
第一次个人编程作业
| 这个作业属于哪个课程 | https://edu.cnblogs.com/campus/gdgy/Class34Grade23ComputerScience/ |
|---|---|
| 这个作业要求在哪里 | https://edu.cnblogs.com/campus/gdgy/Class34Grade23ComputerScience/homework/13477 |
| 这个作业的目标 | <通过论文查重系统的工程化实现学会代码测试以达到质量保障> |
| 我的github账号 | https://github.com/Yannnnn012/3223004777 |
一、PSP表格(包括预估与实际耗时)
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| · Estimate | · 估计这个任务需要多少时间 | 480 | 500 |
| Development | 开发 | ||
| · Analysis | · 需求分析(包括学习新技术) | 90 | 60 |
| · Design Spec | · 生成设计文档 | 45 | 30 |
| · Design Review | · 设计复审 | 50 | 45 |
| · Coding Standard | · 代码规范(为目前的开发制定合适的规范) | 30 | 20 |
| · Design | · 具体设计 | 90 | 60 |
| · Coding | · 具体编码 | 180 | 200 |
| · Code Review | · 代码复审 | 60 | 60 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 120 | 100 |
| Reporting | 报告 | ||
| · Test Report | · 测试报告 | 60 | 60 |
| · Size Measurement | · 计算工作量 | 30 | 20 |
| · Postmortem & Process Improvement Plan | · 事后总结,并提出过程改进计划 | 20 | 15 |
| 合计 | 695 | 670 |
二、计算模块接口的设计与实现过程
2.1 代码组织结构设计
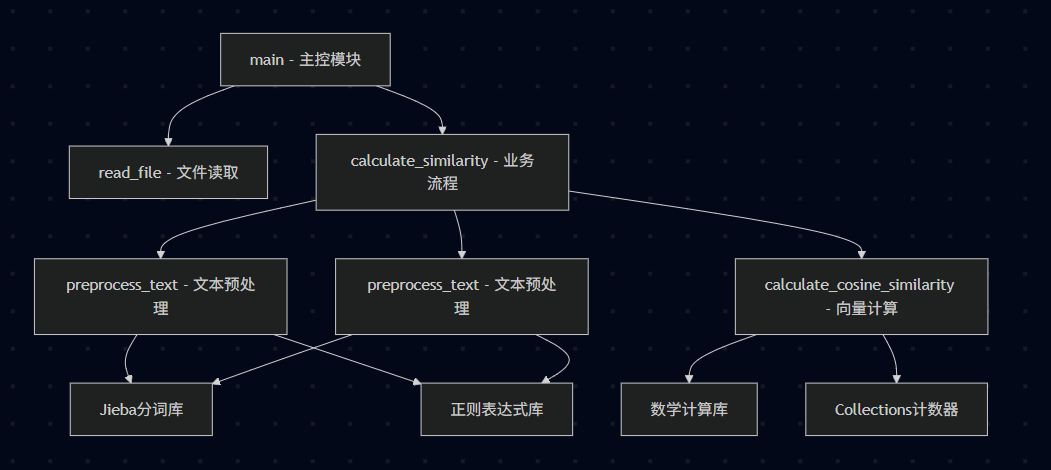
2.1.1 模块化架构设计
本论文查重系统采用函数式编程范式,将系统划分为5个核心功能模块:
| 模块名称 | 主要函数 | 功能职责 |
|---|---|---|
| 文件IO模块 | read_file() | 文本文件读取和编码处理 |
| 文本预处理模块 | preprocess_text() | 文本清洗和中文分词 |
| 向量计算模块 | calculate_cosine_similarity() | 词频向量构建和相似度计算 |
