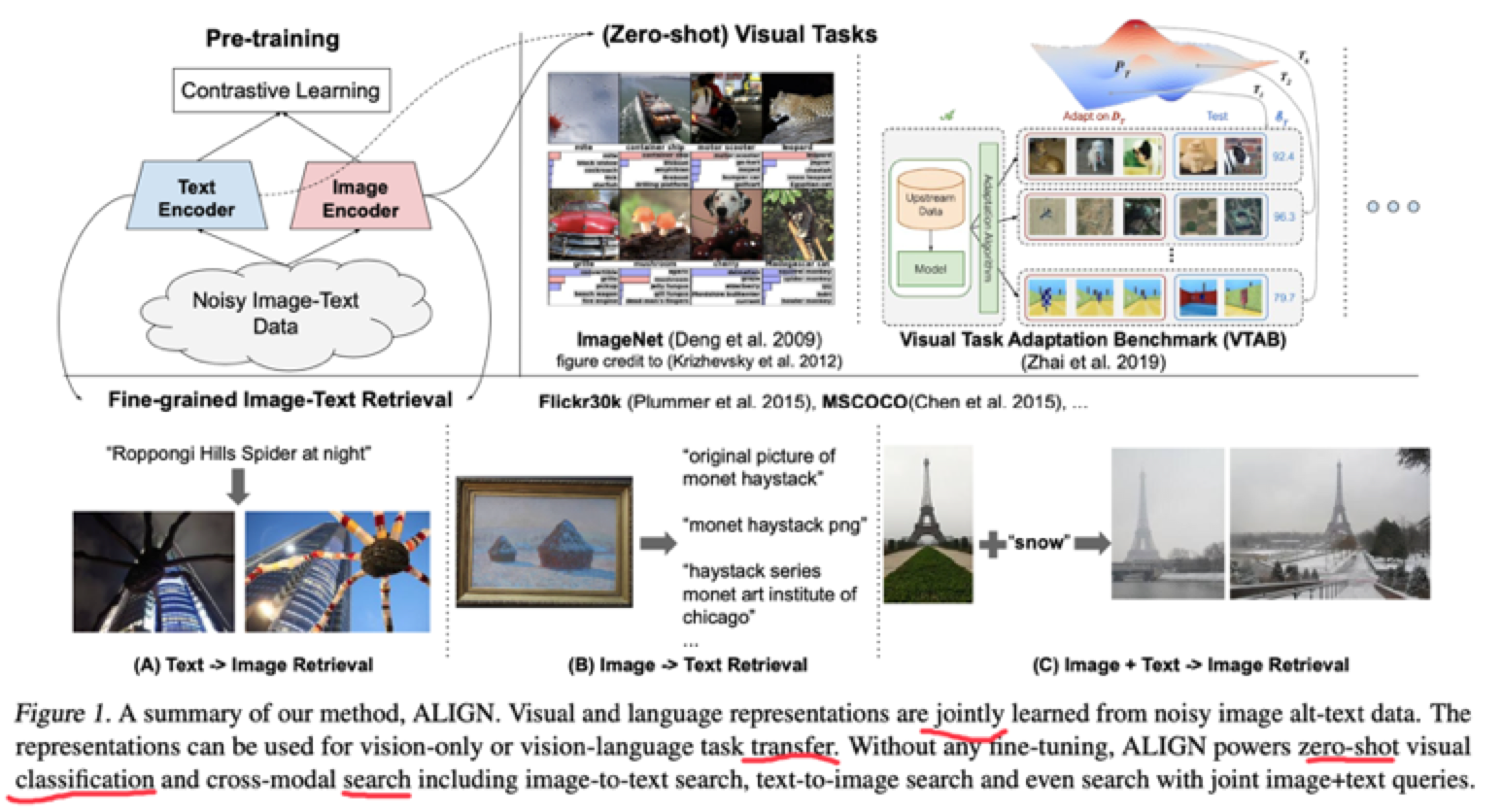
ALIGN
ALIGN: A Large-scale ImaGe and Noisy-text embedding
https://arxiv.org/abs/2102.05918
代码未公开
10亿图文对儿
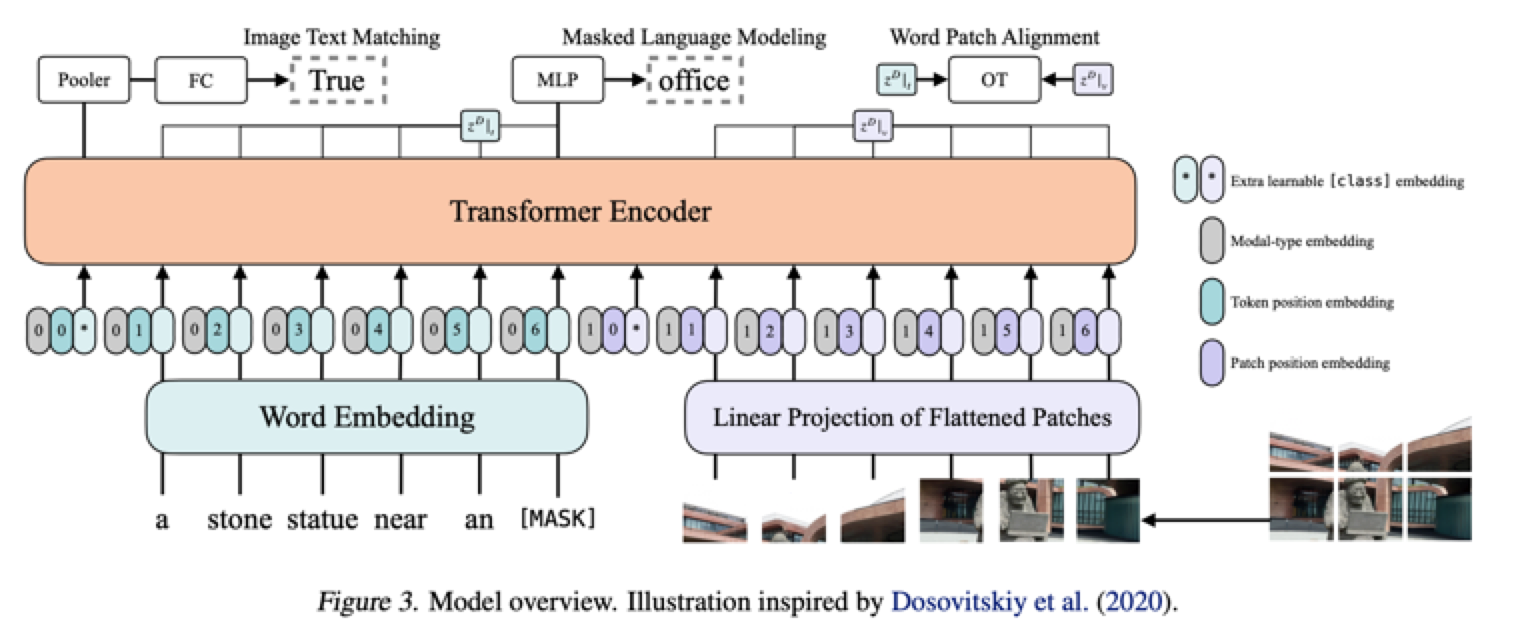
ViLT
关键词:图像切块、拼接、速度快、最简单的多模态
ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision
NAVER AI Lab
ViLT:最简单的多模态Transformer
2021.6 ICML
论文地址 https://arxiv.org/abs/2102.03334
代码地址 https://github.com/dandelin/vilt


CPT
CROSS-MODAL PROMPT TUNING

 浙公网安备 33010602011771号
浙公网安备 33010602011771号