
深度学习笔记(二十三)Semantic Segmentation(FCN/U-Net/PSPNet/SegNet/U-Net++/ICNet/DFANet/Fast-SCNN)
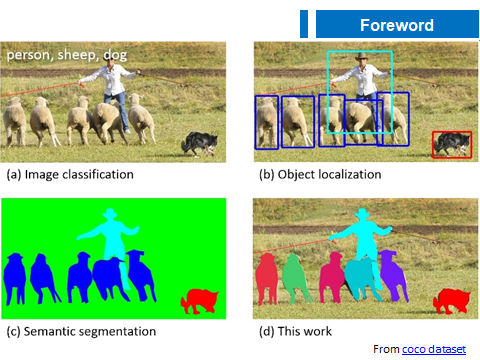
借助一张 COCO 数据集中的图片来展示下分类、检测、语义分割、实例分割的区别。
语义分割的本质是图片信息的编解码(encoder-decoder)过程:

当时这个结构提出的主要作用并不是分割,而是压缩图像和去噪声。输入是一幅图,经过下采样的编码,得到一串比原先图像更小的特征,相当于压缩,然后再经过一个解码,理想状况就是能还原到原来的图像。这样的话我们存一幅图的时候就只需要存一个特征和一个解码器即可。
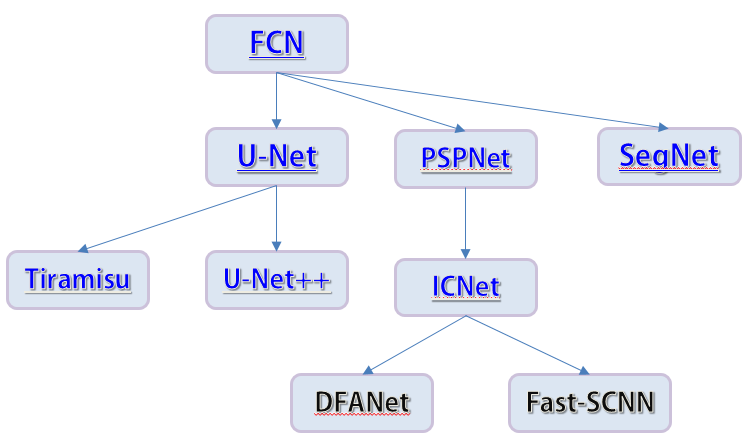
本文按照下面这张图的顺序简单理一下语义分割:
1. FCN
FCN 全名 Fully Convolutional Networks for Semantic Segmentation,算是利用深度学习进行语义分割的开山之作了。
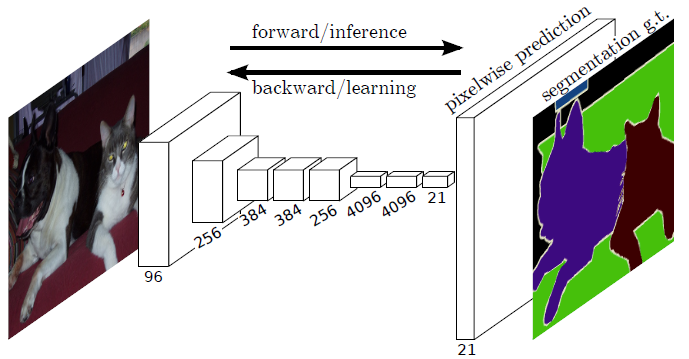
它将传统的分类网络改造成了分割网络:替换全连接层为卷积层,利用反卷积操作上采样获得高分辨率的语义特征图。输出 feature map 每一维通道预测一个类别的分割结果。


为了加强特征表示,在编码器阶段将不同阶段的特征融合。
2. U-Net
U-Net 全名为 U-Net: Convolutional Networks for Biomedical Image Segmentation.