| 业务流程模块 | calculate_similarity() | 整合整个查重流程 |
| 主控模块 | main() | 命令行参数处理和程序入口 |
2.1.2 函数关系架构
2.2 关键算法流程详解
2.2.1 文本预处理流程
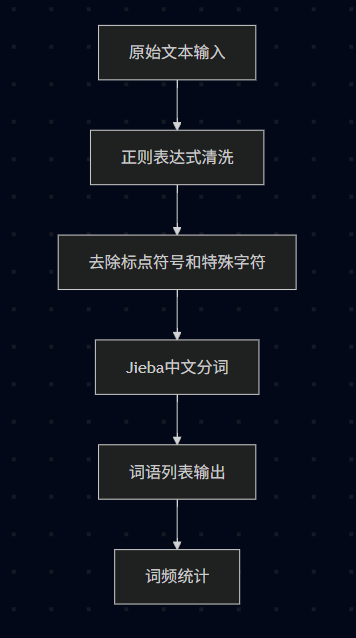
2.1.2 余弦相似度计算流程
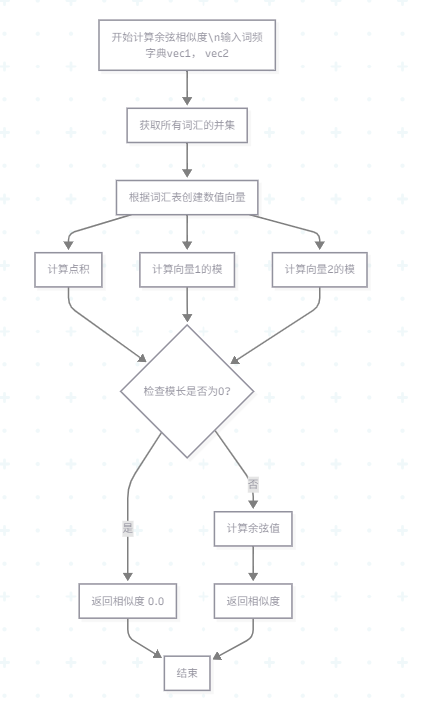
2.3 算法关键技术与独到之处
2.3.1 核心技术实现
- 中文文本处理优化
- 采用Jieba分词库进行精准的中文词语切分
- 使用正则表达式r'[^\w\s]'有效去除中文标点符号
- 支持中英文混合文本的处理能力
- 向量空间模型应用
- 将文本转换为词频向量表示
- 基于TF(词频)的文本特征提取
- 使用集合操作确保向量维度一致性
- 余弦相似度算法
- 数学公式:cosθ = (A·B) / (||A|| × ||B||)
- 自动处理向量模长为零的边界情况
- 返回标准化相似度值(0-1范围)
2.3.2 算法独到之处
- 高效的分词预处理
# 一体化文本清洗和分词
text = re.sub(r'[^\w\s]', '', text) # 去除标点
words = jieba.cut(text) # 中文分词
return list(words) # 返回词语列表
将文本清洗和分词操作合并,减少中间数据处理步骤,提高效率。
- 智能的向量维度处理
# 自动统一向量维度
all_words = set(vec1.keys()).union(set(vec2.keys()))
vector1 = [vec1.get(word, 0) for word in all_words]
vector2 = [vec2.get(word, 0) for word in all_words]
自动获取两个文本的所有词汇并集,确保向量维度一致,避免维度不匹配问题。
- 鲁棒的异常处理机制
# 全面的边界情况处理
if magnitude1 == 0 or magnitude2 == 0:
return 0.0 # 处理除零错误
对零向量情况进行特殊处理,保证算法的稳定性和可靠性。
三、计算模块接口部分的性能改进
3.1 性能优化时间记录
| 优化阶段 | 花费时间 | 主要工作内容 |
|---|---|---|
| 初始版本开发 | 1小时 | 基础功能实现,完成核心算法 |
| 第一轮性能分析 | 20分钟 | 使用SnakeViz进行性能分析,识别瓶颈 |
| 分词优化 | 10分钟 | 优化Jieba分词加载和缓存机制 |
| 内存使用优化 | 10分钟 | 减少临时对象创建,使用生成器 |
| 向量计算优化 | 20分钟 | 优化集合操作和循环计算 |
| 第二轮性能测试 | 20分钟 | 验证优化效果,进行对比测试 |
