
从celery rabbitmq with docker-compose 引出对容器、依赖注入、TDD的感悟
用docker配置项目管理系统taiga的时候,不是我一个人遇到这个问题。https://github.com/douglasmiranda/docker-taiga/issues/5
问题描述:
用docker-compose启动celery_worker和rabbitmq,但是celery_worker 连不上 rabbitmq
celeryworker_1 | [2017-12-06 07:56:36,539: ERROR/MainProcess] consumer: Cannot connect to amqp://guest:**@rabbit1:5672//: [Errno -2] Name or service not known.
celeryworker_1 | Trying again in 4.00 seconds...
创建celery的地方用官网的
app = Celery(backend='amqp', broker='amqp://')
是不行的。
改成正式点的:
app = Celery(backend='amqp', broker='amqp://guest:guest@localhost:5672/')
也是不行的,不论用localhost。docker-compose 里 给 rabbitmq 设置的 hostname 都是不行的
成功尝试一:rabbitmq在容器中,celery worker 和 发起异步任务在host
遇到问题1,首先缩小问题。分步尝试,首先尝试只用容器启动rabbitmq。然后和传统方式一样,在host手工启动celery worker。
成功。
问题缩小到celery_worker容器化的问题。
稍微靠谱点的解法是
1先手工创建1个docker bridge
2 用docker命令行分别启动rabbitmq和celery worker
3 手工把celery worker 和 rabbitmq 添加进bridge。
据说可行,但是我就是要用docker-compose的啊,这样太丑陋了。
但至少说明有可能成功(不是celery本身bug之类)
成功尝试二、rabbitmq 和celeryworker都在容器中,celery用host的ip地址连接rabbitmq。
异步发起者可以在容器中,也可以在host中
docker中只运行rabbitmq,暴露5672 和15672端口,在本地host安装celery 起celery worker 是没问题的
但是如果想把celery worker也放进容器里,就出问题了。总是提示连不上amqp。
用了各种方法,最终把rabbit5672暴露,然后把HOST主机IP灌进celery,搞定
HOST_IP = '192.168.239.129' # ip of host(run docker-compose)
app = Celery(backend = 'rpc://', broker = 'amqp://guest:guest@{0}:5672/'.format(HOST_IP))
额外的小技巧:
ubuntu查看 ip :
ip addr show
成功尝试三、rabbitmq 和celeryworker都在容器中,celery用docker-compose.yml中的service_name连接
异步发起者只能在容器中
20171207隔了一天,终于发现其实不需要HOST_IP,可以用名字连接的!
只不过名字被docker、rabbitmq给来回误导了
先说答案:celery里要用docker-compose.yml里的这个名字,即启动rabbitmq镜像的那个service的名字(而不是他的hostname,我把它注释掉了,太坑人):
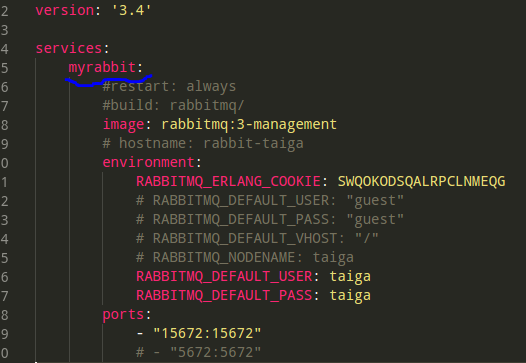
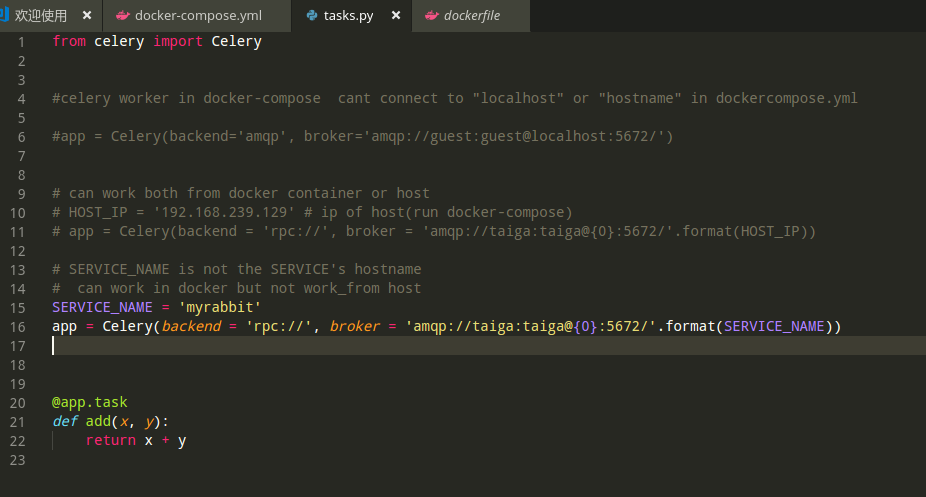
这样搞的话,比用HOST_IP不好的地方在于,没法从host发起异步任务(返回不了结果)。只能从docker-compose启动容器,在里面发起异步任务。
好处是5672端口不用暴露出来了。docker-compose内网和外部完全隔离,外面感觉不到rabbitmq存在(当然我保留了暴露15672监控端口,其实也可以不暴露)
——其实postgres的问题也是一样,用Adminer连接的时候,Server处填的也是docker-composer.yml里的service名字。
http://www.cnblogs.com/xuanmanstein/p/7742647.html
结论
解决方案不细说了,放github上了
https://github.com/xuqinghan/celery-with-docker-compose#celery-with-docker-compose
心得:
1 遇到问题,要缩小、后退、分解。
像锯木头锯不动了,要往后撤,然后稍微换换方向,角度,再用巧力,不要用蛮力:
1从部署taiga的event模块遇到celery_worker连接不上;
2退到用docker-compose运行celery官网的a+b小函数的demo 还是连不上;