1.1 DataAugmentation
U-Net 的实验环境是医学图像的语义分割,这类图像由于其特殊性,因而通常无法获得大量的数据,而深度学习却依赖于大量的训练数据来拟合。因此文章中描述到,作者主要针对平移、旋转、形变、灰度值方面做了数据增广。具体细节就要参考源码了
1.2 Network Architecture
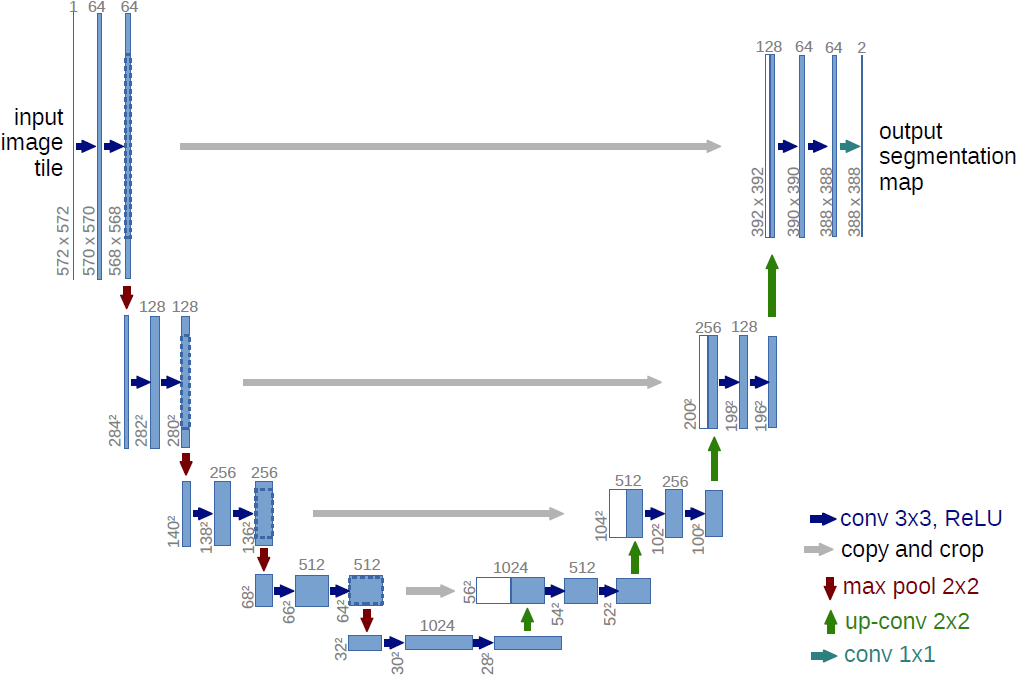
网络将编码和解码(encoder-decoder)思想用在了图像分割的问题上,也就是现在我们看到的U-Net结构,在它被提出的几年中,有很多很多的论文去讲如何改进 U-Net 或者 FCN,不过这个分割网络的本质的拓扑结构是没有改动的。
网络设计的很规整对称,让我们来看图说话:下采样阶段,重复使用两个 3x3 的卷积层(no padding),每一个卷积层跟上一个 ReLU 激活层,随后跟上一个大小为 2x2 , stride=2 的最大池化层。每次下采样过后,将特征通道数加倍。上采样阶段和下采样阶段保持对称,上采样采用大小为 2x2 , stride=2 的反卷积层。上采样的同时,采用 skip connection,将对应的下采样的 feature map crop 后通道维度 concat 到上采样的 feature map 上,随后跟上两个连续的 3x3 卷积层,第一个卷积层会将特征通道减半。特别的,由于使用 unpadded convolution,因此每次卷积过后,feature map 的的尺度会有些许变小(边界信息丢失),这就是为什么 concat feature map 的时候需要 crop 的原因了。而为了保证分割的无缝平铺,需要合理地选择输入图像尺寸,以保证池化操作时能被整除。上采样同样采用 反卷积(Deconvolution Conv.)