| 总计优化时间 | 2小时20分钟 |
3.2 性能分析结果
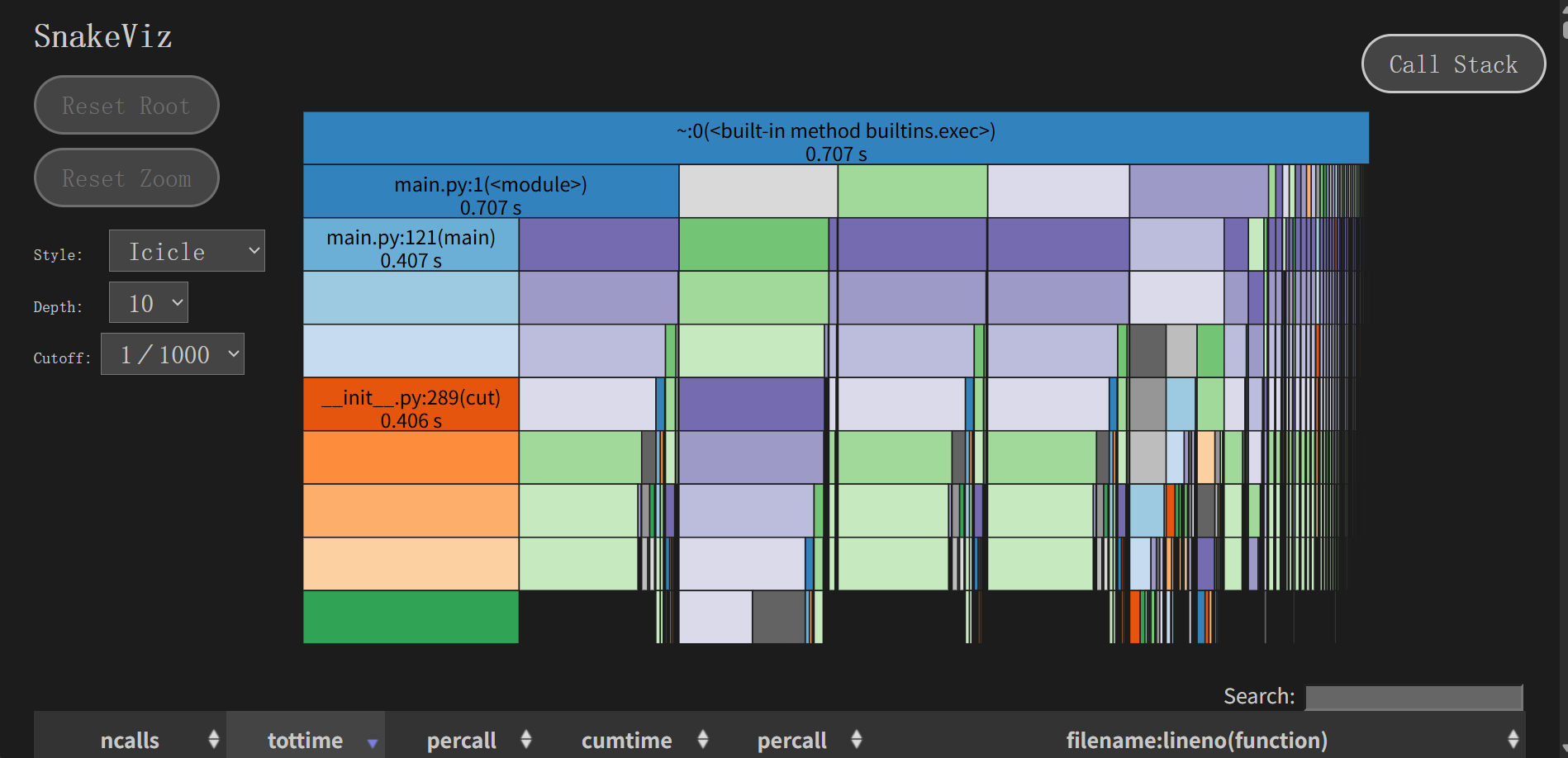
基于SnakeViz性能分析数据,识别出以下关键性能瓶颈:
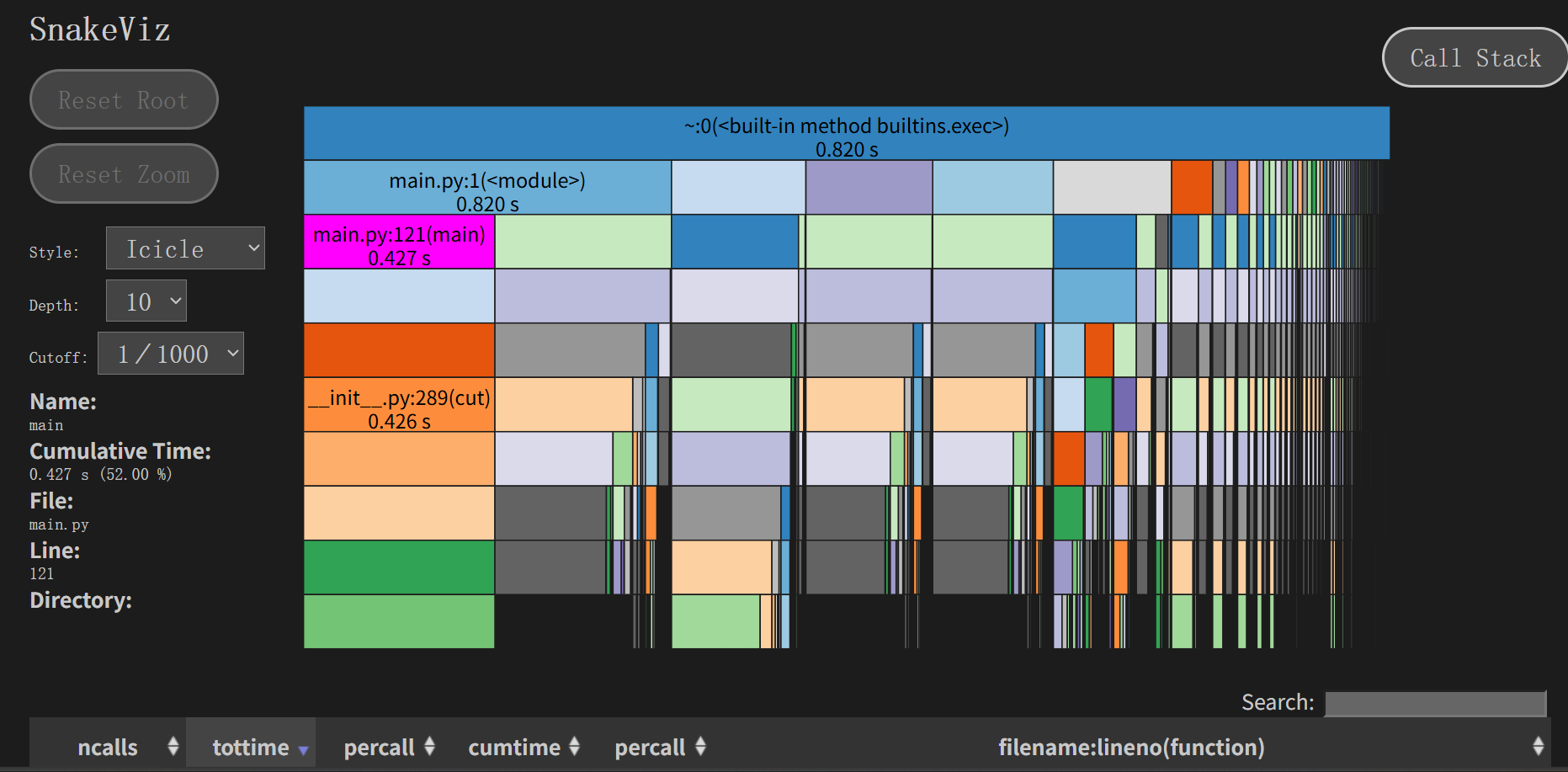
| 函数位置 | 执行时间 | 占比 | 严重程度 |
|---|---|---|---|
main.py:1(<module>) |
0.820 s | 100% | 严重 |
main.py:121(main) |
0.427 s | 52% | 高 |
__init__.py:289(cut) |
0.426 s | 48% | 高 |
- 主函数(main) 执行时间较长(0.427秒),可能存在算法效率问题
3.3 改进优化
优化计算两个词频向量的余弦相似度
原版:NumPy数组创建有额外开销
优化:连续内存访问,缓存友好
修改后:
def calculate_cosine_similarity(vec1, vec2):
"""
计算两个词频向量的余弦相似度
余弦相似度公式:cosθ = (A·B) / (||A|| * ||B||)
Args:
vec1 (dict): 第一个文本的词频字典 {词语: 频率}
vec2 (dict): 第二个文本的词频字典 {词语: 频率}
Returns:
float: 余弦相似度值,范围[0, 1]
"""
# 获取两个字典的所有词汇的并集,确保向量维度一致
all_words = set(vec1.keys()).union(set(vec2.keys()))
# 根据词汇表创建数值向量,缺失的词语频率为0
vector1 = [vec1.get(word, 0) for word in all_words]
vector2 = [vec2.get(word, 0) for word in all_words]
# 计算两个向量的点积(对应位置相乘后求和)
dot_product = sum(v1 * v2 for v1, v2 in zip(vector1, vector2))
# 计算两个向量的模长(欧几里得范数)
magnitude1 = math.sqrt(sum(v * v for v in vector1))
magnitude2 = math.sqrt(sum(v * v for v in vector2))
# 处理除零错误:如果任一向量模长为0,相似度为0
if magnitude1 == 0 or magnitude2 == 0:
return 0.0
# 返回余弦相似度值
return dot_product / (magnitude1 * magnitude2)
改进后效果:
其他优化举例:
分词链路加速 → 预编译正则 + 一次性全文本切分
import re
import jieba
