


python学习笔记 day06 小知识点总结
python2 与python3区别
见这篇博客:https://www.cnblogs.com/xuanxuanlove/p/9452895.html
'==' ,'=' ,is ,id()
==是比较值是否相等;
=是赋值号;
is是比较内存地址是否相等,用来判断是否是同一个;
id()用来查看一个变量的内存地址;
L1=[1,2,3] L2=L1 print(L1 is L2)
运行结果:
F:\workspace_python\pycharm_projects\venv\Scripts\python.exe F:/workspace_python/pycharm_projects/fullstack2018-08-17/week2/day03/01.py
True
L1=[1,2,3] L2=L1 print(L1 is L2) #判断L1 L2是否内存一样; print(id(L1),id(L2)) #查看两个变量的内存地址; L2=[2,3,4] #现在改变L2变量的指向,并不会改变L1的指向; print(L1 is L2) #所以现在L1,L2的指向不同,内存地址也不一样; print(id(L1),id(L2)) #输出两个变量的内存地址;
运行结果:
F:\workspace_python\pycharm_projects\venv\Scripts\python.exe F:/workspace_python/pycharm_projects/fullstack2018-08-17/week2/day03/01.py True 32021512 32021512 False 32021512 31209544
数字 字符串--小数据池
小数据池:就是在小数范围内,两个变量赋予同一个值时,会指向同一个内存空间;
数字:-5 - 265范围内,两个变量值一样,会指向同一块内存空间;
字符串:1.不能有特殊字符;2. s*20会指向同一块内存空间;
数字:
a=6 b=6 print(id(a),id(b)) #小数据范围内会指向同一块内存空间; a=257 b=257 print(a is b) #False 超出整数小数据池范围,就会分配两个内存空间;
运行结果:
1494573376 1494573376
True
字符串:
s1='asjkdj' s2='asjkdj' print(s1 is s2) # True 无特殊字符,会指向同一块内存空间; s1='a'*18 s2='a'*18 print(s1 is s2) #True s*20以内的都指向同一块内存空间;; s1='b'*23 s2='b'*23 print(s1 is s2) #False 会分配两个内存空间;
运行结果:
F:\workspace_python\pycharm_projects\venv\Scripts\python.exe F:/workspace_python/pycharm_projects/fullstack2018-08-17/week2/day03/01.py
True
True
False
小数据池是为了在一定程度上节省内存空间;
其他数据类型 list tuple dict set---无数据池概念
L1=[1,2] L2=[1,2] print(L1 is L2) #False list 无数据池概念
运行结果:
F:\workspace_python\pycharm_projects\venv\Scripts\python.exe F:/workspace_python/pycharm_projects/fullstack2018-08-17/week2/day03/01.py
False
编码

总结一下:
编码方式有 ASCII,Unicode , utf-8 gbk
ASCII :只对英文,一个字符用一个字节,8位表示;
Unicode: 最开始对所有字符都采用两个字节,16位表示(中英 字符都是两个字节),后来扩充全部采用4个字节,32位表示,----并未进行优化,不区分中英,统一表示;
utf-8:一个英文字符采用一个字节8位表示,中文字符采用三个字节24位表示;
gbk:一个英文字符一个字节8位表示,一个中文字符两个字节16位表示;
关于编码需要说明的两点:
1.各个编码方式之间的二进制,是互不相识的,会产生乱码;
2.文件的存储和传输不用unicode 因为4个字节占用内存太大,一般采用utf-8,utf-16,gbk,gb1232,ascii等;
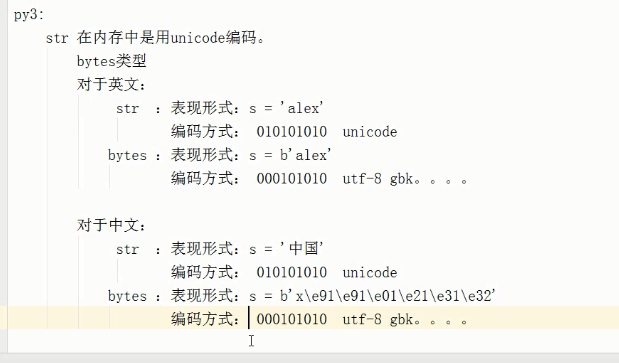
python3
python3中 str编码方式是unicode方式,由于在进行存储和传输时不能采用unicode(占用内存太大)而是采用utf-8或者gbk方式,所以str不能直接存储和传输,需要进行转换,转成gbk的0101 或者utf-8的0101再进行传输;
python中的数据类型除了int str bool list tuple dict set外还有一种数据类型Bytes类型:bytes编码方式 utf-8 或者gbk 所以str需要先转化为bytes才可以进行存储和传输;
python3
英文存储
str 表观表示: s='a' ;
编码方式:unicode;
bytes 表观表示:s=b‘a’ #需要前面加上b;
编码方式:utf-8 或者gbk;
中文存储
str 表观表示:s='中';
编码方式:unicode ;
bytes 表观表示:s=''b'\xd6\xd0'(gbk一个字符采用2个字节表示) 或者s=b'\xe4\xb8\xad'(utf-8一个字符采用三个字节表示)
编码方式gbk 或者utf-8
s='a' #str print(s,type(s)) s=b'a' #Bytes print(s,type(s))
运行结果:
F:\workspace_python\pycharm_projects\venv\Scripts\python.exe F:/workspace_python/pycharm_projects/fullstack2018-08-17/week2/day03/01.py a <class 'str'> b'a' <class 'bytes'>
s='中国' #str 中文 print(s,type(s)) # str类型 s1=s.encode('utf-8') #一个中文字符用三个字节表示; s2=s.encode('gbk') #一个字节采用两个字节表示; print(s1,type(s1)) #bytes数据类型; print(s2,type(s2)) #bytes数据类型;
运行结果:
中国 <class 'str'> b'\xe4\xb8\xad\xe5\x9b\xbd' <class 'bytes'> b'\xd6\xd0\xb9\xfa' <class 'bytes'>
以上就是str转化为bytes数据类型,内部编码方式上就是unicode转化为utf-8或者gbk编码方式,以便进行存储和传输;


 浙公网安备 33010602011771号
浙公网安备 33010602011771号