1.3 Training
在那个时期,GPU 的计算能力还不是很强,为了有效利用 GPU, 作者采用 batch_size=1 的设置。为此,使用高动量(0.99),使得大量先前看到的训练样本确定当前优化步骤中的更新。
Loss 层面为逐像素层级的 softmax_cross_entropy 损失函数。而为了凸显邻近的相同类别不同实例之间的边界,作者在基础 Loss 上增加了一个权重项 $w(x)$:
\begin{equation}
\label{loss}
\begin{split}
& E = \sum_{x \in \Omega} w(x) log(p_{l(x)} (x)) \\
& w(x) = w_c(x) + w_0 \cdot exp(-\frac{(d_1(x) + d_2(x))^2}{2 \sigma^2}) \\
\end{split}
\end{equation}
这里$w_c$ 是根据每个类别像素点数量确定的一个权重系数(用以避免类别不平衡), $d_1$ 表示该像素点到最近实例的边界的距离,$d_2$ 则表示该像素点到次近实例的边界的距离。实验中设定 $w_0=10$, $\sigma \approx 5$。
权重初始化方面,实验标准差为 $\sqrt{2/N}$ 的高斯分布中绘制初始化权重来实现,其中 $N$ 表示一个输出节点对于的输入节点数量(kernel_size * input_channel) 。
1.4 Others
为了预测图像边界区域中的像素,通过镜像输入图像来外推缺失的上下文。这种图像块策略对于将网络应用于大的图像非常重要,否则分辨率将受到GPU内存的限制。
3. SegNet
SegNet 全名为 SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation.
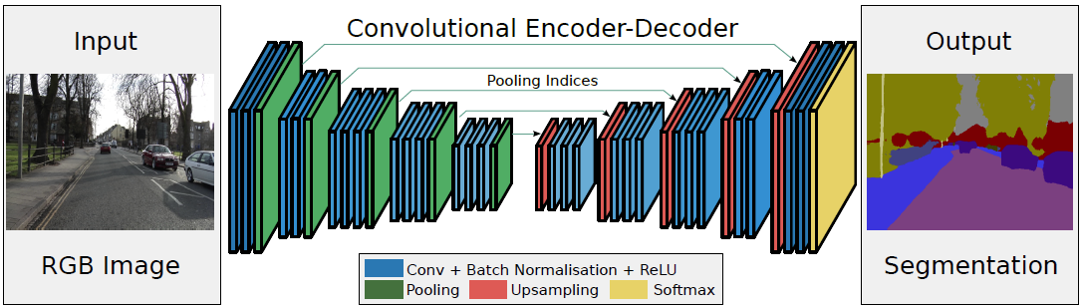
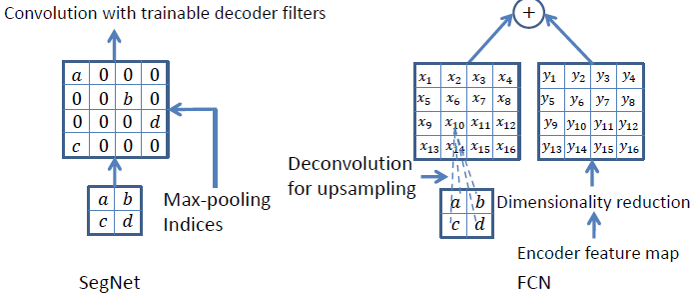
这其实和 U-Net 很像,区别在于它使用 Pooling 操作来完成上采样:
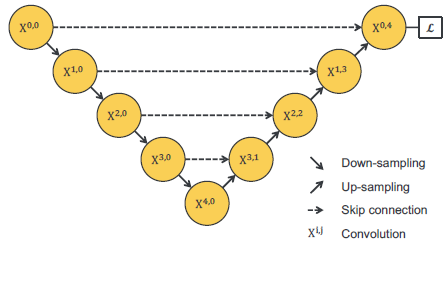
4. U-Net++
3.1 分析 U-Net 的缺点
对于 Encode 阶段来说,UNet 采用了四次降采用操作,那么问题来了,对比分类网络,这里是不是网络越深越好?