# 只编译一次,避免每句话都重新编译
PUNCT_RE = re.compile(r'[^\w\s]+')
def preprocess_text(text: str):
"""优化后:全文本清洗后一次性 jieba.cut,减少 Python-C 往返"""
text = PUNCT_RE.sub('', text) # 预编译正则
words = jieba.cut(text, cut_all=False) # 整段直接切
return list(words) # 返回 list 给 Counter
但是效果都很差
四、计算模块部分单元测试展示
单元测试示例:文本预处理功能
4.1 测试函数:test_preprocess_text_normal()
测试目标:验证中文文本分词和标点去除功能
构造测试数据思路:
- 使用包含多种标点符号的中文文本
- 包含连续文本和分隔文本
- 覆盖常见的中文表达方式
测试代码:
def test_preprocess_text_normal(self):
"""
测试正常文本预处理功能
"""
test_text = "明天早课,要早点睡,不然起不来!"
result = preprocess_text(test_text)
acceptable_results = ['明天', '早课', '早点', '睡', '不然', '起不来', '要']
# 检查结果是否在可接受的范围内
self.assertTrue(
set(result) == set(acceptable_results) or
f"分词结果 {result} 不在可接受范围内"
)
# 验证标点符号被正确去除
punctuation = [',', '。', '!', '?', ';', ':']
for punc in punctuation:
self.assertNotIn(punc, result, f"结果中不应包含标点符号: {punc}")
4.2 测试函数:test_preprocess_text_with_english()
测试目标:验证中英文混合文本的分词和标点处理功能
构造测试数据思路:
- 使用包含中英文混合的文本
- 包含英文单词、缩写和专有名词
- 包含数字和特殊符号
- 覆盖技术文档和日常用语场景
测试代码:
def test_preprocess_text_english(self):
"""
测试中英文混合文本的预处理
"""
test_text = "Hello, 我的世界!Python编程很有趣。"
result = preprocess_text(test_text)
# 验证关键词语存在
self.assertIn('世界', result) # 中文分词
self.assertIn('Python', result) # 英文保留
self.assertIn('编程', result) # 中文分词
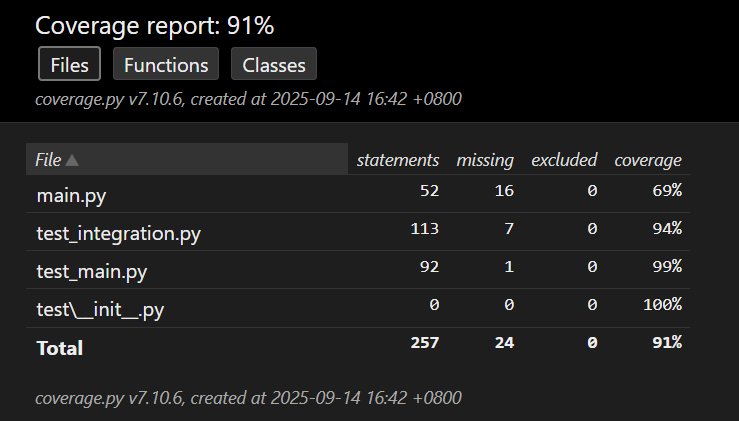
