

此作业要求参见:https://edu.cnblogs.com/campus/nenu/2020Fall/homework/11242
要求一:bug计分
李思源同学bug报告
功能1的bug
(1)bug标题
李思源同学的程序在统计前10名单词时,没考虑当第11名或者后面的单词的频数与第10名相等的情况,只显示了前10,没有考虑后面的情况,显示不够全面
(2)bug内容
<1>测试环境:win10旗舰版;64位操作系统
<2>准备工作:git clone李思源同学的代码至homework03文件夹;建立名为exam的TXT文件,内容如下图:

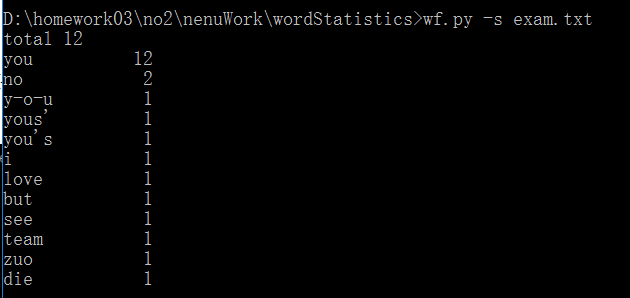
<3>测试步骤:启动控制台,输入wf -s exam.txt
<4>运行结果如下:
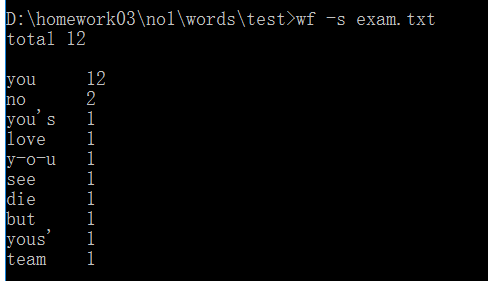
<5>期待结果如下:
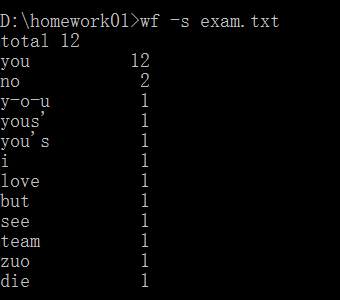
<6>差异:没考虑当第11名或者后面的单词的频数与第10名相等的情况,只显示了前10,没有考虑后面的情况,显示不够全面
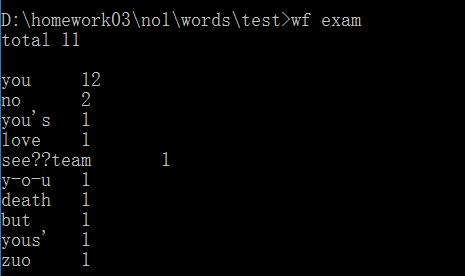
(3)佐证材料
<1>李思源同学的实际运行截图
<2>wf spec
功能2的bug
(1)bug标题
李思源同学的程序在统计前10名单词时,没考虑当第11名单词的频数与第10名相等的情况,只显示了前10,没有考虑后面的情况,显示不够全面
(2)bug内容
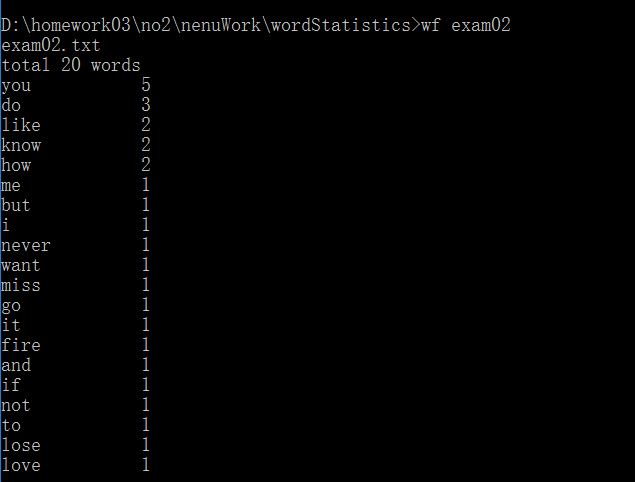
<1>测试步骤:启动控制台,输入wf exam
<2>运行结果如下:
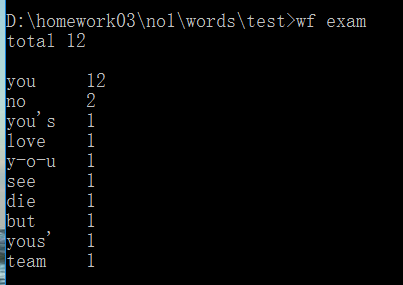
<3>期待结果如下:
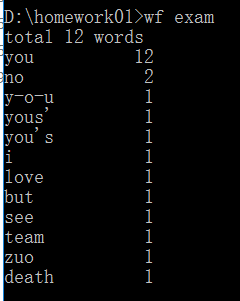
<4>差异:没考虑当第11名单词的频数与第10名相等的情况,只显示了前10,没有考虑后面的情况,显示不够全面
功能3,功能4,功能5 全部都是这个bug问题
造成的差异:没考虑当第11名或者后面的单词的频数与第10名相等的情况,只显示了前10,没有考虑后面的情况,显示不够全面
韩亚光同学的bug报告
功能1的bug
problem1:
(1)bug标题
韩亚光同学对单词的定义以及频数的输出不完全正确
(2)bug内容
<1>测试环境:win10旗舰版;64位操作系统
<2>准备工作:git clone韩亚光同学的代码至homework03文件;建立名为exam的TXT文件,内容如下图:

<3>测试步骤:启动控制台,输入wf -s exam.txt
<4>运行结果如下:

<5>期待结果如下:
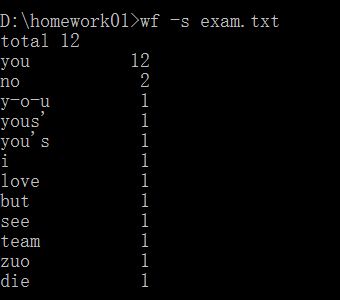
<6>差异:没考虑单词划分的正则表达式规则,对单词定义有问题,造成了统计计数错误
problem2:
(1)bug标题
韩亚光同学的程序在统计前10名单词时,没考虑当第11名或者后面的单词的频数与第10名相等的情况,只显示了前10,没有考虑后面的情况,显示不够全面
(2)bug内容
<1>测试环境:win10旗舰版;64位操作系统
<2>准备工作:git clone韩亚光同学的代码至homework03文件;建立名为exam02的TXT文件,内容如下图:

<3>测试步骤:启动控制台,输入wf -s exam.txt
<4>运行结果如下:
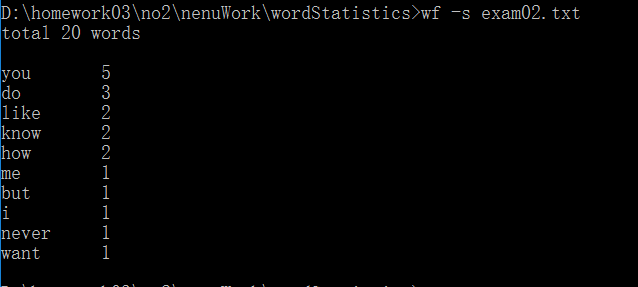
<5>期待结果如下:
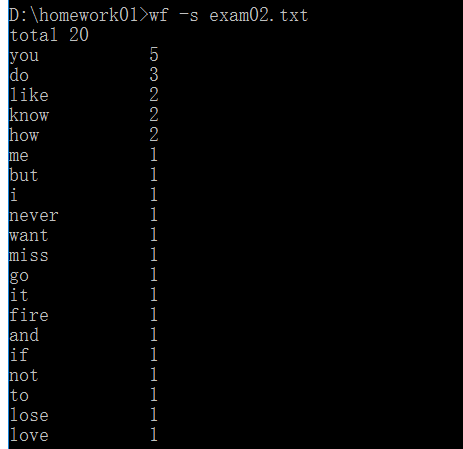
<6>差异:没考虑当第11名或者后面的单词的频数与第10名相等的情况,只显示了前10,没有考虑后面的情况,显示不够全面
功能2的bug
(1)bug标题
韩同学的功能2未实现显示错误,不能正常显示
(2)bug内容
<1>测试环境:win10旗舰版;64位操作系统
<2>准备工作:git clone韩亚光同学的代码至homework03文件;建立名为exam02的TXT文件,内容如下图:
<3>测试步骤:启动控制台,输入wf exam02
<4>运行结果如下:
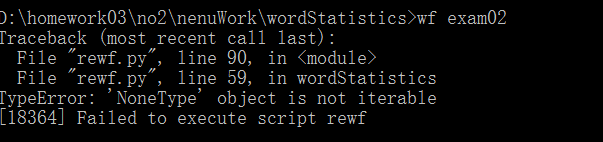
<5>期待结果如下:
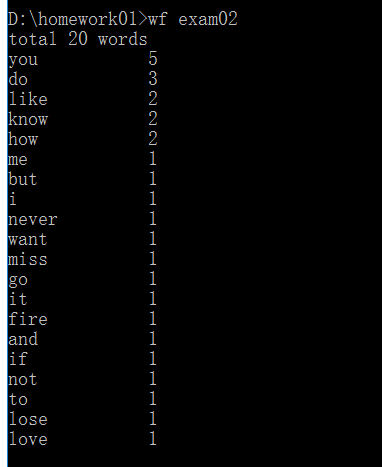