我们知道浅层特征提取的是一些我们容易理解的纹理外观信息,而深层特征提取的则是一些比较深层次的我们不理解的高维特征,从理论上来说,浅层特征和深层特征对于分割任务都有其重要性。
UNet++ 作者做了这样一个实验:实验不同下采样的次数对分割性能的影响,结论是对于不同的数据集来说,并不是越深越好。

针对上面那个问题,U-Net++ 的做法是下图这样的:

U-Net++ 的思想是,在对于某个数据集,我们不知道选择几次下采样更好的情况下,我们选择让网络自己去选择。这里的 Backbone 是共用的。
这里可以理解为将 U-Net 和 Deep Layer Aggregation 结合起来(当然需要强调这只是创新点的偶遇):
| U-Net | DLA | U-Net++ |
 |
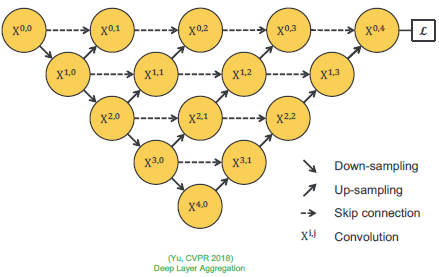 |
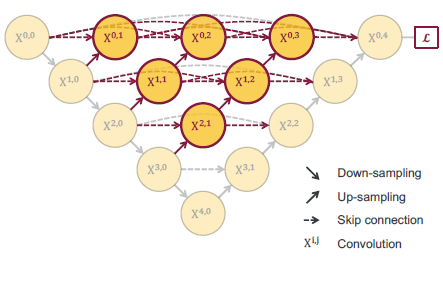 |
这里面隐含了一个问题就是:UNet++ 的性能提升是否来自于计算量的增加?
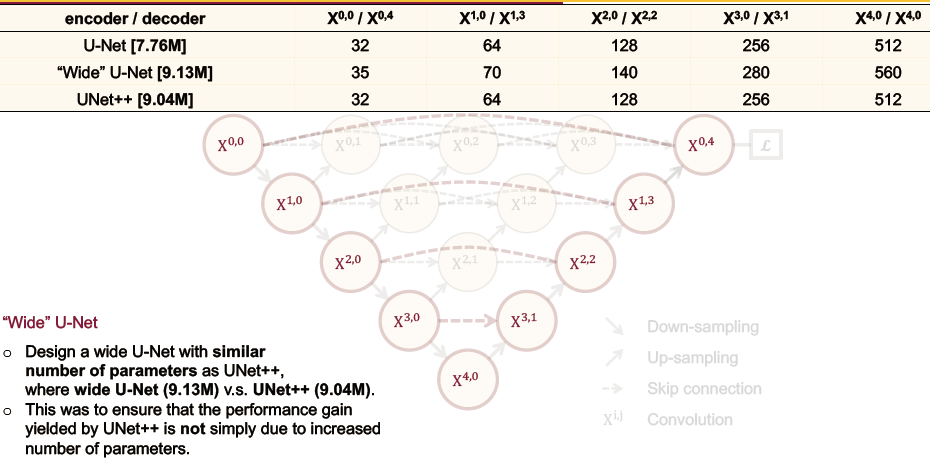
作者通过扩展 U-Net 的参数量(增加 channel)到与 UNet++ 差不多大小的情况下,来对比性能。
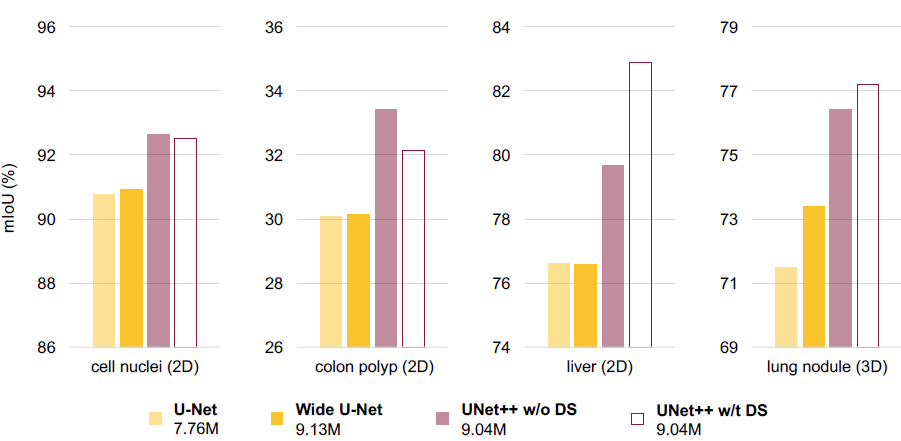
实际使用中,作者在上面网络的基础上加了一个深监督信息,来让网络自己学习哪个层次的特征更重要:
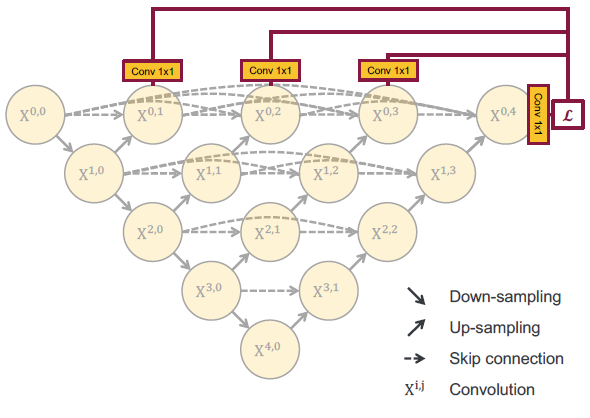
这里一个更有意思的地方在于,我们可以通过这个网络在不同的数据集中来剪枝!
