
GAN Lecture 6 (2018)_WGAN, EBGAN
课程主页:提供作业相关
PS: 这里只是课程相关笔记
上一节我们学习了 GAN 的一些基础理论知识,这节课我们就开始学习一些具体的例子
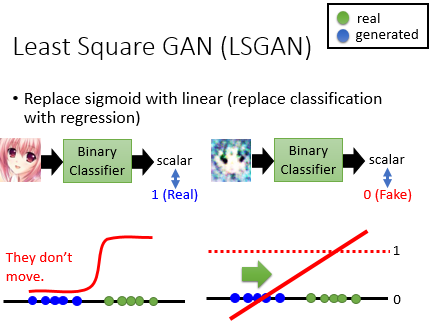
1. Least Square GAN(LSGAN)
传统的 GAN 由于在训练初期生成的样本和真实样本很容易区分, 那么 Generator 的输出经过 sigmoid 操作后在梯度平滑的区域,这就导致了 Binary Classifier 很难训练。一种解决方案是将 sigmoid 操作替换成 linear function,然后将 Classification 替换成 Regression。
2. Wasserstein GAN (WGAN)
这是一个比较常用的技术,这里换了一个 evaluation major 来衡量 $P_G$ 和 $P_{data}$,用的是一个叫做 Earth Mover's(Wasserstein) Distance 的衡量方法。 Earth Mover's Distance 的意思是我们有两个分布 P 和 Q, 我们试图将 P 进行搬运以达到 Q 的分布所搬运的平均所移动的距离。
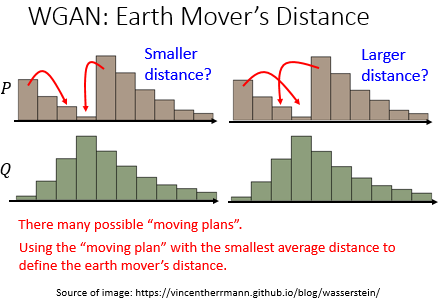
这里有一个问题是,我们有很多种搬运的方式, 到底哪一个才是 Earth Mover's Distance。所以今天 Wasserstein Distance 的意思是穷举所有的搬运方法,即 moving plans,看那个移动的距离最小就是我们要寻找的 Wasserstein Distance。
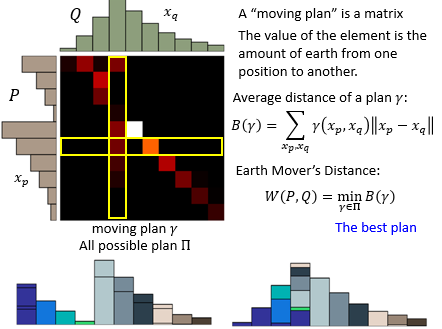
更形象一点,我们可以把 moving plan 看成一个矩阵,矩阵的每个元素代表搬运多少 P 到 Q,这个矩阵每一行加起来就是 P 的每一个 compoment,矩阵每一列加起来就是 Q 的每一个 compoment。这样每一个 moving plan 的 Average Distance 就可以用下面这个式子来表示:
\begin{equation}
\label{B}
B(\gamma) = \sum_{x_p, x_q} \gamma(x_p, x_q)\lVert{x_p - x_q}\rVert
\end{equation}
我们的目的就是要找到有个最小的距离:
\begin{equation}
\label{W}
W(P, Q) = \mathop{min}\limits_{\gamma \in \Pi} B(\gamma)
\end{equation}
之前我们理论推导那节所用的 JS divergence 有一个缺陷就是无法衡量没有重叠的两个分布之间的距离,而这里的 Earth Mover's Distance 可以。这让我想到了目标检测中回归 IoU Loss 无法衡量两个没有任何交集的 BBox 之间的距离
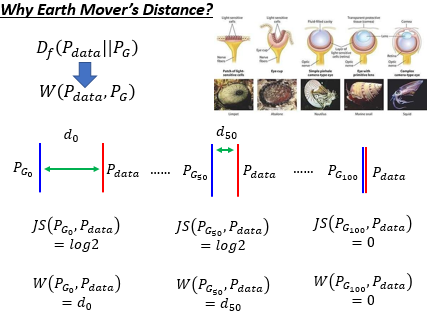
那么如何修改 Discriminator 让它来衡量 $P_G$ 和 $P_{data}$ 之间的 Wasserstein Distance 呢?