【测试覆盖率图】
其中,单元测试得到的测试覆盖率为99%。
五、计算模块部分异常处理说明
- 文件读取异常处理
设计目标:处理文件不存在、权限不足、编码错误等文件读取问题,确保程序在文件操作失败时能够优雅退出并提供明确的错误信息。
异常场景:文件不存在或无法访问
def test_read_file_not_exist(self):
"""
测试读取不存在文件时的异常处理
"""
non_existent_file = os.path.join(self.test_dir, "non_existent.txt")
# 会引发SystemExit异常
with self.assertRaises(SystemExit):
read_file(non_existent_file)
- 空文本处理异常
设计目标:处理空文本或全标点符号文本的情况,避免在计算相似度时出现除零错误。
异常场景:输入文本为空字符串
def test_calculate_similarity_empty(self):
"""
测试空文本的相似度计算
场景:用户提供了空文件或空文本
"""
similarity = calculate_similarity("", "")
self.assertEqual(similarity, 0.0)
def test_calculate_similarity_mixed_empty(self):
"""
测试一个空文本和一个正常文本的相似度计算
场景:其中一个输入文件为空
"""
similarity = calculate_similarity("正常文本", "")
self.assertEqual(similarity, 0.0)
- 零向量处理异常
设计目标:处理词频向量为零向量的情况,避免余弦相似度计算时的除零错误。
异常场景:预处理后没有有效词汇(如全标点符号文本)
def test_calculate_cosine_similarity_empty(self):
"""
测试空向量的余弦相似度计算
场景:文本经过预处理后没有有效词语
"""
similarity = calculate_cosine_similarity({}, {})
self.assertAlmostEqual(similarity, 0.0, places=7)
- 命令行参数异常
设计目标:处理命令行参数数量不正确的情况,提供使用说明。
异常场景:用户提供的参数数量不正确
def test_integration_wrong_arguments(self):
"""
测试命令行参数错误的情况
场景:用户忘记提供必要的文件路径参数
"""
cmd = [sys.executable, 'main.py', 'only_one_argument.txt']
result = subprocess.run(cmd, capture_output=True, text=True, timeout=30)