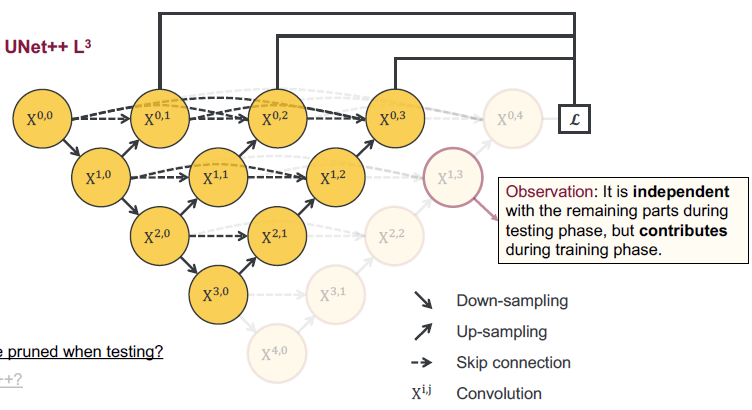
如上图所示,训练阶段每个节点都是对前面的节点作贡献的,而在测试阶段,我们可以从后往前丢弃某一层次或某几层次节点。按照作者的说法,这使得 U-Net++ 比 U-Net 更加灵活!
U-Net++ 的优势在于一方面长短连接加强了特征的表示能力,另一方面允许剪枝操作使得网络更加灵活。
5. PSPNet
PSPNet 全名为 Pyramid Scene Parsing Network.

作者对比 FCN 的分割结果,发现 FCN 算法有上面的三个缺点,这些问题产生的原因作者分析为,FCN 的感受野一方面对于大目标不够大,另一方面又对小目标不够小。
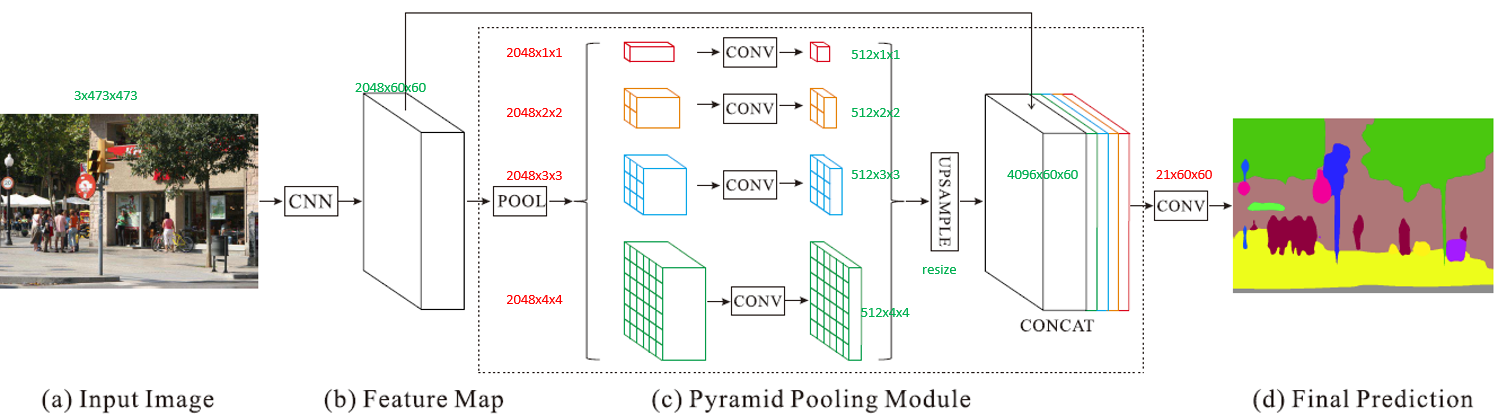
PSPNet 的核心思想就是:利用空洞卷积增加感受野,不同大小感受野的 feature map cancat 到一起实现多尺度分割。
6. ICNet
ICNet 全名 ICNet for Real-Time Semantic Segmentation on High-Resolution Images.