结论就是,如果 x 是从 $P_{data}$ 里 sample 出来的,那让它 D 的输出越大越好,如果 x 是从 $P_{G}$ 里 sample 出来的,那让它 D 的输出越小越好,同时还要保证 Discriminator 是一个 1-Lipschitz 的 function,以避免 $P_G$ 和 $P_{data}$ 的差距无穷大。
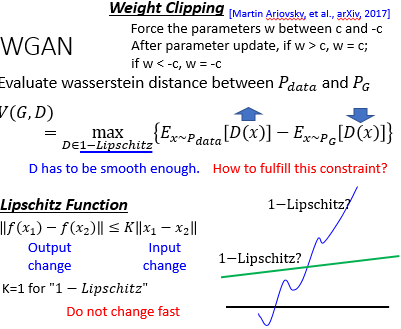
至于 Lioschitz Function 如上图定义,目的是让该函数的输出差距不至于过大。而具体怎么解这个带有 constraint 的 optimize function 呢?最原始的论文里的做法就是 Weight Clipping ... 来让 Discriminator 来变得平滑 ... 当然这么干就行了吗?当然不行 ...
后面提出了 Improved WGAN(WGAN-GP) , 作者发现让 Discriminator 是个 1-Lipschitz Function 等价于让 Discriminator 对所有的 x 的梯度都小于 1。具体实现时就是加一个 penalty。

但是这个惩罚项由于是对所有的 x 作积分,这是不现实的。因此我们只可能从一个小的 $P_{penalty}$ 分布里取 x。
 |
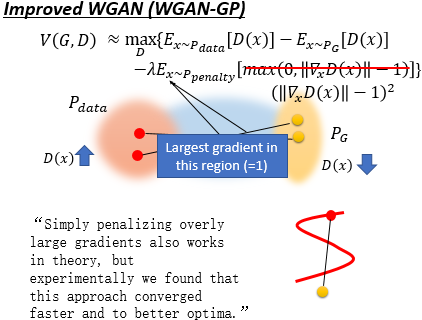 |
考虑到我们的目标是将 $P_G$ 往 $P_{data}$ 上移,因此这个 $P_{penalty}$ 只要在 $P_G$ 和 $P_{data}$ 之间的分布就好了。而另一方面,作者实验发现梯度不仅仅是小于 1 就好了,而是越接近于 1 越好。当然这个 $P_{penalty}$ 理论上也是有点问题的,后来也有很多改进版。
 |
 |
3. Spectrum Norm(SNGAN)
4. Energy-based GAN(EBGAN)
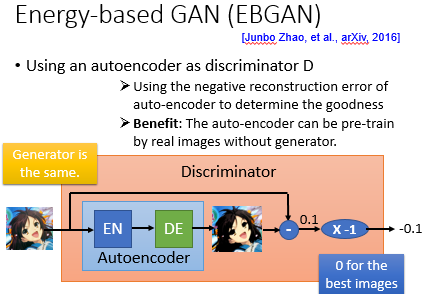
EBGAN 是什么,EBGAN 他唯一跟一般的 GAN 不同的地方是它改了 discriminator 的 network 架构。本來 discriminator 是一個 binary 的 classifier 对不对,它现在把它改成 auto-encoder.接下來你算那个 auto encoder 的 reconstruction error, 把 reconstruction error 乘一個负号,就变成了你的 discriminator 的 output,需要注意一点是,EBGAN-PT也有权重,作者在实验中取了0.1。
这个 discriminator 跟一般的 discriminator,其实是一样的,input 一张 image,output 就是一個 scalar,只不过这个 scalar 相比传统的 GAN 中 Discriminator 作为 binary classifier 输出,BEGAN 中的 Discriminator 是作为 reconstruction error 来输出的。
这个 energy based GAN 它的假设就是:假设某一张 image 它可以被 reconstruction 的越好,它的 reconstruction error 就越低,代表它是一个 high quality 的 image;但如果它很难被 reconstruct,它的 reconstruction error 很大,代表它是一個 low quality 的 image。
那这种 EBGAN 他到底有什么样的好处呢?大佬觉得他最大的好处就是,你可以 pre train 你的 discriminator,我们 auto encoder 在 train 的時候,不需要 negative example,而在 train discriminator 的時候你需要 negative example,对不对。你在 train 你的 discriminator 的時候,它是一個 binary classifier,所以你要从你的 data 裡面去 sample 一些 real image,再用你的 generator sample 一堆 fake image,然後再去 train 你的 discriminator,去分辨 real 跟 fake image,所以这个东西没法 pre trained。你沒有办法只拿 positive example 去 train 一個 binary classifier,你沒办法 pre train 它,所以这边会造成的问题是什么?会造成的问题是一开始你的 generator 很弱,所以它 sample 出來的 negative example 也很弱,用很弱的 negative example 你 learn 出來就是一個很弱的 discriminator,那 discriminator 必须要等 generator 慢慢变強以后,它才会越來越强,所以你 discriminator 一开始不会很厉害,你要 train 很久,才会让 discriminator 变得比较厉害。
