随机森林简介
随机森林是机器学习中的一种分类算法,在介绍随机森林之前,非常有必要了解决策树这种分类器。
决策树是一种分类器,通过训练集构建一颗决策树,从而可以对新的数据预测其分类。一颗构建好的决策树如下:
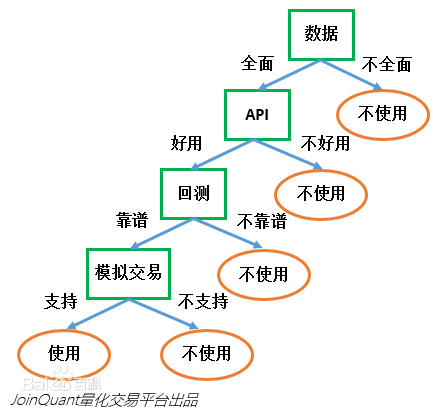
图片来源于百度百科,可以看到这颗决策树的目标是将数据分成 "使用" 和 "不使用" 两类,分类的条件有树中的节点来决定;
而随机森林算法,可以看到有好多颗决策树构成的分类器,首先通过有放回的抽样从原始数据集中构建多个子数据集,然后利用每个子数据集构建一颗决策树,最终的分类效果有多颗决策树预测得到的众数决定;
之所以叫做随机森林,是因为两个核心观点:
1)子数据集的构建,通过随机抽样得到,所以有随机这个关键词
2)在这个分类器中,有多颗决策树,所以有森林这个关键词
来看一个随机森林算法的具体例子:
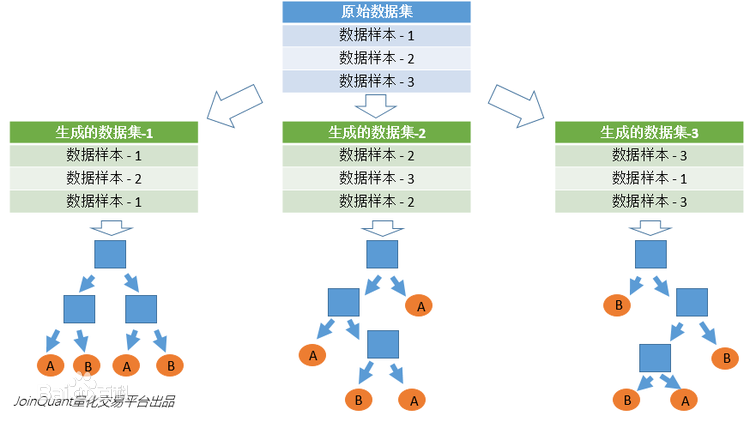
图片来源于百度百科,原始数据集包含3个样本,首先通过有放回的随机抽样构建了3个子数据集,需要注意的是,子数据集的大小和原始数据集的大小是相同的,而且由于采用了有放回的随机抽样,所以子数据集中数据会有重复;
子数据集创建完之后,利用每一个子数据集构建一颗决策树,这里有3颗决策树,每科决策树都会将输入数据分成A 和 B两类;
设想有一批待分类数据,采用上述的随机森林分类器进行分类,3颗决策树会给出3个分类结果,采用3个分类结果的众数作为这批数据最终的分类结果;
参考资料:
https://baike.baidu.com/item/%E9%9A%8F%E6%9C%BA%E6%A3%AE%E6%9E%97/1974765?fr=aladdin
欢迎关注微信公众号<生信修炼手册>

 浙公网安备 33010602011771号
浙公网安备 33010602011771号