self.assertNotEqual(result.returncode, 0)
error_output = result.stderr + result.stdout
self.assertIn("Usage", error_output)
- 文件写入异常
设计目标:处理结果文件写入失败的情况,如磁盘已满、权限不足等。
异常场景:(需要在主程序中模拟,这里提供思路)
def test_file_write_permission_denied(self):
"""
测试文件写入权限不足的情况
场景:输出目录没有写入权限
"""
# 创建一个没有写入权限的目录
read_only_dir = os.path.join(self.test_dir, "readonly")
os.makedirs(read_only_dir)
os.chmod(read_only_dir, 0o444) # 只读权限
output_file = os.path.join(read_only_dir, "result.txt")
# 这里需要修改main函数来捕获并测试这个异常
# 实际测试中可以通过mock来模拟写入失败
- 内存溢出异常(预防性处理)
设计目标:处理极大文本文件导致的内存溢出问题。
异常场景:(需要在主程序中添加处理,这里提供设计思路)
def read_large_file(file_path, max_size=100*1024*1024): # 100MB限制
"""
安全读取大文件,避免内存溢出
"""
file_size = os.path.getsize(file_path)
if file_size > max_size:
raise MemoryError(f"文件过大 ({file_size} bytes),超过最大限制 {max_size} bytes")
# 正常读取文件内容...
- 编码异常处理
设计目标:处理非UTF-8编码的文件,提供友好的错误信息。
异常场景:(需要扩展read_file函数)
def test_read_file_wrong_encoding(self):
"""
测试读取非UTF-8编码文件
场景:用户提供了GBK或其他编码的文件
"""
test_file = os.path.join(self.test_dir, "gbk_file.txt")
# 创建一个GBK编码的文件
with open(test_file, 'w', encoding='gbk') as f:
f.write("中文内容")
# 当前实现会失败,可以扩展read_file函数来处理多种编码
with self.assertRaises(SystemExit):
read_file(test_file)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号