3再继续后退:只用docker-compose部署rabbitmq。手工启动celery和发起异步任务,成功。
4在3成功的基础上小步前进。而此时问题已经缩小、聚焦到足够小,再尝试几种解决方案:localhost 127.0.0.1 hostname bridge方式docker0网络
5搞定、总结。成为自己的技能点,到处复用。
2 不要有洁癖,
不追求rabbitmq不暴露任何端口,只服务于docker-compose的网络(不是docker0) ,在host里暴露端口不丢人;
在开发机上,只在调试当前工程时启动当前的docker-compose。在生产环境还是1机1个组的。不追求多工程在一个机器上运行。
不追求一次就实现全都容器化,和写代码一样,先写好单次执行的逻辑,再套外层的for循环。
——注意到了这些点,问题半天不到就搞定了;死钻牛角尖,可能N天都无解。
3 不能有0 or 100分这种想法。
不能急躁,也不能浮躁(想一次就得100分);
也不能因为想太多,把问题看成铁板1块,就畏惧困难(直接交白卷得0分)。
——做工程,都是1分、1分地得分,也是1分 1分地扣分的。 这和合同收付款、各种节点是完全不同的!不要被后者的干扰带乱了自己的工作节奏。
做工程是类似持仓、空仓的长期过程,而不是啪啪啪不断交易的各种精彩瞬间。(如果永远处在赶工、保/抢节点的状态,要么是自己工作能力不行,要么就是项目管理SB,没有轻重缓急)
4做工程的人,在工程上做任何事每次出手,都要有章有法:有高度的目的论,且目的又和普通人不同:
1 贯彻目的和意图导向的思考。在意从需求、系统用例、到组件名、类名、子过程名、直到变量名的命名,名不正则言不顺,要强迫自己和别人(Не жалей ни себя, ни врагов.“不要吝惜自己和敌人”——《斯拉夫女人的告别》白俄版)思考目的性、价值和重要性排序。并且在每一天、每一句的开发中不断加深学习、打磨、养成习惯;
2 能每时每刻聚焦特定问题,能暂时忽略其他问题和要求,有“置XX之敌于不顾”,“攻其一点,不及其余”的勇气和能耐。这是建立在对能力的自信心(“打哪个,哪个就剩不下”,所以我有资格挑着打)基础之上的纯粹和纯净的心理状态。
接触新人、业余选手、非技术人员的最大感觉就是:
在1上,想的太简单,做的太随意(用我的话说,像个孩子);
在2上,一次想得太杂,想得太多(0分VS100分 来回地跳变,还是像个什么都想要的孩子)。
——包括之前的自己,也是这样。还是因为功力不够+心浮气躁=棒槌。
因为和他们视角不同(甚至完全不同),所以自己首先不要生气,配合别人的任务区时可以忍着点,尽力配合;
但只要进入自己的责任区,就是要火力全开。如果气着对方也不要在意(负责这片的人是我,我也没想故意气谁,所以也无所谓)。
和战斗机一样,包线上各有优势区,但进入大喷9(Spitfire LF IX)的优势区,就不要怪Hispano 炮狠了。
技术方面的感受:容器和镜像不是万能的。不是什么都适合打包进镜像。
celery和django都相继不再在dockerhub发布官方镜像。因为这俩在用的时候,大家都是定制、引用之后才用的。
并不是这俩和docker决裂了,只是不适合打包进dockerfile罢了。
对开发人员来说,什么适合塞进dockerfile呢?配环境的步骤+配出来的一致性,隔离的、纯净的运行环境。塞配置文件的位置。
其实dockerfile有点像测试框架。而源代码和配置文件,类似mock。
所以,这符合我下意识的做法:我喜欢把源代码、和各种配置文件,数据库文件都放在外面, 用-v 或者volumns 在容器启动时挂进去,而不是写在dockerfile里(git clone 源代码,具体配置参数),直接build成image。
这种套路,非常类似于依赖注入,把repository,service塞进component的过程。
此外,这样好写测试用例啊(不依赖实际连接web和数据库)!
任何单元测试的运行,都不能依赖真实的web和数据库访问。
否则因为耗时间或者环境难配,不得不每次注释掉一部分用例,现在想想,那还测试个屁啊!
写程序的精髓在于识别和感受到 复杂性+变化性 VS 繁琐+稳定 ,然后不断分离,隔离,让不同变化速率,膨胀系数的材料,高度地解耦。
——写程序的门道无非那几条,但是知道这些道理是一回事,理解认同这些道理是另一回事, 而实际工作中能在各种场合把这些招给用出来,用活了,又是另一回事了。
和武术、修行一样,知易行难。“三岁小儿道得,八十老翁行不得”。
需要勤学苦练,不是蛮干(grasshopper里不写代码,一片一片地电池)
从各种角度、各种道路、多次实践,去领悟相同的道理。
然后就容易全面开窍和到处突破了。
之前了解、学TDD半天,但是就是用不好;现在用了一段时间docker,反而容易找到依赖注入的感觉。
自己写的程序,有哪些是框架性的,类似dockefile的;有哪些是频繁改动的,类似源代码、配置文件内容的,要层次分明,分离,然后各自获得自由;
这个分离:就是意图与实现、虚VS实;部队 VS 分队,测试用例VS外部接口的mock。
关注点分离了,就各自聚焦了,也自由了。分得开,责任边界清晰,才联合得起来。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号