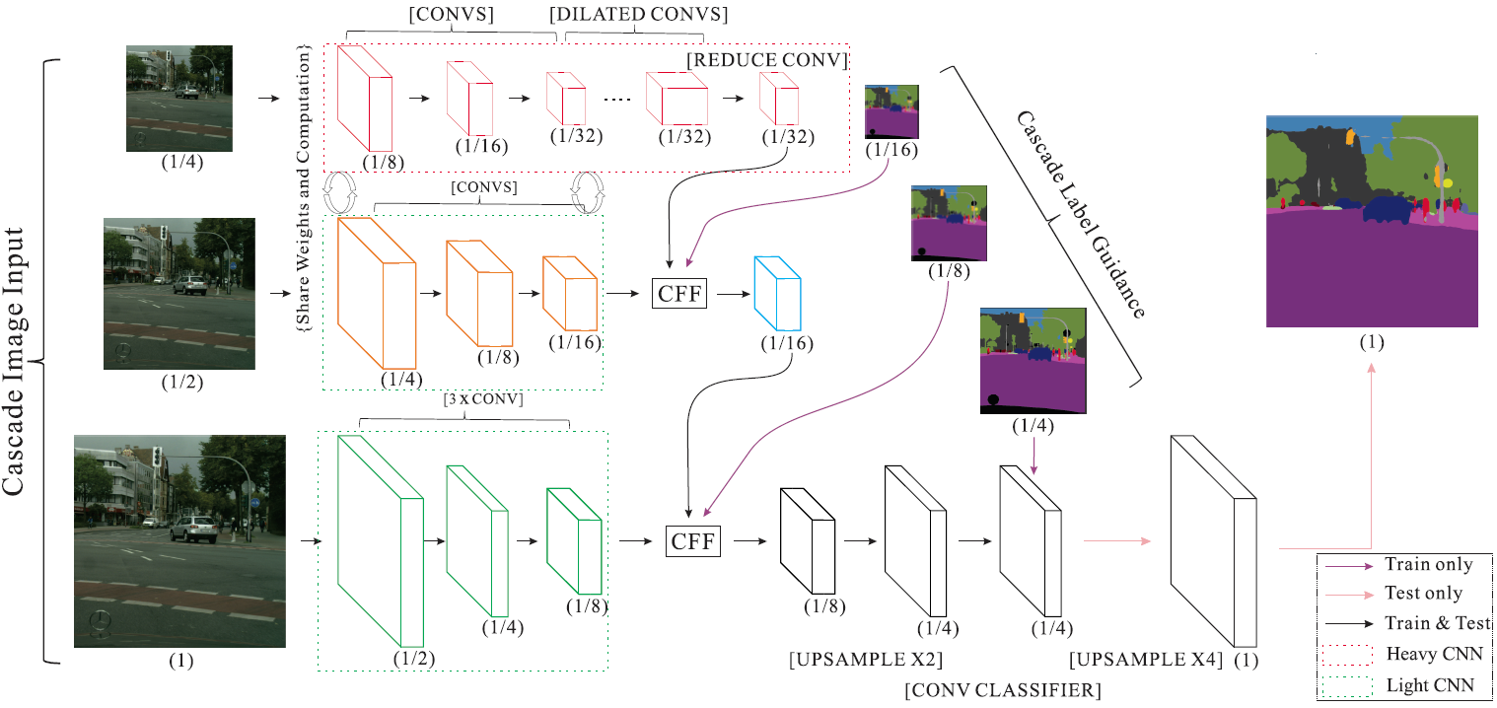
它的核心思想,是设计 Cascade Feature Fusion 和 Cascade Label Guidance 多阶段多 Loss 学习,小尺度的输入经过较大的网络提取粗糙的分割结果,大尺度的输入经过较小的网络提取精细的分割结果,小尺度输入 提取的特征 会融合到 大尺度输入 提取的特征中,从 Loss 角度来看有点 相关的多任务学习,彼此之间可以互相促进 的味道。
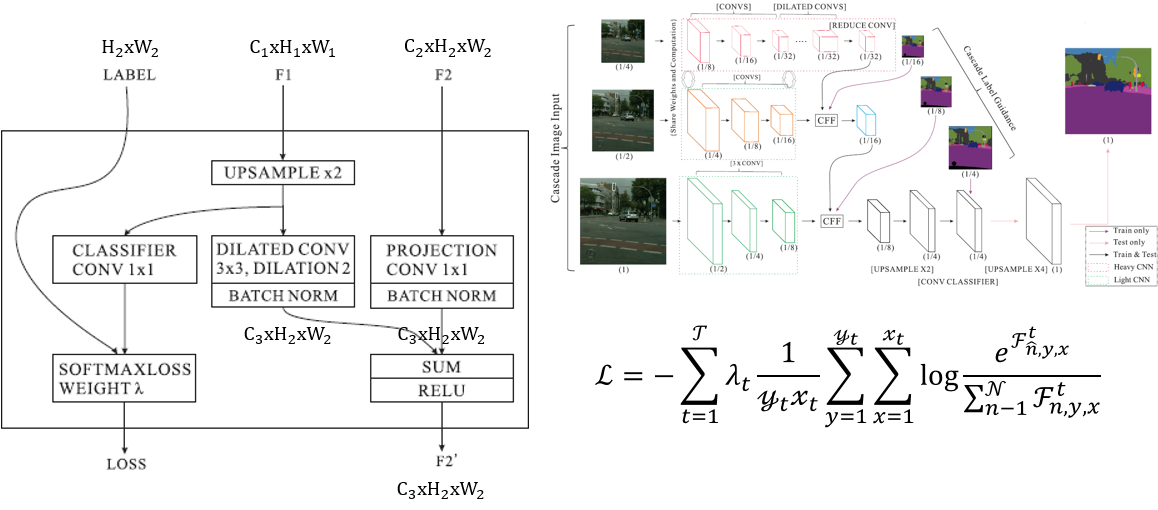
7. DFANet

DFANet 全称 DFANet: Deep Feature Aggregation for Real-Time Semantic Segmentation。DFANet 与 ICNet 形式上很像,区别在于利用多尺度融合特征来替换多尺度图片输入(sub-network Aggregation),不同支路之间的 feature map 之间也加上短连接来增强特征融合(sub-stage Aggregation)。
