解决 scrapy 爬虫出现Forbidden by robots.txt
我们在爬取网站的时候,scrapy 默认的是遵循 robots.txt 协议,怎么破解这个文件
操作很简单,找到setting 文件

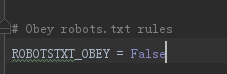
直接改成
如果觉得对您有帮助,麻烦您点一下推荐,谢谢!
好记忆不如烂笔头
好记忆不如烂笔头


我们在爬取网站的时候,scrapy 默认的是遵循 robots.txt 协议,怎么破解这个文件
操作很简单,找到setting 文件
直接改成

 浙公网安备 33010602011771号
浙公网安备 33010602011771号