功能3的bug
problem1
(1)bug标题
韩亚光同学对单词的定义以及频数的输出不完全正确
(2)bug内容
<1>测试环境:win10旗舰版;64位操作系统
<2>准备工作:git clone韩亚光同学的代码至homework03文件;建立名为exam02的TXT文件,内容如下图:
<3>测试步骤:启动控制台,输入wf books
<4>运行结果如下:
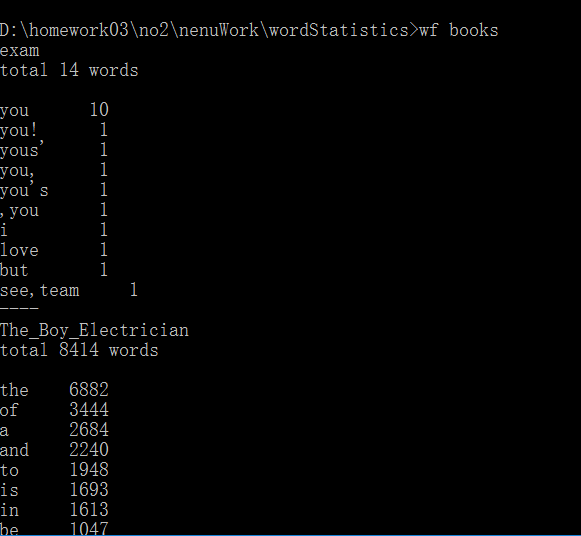
<5>期待结果如下:
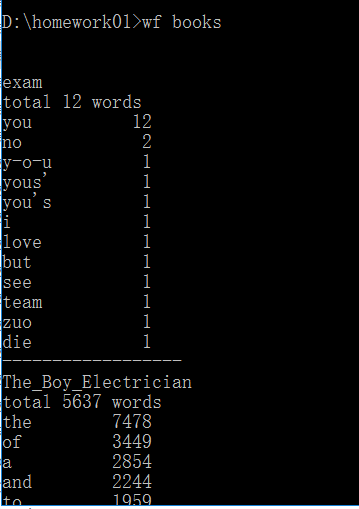
<6>差异:没考虑单词划分的正则表达式规则,对单词定义有问题,造成了统计计数错误
problem2:
bug情况:
韩亚光同学的程序在统计前10名单词时,没考虑当第11名或者后面的单词的频数与第10名相等的情况,只显示了前10,没有考虑后面的情况,显示不够全面
同前面的bug一样
<1>实际运行结果如图:
<2>期望结果如图:
造成的差异:没考虑当第11名单词的频数与第10名相等的情况,只显示了前10,没有考虑后面的情况,显示不够全面
功能4,功能5都有前面两种bug的问题
差异:对单词的定义不够全,且没考虑当第11名或者后面的单词的频数与第10名相等的情况,只显示了前10,没有考虑后面的情况,显示不够全面
要求2 记录所有为你的代码找到的bug,合并相同的bug,亲自重现bug现象,发布bug报告
1.(1)bug标题
徐灿灿同学的词频统计程序在测试用例2中未能提供准确结果。
(2)bug内容
<1>测试环境:win7旗舰版;64位操作系统
<2>准备工作:git clone徐灿灿同学的代码至homework01文件;建立名为2.txt文件,内容如下