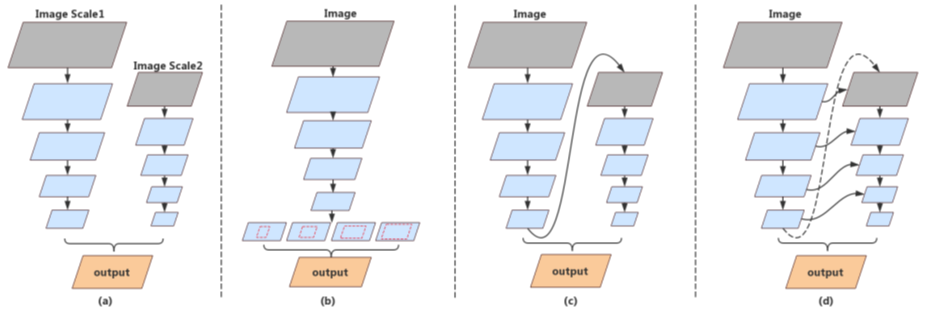
网络主要采用 depthwise separable convolution,同时加入了 SENet 里面的 channel-wise attention 机制以及类似 EncNet 中的上下文编码结构。
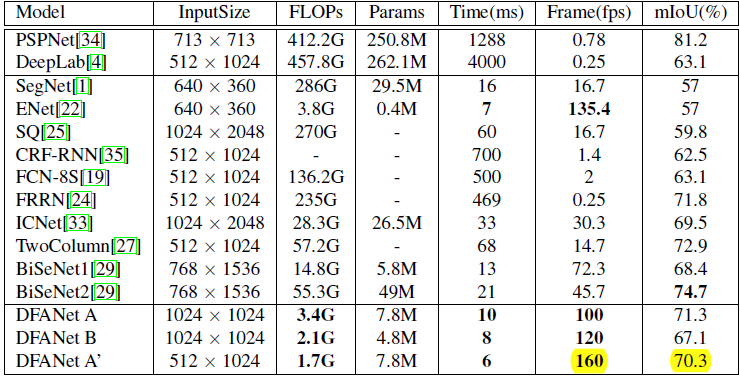
性能看上去还是挺屌的!这里的 DFANet A’ 应该是输入图片尺度为 512x1024, Backbone A x3+HL+LL 的网结构,这里的 Backbone A = Xception A + SENet, ’HL’ means that fusing high-level features. ’LL’ means fusing low-level features.