但是 energy base GAN 就不一样,discriminator 是一個 auto encoder,auto encoder 是可以 pre trained,auto encoder 不需要 negative example,你只要给它 positive example,让它去 minimize reconstruction error 就好了,所以你真的要用 energy base GAN 的時候,你要先 pre-train 好你的 discriminator,先拿你手上的那些 real 的 image,去把你的 auto encoder 先 train 好,所以你一开始的 discriminator,会很强。所以因为你的 discriminator 一开始就很强,所以你的 generator 一开始就可以 generate 很好的 image,所以如果你今天是用 energy base GAN,你会发现说你前面几个 epoch,你就可以还蛮清楚的 image,那这个就是 energy base GAN 一个厉害的地方。
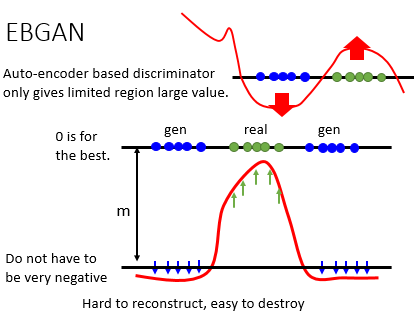
那 energy based GAN 实际上在 train 的時候,還有一個细节你是要注意的,就是今天在 train energy based GAN 的時候,你要让 real 的 example 它得到的分数越大越好(0 is best),也就是 real example 它的 reconstruction error 越小越好。但是要注意你并不是要让 generated 的 example 它的分数越小越好,或它的 reconstruction error 越大越好,为什么?因为想要 real image 的 reconstruction error 很小是比较难得,而想要 fake image 的 reconstruction error 很大确是太容易不过了,但这么训练下去你的 discriminator 的 loss 虽然可以把它变得很小,整个 Discriminator 肯定会偏向 fake image 这边而牺牲了 real image。所以实际上在做的時候,我们需要设一个 margin,今天 generator 的 reconstruction loss 只要小于某一个 threshold 就好,当然 threshold 这个 margin 是你要手调的,所以就多一個参数要调就是了。这个 margin 意思是说 generator loss 只要小与 margin 就好,不用再小,小于 margin 就好,不用让它再更小。
5. Loss-Sensitive GAN(LSGAN)
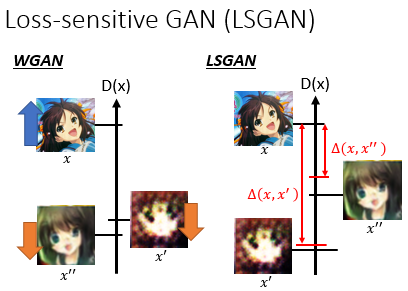
那今天其实还有另外一个东西也是有用到 margin 的概念,叫做 Loss-Sensitive GAN,也有用到 margin 的概念。我们之前在做 WGAN 的時候是说如果是个 real image 就让它的值越大越好, 如果是个 negative example,就让他的值越小越好。但是假設你已经有些 image,其实已经很 realistic,你让它的值越小越好,其实也不 make sense 对不对。所以今天在 LSGAN 里面它的概念就是,他加了一个叫做 margin 的東西。就是你需要先有一個方法,去 evaluate 说你現在产生出來的 image 有多好。如果今天这个 $x^{''}$ 跟 $x$ 已經很像了,那它們的 margin 就小一点,如果 $x^{'}$ 跟 $x$ 很不像,它們 margin 就大一点。所以你会希望 $x^{'}$ 的分数被压得很低,$x^{''}$ 的分数只要被压过 margin 就好,不需要压得太低。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号