<3>测试步骤:启动控制台,在CMD中使用wf -s 2.txt 命令测试功能1
<4>测试结果如下图:
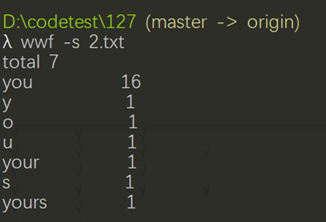
<5>期待结果如下图:

<6>差异:没考虑全单词划分的正则表达式规则,对单词定义不够全面,造成了统计计数错误
要求3 修改bug。根据自己和其他同学提交的bug报告,修改自己代码的bug,或clone其他任意同学的代码,另建git,在此git中修改这位同学的bug。
1.修改自己的功能1bug(第1个)
修改后的git地址:https://e.coding.net/xucancan1/words_count/words_count.git
修改结果:能对文件内的单词进行正确统计,能够很好的区分单词并进行正确统计。
修改前的测试截图如下:
修改后的测试截图如下:
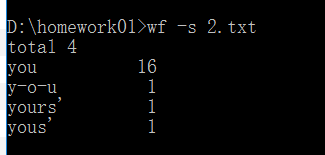
2.修改自己的功能2,功能3,功能4,功能5的bug(共4个)
修改后的git地址:https://e.coding.net/xucancan1/words_count/words_count.git
修改结果:考虑到了当第11名或者后面的单词的频数与第10名相等的情况,一起并列显示。
修改前的测试结果如下:
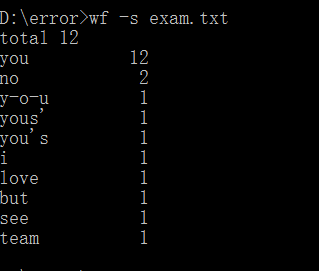
修改后的测试结果如下:

3.修改韩亚光同学功能1,功能2,功能3,功能4的bug(共4个)
修改后的git地址:https://e.coding.net/xucancan1/update_words/update_words.git
修改结果:对单词的定义更全面了,统计单词更准确了
修改前功能1的测试结果如下:
修改后功能1的测试结果如下:
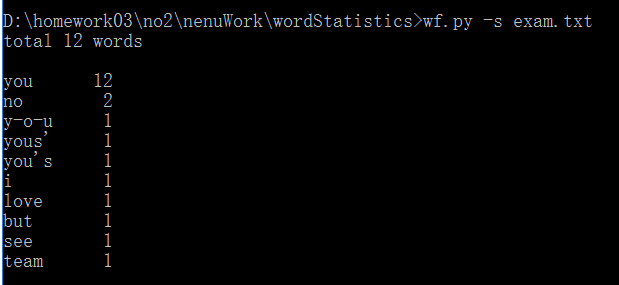
4.修改韩亚光同学功能1,功能2,功能3,功能4的bug(共4个)
修改后的git地址:https://e.coding.net/xucancan1/update_words/update_words.git
修改结果:考虑到了当第11名或者后面的单词的频数与第10名相等的情况,一起并列显示。
修改前功能1的测试结果如下:
修改后功能1的测试结果如下:
5.修改韩亚光的bug(共1个)
修改后的git地址:https://e.coding.net/xucancan1/update_words/update_words.git
修改结果:功能2能够正常运行,且能够准确显示单词的词频结果
修改前功能2的测试结果如下:
修改后的功能2结果测试如下:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号