该文章官方没有公布源码,第三方实现我这边 512x1024 尺度下训练,2 GFlops,1024x2048 尺度下测试能够达到 67 mIoU.
8. Fast-SCNN
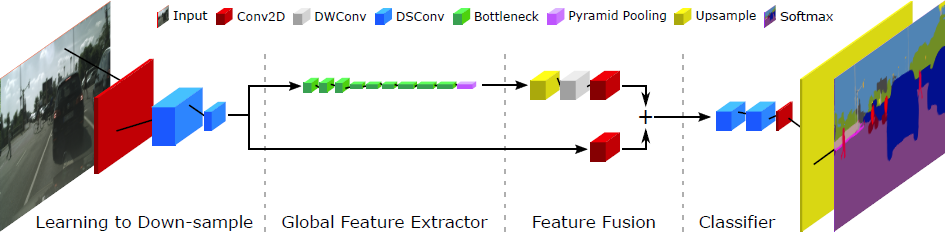 |
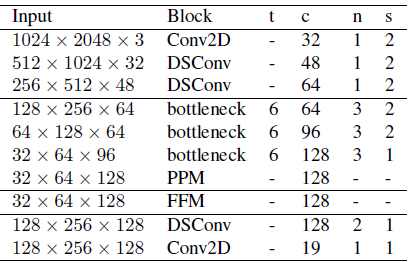 |
Fast-SCNN uses standard convolution (Conv2D), depthwise separable convolution (DSConv), inverted residual bottleneck blocks (bottleneck), a pyramid pooling module (PPM) and a feature fusion module (FFM) block. Parameters t, c, n and s represent expansion factor of the bottleneck block, number of output channels, number of times block is repeated and stride parameter which is applied to first sequence of the repeating block. The horizontal lines separate the modules: learning to down-sample, global feature extractor, feature fusion and classifier (top to bottom).
可以理解为 PSPNet 的加强版!
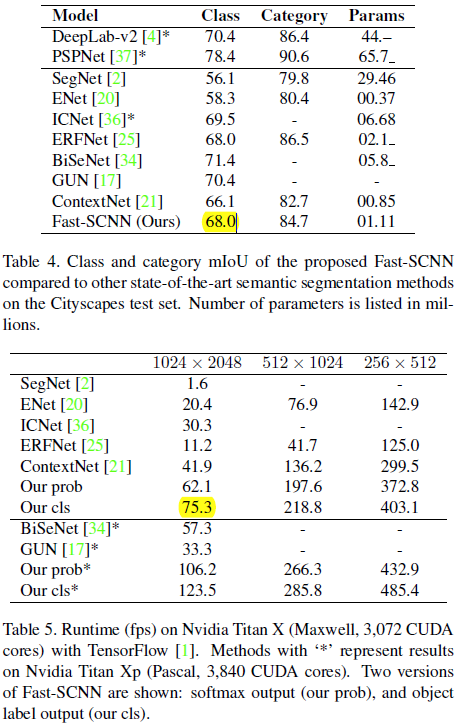
该文章官方没有公布源码,第三方实现我这边 512x1024 尺度下训练,2 GFlops,1024x2048 尺度下测试能够达到 69 mIoU.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号